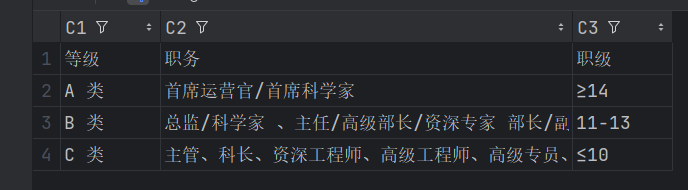
表格解析调研
TextInTools
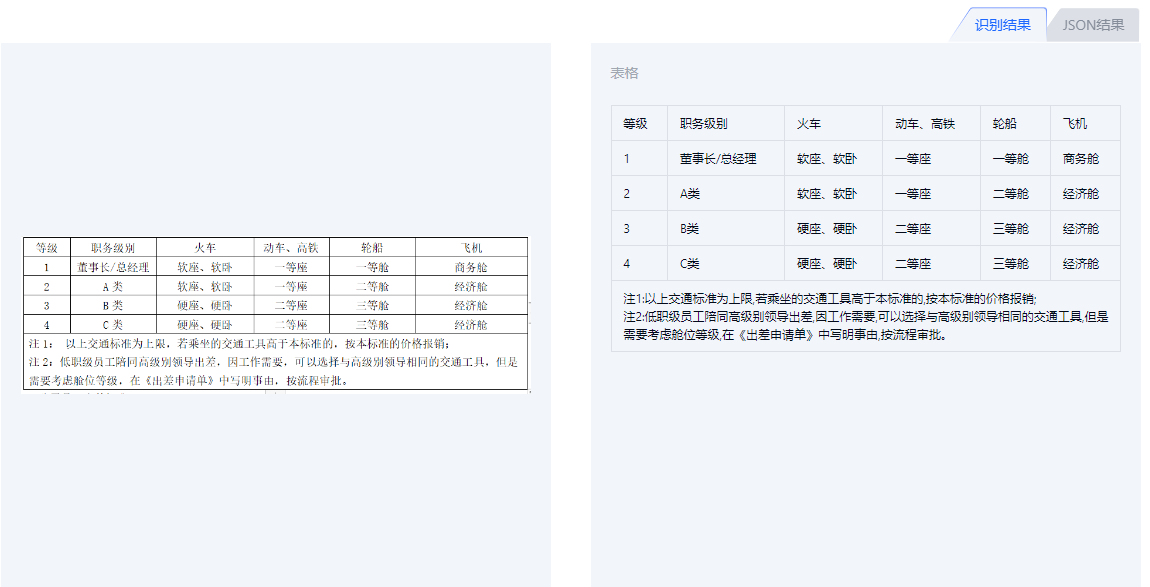
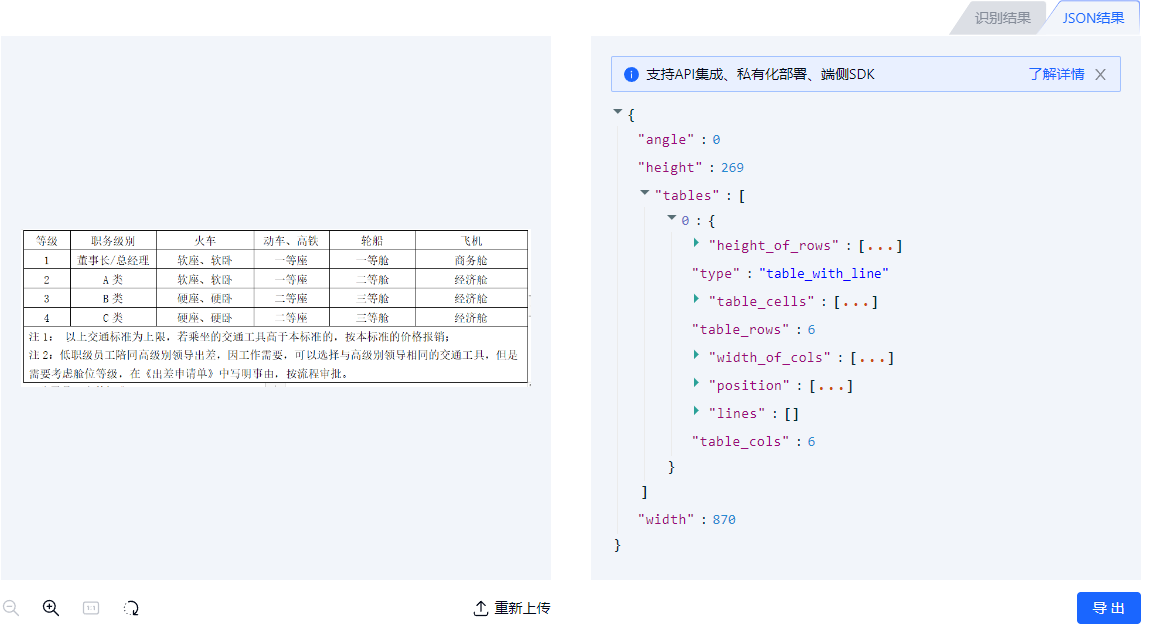
TextInTools:https://tools.textin.com/table
可以将表格图片解析成可编辑的表格/json,效果不错
白描
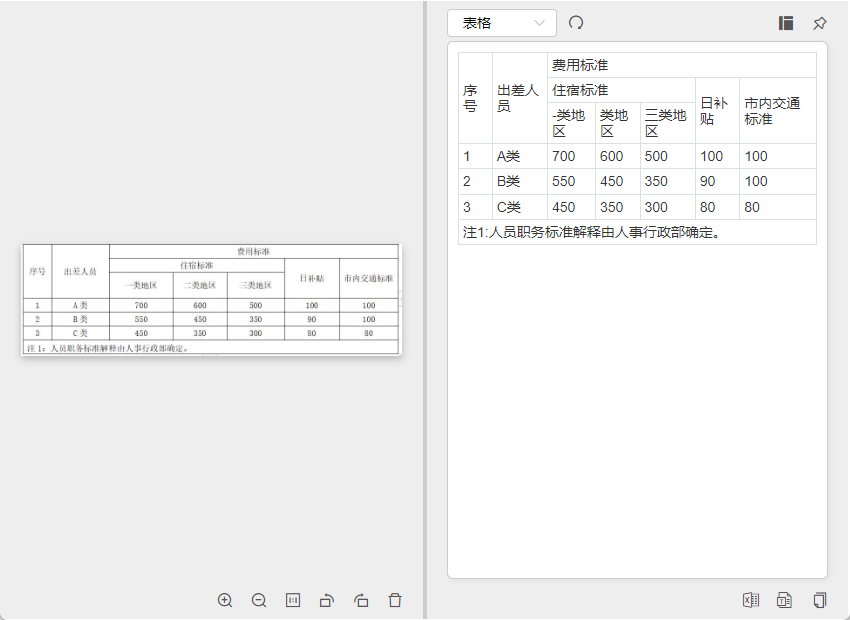
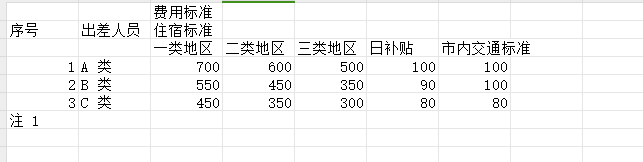
地址:https://web.baimiaoapp.com/image-to-excel
可以将表格图片识别成可编辑的表格,可复制、导出为xlsx、txt。效果不错,但是免费有额度
i2PDF
地址:https://www.i2pdf.com/cn/extract-tables-from-pdf
可以对pdf进行多种处理,提取表格效果不错,并且可以选择导出的格式,效果不错

Tabula-PDF
项目地址:https://github.com/tabulapdf/tabula
用于从PDF文档中识别和提取表格数据。它利用机器学习算法和计算机视觉技术,能够准确地识别PDF页面中的表格,并将其转换为结构化数据。Tabula-PDF会将识别到的表格转换为结构化数据,如CSV、Excel、json等格式。效果一般
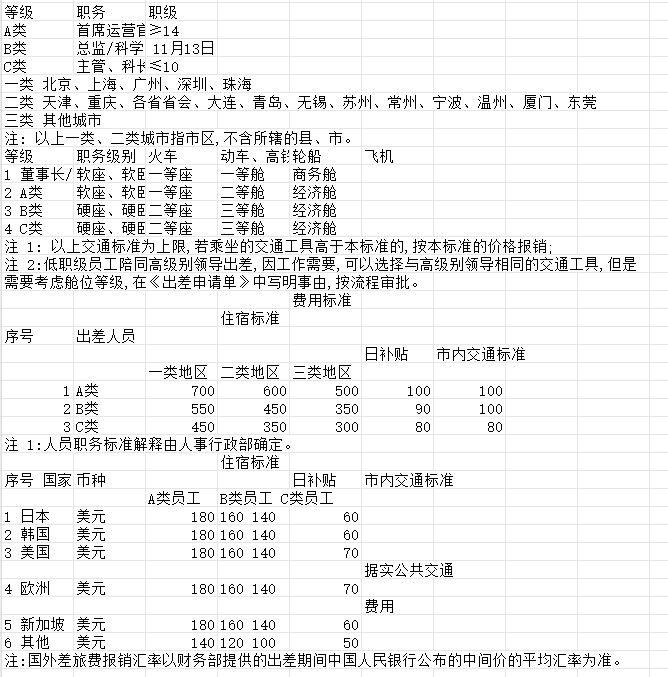
pdflux
项目地址:https://pdflux.com/
效果不错,会有免费额度

iLoveOCR
地址:https://cn.iloveocr.com/
效果一般
ocr2edit
地址:https://www.ocr2edit.com/zh
识别效果不好
py代码
使用python-docx库
python代码实现将word中的表格解析出来
from docx import Document
doc = Document('example.docx')
for table in doc.tables:
for row in table.rows:
cells = [cell.text for cell in row.cells]
print(cells)
使用PyMuPDF库
需要安装PyMuPDF,可以用来提取pdf内容,并且可以查找页面的表格。效果不错
import fitz
doc = fitz.open('../example.pdf')
page = doc[2] # 下标从0开始
tables = page.find_tables()
df = tables[1].to_pandas()
df.to_excel('table.xlsx', index=False)
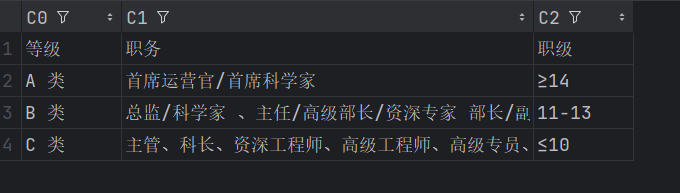
使用pdfplumber库
使用pdfplumber实现将pdf中的表格解析出来,效果一般,示例代码如下:
import pdfplumber
import pandas as pd
with pdfplumber.open("../example.pdf") as pdf:
page = pdf.pages[3]
for table in page.extract_tables():
df = pd.DataFrame(table[1:], columns=table[0])
df.to_excel('table.xlsx', index=False)
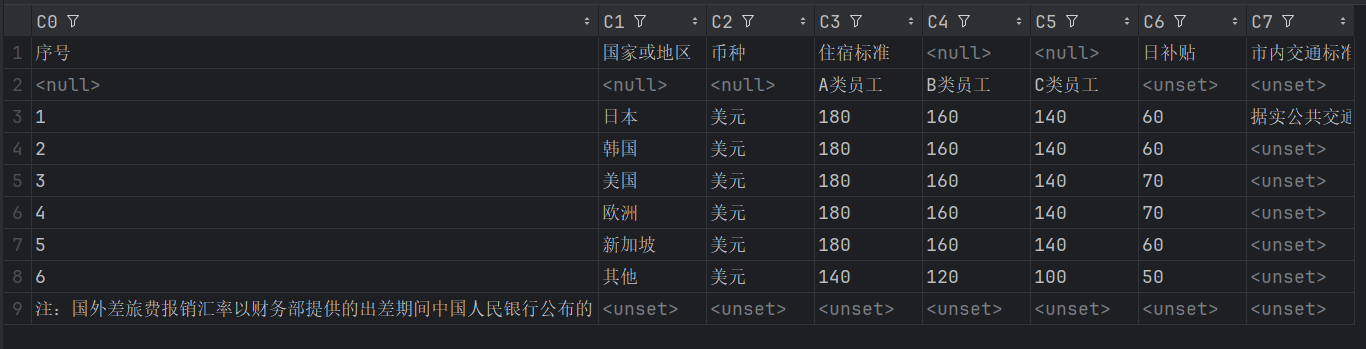
使用camelot库
camelot专门用于从 PDF 文件中提取表格数据。效果不错
import camelot
tables = camelot.read_pdf('../example.pdf')
tables.export('result.csv', f='csv', compress=True) # json, excel, html, markdown, sqlite
print(tables[0].parsing_report)
tables[0].to_csv('result.csv') # to_json, to_excel, to_html, to_markdown, to_sqlite