快速上手大模型基于langchain实现RAG检索应用 - 项目作业
目录
- 准备工作
- 镜像选择
- 算力选择
- 安装包
- 数据说明
- 提示
- 参考链接
- Task1 申请 api 后,使用 langchain 导入大模型,并打印出大模型信息
- Task2 使用 langchian 加载数据,并把数据打印出来
- Task3 使用 faiss 进行存储,将向量数据库及加载的向量化模型信息打印出来。
- Task4 根据使用的数据设置一个问题,调用大模型,让大模型进行回答,打印出大模型回答结果
- Task5 参考 langchian 文档任意选一种检索方法,先检索后再让大模型去回答,打印出大模型回答效果,对比与 Task4 的结果是否有区别
- 回答1及点评:
- 回答2及点评:
- 回答3及点评:
- 回答4及点评:
- 回答5及点评:
- 回答6及点评:
- 回答7及点评: 较好的回答,打印所有召回方法,选最好的用
注意本项目是在和鲸的虚拟环境上运行的,和本地实际部署流程可能会有差异 ,项目的难点在于选择合适的召回函数,文档中配置安装会占据较大篇幅,直接浏览代码部分就好。
计算资源:T4 GPU
使用镜像:3.11.8 LangChain 0.16 Ubuntu 22.04
项目原链接
参考项目1
参考项目2
准备工作
镜像选择
在 ModelWhale 工作台,在更多,搜索 langchain 添加镜像:

添加成功,可以在我的镜像中看到添加的镜像:
运行此作业使用此镜像运行,此镜像为 gpu 镜像,已经装好了 langchian 的一些包。
算力选择
运行此作业使用算力如下图:
安装包
直接运行以下命令安装一些依赖包
如果失败错尝试几次,总会安装成功的。
或者切换镜像源也是可以的。
!pip install -i https://mirrors.aliyun.com/pypi/simple langchain langchain_community langchain_core sentence-transformers dashscope
Looking in indexes: https://mirrors.aliyun.com/pypi/simple
Requirement already satisfied: langchain in /opt/conda/lib/python3.11/site-packages (0.1.16)
Requirement already satisfied: langchain_community in /opt/conda/lib/python3.11/site-packages (0.0.34)
Requirement already satisfied: langchain_core in /opt/conda/lib/python3.11/site-packages (0.1.45)
Collecting sentence-transformers
Downloading https://mirrors.aliyun.com/pypi/packages/58/4b/922436953394e1bfda05e4bf1fe0e80f609770f256c59a9df7a9254f3e0d/sentence_transformers-3.0.1-py3-none-any.whl (227 kB)
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 227.1/227.1 kB 203.2 kB/s eta 0:00:00a 0:00:01
Collecting dashscope
Downloading https://mirrors.aliyun.com/pypi/packages/2b/23/b517bbd33577d37142e5ebbdfed369637785a12a1b1b22fbdcbb8cada3d1/dashscope-1.20.4-py3-none-any.whl (1.3 MB)
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 1.3/1.3 MB 200.4 kB/s eta 0:00:0000:0100:01
Requirement already satisfied: PyYAML>=5.3 in /opt/conda/lib/python3.11/site-packages (from langchain) (6.0.1)
Requirement already satisfied: SQLAlchemy<3,>=1.4 in /opt/conda/lib/python3.11/site-packages (from langchain) (2.0.29)
Requirement already satisfied: aiohttp<4.0.0,>=3.8.3 in /opt/conda/lib/python3.11/site-packages (from langchain) (3.9.5)
Requirement already satisfied: dataclasses-json<0.7,>=0.5.7 in /opt/conda/lib/python3.11/site-packages (from langchain) (0.6.4)
Requirement already satisfied: jsonpatch<2.0,>=1.33 in /opt/conda/lib/python3.11/site-packages (from langchain) (1.33)
Requirement already satisfied: langchain-text-splitters<0.1,>=0.0.1 in /opt/conda/lib/python3.11/site-packages (from langchain) (0.0.1)
Requirement already satisfied: langsmith<0.2.0,>=0.1.17 in /opt/conda/lib/python3.11/site-packages (from langchain) (0.1.50)
Requirement already satisfied: numpy<2,>=1 in /opt/conda/lib/python3.11/site-packages (from langchain) (1.26.4)
Requirement already satisfied: pydantic<3,>=1 in /opt/conda/lib/python3.11/site-packages (from langchain) (2.7.1)
Requirement already satisfied: requests<3,>=2 in /opt/conda/lib/python3.11/site-packages (from langchain) (2.31.0)
Requirement already satisfied: tenacity<9.0.0,>=8.1.0 in /opt/conda/lib/python3.11/site-packages (from langchain) (8.2.3)
Requirement already satisfied: packaging<24.0,>=23.2 in /opt/conda/lib/python3.11/site-packages (from langchain_core) (23.2)
Collecting transformers<5.0.0,>=4.34.0 (from sentence-transformers)
Downloading https://mirrors.aliyun.com/pypi/packages/62/c0/810e741a6244c0f004be40ccb96486d072f042eabbd4d7e8aa02b81ca1eb/transformers-4.44.0-py3-none-any.whl (9.5 MB)
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 9.5/9.5 MB 240.3 kB/s eta 0:00:0000:0100:01
Requirement already satisfied: tqdm in /opt/conda/lib/python3.11/site-packages (from sentence-transformers) (4.66.2)
Requirement already satisfied: torch>=1.11.0 in /opt/conda/lib/python3.11/site-packages (from sentence-transformers) (2.2.2+cu121)
Requirement already satisfied: scikit-learn in /opt/conda/lib/python3.11/site-packages (from sentence-transformers) (1.4.2)
Requirement already satisfied: scipy in /opt/conda/lib/python3.11/site-packages (from sentence-transformers) (1.13.0)
Requirement already satisfied: huggingface-hub>=0.15.1 in /opt/conda/lib/python3.11/site-packages (from sentence-transformers) (0.22.2)
Requirement already satisfied: Pillow in /opt/conda/lib/python3.11/site-packages (from sentence-transformers) (10.3.0)
Requirement already satisfied: websocket-client in /opt/conda/lib/python3.11/site-packages (from dashscope) (1.8.0)
Requirement already satisfied: aiosignal>=1.1.2 in /opt/conda/lib/python3.11/site-packages (from aiohttp<4.0.0,>=3.8.3->langchain) (1.3.1)
Requirement already satisfied: attrs>=17.3.0 in /opt/conda/lib/python3.11/site-packages (from aiohttp<4.0.0,>=3.8.3->langchain) (23.2.0)
Requirement already satisfied: frozenlist>=1.1.1 in /opt/conda/lib/python3.11/site-packages (from aiohttp<4.0.0,>=3.8.3->langchain) (1.4.1)
Requirement already satisfied: multidict<7.0,>=4.5 in /opt/conda/lib/python3.11/site-packages (from aiohttp<4.0.0,>=3.8.3->langchain) (6.0.5)
Requirement already satisfied: yarl<2.0,>=1.0 in /opt/conda/lib/python3.11/site-packages (from aiohttp<4.0.0,>=3.8.3->langchain) (1.9.4)
Requirement already satisfied: marshmallow<4.0.0,>=3.18.0 in /opt/conda/lib/python3.11/site-packages (from dataclasses-json<0.7,>=0.5.7->langchain) (3.21.1)
Requirement already satisfied: typing-inspect<1,>=0.4.0 in /opt/conda/lib/python3.11/site-packages (from dataclasses-json<0.7,>=0.5.7->langchain) (0.9.0)
Requirement already satisfied: filelock in /opt/conda/lib/python3.11/site-packages (from huggingface-hub>=0.15.1->sentence-transformers) (3.13.4)
Requirement already satisfied: fsspec>=2023.5.0 in /opt/conda/lib/python3.11/site-packages (from huggingface-hub>=0.15.1->sentence-transformers) (2024.3.1)
Requirement already satisfied: typing-extensions>=3.7.4.3 in /opt/conda/lib/python3.11/site-packages (from huggingface-hub>=0.15.1->sentence-transformers) (4.11.0)
Requirement already satisfied: jsonpointer>=1.9 in /opt/conda/lib/python3.11/site-packages (from jsonpatch<2.0,>=1.33->langchain) (2.4)
Requirement already satisfied: orjson<4.0.0,>=3.9.14 in /opt/conda/lib/python3.11/site-packages (from langsmith<0.2.0,>=0.1.17->langchain) (3.10.1)
Requirement already satisfied: annotated-types>=0.4.0 in /opt/conda/lib/python3.11/site-packages (from pydantic<3,>=1->langchain) (0.6.0)
Requirement already satisfied: pydantic-core==2.18.2 in /opt/conda/lib/python3.11/site-packages (from pydantic<3,>=1->langchain) (2.18.2)
Requirement already satisfied: charset-normalizer<4,>=2 in /opt/conda/lib/python3.11/site-packages (from requests<3,>=2->langchain) (3.3.2)
Requirement already satisfied: idna<4,>=2.5 in /opt/conda/lib/python3.11/site-packages (from requests<3,>=2->langchain) (3.7)
Requirement already satisfied: urllib3<3,>=1.21.1 in /opt/conda/lib/python3.11/site-packages (from requests<3,>=2->langchain) (2.2.1)
Requirement already satisfied: certifi>=2017.4.17 in /opt/conda/lib/python3.11/site-packages (from requests<3,>=2->langchain) (2024.2.2)
Requirement already satisfied: greenlet!=0.4.17 in /opt/conda/lib/python3.11/site-packages (from SQLAlchemy<3,>=1.4->langchain) (3.0.3)
Requirement already satisfied: sympy in /opt/conda/lib/python3.11/site-packages (from torch>=1.11.0->sentence-transformers) (1.12)
Requirement already satisfied: networkx in /opt/conda/lib/python3.11/site-packages (from torch>=1.11.0->sentence-transformers) (3.3)
Requirement already satisfied: jinja2 in /opt/conda/lib/python3.11/site-packages (from torch>=1.11.0->sentence-transformers) (3.1.3)
Requirement already satisfied: nvidia-cuda-nvrtc-cu12==12.1.105 in /opt/conda/lib/python3.11/site-packages (from torch>=1.11.0->sentence-transformers) (12.1.105)
Requirement already satisfied: nvidia-cuda-runtime-cu12==12.1.105 in /opt/conda/lib/python3.11/site-packages (from torch>=1.11.0->sentence-transformers) (12.1.105)
Requirement already satisfied: nvidia-cuda-cupti-cu12==12.1.105 in /opt/conda/lib/python3.11/site-packages (from torch>=1.11.0->sentence-transformers) (12.1.105)
Requirement already satisfied: nvidia-cudnn-cu12==8.9.2.26 in /opt/conda/lib/python3.11/site-packages (from torch>=1.11.0->sentence-transformers) (8.9.2.26)
Requirement already satisfied: nvidia-cublas-cu12==12.1.3.1 in /opt/conda/lib/python3.11/site-packages (from torch>=1.11.0->sentence-transformers) (12.1.3.1)
Requirement already satisfied: nvidia-cufft-cu12==11.0.2.54 in /opt/conda/lib/python3.11/site-packages (from torch>=1.11.0->sentence-transformers) (11.0.2.54)
Requirement already satisfied: nvidia-curand-cu12==10.3.2.106 in /opt/conda/lib/python3.11/site-packages (from torch>=1.11.0->sentence-transformers) (10.3.2.106)
Requirement already satisfied: nvidia-cusolver-cu12==11.4.5.107 in /opt/conda/lib/python3.11/site-packages (from torch>=1.11.0->sentence-transformers) (11.4.5.107)
Requirement already satisfied: nvidia-cusparse-cu12==12.1.0.106 in /opt/conda/lib/python3.11/site-packages (from torch>=1.11.0->sentence-transformers) (12.1.0.106)
Requirement already satisfied: nvidia-nccl-cu12==2.19.3 in /opt/conda/lib/python3.11/site-packages (from torch>=1.11.0->sentence-transformers) (2.19.3)
Requirement already satisfied: nvidia-nvtx-cu12==12.1.105 in /opt/conda/lib/python3.11/site-packages (from torch>=1.11.0->sentence-transformers) (12.1.105)
Requirement already satisfied: triton==2.2.0 in /opt/conda/lib/python3.11/site-packages (from torch>=1.11.0->sentence-transformers) (2.2.0)
Requirement already satisfied: nvidia-nvjitlink-cu12 in /opt/conda/lib/python3.11/site-packages (from nvidia-cusolver-cu12==11.4.5.107->torch>=1.11.0->sentence-transformers) (12.4.127)
Collecting huggingface-hub>=0.15.1 (from sentence-transformers)
Downloading https://mirrors.aliyun.com/pypi/packages/b9/8f/d6718641c14d98a5848c6a24d2376028d292074ffade0702940a4b1dde76/huggingface_hub-0.24.6-py3-none-any.whl (417 kB)
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 417.5/417.5 kB 167.3 kB/s eta 0:00:0000:0100:01
Collecting regex!=2019.12.17 (from transformers<5.0.0,>=4.34.0->sentence-transformers)
Downloading https://mirrors.aliyun.com/pypi/packages/8b/77/92d4a14530900d46dddc57b728eea65d723cc9fcfd07b96c2c141dabba84/regex-2024.7.24-cp311-cp311-manylinux_2_17_x86_64.manylinux2014_x86_64.whl (786 kB)
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 786.6/786.6 kB 241.9 kB/s eta 0:00:0000:0100:01
Collecting safetensors>=0.4.1 (from transformers<5.0.0,>=4.34.0->sentence-transformers)
Downloading https://mirrors.aliyun.com/pypi/packages/af/b9/c33f69f4dad9c65209efb76c2be6968af5219e31ccfd344a0025d972252f/safetensors-0.4.4-cp311-cp311-manylinux_2_17_x86_64.manylinux2014_x86_64.whl (435 kB)
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 435.4/435.4 kB 236.7 kB/s eta 0:00:0000:0100:01
Requirement already satisfied: tokenizers<0.20,>=0.19 in /opt/conda/lib/python3.11/site-packages (from transformers<5.0.0,>=4.34.0->sentence-transformers) (0.19.1)
Requirement already satisfied: joblib>=1.2.0 in /opt/conda/lib/python3.11/site-packages (from scikit-learn->sentence-transformers) (1.4.0)
Requirement already satisfied: threadpoolctl>=2.0.0 in /opt/conda/lib/python3.11/site-packages (from scikit-learn->sentence-transformers) (3.4.0)
Requirement already satisfied: mypy-extensions>=0.3.0 in /opt/conda/lib/python3.11/site-packages (from typing-inspect<1,>=0.4.0->dataclasses-json<0.7,>=0.5.7->langchain) (1.0.0)
Requirement already satisfied: MarkupSafe>=2.0 in /opt/conda/lib/python3.11/site-packages (from jinja2->torch>=1.11.0->sentence-transformers) (2.1.5)
Requirement already satisfied: mpmath>=0.19 in /opt/conda/lib/python3.11/site-packages (from sympy->torch>=1.11.0->sentence-transformers) (1.3.0)
Installing collected packages: safetensors, regex, huggingface-hub, dashscope, transformers, sentence-transformers
Attempting uninstall: huggingface-hub
Found existing installation: huggingface-hub 0.22.2
Uninstalling huggingface-hub-0.22.2:
Successfully uninstalled huggingface-hub-0.22.2
Successfully installed dashscope-1.20.4 huggingface-hub-0.24.6 regex-2024.7.24 safetensors-0.4.4 sentence-transformers-3.0.1 transformers-4.44.0
数据说明
给大家准备了两份数据,大家可以选择其中一个数据完成即可:
1、/home/mw/input/rag2153/专业描述.csv
假如你是高三毕业学生,面临选择专业,已经知道了一些专业的大概描述,但并不知道具体专业名称,通过大模型输入描述,让大模型推荐你具体的专业名称;
2、/home/mw/input/rag2153/汽车投诉数据(20240429).csv
假如你是汽车服务经理,针对近期的汽车投诉数据,想通过对话的方式能马上知道具体的投诉信息,例如:我想知道奔驰这个品牌的汽车大家投诉的点都是什么?
提示
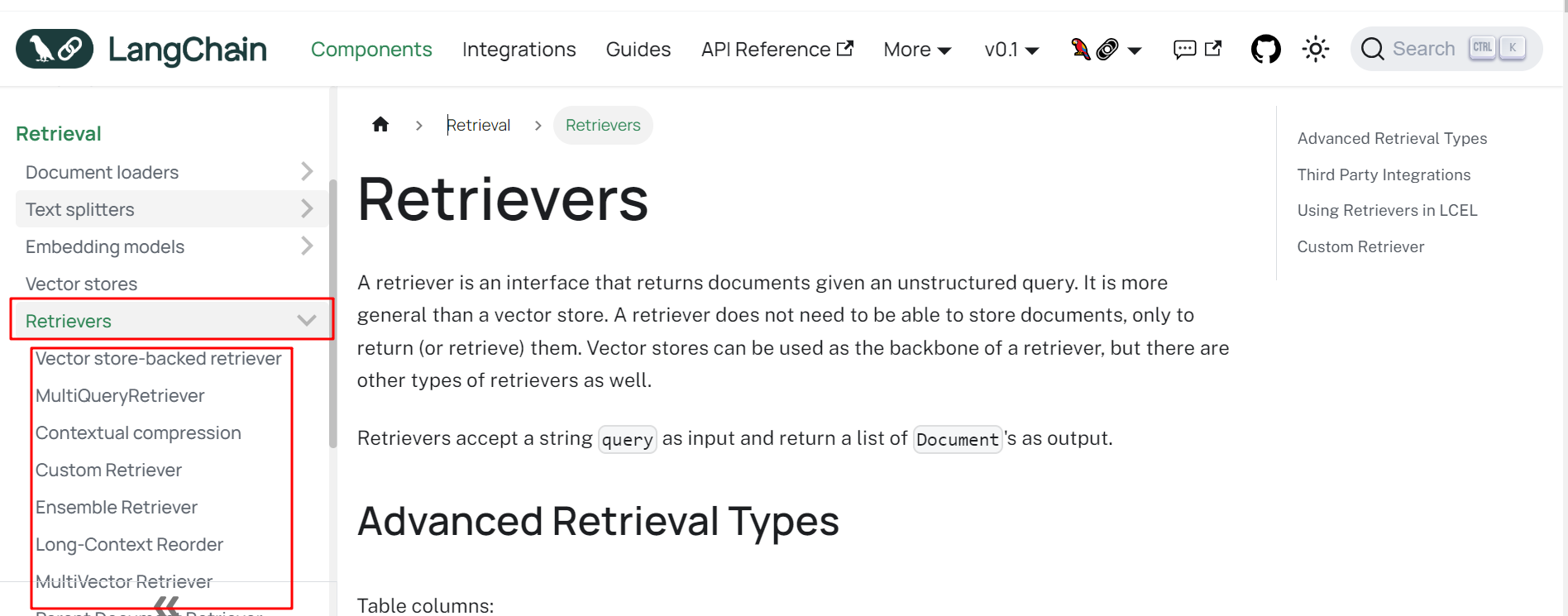
langchian 官方文档检索部分:https://python.langchain.com/v0.1/docs/modules/data_connection/retrievers/
框起来的是 langchain 检索部分的文档,可以参考自己选择一种进行实现
参考链接
https://blog.csdn.net/zjkpy_5/article/details/137725801?spm=1001.2014.3001.5501
https://github.com/5zjk5/prompt-engineering/blob/master/langchain_module.py
Task1 申请 api 后,使用 langchain 导入大模型,并打印出大模型信息
大模型 api 申请,这里大模型可以申请阿里的通义千问,新用户会有免费的调用次数赠送。(所有大模型厂商都会赠送新用户体验,也可以选择其他 langchain 支持的模型,例如智谱 GLM)
通义千问 api 创建链接:https://dashscope.console.aliyun.com/apiKey
申请 api 后,使用 langchain 导入大模型,并打印出大模型信息。
import json
import os
import pprint
from pathlib import Path
from langchain_community.document_loaders import TextLoader
from langchain_community.document_loaders.csv_loader import CSVLoader
from langchain.text_splitter import CharacterTextSplitter
from langchain_text_splitters import RecursiveCharacterTextSplitter
from langchain_text_splitters import RecursiveJsonSplitter
from langchain.embeddings import HuggingFaceEmbeddings
from langchain_community.vectorstores import FAISS
from langchain.vectorstores import Chroma
from langchain.retrievers.multi_query import MultiQueryRetriever
from langchain.retrievers import ContextualCompressionRetriever
from langchain.retrievers.document_compressors import LLMChainFilter
from langchain.retrievers.document_compressors import EmbeddingsFilter
from langchain.retrievers.document_compressors import DocumentCompressorPipeline
from langchain_community.document_transformers import EmbeddingsRedundantFilter
from langchain_community.document_transformers import LongContextReorder
from langchain_community.retrievers import BM25Retriever
from langchain.retrievers import EnsembleRetriever
from langchain.retrievers import ParentDocumentRetriever
from langchain.storage import InMemoryStore
from langchain.retrievers import KNNRetriever
from langchain.retrievers import TFIDFRetriever
from langchain_community.document_loaders import DirectoryLoader
from langchain_community.document_loaders import UnstructuredHTMLLoader
from langchain_community.document_loaders import UnstructuredMarkdownLoader
from langchain_community.document_loaders import PyPDFLoader
from langchain_community.document_loaders import PyMuPDFLoader
from langchain_community.document_loaders import PyPDFDirectoryLoader
from langchain_community.document_loaders import UnstructuredExcelLoader
from langchain_community.document_loaders import UnstructuredPowerPointLoader
from langchain_community.document_loaders import UnstructuredWordDocumentLoader
from langchain_text_splitters import HTMLHeaderTextSplitter
from langchain_text_splitters import Language
from langchain_text_splitters import MarkdownHeaderTextSplitter
# from langchain_experimental.text_splitter import SemanticChunker
from langchain_community.document_loaders import UnstructuredImageLoader
from langchain_core.prompts import PromptTemplate
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.messages import SystemMessage
from langchain_core.prompts import HumanMessagePromptTemplate
from langchain_core.prompts import ChatMessagePromptTemplate
from langchain_core.prompts import MessagesPlaceholder
from langchain_core.messages import AIMessage, HumanMessage
from langchain_core.example_selectors import LengthBasedExampleSelector
from langchain_core.prompts import FewShotPromptTemplate
from langchain_core.example_selectors import MaxMarginalRelevanceExampleSelector
from langchain_core.prompts import FewShotChatMessagePromptTemplate
from langchain_core.example_selectors import SemanticSimilarityExampleSelector
from langchain.chains import LLMChain
from langchain.output_parsers import CommaSeparatedListOutputParser
from langchain.output_parsers import DatetimeOutputParser
from langchain_core.output_parsers import JsonOutputParser
from langchain.agents import load_tools
# from langchain_experimental.utilities import PythonREPL
from langchain_community.utilities import TextRequestsWrapper
from langchain.agents import AgentType, initialize_agent
import json
import os
import pprint
from pathlib import Path
from langchain_community.document_loaders import TextLoader
from langchain_community.document_loaders.csv_loader import CSVLoader
from langchain.text_splitter import CharacterTextSplitter
from langchain_text_splitters import RecursiveCharacterTextSplitter
from langchain_text_splitters import RecursiveJsonSplitter
from langchain.embeddings import HuggingFaceEmbeddings
from langchain_community.vectorstores import FAISS
from langchain.vectorstores import Chroma
from langchain.retrievers.multi_query import MultiQueryRetriever
from langchain.retrievers import ContextualCompressionRetriever
from langchain.retrievers.document_compressors import LLMChainFilter
from langchain.retrievers.document_compressors import EmbeddingsFilter
from langchain.retrievers.document_compressors import DocumentCompressorPipeline
from langchain_community.document_transformers import EmbeddingsRedundantFilter
from langchain_community.document_transformers import LongContextReorder
from langchain_community.retrievers import BM25Retriever
from langchain.retrievers import EnsembleRetriever
from langchain.retrievers import ParentDocumentRetriever
from langchain.storage import InMemoryStore
from langchain.retrievers import KNNRetriever
from langchain.retrievers import TFIDFRetriever
from langchain_community.document_loaders import DirectoryLoader
from langchain_community.document_loaders import UnstructuredHTMLLoader
from langchain_community.document_loaders import UnstructuredMarkdownLoader
from langchain_community.document_loaders import PyPDFLoader
from langchain_community.document_loaders import PyMuPDFLoader
from langchain_community.document_loaders import PyPDFDirectoryLoader
from langchain_community.document_loaders import UnstructuredExcelLoader
from langchain_community.document_loaders import UnstructuredPowerPointLoader
from langchain_community.document_loaders import UnstructuredWordDocumentLoader
from langchain_text_splitters import HTMLHeaderTextSplitter
from langchain_text_splitters import Language
from langchain_text_splitters import MarkdownHeaderTextSplitter
# from langchain_experimental.text_splitter import SemanticChunker
from langchain_community.document_loaders import UnstructuredImageLoader
from langchain_core.prompts import PromptTemplate
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.messages import SystemMessage
from langchain_core.prompts import HumanMessagePromptTemplate
from langchain_core.prompts import ChatMessagePromptTemplate
from langchain_core.prompts import MessagesPlaceholder
from langchain_core.messages import AIMessage, HumanMessage
from langchain_core.example_selectors import LengthBasedExampleSelector
from langchain_core.prompts import FewShotPromptTemplate
from langchain_core.example_selectors import MaxMarginalRelevanceExampleSelector
from langchain_core.prompts import FewShotChatMessagePromptTemplate
from langchain_core.example_selectors import SemanticSimilarityExampleSelector
from langchain.chains import LLMChain
from langchain.output_parsers import CommaSeparatedListOutputParser
from langchain.output_parsers import DatetimeOutputParser
from langchain_core.output_parsers import JsonOutputParser
from langchain.agents import load_tools
# from langchain_experimental.utilities import PythonREPL
from langchain_community.utilities import TextRequestsWrapper
from langchain.agents import AgentType, initialize_agent
# Your Answer
import os
from transformers import AutoModelForCausalLM, AutoTokenizer # 本地模型所需的库
from transformers.generation import GenerationConfig # 本地模型所需的库
from langchain_community.llms import Tongyi
from langchain_community.llms import QianfanLLMEndpoint
from transformers import pipeline # 本地模型所需的库
from langchain import HuggingFacePipeline # 用于本地模型加载
# from langchain_openai import ChatOpenAI
# 设置环境变量
os.environ['DASHSCOPE_API_KEY'] = 'sk-d47c2df58a62486ba407cce041974d22'
os.environ['QIANFAN_AK'] = 'your_qianfan_ak'
os.environ['QIANFAN_SK'] = 'your_qianfan_sk'
os.environ['ZHIPUAI_API_KEY'] = 'your_zhipuai_api_key'
class LLM():
def __init__(self):
self.DASHSCOPE_API_KEY = os.getenv('DASHSCOPE_API_KEY')
self.QIANFAN_AK = os.getenv('QIANFAN_AK')
self.QIANFAN_SK = os.getenv('QIANFAN_SK')
self.ZHIPUAI_API_KEY = os.getenv('ZHIPUAI_API_KEY')
def tongyi_qwen_plus(self, temperature=1):
# 通义 qwen_plus
model = Tongyi(temperature=temperature, model_name='qwen-plus', dashscope_api_key=self.DASHSCOPE_API_KEY)
return model
def tongyi_qwen_turbo(self, temperature=1):
# 通义 qwen-turbo
model = Tongyi(temperature=temperature, model_name='qwen-turbo', dashscope_api_key=self.DASHSCOPE_API_KEY)
return model
def tongyi_qwen_7b_chat(self, temperature=1):
# 通义 qwen_7b_chat
model = Tongyi(temperature=temperature, model_name='qwen-7b-chat', dashscope_api_key=self.DASHSCOPE_API_KEY)
return model
def tongyi_qwen_14b_chat(self, temperature=1):
# 通义 qwen_14b_chat
model = Tongyi(temperature=temperature, model_name='qwen-14b-chat', dashscope_api_key=self.DASHSCOPE_API_KEY)
return model
def wenxin_ERNIE_Speed_128K(self):
# 文心 ERNIE_Speed_128K
model = QianfanLLMEndpoint(streaming=True, model='ERNIE-Speed-128K', qianfan_ak=self.QIANFAN_AK,
qianfan_sk=self.QIANFAN_SK)
return model
def wenxin_ERNIE_Speed_8K(self):
# 文心 ERNIE_Speed_8K
model = QianfanLLMEndpoint(streaming=True, model='ERNIE-Speed-8K', qianfan_ak=self.QIANFAN_AK,
qianfan_sk=self.QIANFAN_SK)
return model
def wenxin_ERNIE_Speed_AppBuilder(self):
# 文心 ERNIE Speed-AppBuilder
model = QianfanLLMEndpoint(streaming=True, model='ERNIE-Speed-8K', qianfan_ak=self.QIANFAN_AK,
qianfan_sk=self.QIANFAN_SK)
return model
def wenxin_ERNIE_Lite_8K(self):
# 文心 ERNIE-Lite-8K
model = QianfanLLMEndpoint(streaming=True, model='ERNIE-Speed-8K', qianfan_ak=self.QIANFAN_AK,
qianfan_sk=self.QIANFAN_SK)
return model
def zhipu_glm_3_turbo(self, temperature=0.9):
# 智谱的 temperature 最高不能 >= 1
model = ChatOpenAI(temperature=temperature, model="glm-3-turbo",
openai_api_key=self.ZHIPUAI_API_KEY,
openai_api_base="https://open.bigmodel.cn/api/paas/v4/"
)
return model
def zhipu_glm_4(self, temperature=0.9):
# 智谱的 temperature 最高不能 >= 1
model = ChatOpenAI(temperature=temperature, model="glm-4",
openai_api_key=self.ZHIPUAI_API_KEY,
openai_api_base="https://open.bigmodel.cn/api/paas/v4/"
)
return model
def local_llm(self, model_path, temperature=0.6):
tokenizer = AutoTokenizer.from_pretrained(model_path, trust_remote_code=True)
model = AutoModelForCausalLM.from_pretrained(model_path, device_map="auto", trust_remote_code=True).eval()
model.generation_config = GenerationConfig.from_pretrained(model_path, trust_remote_code=True,
temperature=temperature)
pipe = pipeline(
"text-generation",
model=model,
tokenizer=tokenizer,
# max_length=4096,
# max_tokens=4096,
max_new_tokens=512,
top_p=1,
repetition_penalty=1.15
)
model = HuggingFacePipeline(pipeline=pipe)
return model
llm = LLM()
tongyi_model = llm.tongyi_qwen_plus(temperature=1) # 调用通义千问 7B Chat 模型并打印信息
print(tongyi_model)
Tongyi
Params: {'model_name': 'qwen-plus'}
Task2 使用 langchian 加载数据,并把数据打印出来
使用 langchian 加载数据,并把数据打印出来
# Your Answer
class DocsLoader():
@classmethod
def txt_loader(cls, filepath):
"""
加载 txt 数据
:param filepath:
:return:
"""
loader = TextLoader(filepath, encoding='utf8')
docs = loader.load()
return docs
@classmethod
def csv_loader(cls, filepath):
"""
https://python.langchain.com/docs/modules/data_connection/document_loaders/csv/
可用参数解释:https://blog.csdn.net/zjkpy_5/article/details/137727850?spm=1001.2014.3001.5501
加载 csv 数据
:param filepath:
:return:
"""""
loader = CSVLoader(file_path=filepath, encoding='utf8')
docs = loader.load()
return docs
@classmethod
def json_loader(cls, filepath):
"""
https://python.langchain.com/docs/modules/data_connection/document_loaders/json/
官网 jq 用不了 win 系统
加载 json 数据
:param filepath:
:return:
"""
docs = json.loads(Path(filepath).read_text(encoding='utf8'))
return docs
@classmethod
def file_directory_loader(cls, filepath, glob="**/[!.]*", loader_cls=TextLoader, silent_errors=False, show_progress=True,
use_multithreading=True, max_concurrency=4, exclude=[], recursive=True):
"""
https://python.langchain.com/docs/modules/data_connection/document_loaders/file_directory/
根据目录加载里面所有数据,不会加载文件.rst或.html文件
:param filepath:
:param glob: 默认加载所有非隐藏文件
*.txt:只加载所有 txt
:param loader_cls: 加载器,默认是 UnstructuredFileLoader,可以指定文本加载器(TextLoader)避免编码报错
:param autodetect_encoding: 自动检测编码
:param silent_errors: 跳过无法加载的文件并继续加载过程
:param show_progress: 显示进度条
:param use_multithreading: 多线程开启加载
:param max_concurrency: 线程数量
:param exclude: 指定不加的文件格式,列表格式
:param recursive: 递归加载文件,目录下还有文件夹,加载里面的文件
:return:
"""
text_loader_kwargs = {'autodetect_encoding': True}
loader = DirectoryLoader(filepath, glob=glob, loader_cls=loader_cls, silent_errors=silent_errors,
loader_kwargs=text_loader_kwargs, show_progress=show_progress,
use_multithreading=use_multithreading, max_concurrency=max_concurrency,
exclude=exclude, recursive=recursive)
docs = loader.load()
return docs
@classmethod
def html_loader(cls, filpath):
"""
https://python.langchain.com/docs/modules/data_connection/document_loaders/html/
加载 html
官网 BSHTMLLoader 会报编码错
其他加载方式是利用爬虫,第三方的,需要申请 api
:param filpath:
:return: 网页中的文本
"""
loader = UnstructuredHTMLLoader(filpath)
data = loader.load()
return data
@classmethod
def markdown_loader(cls, filepath, mode='single'):
"""
https://python.langchain.com/docs/modules/data_connection/document_loaders/markdown/
加载 markdown
:param filepath:
:param mode: 分割模式,single 全部合在一起,elements 把每一块都单独分开
:return:
"""
loader = UnstructuredMarkdownLoader(filepath, mode=mode)
data = loader.load()
return data
@classmethod
def pdf_loader(cls, filepath, extract_images=True, is_directory=False):
"""
https://python.langchain.com/docs/modules/data_connection/document_loaders/pdf/
加载 pdf,默认 page 是页码,但可能多出几页
:param filepath:
:param extract_images: 默认提取图片文字,是否提取 pdf 中的图片的文字
:param is_directory: 如果传入进来是目录,加载此路径下的所有 pdf,但图片中的文字不能识别
:return:
"""
if is_directory:
filepath = is_directory
loader = PyPDFDirectoryLoader(filepath)
docs = loader.load()
return docs
else:
if extract_images:
loader = PyPDFLoader(filepath, extract_images=extract_images)
else:
loader = PyMuPDFLoader(filepath) # 最快的 PDF 解析选项,但不能提取图片中的文字
pages = loader.load_and_split()
return pages
@classmethod
def excel_loader(cls, filepath, mode='single'):
"""
https://python.langchain.com/docs/integrations/document_loaders/microsoft_excel/
excel 加载,处理.xlsx和.xls文件
:param filepath:
:param mode: 式下使用加载程序 "elements",则该键下的文档元数据中将提供 Excel 文件的 HTML 表示形式text_as_html
:return:
"""
loader = UnstructuredExcelLoader(filepath, mode='elements')
docs = loader.load()
return docs
@classmethod
def ppt_loader(cls, filepath, mode='single'):
"""
https://python.langchain.com/docs/integrations/document_loaders/microsoft_powerpoint/
加载 ppt,不能提取图片中的文字
:param filepath:
:param mode: 分割模式,single 全部合在一起,elements 把每一页的文本框,表格等都单独分开
:return:
"""
loader = UnstructuredPowerPointLoader(filepath, mode=mode)
data = loader.load()
return data
@classmethod
def word_loader(cls, filepath, mode='single'):
"""
https://python.langchain.com/docs/integrations/document_loaders/microsoft_word/
:param filepath:
:param mode: 分割模式,single 全部合在一起,elements 把每一页单独分开,不能识别图片文字
:return:
"""
loader = UnstructuredWordDocumentLoader(filepath, mode=mode)
data = loader.load()
return data
@classmethod
def img_loader(cls, filepath, mode='single'):
"""
https://python.langchain.com/docs/integrations/document_loaders/image/
加载图片,可以识别上面文字,但不一定准
报错:no modul pdfminer.utils:https://github.com/langchain-ai/langchain/issues/14326
:param filepath:
:param mode: single-所有文字合在一起,elements-每个文字单独分开为一个快
:return:
"""
loader = UnstructuredImageLoader(filepath, mode=mode)
data = loader.load()
return data
# 使用 DocsLoader 加载 CSV 文件
filepath = "/home/mw/input/rag2153/专业描述.csv"
# 实例化 DocsLoader 并加载 CSV 数据
docs = DocsLoader.csv_loader(filepath)
# 打印加载的文档内容
for doc in docs:
print(doc.page_content)
print(doc.metadata)
专业: 材料科学与工程
介绍: 材料科学与工程是一门研究材料的组成、性质、制备、加工及应用的多学科交叉领域。它涵盖了金属、无机非金属、高分子、复合材料等各类材料的基础理论与技术,旨在开发新型功能材料,提升传统材料性能,为工业制造、科技发展和环境保护提供关键支撑。学生将学习材料设计、实验方法、数据分析等技能,未来就业方向广泛,如材料研发、生产、质检等领域。
{'source': '/home/mw/input/rag2153/专业描述.csv', 'row': 0}
专业: 作物学
介绍: 作物学是一门研究农作物生长发育规律、遗传育种、栽培管理、病虫害防治以及与环境关系的科学。它旨在提高农业生产效率,培育高产、优质、抗逆性强的作物品种,保障全球粮食安全。学生将学习植物生理、土壤肥料、农业生态等基础知识,并进行田间实践操作和科研训练。
{'source': '/home/mw/input/rag2153/专业描述.csv', 'row': 1}
专业: 口腔医学
介绍: 口腔医学是一门医学学科,主要研究口腔疾病的预防、诊断和治疗。学生将学习口腔解剖、病理、生理、口腔材料学、口腔内科、口腔外科、儿童口腔医学等内容。毕业后,他们能在医院、口腔诊所或科研机构从事口腔医生、牙科技师等工作,守护人们的口腔健康。
{'source': '/home/mw/input/rag2153/专业描述.csv', 'row': 2}
专业: 药学
介绍: 药学是一门研究药物的性质、结构、合成、分析、应用以及与人体相互作用的科学。它涵盖了药物设计、药品生产、质量控制、药物代谢、药效学和药动学等领域。学生将学习如何发现、开发新药,以及在临床实践中合理用药,保障公众健康。
{'source': '/home/mw/input/rag2153/专业描述.csv', 'row': 3}
专业: 教育学
介绍: 教育学是一门研究教育现象、教育规律和教育问题的学科。它涵盖了学前教育、基础教育、职业教育、高等教育以及特殊教育等多个领域,旨在培养具备教育理论知识和实践能力的教育工作者,探究如何优化教学方法,促进学生的全面发展和社会的进步。
{'source': '/home/mw/input/rag2153/专业描述.csv', 'row': 4}
专业: 水利工程
介绍: 水利工程是一门工程技术学科,主要研究如何规划、设计、建设和管理水资源,包括水的开发、利用、保护和治理。它涵盖了水文地质、水资源、水力发电、农田灌溉、城市给排水、环境水利等多个方向,旨在解决水资源短缺与洪涝灾害等问题,保障社会经济的可持续发展。
{'source': '/home/mw/input/rag2153/专业描述.csv', 'row': 5}
专业: 理论经济学
介绍: 理论经济学是一门研究经济运行规律、资源配置效率以及经济政策的学科。它涵盖了微观经济学,如供求关系、成本效益分析,以及宏观经济学,如经济增长、通货膨胀和财政货币政策。该专业培养学生理解和预测经济现象,为政府决策和企业战略提供理论支持。
{'source': '/home/mw/input/rag2153/专业描述.csv', 'row': 6}
专业: 食品科学与工程
介绍: 食品科学与工程是一门将生物学、化学、物理学和工程学等多学科融合的实用型专业。主要研究食品的生产、加工、储存、安全及品质控制等问题,涉及食品原料处理、食品加工技术、营养与健康、食品安全法规等多个领域。该专业旨在培养具备食品研发、加工制造、质量控制和管理能力的高级技术人才。
{'source': '/home/mw/input/rag2153/专业描述.csv', 'row': 7}
专业: 畜牧学/兽医学
介绍: 畜牧学/兽医学是一门关注动物健康与生产的专业,主要研究家禽、家畜的饲养管理、疾病预防与治疗、繁殖技术等。学生将学习动物生物学、营养学、病理学、药理学等知识,毕业后可在养殖场、兽医院、科研机构或相关政府部门从事动物保健、疾病防控等工作,保障食品安全及畜牧业可持续发展。
{'source': '/home/mw/input/rag2153/专业描述.csv', 'row': 8}
专业: 体育学
介绍: 体育学是一门研究体育运动、体育教育、体育社会学和运动人体科学等方面的学科。它涵盖了体育教学、运动训练、运动项目发展、健康促进以及体育管理等领域。学生将学习理论知识和实践技能,旨在培养具备体育教育、科研及体育产业运营管理能力的专业人才。
{'source': '/home/mw/input/rag2153/专业描述.csv', 'row': 9}
专业: 核科学与技术
介绍: 核科学与技术是一门研究原子核结构、性质、变化规律及其在能源、医学、国防等领域应用的学科。它涵盖了核物理、核工程、辐射防护等多个方向,学生将学习如何设计、操作和管理核反应堆,以及开发安全高效的核能技术。该专业毕业生可在核电站、核医疗、核材料等领域从事科研、设计和技术管理工作。
{'source': '/home/mw/input/rag2153/专业描述.csv', 'row': 10}
专业: 力学
介绍: 力学是一门自然科学,主要研究物体在力的作用下的运动规律和结构稳定性。它涵盖了静力学、动力学、固体力学、流体力学等多个分支,涉及材料科学、航空航天、土木工程、机械设计等诸多领域。学习力学有助于理解和解决工程问题,是工程技术学科的重要基础。
{'source': '/home/mw/input/rag2153/专业描述.csv', 'row': 11}
专业: 园艺学
介绍: 园艺学是一门研究植物生长、繁殖、养护与管理的科学,主要涉及花卉、果树、蔬菜等园艺植物的选种、育种、栽培技术以及园林景观设计。该专业学生将学习植物生理、土壤学、植物病理等基础知识,培养具备园林规划、植物生产与管理能力,能在园林、农业、城市绿化等领域工作的专业人士。
{'source': '/home/mw/input/rag2153/专业描述.csv', 'row': 12}
专业: 水产
介绍: 水产专业主要研究水生生物资源的可持续利用和管理,包括鱼类、虾蟹、贝类等水生动物的养殖技术、疾病防治、繁殖生物学、生态学以及海洋环境科学。学生将学习水产养殖技术、渔业资源评估与开发、水产品质量控制等知识,为渔业生产、科研及政府部门相关工作提供技术支持。
{'source': '/home/mw/input/rag2153/专业描述.csv', 'row': 13}
专业: 法学
介绍: 法学是一门社会科学,主要研究法律体系、法律原则、立法与司法实践。它涵盖了宪法、刑法、民法、商法等多个分支,旨在培养具备法律知识、分析能力和批判思考的未来法律工作者,以及能在政府、企业、非营利组织等领域运用法律解决问题的专业人才。
{'source': '/home/mw/input/rag2153/专业描述.csv', 'row': 14}
专业: 地质学/地质资源与地质工程
介绍: 地质学是一门研究地球内部结构、物质组成、地壳运动、地貌演变以及矿产资源分布等自然现象的科学。地质资源与地质工程专业则结合地质学知识,探索和开发地球资源,如矿产、能源,同时注重环境保护和灾害防治,为社会提供地质技术支持和解决方案。
{'source': '/home/mw/input/rag2153/专业描述.csv', 'row': 15}
专业: 石油与天然气工程
介绍: 石油与天然气工程是一门工程技术学科,主要研究石油、天然气的勘探、开发、生产、输送和利用。学生将学习地质构造、钻井技术、采油工程、油气储运以及环境保护等知识。该专业毕业生可在石油公司、能源工程企业或相关科研机构从事技术、管理等工作,对全球能源行业的发展具有重要影响。
{'source': '/home/mw/input/rag2153/专业描述.csv', 'row': 16}
专业: 农林经济管理
介绍: 农林经济管理是一门综合学科,主要研究农业、林业资源的经济开发与利用,以及农村和林业经济结构、经营方式的优化。它结合经济学原理,探讨农业生产、加工、销售等各个环节的经济效益,旨在推动农业现代化和可持续发展,培养能在政府、企事业单位及农业领域从事经济规划、管理决策的复合型人才。
{'source': '/home/mw/input/rag2153/专业描述.csv', 'row': 17}
专业: 信息与通信工程
介绍: 信息与通信工程是一门融合电子技术、计算机科学和通信理论的理工科专业。它研究信息的获取、处理、传输和应用,涉及信号与系统、通信原理、数字电子技术等内容。学生将学习如何设计和优化通信网络、开发信息系统,为现代通信科技和信息技术产业的发展打下坚实基础。
{'source': '/home/mw/input/rag2153/专业描述.csv', 'row': 18}
专业: 图书馆、情报与档案管理
介绍: 图书馆、情报与档案管理专业是一门综合学科,主要研究图书馆、信息机构的组织运营,以及信息资源的收集、整理、存储和提供。学生将学习信息检索、档案管理理论、信息技术在图书馆应用等内容,培养能在各类图书馆、信息中心及档案馆从事管理和服务工作的高级专门人才。
{'source': '/home/mw/input/rag2153/专业描述.csv', 'row': 19}
专业: 政治学
介绍: 政治学是一门社会科学,研究国家、政府、公共政策以及社会权力结构。它探讨政治行为、制度、理论与实践,包括国际关系、宪法、选举系统、政党政治等。通过学习,学生可培养分析问题、理解政策制定过程和参与公民社会的能力。
{'source': '/home/mw/input/rag2153/专业描述.csv', 'row': 20}
专业: 电气工程
介绍: 电气工程是一门应用广泛的工科专业,主要研究电能的产生、传输、转换和使用,包括电力系统、电子技术、通信技术、控制工程等方向。学生将学习电路理论、电磁场、信号处理、自动化控制等基础知识,毕业后可在电力公司、电子制造、通信行业、科研机构等领域从事设计、研发、管理等工作。
{'source': '/home/mw/input/rag2153/专业描述.csv', 'row': 21}
专业: 海洋科学
介绍: 海洋科学是一门研究海洋生态系统、物理、化学、生物、地质等多学科交叉的综合专业。它探索海洋环境、资源开发、保护与管理,包括海洋生物学、海洋物理学、海洋化学、海洋地质学等内容。学生将学习海洋观测技术、数据分析及海洋环境保护策略,为海洋科技发展和可持续利用做出贡献。
{'source': '/home/mw/input/rag2153/专业描述.csv', 'row': 22}
专业: 民族学
介绍: 民族学是一门社会科学,主要研究不同民族的历史、文化、社会结构、习俗和变迁。它通过田野调查、文献分析等方式,探索民族间的共性与差异,促进跨文化交流与理解。学习民族学有助于培养学生的文化敏感性和全球视野,常应用于教育、政策制定及国际组织等领域。
{'source': '/home/mw/input/rag2153/专业描述.csv', 'row': 23}
专业: 航空宇航科学与技术
介绍: 航空宇航科学与技术是一门融合工程学、物理学、材料科学等多学科的尖端专业。它主要研究飞行器的设计、制造、操控与导航,以及航天器的开发与应用。该专业涵盖飞机设计、火箭技术、卫星通信等领域,致力于推动航空航天领域的科技进步,为未来的航空和航天工业输送高端人才。
{'source': '/home/mw/input/rag2153/专业描述.csv', 'row': 24}
专业: 化学/化学工程与技术
介绍: 化学专业主要研究物质的组成、性质、结构与变化规律,涉及化学反应、物质制备、分析检测等。化学工程与技术则将化学原理应用于工业生产,设计和优化化学过程,如化肥、药品、能源等领域,解决实际生产中的问题,是连接理论与生产的桥梁。
{'source': '/home/mw/input/rag2153/专业描述.csv', 'row': 25}
专业: 哲学
介绍: 哲学专业是一门探究人生、知识、价值和存在等基本问题的学科。它涵盖了逻辑、形而上学、伦理学、美学等多个分支,旨在培养学生的批判思考能力、逻辑推理和深度理解世界的方式。学生将学习历史哲学家的思想,同时通过反思与创新,形成自己的哲学观点。虽然就业领域广泛,但更多的是为其他学科提供理论支持和人文素养的提升。
{'source': '/home/mw/input/rag2153/专业描述.csv', 'row': 26}
专业: 公共卫生与预防医学
介绍: 公共卫生与预防医学是一门关注人群健康和疾病预防的学科。它研究如何通过环境、行为、政策等多角度来预防疾病的发生,提升公众健康水平。学生将学习流行病学、卫生统计学、营养学、环境卫生等知识,旨在培养疾病防控策略的制定者和执行者,致力于社会健康服务和公共卫生活动。
{'source': '/home/mw/input/rag2153/专业描述.csv', 'row': 27}
专业: 艺术学
介绍: 艺术学是一门综合性的学科,研究艺术现象、历史、理论以及创作实践。它涵盖了视觉艺术、表演艺术、音乐、设计等多个领域,旨在理解艺术的审美价值、社会功能与文化内涵。学生将学习艺术批评、艺术史、艺术理论,培养创新思维和跨文化沟通能力,为艺术教育、研究或相关行业提供知识和素养。
{'source': '/home/mw/input/rag2153/专业描述.csv', 'row': 28}
专业: 农业工程
介绍: 农业工程是一门将工程技术与农业生产实践相结合的学科,主要研究如何应用机械、电子、生物等多学科知识解决农业生产中的实际问题。它涵盖了农田水利、农业机械、农产品加工、环境控制等领域,致力于提高农业生产效率,保障食品安全,以及推动农业可持续发展。
{'source': '/home/mw/input/rag2153/专业描述.csv', 'row': 29}
专业: 船舶与海洋工程
介绍: 船舶与海洋工程是一门工程技术学科,主要研究船舶的设计、建造、运行和维护,以及海洋环境中的结构工程。它涵盖了船舶设计、船舶机械、海洋结构分析、海洋能源利用等多个领域。学生将学习船舶制造技术、船舶动力系统、海洋工程材料等知识,未来可在船舶制造、航海、海洋开发等领域从事技术或管理工作。
{'source': '/home/mw/input/rag2153/专业描述.csv', 'row': 30}
专业: 计算机科学与技术
介绍: 计算机科学与技术是一门融合了计算机硬件、软件和理论的工科专业。它研究算法设计、数据结构、编程原理,涵盖了操作系统、数据库、网络技术、人工智能等多个方向。该专业旨在培养具备扎实计算机基础知识,能解决实际问题的高级技术人才,未来就业领域广泛,如IT行业、科研机构、教育等。
{'source': '/home/mw/input/rag2153/专业描述.csv', 'row': 31}
专业: 冶金工程
介绍: 冶金工程是一门工程技术学科,主要研究金属矿物的开采、选矿、冶炼、加工和材料设计。它涵盖了钢铁、有色金属等工业生产过程,包括炼铁、炼钢、合金制造等技术。通过化学、物理、力学等多学科交叉,培养学生在金属材料科学与工程领域的实践能力和创新思维。未来就业方向广泛,涉及钢铁厂、金属研究机构及新材料开发等领域。
{'source': '/home/mw/input/rag2153/专业描述.csv', 'row': 32}
专业: 交通运输工程
介绍: 交通运输工程是一门融合了工程学、经济学与管理学的交叉学科。它主要研究如何设计、建设和优化各种运输系统,包括公路、铁路、航空、水运等,以及交通工具的性能提升。该专业涉及交通规划、交通设施工程、交通安全、物流技术等多个领域,旨在解决现代城市和区域的交通问题,推动交通运输行业的可持续发展。
{'source': '/home/mw/input/rag2153/专业描述.csv', 'row': 33}
专业: 动力工程及工程热物理
介绍: 动力工程及工程热物理是一门工程技术学科,主要研究能源转换、传递与利用的原理和方法,涉及热力学、传热学、流体力学等基础知识。该专业致力于解决能源生产、动力设备(如汽轮机、燃气轮机)以及工业过程中的高温、高压热能问题,是能源、动力领域的重要支撑。学生将学习如何设计、优化和维护高效、环保的能源系统。
{'source': '/home/mw/input/rag2153/专业描述.csv', 'row': 34}
专业: 纺织科学与工程
介绍: 纺织科学与工程是一门多学科交叉的专业,主要研究纤维材料的获取、加工、织造、染整等技术,以及相关设备的设计与开发。它涵盖了纺织材料学、纺织工程、染整工程等多个方向,旨在培养具备纺织生产、设计和管理能力的高级工程技术人才,涉及服装、家居、汽车等多种行业。
{'source': '/home/mw/input/rag2153/专业描述.csv', 'row': 35}
专业: 建筑学
介绍: 建筑学是一门艺术与技术相结合的学科,主要研究建筑物的设计、规划、结构和环境影响。它涵盖了历史保护、城市规划、景观设计等多个领域,要求学生具备创新思维、审美能力和扎实的绘图技能。未来就业方向广泛,包括建筑师、城市设计师、施工管理等,是塑造人类生活环境的重要专业。
{'source': '/home/mw/input/rag2153/专业描述.csv', 'row': 36}
专业: 环境科学与工程
介绍: 环境科学与工程是一门多学科交叉的专业,主要研究环境系统的结构、功能、变化规律以及环境污染的预防和治理。它涵盖了大气科学、水文学、生态学、化学等多个领域,旨在培养具备环境监测、评价、治理、规划和技术开发能力的高级人才,致力于解决环境问题,推动可持续发展。
{'source': '/home/mw/input/rag2153/专业描述.csv', 'row': 37}
专业: 公共管理
介绍: 公共管理是一门融合了行政学、经济学、法学等多学科知识的专业,主要研究如何运用科学方法和管理理念来提高政府机构、非营利组织和社会公共服务的效率与质量。学生将学习政策分析、项目管理、公共财务、法律与伦理等内容,培养具备领导力和解决公共问题能力的未来管理者。
{'source': '/home/mw/input/rag2153/专业描述.csv', 'row': 38}
专业: 数学
介绍: 数学专业是一门研究数量、结构、变化和空间等概念的科学,涵盖了代数、几何、概率论、数论等多个分支。它既是理论研究的基础,也是应用广泛的工具,如物理学、工程学、经济学等领域都离不开数学的支持。在大学中,数学专业培养学生严谨的逻辑思维、抽象推理和问题解决能力,为今后的科研或技术工作打下坚实基础。
{'source': '/home/mw/input/rag2153/专业描述.csv', 'row': 39}
专业: 物理学
介绍: 物理学是一门探索物质世界最基本的构成、性质和运动规律的科学。它涵盖了广泛的领域,如力学、热学、电磁学、光学、原子物理和粒子物理等。通过实验、理论分析和数学模型,物理学家揭示自然现象背后的原理,为科技发展提供基础,如信息技术、能源、材料科学等。学习物理学,学生将培养严谨的逻辑思维和创新精神。
{'source': '/home/mw/input/rag2153/专业描述.csv', 'row': 40}
专业: 林学/林业工程
介绍: 林学/林业工程是一门研究森林资源的科学与技术结合的专业。它涵盖了森林生态学、造林技术、森林经营管理、木材科学与工程等内容。学生将学习如何保护和可持续利用森林资源,进行林业规划与设计,以及开发和改进木材加工技术。该专业毕业生可在林业部门、生态保护机构、木制品工业等从事相关工作,致力于环境与经济的和谐发展。
{'source': '/home/mw/input/rag2153/专业描述.csv', 'row': 41}
专业: 心理学
介绍: 心理学是一门探索人类思维、行为和情感的科学。它研究心理过程、发展、结构、功能及其与社会环境的关系。学习心理学,你将学习如何理解个体的认知、情绪及动机,掌握各种心理评估和干预方法,可用于教育、临床、管理等领域,帮助人们改善心理健康,解决生活中的问题。
{'source': '/home/mw/input/rag2153/专业描述.csv', 'row': 42}
专业: 历史学
介绍: 历史学是一门研究人类社会过去事件、行为和思想的学科,通过考古发掘、文献分析、口述历史等方式,探索历史变迁、文化发展和社会结构。它培养具备批判性思维和深度理解能力的学生,使他们能够在教育、文化、政策等领域发挥作用,传承与创新历史知识。
{'source': '/home/mw/input/rag2153/专业描述.csv', 'row': 43}
专业: 工商管理
介绍: 工商管理是一门综合性的学科,主要研究企业组织的运作、战略规划、财务管理、市场营销和人力资源管理等内容。它注重理论与实践结合,旨在培养具备现代企业管理知识和技能的高级商务人才,能在各类企事业单位、咨询机构或政府部门从事经营管理、战略决策等工作。
{'source': '/home/mw/input/rag2153/专业描述.csv', 'row': 44}
专业: 应用经济学
介绍: 应用经济学是一门将理论经济学知识与实际经济问题相结合的学科。它研究如何运用经济模型、数据分析来解决生产、分配、消费等经济活动中的问题,涉及宏观经济学、微观经济学、金融学、国际经济等多个领域。学生将学习经济政策分析、市场行为理解、投资决策等技能,为政府、企业、金融机构等领域提供决策支持。
{'source': '/home/mw/input/rag2153/专业描述.csv', 'row': 45}
专业: 中医学/中药学
介绍: 中医学专业主要研究人体生命活动规律和疾病的预防、诊断与治疗,以中医理论体系为核心,包括中医基础医学、临床医学、针灸推拿、中药学等。学生将学习中医经典理论、辨证论治、中药炮制与应用等内容,旨在培养具有深厚中医底蕴和实践能力的中医医师或科研人员。中药学则侧重于中药的研究与开发,包括植物药、动物药和矿物药的来源、性质、炮制、制剂及药理作用等,为现代中医药产业提供技术支持。
{'source': '/home/mw/input/rag2153/专业描述.csv', 'row': 46}
专业: 天文学
介绍: 天文学是一门研究宇宙的科学,探索星体、宇宙物质、宇宙结构和宇宙演化的学科。它涉及观测、理论物理、数据处理等多个领域,通过研究恒星、行星、星系等天体,揭示宇宙的起源、演化及基本规律。学生将学习天文观测技术、天体物理学、宇宙化学等内容,未来可在科研机构、教育部门或相关高科技产业从事工作。
{'source': '/home/mw/input/rag2153/专业描述.csv', 'row': 47}
专业: 机械工程
介绍: 机械工程是一门工程技术学科,主要研究设计、制造和维护各种机械设备。它涵盖了力学、材料科学、电子技术等多个领域,包括机械设计、机械制造、自动化、机器人技术等方向。学生将学习如何解决实际问题,通过创新来提升生产效率和产品质量,是工业现代化的核心驱动力。
{'source': '/home/mw/input/rag2153/专业描述.csv', 'row': 48}
专业: 土木工程
介绍: 土木工程是一门实践性极强的学科,主要研究建筑物、道路、桥梁等基础设施的规划、设计、建造与维护。它融合了力学、材料科学、环境科学等多领域知识,涉及结构工程、交通工程、地质工程等多个方向。学生将学习如何解决实际问题,参与到城市和环境的建设中,是工程建设的中坚力量。
{'source': '/home/mw/input/rag2153/专业描述.csv', 'row': 49}
专业: 光学工程
介绍: 光学工程是一门应用物理学原理,研究光的性质、测量、控制和应用的工程技术学科。它涵盖了光学设计、光学仪器制造、激光技术、光纤通信、光电子材料等领域,旨在开发新型光学设备和系统,以解决信息传输、成像、检测等领域的实际问题。未来就业前景广阔,涉及科研机构、制造业、信息技术等多个行业。
{'source': '/home/mw/input/rag2153/专业描述.csv', 'row': 50}
专业: 地理学
介绍: 地理学是一门研究地球表面各种自然现象、人文现象及其相互关系的学科。它涵盖了地球环境、自然资源、城市规划、气候变化、人口分布等多个领域。通过实地考察、遥感技术与数据分析,培养学生空间思维和解决环境问题的能力,为社会可持续发展提供科学依据。
{'source': '/home/mw/input/rag2153/专业描述.csv', 'row': 51}
专业: 农业资源利用
介绍: 农业资源利用专业是一门关注农业生产与环境保护相结合的学科。它研究如何科学合理地开发、保护和管理土地、水、气候等农业自然资源,以及生物多样性在农业生产中的应用。学生将学习土壤学、生态学、农业工程等知识,旨在提升农业生产效率,实现可持续发展。
{'source': '/home/mw/input/rag2153/专业描述.csv', 'row': 52}
专业: 生物学/生物科学与工程
介绍: 生物学是一门研究生命现象、结构、功能及其变化规律的科学,涵盖了从分子到生态系统的各个层次。生物科学与工程专业融合了生物学与工程学,通过实验、计算和设计,解决生物医学、环境保护、农业生产等领域的实际问题,培养具备创新能力和实践技能的复合型人才。
{'source': '/home/mw/input/rag2153/专业描述.csv', 'row': 53}
专业: 兵器科学与技术
介绍: 兵器科学与技术是一门集科学、技术和工程于一体的学科,主要研究武器装备的设计、制造、测试和系统集成。它涵盖了火炮、导弹、舰艇、飞机等各类兵器的原理、材料、结构、控制以及战场环境下的应用。该专业学生将学习军事科技理论,具备武器系统分析和研发能力,是国防工业和国家安全的重要支柱。
{'source': '/home/mw/input/rag2153/专业描述.csv', 'row': 54}
专业: 矿业工程
介绍: 矿业工程是一门工程技术学科,主要研究地球内部矿产资源的勘探、开采、选矿、矿物加工和安全环保等方面。学生将学习地质构造、采矿方法、矿井通风、岩土力学等专业知识,毕业后可在矿山企业、科研机构或政府部门从事矿产开发、设计、管理等工作,是连接自然资源与工业生产的桥梁。
{'source': '/home/mw/input/rag2153/专业描述.csv', 'row': 55}
专业: 大气科学
介绍: 大气科学是一门研究地球大气层的物理、化学、生物和气象现象的学科。它涵盖了天气预报、气候模型、空气质量、气候变化、空间天气等领域,旨在理解大气系统的工作原理,并为环境保护、资源管理以及灾害防范提供科学依据。学生将学习大气动力学、气象学、遥感技术等,培养气候分析和解决实际问题的能力。
{'source': '/home/mw/input/rag2153/专业描述.csv', 'row': 56}
专业: 基础医学/临床医学
介绍: 基础医学专业主要研究人体生命活动的基本规律和生物学机制,包括细胞、分子、器官等层次的结构与功能。它为临床医学提供理论支持,是医学科学的基础。临床医学则侧重于疾病的预防、诊断和治疗,通过实践经验将基础医学知识应用于病人实际诊疗中,如内科、外科、儿科等各科领域。
{'source': '/home/mw/input/rag2153/专业描述.csv', 'row': 57}
专业: 电子科学与技术
介绍: 电子科学与技术是一门融合了物理学、电子学、计算机科学等多学科的工科专业。它主要研究电子设备、电路、信号处理、通信技术等内容,涉及半导体器件、微电子技术、光电子技术等领域。学生将学习设计、制造和应用各种电子设备与系统,为现代信息技术产业提供技术支持。
{'source': '/home/mw/input/rag2153/专业描述.csv', 'row': 58}
专业: 测绘科学与技术
介绍: 测绘科学与技术是一门应用性强的工科专业,主要研究地球空间信息的获取、处理、管理与应用。学生学习地理信息系统、测量工程、摄影测量与遥感等知识,通过现代科技手段进行地图制作、土地资源调查、工程建设测量等工作,为城市规划、地理环境监测等领域提供技术支持。
{'source': '/home/mw/input/rag2153/专业描述.csv', 'row': 59}
专业: 控制科学与工程
介绍: 控制科学与工程是一门融合了数学、电子技术、计算机科学和机械工程等多学科的理工科专业。它主要研究如何设计、分析和实现对系统(如工业生产过程、机器人、航空航天设备等)的精确控制,以提高效率、安全性和稳定性。学生将学习信号处理、自动控制理论、优化算法等核心知识,并培养解决复杂工程问题的能力。
{'source': '/home/mw/input/rag2153/专业描述.csv', 'row': 60}
专业: 军事学
介绍: 军事学是一门研究战争、军队建设和国防战略的学科,主要探讨军事理论、战术技术、军队管理、国际安全等问题。它涵盖了军事历史、军事思想、武器装备、指挥艺术等多个领域,旨在培养具备军事知识和领导才能的军事人才,为国家的安全和发展提供战略支持。
{'source': '/home/mw/input/rag2153/专业描述.csv', 'row': 61}
专业: 中国语言文学
介绍: 中国语言文学是一门研究汉语言文字、汉语历史演变、古代和现代汉语语法、修辞、词汇、方言以及中国文学作品的学科。它涵盖了古代诗词、小说、戏曲、散文等各类文体的研究,旨在传承和弘扬中华文化,培养学生的文学鉴赏能力和创作技巧。对于热爱中国文化的人来说,这是一个深度发掘历史底蕴与审美价值的专业。
{'source': '/home/mw/input/rag2153/专业描述.csv', 'row': 62}
专业: 新闻传播学
介绍: 新闻传播学是一门研究新闻采集、制作、传播与接收的学科,它涵盖了媒体理论、新闻史、新闻业务、广告学、公共关系等多个方向。学生将学习如何挖掘信息,撰写报道,理解社会议题,以及利用数字媒体进行传播。这个专业培养具备敏锐洞察力和沟通能力的传媒人才,就业领域包括新闻媒体、广告公司、公关机构和政府机构等。
{'source': '/home/mw/input/rag2153/专业描述.csv', 'row': 63}
专业: 社会学
介绍: 社会学是一门研究社会结构、社会行为、社会变迁以及社会问题的学科。它通过理论分析和实证研究,探索人类社会的各种现象和规律,包括社会分层、文化冲突、社区发展等。学习社会学,学生将培养批判性思维、调查研究和问题解决的能力,为公共服务、政策分析等领域提供理论支持。
{'source': '/home/mw/input/rag2153/专业描述.csv', 'row': 64}
专业: 地球物理学
介绍: 地球物理学是一门研究地球内部结构、物理性质及其变化规律的科学。它结合地质学、物理学和数学方法,通过地震波探测、磁力测量等手段,解析地壳、地幔、地核的构成与运动,探索自然资源分布,预防地质灾害,为矿产勘探、环境保护等领域提供技术支持。
{'source': '/home/mw/input/rag2153/专业描述.csv', 'row': 65}
专业: 植物保护
介绍: 植物保护专业是一门生物学与农业科学交叉的学科,主要研究如何预防、诊断和控制植物病虫害,保障农业生产安全。学生将学习植物病理学、昆虫学、农药学等知识,通过实验室实践和实地操作,掌握病虫害监测、防治技术和绿色防控策略,为农业生产可持续发展提供技术支持。
{'source': '/home/mw/input/rag2153/专业描述.csv', 'row': 66}
Task3 使用 faiss 进行存储,将向量数据库及加载的向量化模型信息打印出来。
数据向量化存储,向量化模型路径:/home/mw/input/test8270/bge-small-zh-v1.5/bge-small-zh-v1.5
使用 faiss 进行存储,将向量数据库及加载的向量化模型信息打印出来。
# Your Answer
class TextSpliter():
@classmethod
def text_split_by_char(cls, docs, separator='\n', chunk_size=100, chunk_overlap=20, length_function=len,
is_separator_regex=False):
"""
https://python.langchain.com/docs/modules/data_connection/document_transformers/character_text_splitter/
指定字符拆分,separator 指定,若指定有效 chunk_size 失效
:param docs: 文档,必须为 str,如果是 langchain 加载进来的需要转换一下
:param separator: 分割字符
:param chunk_size: 每块大小
:param chunk_overlap: 允许字数重叠大小
:param length_function:
:param is_separator_regex:
:return:
"""
text_splitter = CharacterTextSplitter(
separator=separator,
chunk_size=chunk_size,
chunk_overlap=chunk_overlap,
length_function=length_function,
is_separator_regex=is_separator_regex,
)
docs = docs[0].page_content # langchian 加载的 txt 转换为 str
text_split = text_splitter.create_documents([docs])
return text_split
@classmethod
def text_split_by_manychar_or_charnum(cls, docs, separator=["\n\n", "\n", " ", ""], chunk_size=100, chunk_overlap=20,
length_function=len, is_separator_regex=True):
"""
https://python.langchain.com/docs/modules/data_connection/document_transformers/recursive_text_splitter/
按照 chunk_size 字数分割,separator 不需要传,保持默认值即可
多个字符拆分,separator 指定,符合列表中的字符就会被拆分
:param docs: 文档,必须为 str,如果是 langchain 加载进来的需要转换一下
:param separator: 分割字符,默认以列表中的字符去分割 ["\n\n", "\n", " ", ""]
:param chunk_size: 每块大小
:param chunk_overlap: 允许字数重叠大小
:param length_function:
:param is_separator_regex:
:return:
"""
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=chunk_size, # 指定每块大小
chunk_overlap=chunk_overlap, # 指定每块可以重叠的字符数
length_function=length_function,
is_separator_regex=is_separator_regex,
separators=separator # 指定按照什么字符去分割,如果不指定就按照 chunk_size +- chunk_overlap(100+-20)个字去分割
)
docs = docs[0].page_content # langchian 加载的 txt 转换为 str
split_text = text_splitter.create_documents([docs])
return split_text
@classmethod
def json_split(cls, json_data, min_chunk_size=50, max_chunk_size=300):
"""
https://python.langchain.com/docs/modules/data_connection/document_transformers/recursive_json_splitter/
json 拆分,每一个块会拆分为完整的字典
:param json_data:
:param min_chunk_size:
:param max_chunk_size:
:return:
"""
splitter = RecursiveJsonSplitter(min_chunk_size=min_chunk_size, max_chunk_size=max_chunk_size)
json_chunks = splitter.split_json(json_data=json_data)
return json_chunks
@classmethod
def html_split(cls, html_string='', url='', chunk_size=500, chunk_overlap=30):
"""
https://python.langchain.com/docs/modules/data_connection/document_transformers/HTML_header_metadata/
html 分割,两种方式
:param html_string: 字符串类型 html
:param url: 传入 url 分割 html
:return:
"""
# 按照标题标签分,相同的 h 标签会在元数据可以看到属于哪一个 h
headers_to_split_on = [
("h1", "Header 1"),
("h2", "Header 2"),
("h3", "Header 3"),
("h4", "Header 4"),
("h5", "Header 5"),
("h6", "Header 6"),
]
html_splitter = HTMLHeaderTextSplitter(headers_to_split_on=headers_to_split_on)
if html_string:
splits = html_splitter.split_text(html_string)
else:
html_header_splits = html_splitter.split_text_from_url(url)
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=chunk_size, chunk_overlap=chunk_overlap
)
splits = text_splitter.split_documents(html_header_splits)
return splits
@classmethod
def code_split(cls, code, language=Language.PYTHON, chunk_size=50, chunk_overlap=0):
"""
https://python.langchain.com/docs/modules/data_connection/document_transformers/code_splitter/
# Full list of supported languages
[e.value for e in Language]
分割代码
:param code:
:param language: 默认 python
:param chunk_size:
:param chunk_overlap:
:return:
"""
python_splitter = RecursiveCharacterTextSplitter.from_language(
language=language, chunk_size=chunk_size, chunk_overlap=chunk_overlap
)
docs = python_splitter.create_documents([code])
return docs
@classmethod
def markdown_split(cls, mkardown_string, char_level_splits=False, strip_headers=False, chunk_size=250,
chunk_overlap=30):
"""
https://python.langchain.com/docs/modules/data_connection/document_transformers/markdown_header_metadata/
分割 markdown
:param mkardown_string: markdown 字符串
:param char_level_splits: 是否在标题分割后再继续按字数分割
:param strip_headers: 默认情况下,从输出块的内容中删除分割的标头。可以通过设置禁用此功能 strip_headers = False。
:return:
"""
headers_to_split_on = [
("#", "Header 1"),
("##", "Header 2"),
("###", "Header 3"),
]
markdown_splitter = MarkdownHeaderTextSplitter(headers_to_split_on=headers_to_split_on,
strip_headers=strip_headers)
md_header_splits = markdown_splitter.split_text(mkardown_string)
splits = md_header_splits
if char_level_splits:
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=chunk_size, chunk_overlap=chunk_overlap
)
splits = text_splitter.split_documents(md_header_splits)
return splits
@classmethod
def semantic_chunker_split(cls, txt, embedding_model, breakpoint_threshold_type="percentile"):
"""
https://python.langchain.com/docs/modules/data_connection/document_transformers/semantic-chunker/
语义分块
:param txt: txt 字符串
:param embedding_model:
:param breakpoint_threshold_type: 分割断点
percentile:默认的分割方式是基于百分位数。在此方法中,计算句子之间的所有差异,然后分割任何大于 X 百分位数的差异
standard_deviation:任何大于 X 个标准差的差异都会被分割。
interquartile:使用四分位数距离来分割块
:return:
"""
text_splitter = SemanticChunker(embedding_model, breakpoint_threshold_type=breakpoint_threshold_type)
docs = text_splitter.create_documents([txt])
return docs
class EmbeddingVectorDB():
@classmethod
def load_local_embedding_model(cls, embedding_model_path, device='cpu'):
"""加载本地向量模型"""
embedding_model = HuggingFaceEmbeddings(model_name=embedding_model_path, model_kwargs={'device': device})
return embedding_model
@classmethod
def faiss_vector_db(cls, split_docs, vector_db_path, embedding_model):
"""
https://python.langchain.com/docs/modules/data_connection/vectorstores/
faiss 创建向量数据库
:param split_docs: 分割的文本块
:param vector_db_path: 向量数据库存储路径
:param embedding_model: embedding 模型
:return:
"""
if os.path.exists(vector_db_path):
print('加载向量数据库路径 =》', vector_db_path)
db = FAISS.load_local(vector_db_path, embedding_model, allow_dangerous_deserialization=True)
else:
print('创建向量数据库路径 =》', vector_db_path)
db = FAISS.from_documents(split_docs, embedding_model)
db.save_local(vector_db_path)
return db
@classmethod
async def faiss_vector_db_await(cls, split_docs, vector_db_path, embedding_model):
"""
https://python.langchain.com/docs/integrations/vectorstores/faiss_async/#similarity-search-with-score
:param split_docs: 分割的文本块
:param vector_db_path: 向量数据库存储路径
:param embedding_model: embedding 模型
:return:
"""
if os.path.exists(vector_db_path):
print('加载向量数据库路径 =》', vector_db_path)
db = FAISS.load_local(vector_db_path, embedding_model, allow_dangerous_deserialization=True)
else:
print('创建向量数据库路径 =》', vector_db_path)
db = await FAISS.afrom_documents(split_docs, embedding_model)
db.save_local(vector_db_path)
return db
@classmethod
def chroma_vector_db(cls, split_docs, vector_db_path, embedding_model):
"""
https://python.langchain.com/docs/modules/data_connection/vectorstores/
faiss 创建向量数据库
:param split_docs: 分割的文本块
:param vector_db_path: 向量数据库存储路径
:param embedding_model: embedding 模型
:return:
"""
if os.path.exists(vector_db_path):
print('加载向量数据库路径 =》', vector_db_path)
db = Chroma(persist_directory=vector_db_path, embedding_function=embedding_model)
else:
print('创建向量数据库路径 =》', vector_db_path)
db = Chroma.from_documents(split_docs, embedding_model, persist_directory=vector_db_path)
db.persist()
return db
# 知识库分割
text_split = TextSpliter.text_split_by_char(docs, separator='\n', chunk_size=20, chunk_overlap=0)
# 加载本地 embedding 模型
model_path = '/home/mw/input/test8270/bge-small-zh-v1.5/bge-small-zh-v1.5'
embedding = HuggingFaceEmbeddings(model_name=model_path)
print("embedding模型信息:\n ", embedding) # 打印 embedding 模型信息
# 创建向量数据库
db = FAISS.from_documents(text_split, embedding)
print("向量数据库信息:\n ", db) # 打印向量数据库信息
# 保存向量数据库到本地
db.save_local("./faiss_index")
print("FAISS index saved at './faiss_index'.")
# 如果已经创建了数据库,可以直接读取
db = FAISS.load_local("./faiss_index", embedding, allow_dangerous_deserialization=True)
print("Loaded FAISS VectorStore from './faiss_index'.")
embedding模型信息:
client=SentenceTransformer(
(0): Transformer({'max_seq_length': 512, 'do_lower_case': True}) with Transformer model: BertModel
(1): Pooling({'word_embedding_dimension': 512, 'pooling_mode_cls_token': True, 'pooling_mode_mean_tokens': False, 'pooling_mode_max_tokens': False, 'pooling_mode_mean_sqrt_len_tokens': False, 'pooling_mode_weightedmean_tokens': False, 'pooling_mode_lasttoken': False, 'include_prompt': True})
(2): Normalize()
) model_name='/home/mw/input/test8270/bge-small-zh-v1.5/bge-small-zh-v1.5' cache_folder=None model_kwargs={} encode_kwargs={} multi_process=False show_progress=False
向量数据库信息:
<langchain_community.vectorstores.faiss.FAISS object at 0x7f753f1fd910>
FAISS index saved at './faiss_index'.
Loaded FAISS VectorStore from './faiss_index'.
Task4 根据使用的数据设置一个问题,调用大模型,让大模型进行回答,打印出大模型回答结果
可以根据使用的数据设置一个问题,调用大模型,让大模型进行回答,打印出大模型回答结果
# Your Answer
class Prompt():
@classmethod
def prompt_template(cls, prompt_string, **kwargs):
"""
https://python.langchain.com/docs/modules/model_io/prompts/quick_start/#prompttemplate
基本 prompt 接受变量的写法,也可以不传入变量
:param prompt_string: 字符串 prompt,变量用 {} 括起来
:param kwargs: 字典,依次传入的变量取值
e.g prompt_string="可以给我介绍一下`{fruit}`还有`{fruit2}`吗?",
fruit='苹果', fruit2='香蕉'
可以给我介绍一下`苹果`还有`香蕉`吗?
:return:
"""
prompt_template = PromptTemplate.from_template(prompt_string)
prompt = prompt_template.format(**kwargs)
return prompt
@classmethod
def chat_prompt_template(cls, text):
"""
https://python.langchain.com/docs/modules/model_io/prompts/quick_start/#chatprompttemplate
对话式模版
content 可以手动设置好,每次传入人工的提示词 text
:param text:
:return:
"""
chat_template = ChatPromptTemplate.from_messages(
[
SystemMessage(
content=(
"You are a helpful assistant that re-writes the user's text to "
"sound more upbeat."
)
),
HumanMessagePromptTemplate.from_template("{text}"),
]
)
messages = chat_template.format_messages(text=text)
return messages
@classmethod
def chat_message_prompt_template(cls, prompt_string, role='human', **kwargs):
"""
https://python.langchain.com/docs/modules/model_io/prompts/quick_start/#message-prompts
聊天模型支持以任意角色获取聊天消息,您可以使用ChatMessagePromptTemplate,它允许用户指定角色名称
:param prompt_string:
:param role: 指定的角色
:param kwargs:
:return:
"""
chat_message_prompt = ChatMessagePromptTemplate.from_template(
role=role, template=prompt_string
)
message = chat_message_prompt.format(**kwargs)
return message
@classmethod
def messages_placeholder(cls, human_prompt, **kwargs):
"""
https://python.langchain.com/docs/modules/model_io/prompts/quick_start/#messagesplaceholder
可以让您完全控制格式化期间要呈现的消息。当您不确定消息提示模板应使用什么角色或希望在格式化期间插入消息列表时,这会很有用
content 可以手动定义
:param human_prompt:
:param kwargs: prompt 变量
:return:
"""
human_message_template = HumanMessagePromptTemplate.from_template(human_prompt)
chat_prompt = ChatPromptTemplate.from_messages(
[MessagesPlaceholder(variable_name="conversation"), human_message_template]
)
human_message = HumanMessage(content="What is the best way to learn programming?")
ai_message = AIMessage(
content="""\
1. Choose a programming language: Decide on a programming language that you want to learn.
2. Start with the basics: Familiarize yourself with the basic programming concepts such as variables, data types and control structures.
3. Practice, practice, practice: The best way to learn programming is through hands-on experience\
"""
)
message = chat_prompt.format_prompt(
conversation=[human_message, ai_message], **kwargs
).to_messages()
return message
@classmethod
def example_selectors_length_based(cls, examples, string, max_length=25):
"""
https://python.langchain.com/docs/modules/model_io/prompts/example_selectors/length_based/
按 prompt 长度选择示例
prefix 可以定义,是显示在开头的
:param examples: 示例列表
e.g examples = [
{"input": "happy", "output": "sad"},
{"input": "tall", "output": "short"},
{"input": "energetic", "output": "lethargic"},
{"input": "sunny", "output": "gloomy"},
{"input": "windy", "output": "calm"},
]
:param examples: 传进来的 prompt
:param max_length: 传进来的 prompt 最大长度小于它则选择全部示例,否则根据长度自动选择几个示例
:return:
"""
examples = [
{"input": "happy", "output": "sad"},
{"input": "tall", "output": "short"},
{"input": "energetic", "output": "lethargic"},
{"input": "sunny", "output": "gloomy"},
{"input": "windy", "output": "calm"},
]
example_prompt = PromptTemplate(
input_variables=["input", "output"],
template="Input: {input}\nOutput: {output}",
)
example_selector = LengthBasedExampleSelector(
# The examples it has available to choose from.
examples=examples,
# The PromptTemplate being used to format the examples.
example_prompt=example_prompt,
max_length=max_length,
)
dynamic_prompt = FewShotPromptTemplate(
# We provide an ExampleSelector instead of examples.
example_selector=example_selector,
example_prompt=example_prompt,
prefix="Give the antonym of every input",
suffix="Input: {adjective}\nOutput:",
input_variables=["adjective"],
)
example_prompt = dynamic_prompt.format(adjective=string)
return example_prompt
@classmethod
def example_selectors_by_mmr(cls, examples, string, embedding_model, k=2):
"""
https://python.langchain.com/docs/modules/model_io/prompts/example_selectors/mmr/
根据与输入最相似的示例的组合来选择示例,同时还针对多样性进行优化。
它通过查找与输入具有最大余弦相似度的嵌入示例来实现这一点,然后迭代地添加它们,同时惩罚它们与已选择示例的接近程度
总的来说就是选出的每个示例尽量都不相相似,不重复
prefix 可以自己定义,显示在开头的
:param examples: 示例列表
e.g examples = [
{"input": "happy", "output": "sad"},
{"input": "tall", "output": "short"},
{"input": "energetic", "output": "lethargic"},
{"input": "sunny", "output": "gloomy"},
{"input": "windy", "output": "calm"},
]
:param string: prompt 字符串
:param examples:
:param embedding_model:
:param k: 选几个示例
:return:
"""
examples = [
{"input": "happy", "output": "sad"},
{"input": "tall", "output": "short"},
{"input": "energetic", "output": "lethargic"},
{"input": "sunny", "output": "gloomy"},
{"input": "windy", "output": "calm"},
]
example_prompt = PromptTemplate(
input_variables=["input", "output"],
template="Input: {input}\nOutput: {output}",
)
example_selector = MaxMarginalRelevanceExampleSelector.from_examples(
examples, embedding_model, FAISS, k=k
)
mmr_prompt = FewShotPromptTemplate(
# We provide an ExampleSelector instead of examples.
example_selector=example_selector,
example_prompt=example_prompt,
prefix="Give the antonym of every input",
suffix="Input: {adjective}\nOutput:",
input_variables=["adjective"],
)
mmr_prompt = mmr_prompt.format(adjective=string)
return mmr_prompt
@classmethod
def example_selectors_similarity(cls, examples, string, embedding_model, k=1):
"""
https://python.langchain.com/docs/modules/model_io/prompts/example_selectors/similarity/
该对象根据与输入的相似性来选择示例。它通过查找与输入具有最大余弦相似度的嵌入示例来实现这一点。
会选择跟 string 相似的示例
:param examples: 示例列表
e.g examples = [
{"input": "happy", "output": "sad"},
{"input": "tall", "output": "short"},
{"input": "energetic", "output": "lethargic"},
{"input": "sunny", "output": "gloomy"},
{"input": "windy", "output": "calm"},
]
:param string:
:param embedding_model:
:param k: 选择几个
:return:
"""
examples = [
{"input": "happy", "output": "sad"},
{"input": "tall", "output": "short"},
{"input": "energetic", "output": "lethargic"},
{"input": "sunny", "output": "gloomy"},
{"input": "windy", "output": "calm"},
]
example_prompt = PromptTemplate(
input_variables=["input", "output"],
template="Input: {input}\nOutput: {output}",
)
example_selector = SemanticSimilarityExampleSelector.from_examples(
examples, embedding_model, Chroma, k=k,
)
similar_prompt = FewShotPromptTemplate(
# We provide an ExampleSelector instead of examples.
example_selector=example_selector,
example_prompt=example_prompt,
prefix="Give the antonym of every input",
suffix="Input: {adjective}\nOutput:",
input_variables=["adjective"],
)
similar_prompt = similar_prompt.format(adjective=string)
return similar_prompt
@classmethod
def few_shot_examples_chat(cls, examples, string, model):
"""
https://python.langchain.com/docs/modules/model_io/prompts/few_shot_examples_chat/#fixed-examples
适用于 chat 模型
system 可以手动设置
:param examples:
e.g examples = [
{"input": "2+2", "output": "4"},
{"input": "2+3", "output": "5"},
]
:param string:
:param model: 大模型
:return:
"""
examples = [
{"input": "2+2", "output": "4"},
{"input": "2+3", "output": "5"},
]
example_prompt = ChatPromptTemplate.from_messages(
[
("human", "{input}"),
("ai", "{output}"),
]
)
few_shot_prompt = FewShotChatMessagePromptTemplate(
example_prompt=example_prompt,
examples=examples,
)
few_shot_prompt = few_shot_prompt.format()
final_prompt = ChatPromptTemplate.from_messages(
[
("system", "You are a wondrous wizard of math."),
few_shot_prompt,
("human", "{input}"),
]
)
chain = final_prompt | model
res = chain.invoke({"input": string})
return res
@classmethod
def few_shot_examples(cls, examples, string, embedding_model, k=1):
"""
https://python.langchain.com/docs/modules/model_io/prompts/few_shot_examples/#create-the-example-set
根据与输入的相似性来选择少数样本。它使用嵌入模型来计算输入和少数样本之间的相似度,并使用向量存储来执行最近邻搜索。
:param examples: 列表,参照 few_shot_examples_chat 样例
:param string:
:param embedding_model:
:return:
"""
examples = [
{
"question": "Who lived longer, Muhammad Ali or Alan Turing?",
"answer": """
Are follow up questions needed here: Yes.
Follow up: How old was Muhammad Ali when he died?
Intermediate answer: Muhammad Ali was 74 years old when he died.
Follow up: How old was Alan Turing when he died?
Intermediate answer: Alan Turing was 41 years old when he died.
So the final answer is: Muhammad Ali
""",
}
]
example_prompt = PromptTemplate(
input_variables=["question", "answer"], template="Question: {question}\n{answer}"
)
example_selector = SemanticSimilarityExampleSelector.from_examples(
examples, embedding_model, Chroma, k=k,
)
prompt = FewShotPromptTemplate(
example_selector=example_selector,
example_prompt=example_prompt,
suffix="Question: {input}",
input_variables=["input"],
)
prompt = prompt.format(input=string)
return prompt
class Chain():
@classmethod
def base_llm_chain(cls, model, prompt, **kwargs):
"""
https://python.langchain.com/docs/modules/model_io/prompts/composition/#string-prompt-composition
基础链,带有变量的 prompt ,model 两个组成链
:param model: llm
:param prompt: prompt 其中的变量是用 {} 括起来的
:param kwargs: prompt 中的变量
:return:
"""
prompt = PromptTemplate.from_template(prompt)
chain = LLMChain(llm=model, prompt=prompt)
res = chain.run(kwargs)
return res
@classmethod
def batch_base_llm_chain(cls, model, prompt, max_concurrency=5, **kwargs):
"""
https://python.langchain.com/docs/modules/model_io/prompts/composition/#string-prompt-composition
基础链,带有变量的 prompt ,model 两个组成链,批次调用
:param model: llm
:param prompt: prompt 其中的变量是用 {} 括起来的
:param kwargs: prompt 中的变量
:param max_concurrency: 并发请求数
e.g:
promt = 'tell me a joke about {other} and {topic2}'
other = ['bear', 'dog']
topic2 = ['cat', 'monkey']
传进来后的 kwargs: kwargs = {'topic1': ['bear', 'dog'], 'topic2': ['cat', 'monkey']}
处理后 batch_list: batch_list = [{"topic1": "bears", "topic2": "cat"}, {"topic1": "dog", "topic2": "monkey"}]
:return:
"""
prompt = PromptTemplate.from_template(prompt)
chain = LLMChain(llm=model, prompt=prompt)
# 确保所有列表长度相同,构造批次列表
keys = list(kwargs.keys())
first_list_length = len(kwargs[keys[0]])
if all(len(kwargs[key]) == first_list_length for key in keys):
# 使用zip函数将所有值配对
paired_values = zip(*[kwargs[key] for key in keys])
# 遍历配对后的值,构造新的字典列表
batch_list = [dict(zip(keys, values)) for values in paired_values]
else:
print("批次对应列表长度不一致,无法转换。")
return None
res = chain.batch(batch_list, config={"max_concurrency": max_concurrency})
return res
@classmethod
def base_chat_llm_chain(cls, model, inputs, **kwargs):
"""
https://python.langchain.com/docs/modules/model_io/prompts/composition/#string-prompt-composition
基础链,对话模型 prompt ,model 两个组成链
:param model:
:param input: 输入
:param kwargs: 可以带一些变量
:return:
"""
prompt = SystemMessage(content="你是个智能助手,能回答各种各样的问题。")
new_prompt = (
prompt + HumanMessage(content="hi") + AIMessage(content="what?") + "{input}"
)
new_prompt.format_messages(input="i said hi")
chain = LLMChain(llm=model, prompt=new_prompt)
res = chain.run(inputs)
return res
@classmethod
def csv_parser_chain(cls, prompt_string, model, **kwargs):
"""
https://python.langchain.com/docs/modules/model_io/output_parsers/types/csv/
列表格式
:param prompt_string: prompt 字符串,里面变量使用 {} 括起来
:param model: llm
:param kwargs: 字典变量
:return:
"""
output_parser = CommaSeparatedListOutputParser()
format_instructions = output_parser.get_format_instructions()
kwargs['format_instructions'] = format_instructions # 格式化输出设置
prompt = PromptTemplate(
template=prompt_string+"\n{format_instructions}",
input_variables=[],
partial_variables=kwargs, # 变量赋值
)
chain = prompt | model | output_parser
res = chain.invoke({})
return res
@classmethod
def datetime_parser_chain(cls, prompt_string, model, **kwargs):
"""
https://python.langchain.com/docs/modules/model_io/output_parsers/types/datetime/
输出时间格式,2009-01-03 18:15:05
:param prompt_string: prompt 字符串,里面变量使用 {} 括起来
:param model: llm
:param kwargs: 字典变量
:return:
"""
output_parser = DatetimeOutputParser()
template = prompt_string + """{format_instructions}"""
kwargs['format_instructions'] = output_parser.get_format_instructions() # 设置输出格式
prompt = PromptTemplate.from_template(
template,
partial_variables=kwargs, # 设置所有变量
)
chain = prompt | model | output_parser
output = chain.invoke({})
return output
@classmethod
def json_parser_chain(cls, prompt_string, model, json_class=None, **kwargs):
"""
https://python.langchain.com/docs/modules/model_io/output_parsers/types/json/
json
:param prompt_string: prompt 字符串,里面变量是已经填充好的
:param model: llm
:param enum_class: json 类,用来指定输出字典的键,也可以不用指定,这样默认就一个键
from langchain_core.pydantic_v1 import BaseModel, Field
e.g class Joke(BaseModel):
setup: str = Field(description="question to set up a joke")
punchline: str = Field(description="answer to resolve the joke")
:param kwargs: 字典变量
:return:
"""
parser = JsonOutputParser(pydantic_object=json_class)
format_instructions = parser.get_format_instructions()
kwargs['format_instructions'] = format_instructions # 格式化输出设置
kwargs['prompt_string'] = prompt_string
prompt = PromptTemplate(
template="Answer the user query.\n{format_instructions}\n{prompt_string}\n",
input_variables=[],
partial_variables=kwargs, # 设置所有变量
)
chain = prompt | model | parser
res = chain.invoke({})
return res
# 模型导入,前边已导入过,直接调用即可
# llm = LLM()
# tongyi_model = llm.tongyi_qwen_plus(temperature=0.9) # 调用通义千问 7B Chat 模型并打印信息
query = '它涉及使用物理学的原理和方法来探测、分析和解释地球的内部结构、地球表面的动态变化,以及地球与周围空间环境的相互作用。'
prompt = f"""
你是一个专业分类专家,你能帮助用户识别描述中的专业。请用中文回答,直接输出描述对应的专业名称,以及你的推理过程。
以下是专业描述:```{query}```
"""
no_rag_res = Chain.base_chat_llm_chain(tongyi_model,prompt,query=query)
no_rag_res
/opt/conda/lib/python3.11/site-packages/langchain_core/_api/deprecation.py:119: LangChainDeprecationWarning: The method `Chain.run` was deprecated in langchain 0.1.0 and will be removed in 0.2.0. Use invoke instead.
warn_deprecated(
'这个描述对应的专业是地质物理学。推理过程如下:描述中提到了使用物理学的原理和方法来研究地球的内部结构、地球表面的变化及地球与周围空间环境的相互作用,这些内容都是地质物理学研究的核心领域。地质物理学是一门交叉学科,结合了地质学与物理学的知识,旨在通过物理方法探索和理解地球的各种现象。'
Task5 参考 langchian 文档任意选一种检索方法,先检索后再让大模型去回答,打印出大模型回答效果,对比与 Task4 的结果是否有区别
跟 Task4 相同的问题,参考 langchian 文档任意选一种检索方法,先检索后再让大模型去回答,打印出大模型回答效果,对比与 Task4 的结果是否有区别
可以多搞一些问题进行对比观察。
class Retriever():
@classmethod
def similarity(cls, db, query, topk=5, long_context=False):
"""
https://python.langchain.com/docs/modules/data_connection/retrievers/vectorstore/
https://python.langchain.com/docs/modules/data_connection/retrievers/long_context_reorder/
相似度,不带分数的,会把检索出所有最相似的返回,如果文档中有重复的,那会返回重复的
:param db:
:param query:
:param long_context: 长上下文排序
:return:
"""
retriever = db.as_retriever(search_kwargs={'k': topk})
retriever_docs = retriever.get_relevant_documents(query)
if long_context:
reordering = LongContextReorder()
retriever_docs = reordering.transform_documents(retriever_docs)
return retriever_docs
@classmethod
def similarity_with_score(cls, db, query, topk=5, long_context=False):
"""
https://python.langchain.com/docs/integrations/vectorstores/usearch/#similarity-search-with-score
https://python.langchain.com/docs/modules/data_connection/retrievers/long_context_reorder/
带分数的,距离分数是L2距离。因此,分数越低越好
:param db:
:param query:
:param long_context: 长上下文排序
:return:
"""
retriever_docs = db.similarity_search_with_score(query, k=topk)
if long_context:
reordering = LongContextReorder()
retriever_docs = reordering.transform_documents(retriever_docs)
return retriever_docs
@classmethod
def mmr(cls, db, query, topk=5, fetch_k=50, long_context=False):
"""
https://python.langchain.com/docs/modules/data_connection/retrievers/vectorstore/
https://python.langchain.com/docs/modules/data_connection/retrievers/long_context_reorder/
mmr 算法会去重,会把检索出所有最相似的返回
:param db:
:param query:
:param topk: 指定最相似的返回几个, 最多返回的数量不会超过 fetch_k
:param fetch_k: 给 mmr 的最多文档数
:param long_context: 长上下文排序
:return:
"""
retriever = db.as_retriever(search_type="mmr", ssearch_kwargs={'k': topk, 'fetch_k': fetch_k})
retriever_docs = retriever.get_relevant_documents(query)
if long_context:
reordering = LongContextReorder()
retriever_docs = reordering.transform_documents(retriever_docs)
return retriever_docs
@classmethod
def similarity_score_threshold(cls, db, query, topk=5, score_threshold=0.8, long_context=False):
"""
https://python.langchain.com/docs/modules/data_connection/retrievers/long_context_reorder/
相似分数过滤
:param db:
:param query:
:param topk:
:param score_threshold: 相似分数
:param long_context: 长上下文排序
:return:
"""
retriever = db.as_retriever(search_type="similarity_score_threshold",
search_kwargs={'k': topk, "score_threshold": score_threshold})
retriever_docs = retriever.get_relevant_documents(query)
if long_context:
reordering = LongContextReorder()
retriever_docs = reordering.transform_documents(retriever_docs)
return retriever_docs
@classmethod
def multi_query_retriever(cls, db, query, model, topk=5, long_context=False):
"""
https://python.langchain.com/docs/modules/data_connection/retrievers/MultiQueryRetriever/
https://python.langchain.com/docs/modules/data_connection/retrievers/long_context_reorder/
多查询检索器
基于向量距离的检索可能因微小的询问词变化或向量无法准确表达语义而产生不同结果;
使用大预言模型自动从不同角度生成多个查询,实现提示词优化;
对用户查询生成表达其不同方面的多个新查询(也就是query利用大模型生成多个表述),对每个表述进行检索,去结果的并集;
优点是生成的查询多角度,可以覆盖更全面的语义和信息需求;
指定 topk 好像没用,不知道为什么
:param db:
:param query:
:param long_context: 长上下文排序
:return:
"""
retriever = db.as_retriever(search_kwargs={'k': topk})
retriever = MultiQueryRetriever.from_llm(retriever=retriever, llm=model)
retriever_docs = retriever.get_relevant_documents(query=query)
if long_context:
reordering = LongContextReorder()
retriever_docs = reordering.transform_documents(retriever_docs)
return retriever_docs
@classmethod
def contextual_compression_by_llm(cls, db, query, model, topk=5, long_context=False):
"""
https://python.langchain.com/docs/modules/data_connection/retrievers/contextual_compression/
https://python.langchain.com/docs/modules/data_connection/retrievers/long_context_reorder/
上下文压缩检索器,大模型,会对结果去重
使用给定查询的上下文来压缩检索的输出,以便只返回相关信息,而不是立即按照原样返回检索到的文档
相当于提取每个检索结果的核心,简化每个文档,利用大模型的能力
不知道为什么 topk 不管用
:param db:
:param query:
:param model:
:param topk:
:param long_context: 长上下文排序
:return:
"""
_filter = LLMChainFilter.from_llm(model)
retriever = db.as_retriever(search_kwargs={'k': topk})
compression_retriever = ContextualCompressionRetriever(
base_compressor=_filter, base_retriever=retriever
)
retriever_docs = compression_retriever.get_relevant_documents(query)
if long_context:
reordering = LongContextReorder()
retriever_docs = reordering.transform_documents(retriever_docs)
return retriever_docs
@classmethod
def contextual_compression_by_embedding(cls, db, query, embedding_model, topk=5, similarity_threshold=0.76,
long_context=False):
"""
https://python.langchain.com/docs/modules/data_connection/retrievers/contextual_compression/
https://python.langchain.com/docs/modules/data_connection/retrievers/long_context_reorder/
上下文压缩检索器,embedding 模型,会对结果去重
使用给定查询的上下文来压缩检索的输出,以便只返回相关信息,而不是立即按照原样返回检索到的文档
利用 embedding 来计算
:param db:
:param query:
:param embedding_model:
:param topk:
:param long_context: 长上下文排序
:return:
"""
retriever = db.as_retriever(search_kwargs={'k': topk})
embeddings_filter = EmbeddingsFilter(embeddings=embedding_model, similarity_threshold=similarity_threshold)
compression_retriever = ContextualCompressionRetriever(
base_compressor=embeddings_filter, base_retriever=retriever
)
retriever_docs = compression_retriever.get_relevant_documents(query)
if long_context:
reordering = LongContextReorder()
retriever_docs = reordering.transform_documents(retriever_docs)
return retriever_docs
@classmethod
def contextual_compression_by_embedding_split(cls, db, query, embedding_model, topk=5, similarity_threshold=0.76,
chunk_size=100, chunk_overlap=0, separator=". ", long_context=False):
"""
https://python.langchain.com/docs/modules/data_connection/retrievers/contextual_compression/
https://python.langchain.com/docs/modules/data_connection/retrievers/long_context_reorder/
上下文压缩检索器,embedding 模型,会对结果去重,将文档分割成更小的部分
使用给定查询的上下文来压缩检索的输出,以便只返回相关信息,而不是立即按照原样返回检索到的文档
利用 embedding 来计算
:param db:
:param query:
:param embedding_model:
:param topk: 不生效,默认是 4 个
:param long_context: 长上下文排序
:return:
"""
retriever = db.as_retriever(search_kwargs={'k': topk})
splitter = CharacterTextSplitter(chunk_size=chunk_size, chunk_overlap=chunk_overlap, separator=separator)
redundant_filter = EmbeddingsRedundantFilter(embeddings=embedding_model)
relevant_filter = EmbeddingsFilter(embeddings=embedding_model, similarity_threshold=similarity_threshold)
pipeline_compressor = DocumentCompressorPipeline(
transformers=[splitter, redundant_filter, relevant_filter]
)
compression_retriever = ContextualCompressionRetriever(
base_compressor=pipeline_compressor, base_retriever=retriever
)
retriever_docs = compression_retriever.get_relevant_documents(query)
if long_context:
reordering = LongContextReorder()
retriever_docs = reordering.transform_documents(retriever_docs)
return retriever_docs
@classmethod
def ensemble(cls, query, text_split_docs, embedding_model, bm25_topk=5, topk=5, long_context=False):
"""
https://python.langchain.com/docs/modules/data_connection/retrievers/ensemble/
https://python.langchain.com/docs/modules/data_connection/retrievers/long_context_reorder/
混合检索
最常见的模式是将稀疏检索器(如 BM25)与密集检索器(如嵌入相似性)相结合,因为它们的优势是互补的。它也被称为“混合搜索”。
稀疏检索器擅长根据关键词查找相关文档,而密集检索器擅长根据语义相似度查找相关文档。
:param query:
:param text_split_docs: langchain 分割后的文档对象
:param long_context: 长上下文排序
:param bm25_topk: bm25 topk
:param topk: 相似性 topk
:return: 会返回两个的并集,结果可能会小于 bm25_topk + topk
"""
text_split_docs = [text.page_content for text in text_split_docs]
bm25_retriever = BM25Retriever.from_texts(
text_split_docs, metadatas=[{"source": 1}] * len(text_split_docs)
)
bm25_retriever.k = bm25_topk
faiss_vectorstore = FAISS.from_texts(
text_split_docs, embedding_model, metadatas=[{"source": 2}] * len(text_split_docs)
)
faiss_retriever = faiss_vectorstore.as_retriever(search_kwargs={"k": topk})
ensemble_retriever = EnsembleRetriever(
retrievers=[bm25_retriever, faiss_retriever], weights=[0.5, 0.5]
)
retriever_docs = ensemble_retriever.invoke(query)
if long_context:
reordering = LongContextReorder()
retriever_docs = reordering.transform_documents(retriever_docs)
return retriever_docs
@classmethod
def bm25(cls, query, text_split_docs, topk=5, long_context=False):
"""
https://python.langchain.com/docs/modules/data_connection/retrievers/long_context_reorder/
稀疏检索器擅长根据关键词查找相关文档
:param query:
:param text_split_docs: langchain 分割后的文档对象
:param topk:
:param long_context: 长上下文压缩
"""
text_split_docs = [text.page_content for text in text_split_docs]
bm25_retriever = BM25Retriever.from_texts(
text_split_docs, metadatas=[{"source": 1}] * len(text_split_docs)
)
bm25_retriever.k = topk
retriever_docs = bm25_retriever.get_relevant_documents(query)
if long_context:
reordering = LongContextReorder()
retriever_docs = reordering.transform_documents(retriever_docs)
return retriever_docs
@classmethod
def parent_document_retriever(cls, docs, query, embedding_model):
"""
https://python.langchain.com/docs/modules/data_connection/retrievers/parent_document_retriever/
https://python.langchain.com/docs/modules/data_connection/retrievers/long_context_reorder/
父文档检索,只适合,chroma 数据库, faiss 不支持
适合多个文档加载进来后检索出符合的小文本段,及对应大的 txt
可以根据此方法,检索出来大的 txt 后,用其他方法再精细化检索 txt 中的内容
:param docs: example
loaders = [
TextLoader("data/专业描述.txt", encoding="utf-8"),
TextLoader("data/专业描述_copy.txt", encoding="utf-8"),
]
docs = []
for loader in loaders:
docs.extend(loader.load())
:return:
"""
child_splitter = RecursiveCharacterTextSplitter(chunk_size=400)
vectorstore = Chroma(
collection_name="full_documents", embedding_function=embedding_model
)
store = InMemoryStore()
retriever = ParentDocumentRetriever(
vectorstore=vectorstore,
docstore=store,
child_splitter=child_splitter,
)
retriever.add_documents(docs, ids=None)
sub_docs = vectorstore.similarity_search(query)
parent_docs = retriever.get_relevant_documents(query)
return sub_docs, parent_docs
@classmethod
def tfidf(cls, query, docs_lst, long_context=False):
"""
https://python.langchain.com/docs/modules/data_connection/retrievers/long_context_reorder/
tfidf 关键词检索
:param query:
:param docs_lst: ['xxx', 'dsfsdg'.....]
:param long_context: 长上下文排序
:return:
"""
retriever = TFIDFRetriever.from_texts(docs_lst)
retriever_docs = retriever.get_relevant_documents(query)
if long_context:
reordering = LongContextReorder()
retriever_docs = reordering.transform_documents(retriever_docs)
return retriever_docs
@classmethod
def knn(cls, query, docs_lst, embedding_model,long_context=False):
"""
https://python.langchain.com/docs/modules/data_connection/retrievers/long_context_reorder/
knn 检索
:param query:
:param docs_lst: ['xxx', 'dsfsdg'.....]
:param long_context:
:return:
"""
retriever = KNNRetriever.from_texts(docs_lst, embedding_model)
retriever_docs = retriever.get_relevant_documents(query)
if long_context:
reordering = LongContextReorder()
retriever_docs = reordering.transform_documents(retriever_docs)
return retriever_docs
回答1及点评:
# Your Answer
# 查找相关知识库
recall = Retriever.similarity(db,query)
reference_info = [r.page_content for r in recall]
# 模型导入,前边已导入过,直接调用即可
# llm = LLM()
# tongyi_model = llm.tongyi_qwen_plus(temperature=0.9) # 调用通义千问 plus 模型并打印信息
query = '它涉及使用物理学的原理和方法来探测、分析和解释地球的内部结构、地球表面的动态变化,以及地球与周围空间环境的相互作用。'
prompt = f"""
你是一个专业分类专家,你能结合相关描述及参考信息帮助用户识别描述中的专业。请用中文回答,直接输出描述对应的专业名称,以及你的推理过程。以下是专业描述:
```{query}```
以下是参考信息:
```{reference_info}```
"""
rag_res = Chain.base_chat_llm_chain(tongyi_model,prompt,query=query,reference_info=reference_info)
rag_res
'该描述对应的专业是地球物理学。推理过程如下:\n\n1. 描述中提到了“使用物理学的原理和方法”,这表明该专业与物理学密切相关。\n2. 描述还提到了研究对象包括“地球的内部结构”、“地球表面的动态变化”以及“地球与周围空间环境的相互作用”,这些都是地球物理学的研究内容。\n3. 参考信息给出的是材料科学与工程专业的描述,与题目中的描述不符。\n\n综上所述,根据题目描述的专业特征,可以判断这是地球物理学专业。'
导师点评:挺好的,这代码有参考我的github,基本都扣下来了💪 ,但是从效果来看,参考信息可能不太好,这时候需要考虑换检索方法,或者改变topk
回答2及点评:
# # Your Answer2
# 查找相关知识库
recall = Retriever.similarity(db,query,topk=1)
reference_info = [r.page_content for r in recall]
# 模型导入,前边已导入过,直接调用即可
# llm = LLM()
# tongyi_model = llm.tongyi_qwen_plus(temperature=0.9) # 调用通义千问 plus 模型并打印信息
query = '它涉及使用物理学的原理和方法来探测、分析和解释地球的内部结构、地球表面的动态变化,以及地球与周围空间环境的相互作用。'
prompt = f"""
你是一个专业分类专家,你能结合相关描述及参考信息帮助用户识别描述中的专业。请用中文回答,直接输出描述对应的专业名称,以及你的推理过程。以下是专业描述:
```{query}```
以下是参考信息:
```{reference_info}```
"""
rag_res2 = Chain.base_chat_llm_chain(tongyi_model,prompt,query=query,reference_info=reference_info)
rag_res2
'该描述对应的专业是地球物理学。推理过程如下:\n\n描述中提到了“使用物理学的原理和方法来探测、分析和解释地球的内部结构、地球表面的动态变化,以及地球与周围空间环境的相互作用”,这明显指向了地球物理学这一学科。地球物理学主要通过物理手段研究地球的性质,包括但不限于地球的重力场、磁场、地震波传播特性等,以揭示地球内部结构、地壳运动规律及其与其他空间环境的相互作用机制。\n\n参考信息给出的是关于材料科学与工程专业的介绍,并不与上述描述内容相匹配。因此,根据描述内容判断,这里所指的专业应为地球物理学。'
自评:限制topk=1后反而结果出错了,是因为返回的参考信息变少了?考虑增大topk
回答3及点评:
# # Your Answer3
# 查找相关知识库
recall = Retriever.similarity(db,query,topk=20)
reference_info = [r.page_content for r in recall]
# 模型导入,前边已导入过,直接调用即可
# llm = LLM()
# tongyi_model = llm.tongyi_qwen_plus(temperature=0.9) # 调用通义千问 plus 模型并打印信息
query = '它涉及使用物理学的原理和方法来探测、分析和解释地球的内部结构、地球表面的动态变化,以及地球与周围空间环境的相互作用。'
prompt = f"""
你是一个专业分类专家,你能结合相关描述及参考信息帮助用户识别描述中的专业。请用中文回答,直接输出描述对应的专业名称,以及你的推理过程。以下是专业描述:
```{query}```
以下是参考信息:
```{reference_info}```
"""
rag_res3 = Chain.base_chat_llm_chain(tongyi_model,prompt,query=query,reference_info=reference_info)
rag_res3
'该描述对应的专业是地球物理学。推理过程如下:\n\n描述中提到了“使用物理学的原理和方法来探测、分析和解释地球的内部结构、地球表面的动态变化,以及地球与周围空间环境的相互作用”,这明显指向了一个专注于研究地球物理特性的学科。地球物理学正是这样一门学科,它利用物理学原理和技术来研究地球的结构、动力学过程及其与空间环境的相互作用。因此,根据描述的内容,可以判断出这是地球物理学的专业描述。'
自评:k从10->15->20参考信息才有被正确检索出来,看来想要好的效果还需继续更换检索方法
回答4及点评:
# similarity_with_score(cls, db, query, topk=5, long_context=False)
# # Your Answer4
# 查找相关知识库
recall = Retriever.similarity_with_score(db,query,topk=20)
# reference_info = [r.page_content for r in recall] # 词句不能使用的原因是 该方法返回 (document, score) 的元组列表,你需要先解包元组
reference_info = [r[0].page_content for r in recall]
# 模型导入,前边已导入过,直接调用即可
# llm = LLM()
# tongyi_model = llm.tongyi_qwen_plus(temperature=0.9) # 调用通义千问 plus 模型并打印信息
query = '它涉及使用物理学的原理和方法来探测、分析和解释地球的内部结构、地球表面的动态变化,以及地球与周围空间环境的相互作用。'
prompt = f"""
你是一个专业分类专家,你能结合相关描述及参考信息帮助用户识别描述中的专业。请用中文回答,直接输出描述对应的专业名称,以及你的推理过程。以下是专业描述:
```{query}```
以下是参考信息:
```{reference_info}```
"""
rag_res4 = Chain.base_chat_llm_chain(tongyi_model,prompt,query=query,reference_info=reference_info)
rag_res4
'该描述对应的专业是地球物理学。推理过程如下:\n\n1. 描述中提到了“使用物理学的原理和方法”,这表明该专业与物理学密切相关。\n2. 描述还提到了研究对象包括“地球的内部结构”、“地球表面的动态变化”以及“地球与周围空间环境的相互作用”,这些都是地球物理学的研究内容。\n3. 参考信息给出的是材料科学与工程专业的描述,与题目中的描述不符。\n\n综上所述,根据题目描述的专业特点,可以判断这是地球物理学专业。'
自评:可以看出similarity_with_score的检索方式虽然能够正确检索,但是topk也需要调到一个相对大的值
回答5及点评:
# mmr(cls, db, query, topk=5, fetch_k=50, long_context=False):
# # Your Answer5
# 查找相关知识库
recall = Retriever.mmr(db,query,topk=10)
print(f"Number of documents returned: {len(recall)}") # 确认实际返回的文档数量
print(type(recall[0]),recall[0],recall[1])
# print(recall[2],recall[3]) # IndexError: list index out of range
reference_info = [r.page_content for r in recall]
# reference_info = [r[0].page_content for r in recall]
# 模型导入,前边已导入过,直接调用即可
# llm = LLM()
# tongyi_model = llm.tongyi_qwen_plus(temperature=0.9) # 调用通义千问 plus 模型并打印信息
query = '它涉及使用物理学的原理和方法来探测、分析和解释地球的内部结构、地球表面的动态变化,以及地球与周围空间环境的相互作用。'
prompt = f"""
你是一个专业分类专家,你能结合相关描述及参考信息帮助用户识别描述中的专业。请用中文回答,直接输出描述对应的专业名称,以及你的推理过程。以下是专业描述:
```{query}```
以下是参考信息:
```{reference_info}```
"""
Number of documents returned: 2
<class 'langchain_core.documents.base.Document'> page_content='介绍: 材料科学与工程是一门研究材料的组成、性质、制备、加工及应用的多学科交叉领域。它涵盖了金属、无机非金属、高分子、复合材料等各类材料的基础理论与技术,旨在开发新型功能材料,提升传统材料性能,为工业制造、科技发展和环境保护提供关键支撑。学生将学习材料设计、实验方法、数据分析等技能,未来就业方向广泛,如材料研发、生产、质检等领域。' page_content='专业: 材料科学与工程'
rag_res5 = Chain.base_chat_llm_chain(tongyi_model,prompt,query=query,reference_info=reference_info)
rag_res5
'该描述对应的专业是地球物理学。推理过程如下:\n\n1. 描述中提到了“使用物理学的原理和方法”,这表明该专业与物理学密切相关。\n2. 描述还提到了研究对象包括“地球的内部结构”、“地球表面的动态变化”以及“地球与周围空间环境的相互作用”,这些都是地球物理学的研究内容。\n3. 参考信息给出的是材料科学与工程专业的描述,与题目中的描述不符。\n\n综上所述,根据题目描述的专业特征,可以判断这是地球物理学专业。'
结果仍然不理想,可能是我在描述时刻意模糊关键词导致的?哈哈哈。此外topk设置后,输出的结果不同是否可以认为检索结果具备一定的随机性,和模型temperature的值有关?以及虽然检索topk,但是实际recall只返回最佳结果?否则为啥recall[2],recall[3]打印不出来
进一步改进:改为更明确的描述
关于疑问的解答(by:GPT):
1. 检索结果的随机性和模型 temperature 的关系
检索过程 和 生成过程 是两个不同的阶段:
-
检索过程:涉及向量化的查询和文档之间的相似度计算。这个过程通常是确定性的,即相同的查询和相同的文档集在同样的检索条件下(如
topk),应当返回相同的结果。检索结果的随机性通常不会受到模型temperature的影响。 -
生成过程:当使用语言模型生成文本时,
temperature参数会影响生成的随机性。temperature越高,生成结果的多样性就越大,内容可能会更加随机。
因此,检索结果的随机性 通常与 temperature 无关,而与具体的检索算法和实现细节有关。
2. 检索过程中的 topk 和 recall 返回结果
topk 设置:
topk是检索时你希望返回的最高相似性文档的数量。设置topk=5意味着你期望返回 5 个最相关的文档。
recall 返回的结果:
- 如果
recall返回的结果只有 1 个,甚至比topk设置的数量少,那么可能有以下几种原因:- 实际匹配的文档数量不足:在数据库中,可能只有 1 个文档与查询有较高的相似度,其他文档不满足
topk要求的相似性阈值。 - 检索函数限制:具体实现的检索函数可能设置了额外的限制条件,例如只返回相似度高于某个阈值的文档。
- 调试或编码错误:如果你期望多个结果,但只返回了一个,可能是代码中存在问题,或者库的使用方式不正确。
- 实际匹配的文档数量不足:在数据库中,可能只有 1 个文档与查询有较高的相似度,其他文档不满足
3. 确认检索结果的数量和内容
你可以通过检查 recall 的长度来确认实际返回的文档数量,并输出所有结果以确认其内容。
# 确认实际返回的文档数量
print(f"Number of documents returned: {len(recall)}")
# 输出所有返回的文档内容
for i, doc in enumerate(recall):
print(f"Document {i}: {doc[0].page_content if isinstance(doc, tuple) else doc.page_content}")
4. 为什么 recall[2], recall[3] 打印不出来?
可能原因包括:
recall中的文档数量少于topk:例如,如果recall只包含 1 个或 2 个文档,尝试访问recall[2]或recall[3]会超出索引范围并导致错误。- 意外的代码行为或错误:如果存在逻辑错误或实现上的问题,可能导致预期数量的结果未能返回。
总结
- 检索结果的随机性 通常与模型的
temperature无关,更多地依赖于检索算法和实现。 topk设置 定义了期望的返回文档数量,但实际返回的数量可能因多种因素而少于topk。- 通过检查
recall的长度和内容,可以更好地理解检索结果的实际行为。
如果你有更多问题或需要进一步解释,请随时告诉我!
回答6及点评:
# # Your Answer6
# 查找相关知识库
recall = Retriever.similarity(db,query,topk = 2)
reference_info = [r.page_content for r in recall]
print(f"Number of documents returned: {len(recall)}") # 确认实际返回的文档数量
print(type(recall[0]),recall[0],recall[1])
# print(recall[2],recall[3]) # IndexError: list index out of range
# 模型导入,前边已导入过,直接调用即可
# llm = LLM()
# tongyi_model = llm.tongyi_qwen_plus(temperature=0.9) # 调用通义千问 plus 模型并打印信息
# 注意这里我的描述有修正
query = '它涉及使用物理学的原理和方法来探测、分析和解释地球的内部结构、地球表面的动态变化,以及地球与周围空间环境的相互作用。地球物理学研究的范围广泛,涵盖从地球内部到地球外层空间的多个层次。'
prompt = f"""
你是一个专业分类专家,你能结合相关描述及参考信息帮助用户识别描述中的专业。请用中文回答,直接输出描述对应的专业名称,以及你的推理过程。以下是专业描述:
```{query}```
以下是参考信息:
```{reference_info}```
"""
Number of documents returned: 2
<class 'langchain_core.documents.base.Document'> page_content='介绍: 材料科学与工程是一门研究材料的组成、性质、制备、加工及应用的多学科交叉领域。它涵盖了金属、无机非金属、高分子、复合材料等各类材料的基础理论与技术,旨在开发新型功能材料,提升传统材料性能,为工业制造、科技发展和环境保护提供关键支撑。学生将学习材料设计、实验方法、数据分析等技能,未来就业方向广泛,如材料研发、生产、质检等领域。' page_content='专业: 材料科学与工程'
rag_res6 = Chain.base_chat_llm_chain(tongyi_model,prompt,query=query,reference_info=reference_info)
rag_res6
自评:修改描述后recall结果仍然不是自己想要的,并不是描述的问题,有待后续进一步测试
回答7及点评: 较好的回答,打印所有召回方法,选最好的用
import pandas as pd
# 设定特定查询
query = '它涉及使用物理学的原理和方法来探测、分析和解释地球的内部结构、地球表面的动态变化,以及地球与周围空间环境的相互作用。'
# 召回相似的文档,对比所有方法,看看哪个召回率高
similarity_result = Retriever.similarity(db, query, topk=30)
similarity_with_score_result = Retriever.similarity_with_score(db, query, topk=30)
mmr_result = Retriever.mmr(db, query, topk=30)
similarity_score_threshold_result = Retriever.similarity_score_threshold(db, query, topk=30, score_threshold=0.2)
contextual_compression_result = Retriever.contextual_compression_by_embedding(db, query, embedding, topk=30, similarity_threshold=0.2)
contextual_compression_split_result = Retriever.contextual_compression_by_embedding_split(db, query, embedding, topk=30, similarity_threshold=0.2, chunk_size=10)
ensemble_result = Retriever.ensemble(query, text_split, embedding, bm25_topk=15, topk=15)
bm25_result = Retriever.bm25(query, text_split, topk=30)
parent_document_result, parent_docs = Retriever.parent_document_retriever(docs, query, embedding)
tfidf_result = Retriever.tfidf(query, [doc.page_content.split('\n') for doc in docs][0])
knn_result = Retriever.knn(query, [doc.page_content.split('\n') for doc in docs][0], embedding)
multi_query_result = Retriever.multi_query_retriever(db, query, tongyi_model)
contextual_compression_llm_result = Retriever.contextual_compression_by_llm(db, query, tongyi_model)
# 打印各个方法的召回结果
print("Similarity Result:", [doc.page_content for doc in similarity_result])
print("Similarity with Score Result:", [doc[0].page_content for doc in similarity_with_score_result])
print("MMR Result:", [doc.page_content for doc in mmr_result])
print("Similarity Score Threshold Result:", [doc.page_content for doc in similarity_score_threshold_result])
print("Contextual Compression Result:", [doc.page_content for doc in contextual_compression_result])
print("Contextual Compression Split Result:", [doc.page_content for doc in contextual_compression_split_result])
print("Ensemble Result:", [doc.page_content for doc in ensemble_result])
print("BM25 Result:", [doc.page_content for doc in bm25_result])
print("Parent Document Result:", [doc.page_content for doc in parent_document_result])
print("TFIDF Result:", tfidf_result)
print("KNN Result:", knn_result)
print("Multi Query Result:", [doc.page_content for doc in multi_query_result])
print("Contextual Compression LLM Result:", [doc.page_content for doc in contextual_compression_llm_result])
# 使用一种方法的结果作为模型输入
retriever_label = [doc.page_content.split('\t')[0] for doc in parent_document_result]
prompt = f"""
**角色设定:**
你是一个专业分类专家,你能帮助用户识别描述中的专业。
**任务:**
你需要识别描述中的专业,并从专业列表中选出最相关的专业名称。
**决策规则:**
- 给出的专业必须来自于专业列表中列出的专业。
- 仔细分析描述中出现的专业名词,判断它们是否指向特定的专业。
- 让我们一步一步来思考。
- 识别出最相关的专业名称。
**输出:**
- 直接输出选出的专业名称,以及你的推理过程。
**以下是描述及专业列表:**
- 描述:{query}
- 专业列表:{retriever_label}
"""
# 调用模型生成回答
res = Chain.base_llm_chain(tongyi_model, prompt)
print(f"模型返回结果:{res}")
/opt/conda/lib/python3.11/site-packages/langchain/chains/llm.py:316: UserWarning: The predict_and_parse method is deprecated, instead pass an output parser directly to LLMChain.
warnings.warn(
/opt/conda/lib/python3.11/site-packages/langchain/chains/llm.py:316: UserWarning: The predict_and_parse method is deprecated, instead pass an output parser directly to LLMChain.
warnings.warn(
Similarity Result: ['介绍: 材料科学与工程是一门研究材料的组成、性质、制备、加工及应用的多学科交叉领域。它涵盖了金属、无机非金属、高分子、复合材料等各类材料的基础理论与技术,旨在开发新型功能材料,提升传统材料性能,为工业制造、科技发展和环境保护提供关键支撑。学生将学习材料设计、实验方法、数据分析等技能,未来就业方向广泛,如材料研发、生产、质检等领域。', '专业: 材料科学与工程']
Similarity with Score Result: ['介绍: 材料科学与工程是一门研究材料的组成、性质、制备、加工及应用的多学科交叉领域。它涵盖了金属、无机非金属、高分子、复合材料等各类材料的基础理论与技术,旨在开发新型功能材料,提升传统材料性能,为工业制造、科技发展和环境保护提供关键支撑。学生将学习材料设计、实验方法、数据分析等技能,未来就业方向广泛,如材料研发、生产、质检等领域。', '专业: 材料科学与工程']
MMR Result: ['介绍: 材料科学与工程是一门研究材料的组成、性质、制备、加工及应用的多学科交叉领域。它涵盖了金属、无机非金属、高分子、复合材料等各类材料的基础理论与技术,旨在开发新型功能材料,提升传统材料性能,为工业制造、科技发展和环境保护提供关键支撑。学生将学习材料设计、实验方法、数据分析等技能,未来就业方向广泛,如材料研发、生产、质检等领域。', '专业: 材料科学与工程']
Similarity Score Threshold Result: ['介绍: 材料科学与工程是一门研究材料的组成、性质、制备、加工及应用的多学科交叉领域。它涵盖了金属、无机非金属、高分子、复合材料等各类材料的基础理论与技术,旨在开发新型功能材料,提升传统材料性能,为工业制造、科技发展和环境保护提供关键支撑。学生将学习材料设计、实验方法、数据分析等技能,未来就业方向广泛,如材料研发、生产、质检等领域。']
Contextual Compression Result: ['介绍: 材料科学与工程是一门研究材料的组成、性质、制备、加工及应用的多学科交叉领域。它涵盖了金属、无机非金属、高分子、复合材料等各类材料的基础理论与技术,旨在开发新型功能材料,提升传统材料性能,为工业制造、科技发展和环境保护提供关键支撑。学生将学习材料设计、实验方法、数据分析等技能,未来就业方向广泛,如材料研发、生产、质检等领域。', '专业: 材料科学与工程']
Contextual Compression Split Result: ['介绍: 材料科学与工程是一门研究材料的组成、性质、制备、加工及应用的多学科交叉领域。它涵盖了金属、无机非金属、高分子、复合材料等各类材料的基础理论与技术,旨在开发新型功能材料,提升传统材料性能,为工业制造、科技发展和环境保护提供关键支撑。学生将学习材料设计、实验方法、数据分析等技能,未来就业方向广泛,如材料研发、生产、质检等领域。', '专业: 材料科学与工程']
Ensemble Result: ['介绍: 材料科学与工程是一门研究材料的组成、性质、制备、加工及应用的多学科交叉领域。它涵盖了金属、无机非金属、高分子、复合材料等各类材料的基础理论与技术,旨在开发新型功能材料,提升传统材料性能,为工业制造、科技发展和环境保护提供关键支撑。学生将学习材料设计、实验方法、数据分析等技能,未来就业方向广泛,如材料研发、生产、质检等领域。', '专业: 材料科学与工程']
BM25 Result: ['介绍: 材料科学与工程是一门研究材料的组成、性质、制备、加工及应用的多学科交叉领域。它涵盖了金属、无机非金属、高分子、复合材料等各类材料的基础理论与技术,旨在开发新型功能材料,提升传统材料性能,为工业制造、科技发展和环境保护提供关键支撑。学生将学习材料设计、实验方法、数据分析等技能,未来就业方向广泛,如材料研发、生产、质检等领域。', '专业: 材料科学与工程']
Parent Document Result: ['专业: 地球物理学\n介绍: 地球物理学是一门研究地球内部结构、物理性质及其变化规律的科学。它结合地质学、物理学和数学方法,通过地震波探测、磁力测量等手段,解析地壳、地幔、地核的构成与运动,探索自然资源分布,预防地质灾害,为矿产勘探、环境保护等领域提供技术支持。', '专业: 地球物理学\n介绍: 地球物理学是一门研究地球内部结构、物理性质及其变化规律的科学。它结合地质学、物理学和数学方法,通过地震波探测、磁力测量等手段,解析地壳、地幔、地核的构成与运动,探索自然资源分布,预防地质灾害,为矿产勘探、环境保护等领域提供技术支持。', '专业: 地球物理学\n介绍: 地球物理学是一门研究地球内部结构、物理性质及其变化规律的科学。它结合地质学、物理学和数学方法,通过地震波探测、磁力测量等手段,解析地壳、地幔、地核的构成与运动,探索自然资源分布,预防地质灾害,为矿产勘探、环境保护等领域提供技术支持。', '专业: 地球物理学\n介绍: 地球物理学是一门研究地球内部结构、物理性质及其变化规律的科学。它结合地质学、物理学和数学方法,通过地震波探测、磁力测量等手段,解析地壳、地幔、地核的构成与运动,探索自然资源分布,预防地质灾害,为矿产勘探、环境保护等领域提供技术支持。']
TFIDF Result: [Document(page_content='介绍: 材料科学与工程是一门研究材料的组成、性质、制备、加工及应用的多学科交叉领域。它涵盖了金属、无机非金属、高分子、复合材料等各类材料的基础理论与技术,旨在开发新型功能材料,提升传统材料性能,为工业制造、科技发展和环境保护提供关键支撑。学生将学习材料设计、实验方法、数据分析等技能,未来就业方向广泛,如材料研发、生产、质检等领域。'), Document(page_content='专业: 材料科学与工程')]
KNN Result: [Document(page_content='介绍: 材料科学与工程是一门研究材料的组成、性质、制备、加工及应用的多学科交叉领域。它涵盖了金属、无机非金属、高分子、复合材料等各类材料的基础理论与技术,旨在开发新型功能材料,提升传统材料性能,为工业制造、科技发展和环境保护提供关键支撑。学生将学习材料设计、实验方法、数据分析等技能,未来就业方向广泛,如材料研发、生产、质检等领域。'), Document(page_content='专业: 材料科学与工程')]
Multi Query Result: ['介绍: 材料科学与工程是一门研究材料的组成、性质、制备、加工及应用的多学科交叉领域。它涵盖了金属、无机非金属、高分子、复合材料等各类材料的基础理论与技术,旨在开发新型功能材料,提升传统材料性能,为工业制造、科技发展和环境保护提供关键支撑。学生将学习材料设计、实验方法、数据分析等技能,未来就业方向广泛,如材料研发、生产、质检等领域。', '专业: 材料科学与工程']
Contextual Compression LLM Result: []
模型返回结果:根据描述:“它涉及使用物理学的原理和方法来探测、分析和解释地球的内部结构、地球表面的动态变化,以及地球与周围空间环境的相互作用。”这段描述明确提到了使用物理学的方法来研究地球的内部结构、表面变化及与空间环境的相互作用。
在提供的专业列表中,所有选项均为“地球物理学”,其介绍内容与描述高度吻合,均涉及使用物理学原理和技术手段(如地震波探测、磁力测量)来研究地球的内部结构、物理性质及其变化规律,以及这些研究如何应用于资源勘探、地质灾害预防等领域。
因此,根据描述内容与专业列表中的信息对比,可以确定该描述对应的专业是:
**地球物理学**。
理由是描述中提到的研究内容和方法与地球物理学专业的定义和研究方向完全一致。
完结撒花,可以看到parent_document_result的召回结果是较为准确的