问题分析概述
库总是OOM,分析到是执行计划生成有问题,planning time 1秒,planning shared hit 100w。一通分析,定位到是统计信息基表pg_statistic膨胀,由于会话首次SQL执行时的CatCacheMiss,导致backend访问并缓存了pg_statistic过多的死元组数据。应用连接总会启用新会话,多个backend的总内存过大从而导致OOM。
下面是详细分析过程。
问题现象
某库反复OOM和重启。经过一通问题排查,发现会话连接数不多,但是每个会话的内存占用比较高,总内存超过内存cg限制导致OOM。
初步可以排除以下原因:
- 不是元数据过多的问题导致。对象过多(一般是分区数太多)会导致会话缓存过多的元数据。这个库的对象不算多
- 不是sql执行计划问题。排序/hash可能使用过多内存。这个库不是这个场景,sql可以是一个顺序扫描。
在问题分析过程中发现,库里面执行任意一个简单sql执行时间很长,并且 Planning Buffers有约100w
explain (analyze,buffers,timing) select * from lzlinfo limit 1;
QUERY PLAN
--------------------------------------------------------------------------------------------------------------------
Limit (cost=0.00..1.02 rows=1 width=71) (actual time=0.011..0.012 rows=1 loops=1)
Buffers: shared hit=1
-> Seq Scan on lzlinfo (cost=0.00..480.73 rows=473 width=71) (actual time=0.010..0.010 rows=1 loops=1)
Buffers: shared hit=1
Planning:
Buffers: shared hit=1127312 --异常planning shared hit
Planning Time: 947.038 ms --异常planning time
Execution Time: 0.035 ms
(8 rows)
再执行一次sql,planning time就正常了。
问题定位过程
打印执行计划的stat信息
把会话的执行计划各阶段的stat信息打到日志:
set log_parser_stats =on;
set log_planner_stats =on;
set log_executor_stats =on;
然后跑下sql,日志输出如下:
2024-08-13 10:02:33.936 CST,"postgres","lzldb",85532,"[local]",66babe8c.14e1c,13,"idle",2024-08-13 10:01:48 CST,4/713,0,LOG,00000,"PARSER STATISTICS","! system usage stats:
! 0.000046 s user, 0.000046 s system, 0.000091 s elapsed
! [0.001661 s user, 0.001661 s system total]
! 4660 kB max resident size
! 0/0 [0/8] filesystem blocks in/out
! 0/36 [0/996] page faults/reclaims, 0 [0] swaps
! 0 [0] signals rcvd, 0/0 [0/0] messages rcvd/sent
! 0/0 [5/0] voluntary/involuntary context switches",,,,,"explain (analyze,buffers) select *,1 from lzlinfo
2024-08-13 10:02:33.938 CST,"postgres","lzldb",85532,"[local]",66babe8c.14e1c,14,"EXPLAIN",2024-08-13 10:01:48 CST,4/713,0,LOG,00000,"PARSE ANALYSIS STATISTICS","! system usage stats:
! 0.001459 s user, 0.000000 s system, 0.001464 s elapsed
! [0.003146 s user, 0.001687 s system total]
! 5972 kB max resident size
! 0/0 [0/8] filesystem blocks in/out
! 0/325 [0/1324] page faults/reclaims, 0 [0] swaps
! 0 [0] signals rcvd, 0/0 [0/0] messages rcvd/sent
! 0/0 [5/0] voluntary/involuntary context switches",,,,,"explain (analyze,buffers) select *,1 from lzlinfo
2024-08-13 10:02:33.938 CST,"postgres","lzldb",85532,"[local]",66babe8c.14e1c,15,"EXPLAIN",2024-08-13 10:01:48 CST,4/713,0,LOG,00000,"REWRITER STATISTICS","! system usage stats:
! 0.000001 s user, 0.000000 s system, 0.000001 s elapsed
! [0.003177 s user, 0.001687 s system total]
! 5972 kB max resident size
! 0/0 [0/8] filesystem blocks in/out
! 0/0 [0/1324] page faults/reclaims, 0 [0] swaps
! 0 [0] signals rcvd, 0/0 [0/0] messages rcvd/sent
! 0/0 [5/0] voluntary/involuntary context switches",,,,,"explain (analyze,buffers) select *,1 from lzlinfo
2024-08-13 10:02:34.644 CST,"postgres","lzldb",85532,"[local]",66babe8c.14e1c,16,"EXPLAIN",2024-08-13 10:01:48 CST,4/713,0,LOG,00000,"PLANNER STATISTICS","! system usage stats:
! 0.539964 s user, 0.164083 s system, 0.705718 s elapsed
! [0.543248 s user, 0.165770 s system total]
! 745072 kB max resident size --异常点
! 0/0 [0/8] filesystem blocks in/out
! 0/184803 [0/186157] page faults/reclaims, 0 [0] swaps
! 0 [0] signals rcvd, 0/0 [0/0] messages rcvd/sent
! 0/1 [5/1] voluntary/involuntary context switches",,,,,"explain (analyze,buffers) select *,1 from lzlinfo
2024-08-13 10:02:34.644 CST,"postgres","lzldb",85532,"[local]",66babe8c.14e1c,17,"EXPLAIN",2024-08-13 10:01:48 CST,4/713,0,LOG,00000,"EXECUTOR STATISTICS","! system usage stats:
! 0.540248 s user, 0.164170 s system, 0.706088 s elapsed
! [0.543532 s user, 0.165857 s system total]
! 745596 kB max resident size
! 0/0 [0/8] filesystem blocks in/out
! 0/184898 [0/186252] page faults/reclaims, 0 [0] swaps
! 0 [0] signals rcvd, 0/0 [0/0] messages rcvd/sent
! 0/1 [5/1] voluntary/involuntary context switches",,,,,"explain (analyze,buffers) select *,1 from lzlinfo
"
planner阶段内存使用率暴涨,elapsed time也暴涨。这部分信息可以定位到是整个planning阶段中的planner阶段有问题。其他可用信息不多。
strace追踪
strace -p 76419
strace: Process 76419 attached
epoll_wait(4, [{EPOLLIN, {u32=15422552, u64=15422552}}], 1, -1) = 1
recvfrom(9, "Q\0\0\0\262explain (analyze,buffers) s"..., 8192, 0, NULL, NULL) = 179
lseek(5, 0, SEEK_END) = 8192
brk(NULL) = 0xfed000
brk(0x100e000) = 0x100e000
brk(NULL) = 0x100e000
brk(NULL) = 0x100e000
brk(0x1007000) = 0x1007000
brk(NULL) = 0x1007000
mmap(NULL, 270336, PROT_READ|PROT_WRITE, MAP_PRIVATE|MAP_ANONYMOUS, -1, 0) = 0x2b7806b0c000
open("base/17076/16678", O_RDWR) = 7
lseek(7, 0, SEEK_END) = 0
open("base/17076/46160", O_RDWR) = 12
lseek(12, 0, SEEK_END) = 7667712
open("base/17076/46168", O_RDWR) = 13
lseek(13, 0, SEEK_END) = 188416
open("base/17076/46170", O_RDWR) = 14
lseek(14, 0, SEEK_END) = 188416
mmap(NULL, 528384, PROT_READ|PROT_WRITE, MAP_PRIVATE|MAP_ANONYMOUS, -1, 0) = 0x2b78c1b36000
brk(NULL) = 0x1007000
brk(0x102c000) = 0x102c000
brk(NULL) = 0x102c000
brk(NULL) = 0x102c000
brk(0x1025000) = 0x1025000
brk(NULL) = 0x1025000
lseek(12, 0, SEEK_END) = 7667712
open("pg_stat_tmp/pgss_query_texts.stat", O_RDWR|O_CREAT, 0600) = 15
pwrite64(15, "explain (analyze,buffers) select"..., 172, 93934) = 172
pwrite64(15, "\0", 1, 94106) = 1
close(15) = 0
sendto(8, "\2\0\0\0\250\3\0\0\264B\0\0\10\0\0\0\1\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0"..., 936, 0, NULL, 0) = 936
sendto(8, "\2\0\0\0\250\3\0\0\264B\0\0\10\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0"..., 936, 0, NULL, 0) = 936
sendto(8, "\2\0\0\0\250\3\0\0\264B\0\0\10\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0"..., 936, 0, NULL, 0) = 936
sendto(8, "\2\0\0\0\250\3\0\0\264B\0\0\10\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0"..., 936, 0, NULL, 0) = 936
sendto(8, "\2\0\0\0\250\3\0\0\264B\0\0\10\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0"..., 936, 0, NULL, 0) = 936
sendto(8, "\2\0\0\0\10\1\0\0\264B\0\0\2\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0"..., 264, 0, NULL, 0) = 264
sendto(8, "\2\0\0\0\10\1\0\0\0\0\0\0\2\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0"..., 264, 0, NULL, 0) = 264
sendto(8, "\16\0\0\0H\0\0\0\6\0\0\0\0\0\0\0\0\0\0\0\0\0\0\0\1\0\0\0\0\0\0\0"..., 72, 0, NULL, 0) = 72
sendto(9, "T\0\0\0#\0\1QUERY PLAN\0\0\0\0\0\0\0\0\0\0\31\377\377\377\377"..., 826, 0, NULL, 0) = 826
recvfrom(9, 0xd2b4e0, 8192, 0, NULL, NULL) = -1 EAGAIN (Resource temporarily unavailable)
epoll_wait(4,
虽然shared hit很多,但strace信息很少
strace显示会话只open了4个数据文件,通过fd和oid2name查到数据文件,分别是表、表的两个索引以及pathman_config:
From database "lzldb":
Filenode Table Name
--------------------------------------
46170 ix_name
46168 pk_lzlinfo
46160 lzlinfo
16678 pathman_config
这些对象都不大,看上去不像这些表(or索引)过大导致的。
perf
(图不好贴自行脑补)
perf火焰图有40%的时间在heap_hot_search_buffer堆栈上
gdb
以heap_hot_search_buffe函数为依据,经过多次gdb,打如下断点试着看看哪有问题:
b relation_open
b get_relation_info
b RelationCacheInvalidateEntry
b get_relname_relid
b AcceptInvalidationMessages
b RelationClearRelation
b pg_hint_plan_planner
b heap_hot_search_buffer
刚开始命中断点的时候,其实有很多无用的信息,因为他们是正常逻辑。不过后面发现,执行到一定程度,只有heap_hot_search_buffer命中:
Breakpoint 15, heap_hot_search_buffer (tid=tid@entry=0x2313c60, relation=0x2b2141663910, buffer=17045, snapshot=snapshot@entry=0x228a058, heapTuple=heapTuple@entry=0x23273d0,
all_dead=all_dead@entry=0x7ffce272e28f, first_call=true) at heapam.c:1503
1503 in heapam.c
(gdb)
Continuing.
...
Breakpoint 15, heap_hot_search_buffer (tid=tid@entry=0x2313c60, relation=0x2b2141663910, buffer=96708, snapshot=snapshot@entry=0x228a058, heapTuple=heapTuple@entry=0x23273d0,
all_dead=all_dead@entry=0x7ffce272e28f, first_call=true) at heapam.c:1503
1503 in heapam.c
heap_hot_search_buffer传入的绝大部分参数没有变,包括relation、heapTuple的地址,只有buffer参数在改变,说明应该在扫描同一个relation。
heapTuple中包含table oid信息,直接打出来看看:
(gdb) p *heapTuple
$46 = {
t_len = 968,
t_self = {
ip_blkid = {
bi_hi = 0,
bi_lo = 7211
},
ip_posid = 5
},
t_tableOid = 2619, --这个比较有用
t_data = 0x2b2155fced00
heap_hot_search_buffer传入的oid=2619,2619在pg_class中对应pg_statistic
select oid,relname from pg_class where oid in (2619)
oid | relname
-------+----------------------------------
2619 | pg_statistic
找这个统计信息基表无可厚非,因为pg在生成可能的执行计划s时需要用到统计信息来估算代价。
pg_statistic的膨胀
定位到pg_statistic,那么看下pg_statistic表的情况
> \dt+ pg_statistic
List of relations
Schema | Name | Type | Owner | Persistence | Size | Description
------------+--------------+-------+----------+-------------+---------+-------------
pg_catalog | pg_statistic | table | postgres | permanent | 1036 MB |
> select * from pg_class where relname='pg_statistic'\gx
-[ RECORD 1 ]-------+------------------------------------------------
oid | 2619
relname | pg_statistic
relnamespace | 11
reltype | 12016
reloftype | 0
relowner | 10
relam | 2
relfilenode | 2619
reltablespace | 0
relpages | 132481
reltuples | 4655
pg_statistic有1G,确实有些大了, 有132481块却只有4655行,这明显是有表膨胀了。但是即便有表膨胀,访问统计信息需要cache整个pg_statistic吗?逻辑上来说不需要,因为只需要访问对应表的统计信息就行了,实际上pg也是通过pg_statistic的主键索引pg_statistic_relid_att_inh_index来访问的。从下面的从堆栈中能看到传入的是pg_statistic的复合主键上的字段:
bt
...
#6 0x000000000086edbc in SearchCatCacheMiss (cache=cache@entry=0x226ba80, nkeys=nkeys@entry=3, hashValue=hashValue@entry=853716409, hashIndex=hashIndex@entry=57, v1=v1@entry=18767, v2=v2@entry=1,
v3=v3@entry=0, v4=v4@entry=0) at catcache.c:1368
#7 0x000000000086fa82 in SearchCatCacheInternal (v4=0, v3=<optimized out>, v2=<optimized out>, v1=<optimized out>, nkeys=3, cache=0x226ba80) at catcache.c:1299
#8 SearchCatCache3 (cache=0x226ba80, v1=v1@entry=18767, v2=v2@entry=1, v3=v3@entry=0) at catcache.c:1183
#9 0x0000000000880d70 in SearchSysCache3 (cacheId=cacheId@entry=58, key1=key1@entry=18767, key2=key2@entry=1, key3=key3@entry=0) at syscache.c:1145
#10 0x0000000000874092 in get_attavgwidth (relid=relid@entry=18767, attnum=1) at lsyscache.c:2991
#11 0x00000000006a2d46 in set_rel_width (root=root@entry=0x2326600, rel=rel@entry=0x21e8418) at costsize.c:5516
...
传入了relid=relid@entry=18767, attnum=1
select ctid,starelid,staattnum from pg_statistic where starelid=18767;
ctid | starelid | staattnum
------------+----------+-----------
(132657,6) | 18767 | 1
(132657,7) | 18767 | 2
(132657,8) | 18767 | 3
(132657,9) | 18767 | 4
(132658,1) | 18767 | 5
(132658,2) | 18767 | 6
(132658,3) | 18767 | 7
(132658,4) | 18767 | 8
(132658,5) | 18767 | 9
(132658,6) | 18767 | 10
--lzlinfo总共10个字段,每个字段对应一个staattnum
通过ctid可以看出,这些数据实际上只在2个块中。
看下通过复合主键索引访问pg_statistic,结果发现哪怕在只有2个块,也要访问1s,shared hit高达100w(1141568):
explain (analyze,buffers,timing,verbose) select ctid,starelid from pg_statistic where starelid=18767;
QUERY PLAN
--------------------------------------------------------------------------------------------------------------------------------------------------------------------
Index Scan using pg_statistic_relid_att_inh_index on pg_catalog.pg_statistic (cost=0.41..103.31 rows=23 width=10) (actual time=105.416..1035.723 rows=10 loops=1)
Output: ctid, starelid
Index Cond: (pg_statistic.starelid = '18767'::oid)
Buffers: shared hit=1141568 --异常
Planning:
Buffers: shared hit=8
Planning Time: 0.102 ms
Execution Time: 1035.802 ms
通过索引访问10条pg_statistic数据,shared hit有100w,跟SQL的100w planning shared hit差不多。(注意这里的 Planning Time很少,说明我们没有在生成执行计划阶段出问题)
索引dead tuple
如果vacuum没有真的“跑起来”,那么索引的dead tuple还是会指向死元组
参考从很慢的唯一索引扫描到索引膨胀
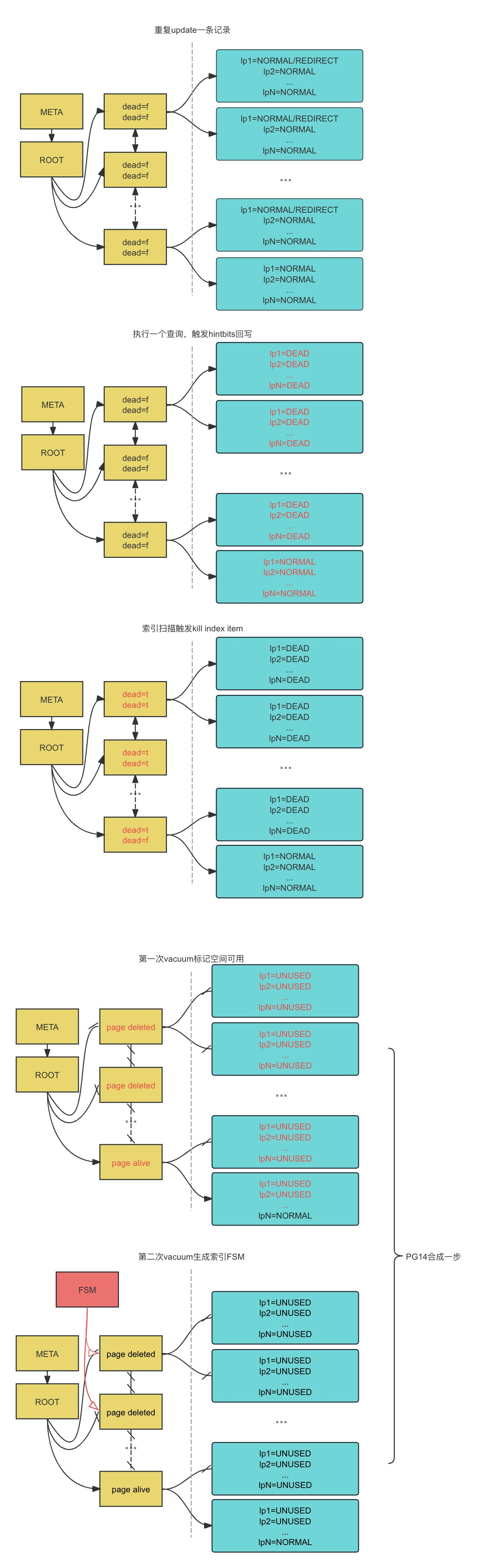
autovacuum未回收死元组
表膨胀这么大,autovacuum不应该回收吗?
select * from pg_stat_all_tables where relname='pg_statistic'\gx
-[ RECORD 1 ]-------+------------------------------
relid | 2619
schemaname | pg_catalog
relname | pg_statistic
seq_scan | 1 --顺序访问pg_statistic极少
seq_tup_read | 4655
idx_scan | 28715508 --索引访问pg_statistic多
idx_tup_fetch | 25150245
n_tup_ins | 46
n_tup_upd | 1292143 --update很多
n_tup_del | 14
n_tup_hot_upd | 138448
n_live_tup | 4655
n_dead_tup | 1496776
n_mod_since_analyze | 1292203
n_ins_since_vacuum | 0
last_vacuum | [null]
last_autovacuum | 2024-08-16 20:34:15.045022+08 --注意autovacuum的时间是一个最近的值
last_analyze | [null]
last_autoanalyze | [null]
vacuum_count | 0
autovacuum_count | 144170
analyze_count | 0
autoanalyze_count | 0
其实pg_statistic上是autovacuum一直在跑,只不过进程有可能看不到,因为autovacuum没有跑什么,所以跑的比较快,跑完又snap休息了
show autovacuum_naptime ;
autovacuum_naptime
--------------------
1min
每间隔1分钟休息一次,日志中也是每隔1分钟打印一次autovacuum信息。
2024-08-16 21:05:15.267 CST,,,41080,,66bf4e87.a078,1,,2024-08-16 21:05:11 CST,27/166839,0,LOG,00000,"automatic vacuum of table ""lzldb.pg_catalog.pg_statistic"": index scans: 0
pages: 0 removed, 132685 remain, 1 skipped due to pins, 0 skipped frozen
tuples: 0 removed, 1501745 remain, 1497090 are dead but not yet removable, oldest xmin: 119329380
buffer usage: 265443 hits, 0 misses, 0 dirtied
avg read rate: 0.000 MB/s, avg write rate: 0.000 MB/s
system usage: CPU: user: 0.53 s, system: 0.17 s, elapsed: 3.38 s
WAL usage: 1 records, 0 full page images, 233 bytes",,,,,,,,,"","autovacuum worker"
2024-08-16 21:05:17.474 CST,,,41080,,66bf4e87.a078,2,,2024-08-16 21:05:11 CST,27/166844,136438968,LOG,00000,"automatic analyze of table ""lzldb.public.lzlinfo"" system usage: CPU: user: 2.02 s, system: 0.00 s, elapsed: 2.08 s",,,,,,,,,"","autovacuum worker"
"
1497090 are dead but not yet removable虽然触发了autovacuum但是根本没有回收到死元组,1497090条死元组没有清理。
排查下库内是谁持有了oldest xmin: 119329380,很快可以定位到复制槽:
select * from pg_replication_slots;
slot_name | plugin | slot_type | datoid | database | temporary | active | active_pid | xmin | catalog_xmin | restart_lsn | confirmed_flush_lsn | wal_status | safe_wal_size
-----------------+----------+-----------+--------+----------+-----------+--------+------------+--------+--------------+--------------+---------------------+------------+---------------
slotslotlostname | pgoutput | logical | 17076 | lzldb | f | f | [null] | [null] | 119329380 | 3F9/105A4970 | 3F9/105F8778 | extended | [null]
slot的catalog_xmin=119329380,与vacuum展示的oldest xmin: 119329380一致。
active=f说明复制链路已经挂了。
修复问题
把复制槽删除:
select pg_drop_replication_slot('slotslotlostname');
pg_drop_replication_slot
--------------------------
手动vacuum或再等待1分钟autovacuum。
最后再开一个全新的会话测试一下恢复没有:
# psql
psql (13.2)
Type "help" for help.
> \c lzldb
You are now connected to database "lzldb" as user "postgres".
> explain (analyze,buffers,timing) select * from lzlinfo limit 1;
QUERY PLAN
---------------------------------------------------------------------------------------------------------------------
Limit (cost=0.00..8.04 rows=1 width=71) (actual time=0.023..0.025 rows=1 loops=1)
Buffers: shared hit=1
-> Seq Scan on lzlinfo (cost=0.00..3802.73 rows=473 width=71) (actual time=0.018..0.018 rows=1 loops=1)
Buffers: shared hit=1
Planning:
Buffers: shared hit=2578
Planning Time: 9.605 ms
Execution Time: 0.098 ms
耗时从1s下降到10ms,Planning shared hit从100w下降到2k,问题基本解决。
案例总结
复制链路挂掉,复制槽未及时清理,导致pg_statistic统计信息基表膨胀,导致每个backend在首次加载统计信息时都非常缓慢且读取多余的page到本地缓存,导致每个backend的缓存都大于正常水平(2g左右),多个backend导致最后的OOM。
其实问题很简单,只是过程比较曲折···简言之:基表pg_statistic膨胀导致执行计划生成阶段访问数据过大。元数据基表膨胀其实还有其他棘手的问题,有缘再见了。