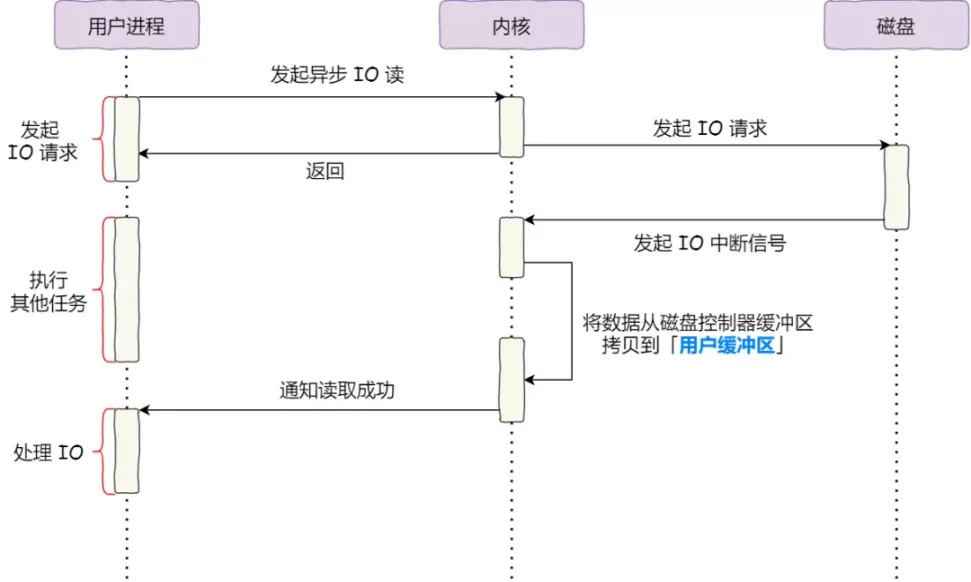
分布式系统之所以难,很重要的原因之一是“没有一个全局时钟,难以保证绝对的时序”。

一、分布式ID的特性或要求:
- 唯一性:确保生成的ID是应用系统内唯一。
- 高可用性:确保任何时候都能正确的生成ID。
- 有意义:或者说包含更多信息,例如时间、业务等信息。如:有序性,通常都需要保证生成的 ID 是有序递增的。例如,在数据库存储等场景中,有序 ID便于确定数据位置,往往更加高效
- 紧凑性:ID 的大小可能受到实际应用的制约,例如数据库存储往往对长 ID不友好,太长的ID 会降低 MySQL 等数据库索引的性能;
二、分布式ID的生成方案
1. UUID
算法的核心思想是结合机器的网卡、当地时间、一个随记数来生成UUID。
优点:本地生成,生成简单,性能好,没有高可用风险
缺点:长度过长,存储冗余,且无序不可读,查询效率低
2. 数据库自增ID
使用数据库的id自增策略,如 MySQL 的 auto_increment。并且可以使用两台数据库分别设置不同步长,生成不重复ID的策略来实现高可用。
优点:数据库生成的ID绝对有序,高可用实现方式简单
缺点:
- 需要独立部署数据库实例,成本高,有性能瓶颈
- 可用性难以保证:数据库常见架构是一主多从+读写分离,生成自增ID是写请求,主库挂了就玩不转了
- 扩展性差,性能有上限:因为写入是单点,数据库主库的写性能决定ID的生成性能上限,并且难以扩展
优点:避免了每次生成ID都要访问数据库并带来压力,提高性能
缺点:属于本地生成策略,存在单点故障,服务重启造成ID不连续

自增ID选择bigint类型,bigint的范围是 -2^63 (-9223372036854775808) 到 2^63-1 (9223372036854775807) 的整型数据(所有数字)。可以批量生成ID,一次按需批量生成多个ID,每次生成都需要访问数据库,将数据库修改为最大的ID值,并在内存中记录当前值及最大值。
假设每天100万记录,你可以使用922,337,203,685天,也就是 2,562,047,788 年。
3. Redis生成ID(推荐)
Redis的所有命令操作都是单线程的,本身提供像 incr 和 increby 这样的自增原子命令,所以能保证生成的 ID 肯定是唯一有序的。
优点:不依赖于数据库,灵活方便,且性能优于数据库;数字ID天然排序,对分页或者需要排序的结果很有帮助。
缺点:如果系统中没有Redis,还需要引入新的组件,增加系统复杂度&#x










![[ 全部搞定 - 发票导出表格 ] PDF发票提取到表,图片发票提取到表格,扫描件发票提取到表格,全电发票PDF,全电发票扫描件识别导出EXCEL表格](https://i-blog.csdnimg.cn/direct/5c210fb098f54763ad83294b79b16c2f.jpeg)



