我的课程笔记,欢迎关注:https://github.com/BBuf/how-to-optim-algorithm-in-cuda/tree/master/cuda-mode
CUDA-MODE课程笔记 第7课: Quantization Cuda vs Triton
适配课件详细解读
作者课件可以在这里找到:https://github.com/cuda-mode/lectures 。我也下载里一份放在 https://github.com/BBuf/how-to-optim-algorithm-in-cuda/tree/master/cuda-mode/ppt 这里。

PyTorch最近一年发布了一些生成式AI模型的案例研究,这些模型运行速度极快,且代码及其精简。这些模型比如GPT-FAST,SAM-FAST都应用了量化技术,Charles很大程度上是这些量化Kernel的主要开发者。因此,这节课由Charles来分享量化技术。

这张Slides介绍了演讲者的背景和最近的研究重点,内容如下:
- Pytorch Core
- AO (Architecture Optimization) 团队
- 量化 (Quantization)
- 剪枝 (Pruning)
- AO (Architecture Optimization) 团队
- 最近的研究重点
- GPU 量化
- Segment-anything-fast, gpt-fast, sdxl-fast 等项目
- TorchAO - 提供了一个 GitHub 链接 (https://github.com/pytorch-labs/ao)
- Int8 动态量化
- i8i8->i32 vs i8i8bf16->bf16
- Int8 仅权重量化
- bf16i8->bf16
- Int4 仅权重量化
- bf16i4->bf16
- GPU 量化
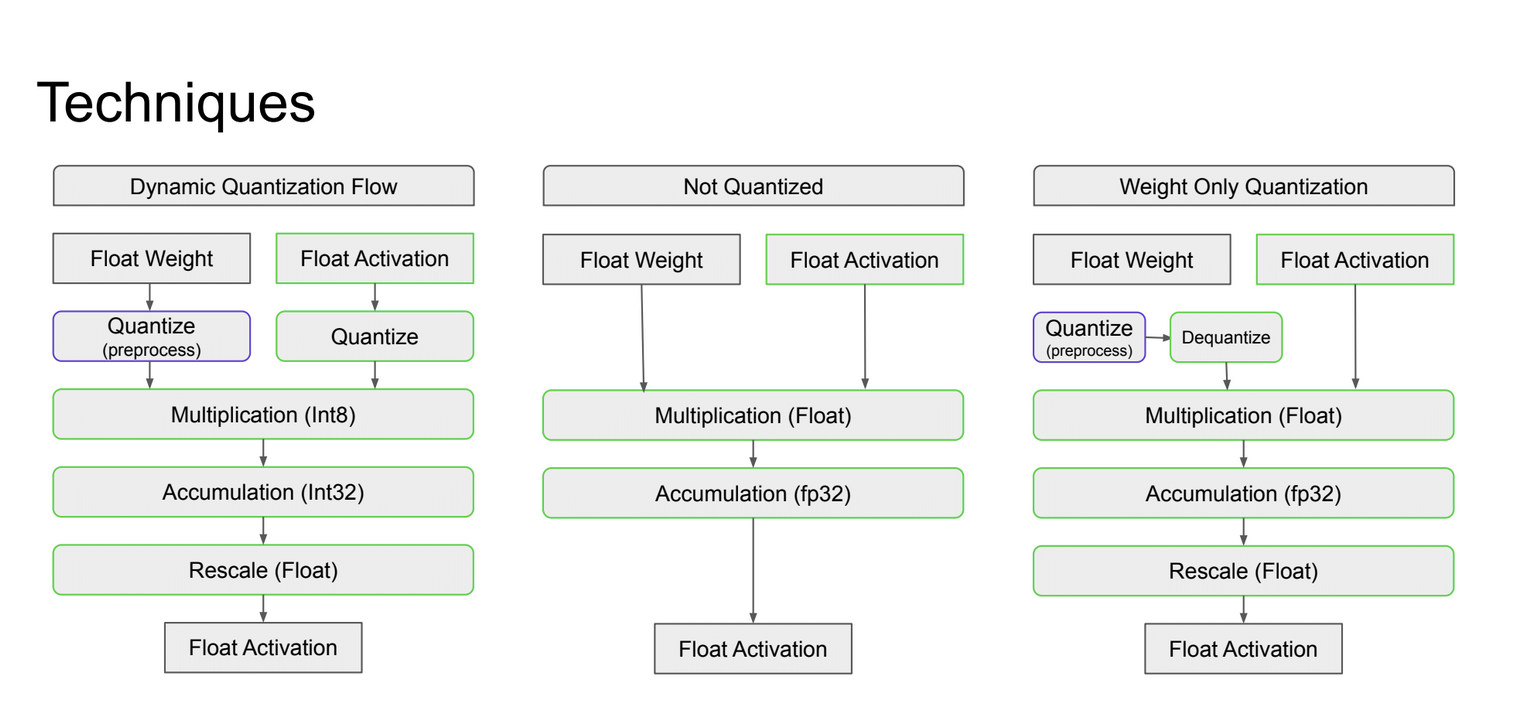
这张Slides介绍了三种不同的量化技术:
- 动态量化流程 (Dynamic Quantization Flow):
- 权重和激活都从浮点开始
- 权重在预处理阶段量化
- 激活在运行时量化
- 使用Int8进行乘法运算
- 使用Int32进行累加
- 最后rescale回浮点数
- 未量化 (Not Quantized):
- 权重和激活都保持浮点格式
- 所有运算(乘法和累加)都使用浮点数进行
- 仅权重量化 (Weight Only Quantization):
- 权重在预处理阶段量化
- 随后立即反量化回浮点数
- 激活保持浮点格式
- 乘法和累加都使用浮点数进行
- 最后有一个rescale步骤
总的来说,这张Slides展示了这三种技术在处理神经网络计算时的不同流程。动态量化通过在计算过程中使用整数运算来提高效率,而仅权重量化则只对权重进行压缩,在实际计算时仍使用浮点数。未量化的方法则完全使用浮点数,可能提供最高的精度但计算效率较低。


这张Slides进一步说明了动态量化(Dynamic Quantization)的概念和流程:
- 数学表达:
- 原始公式:Y = X.W
- 量化后的公式:Y = (Sx*Xint).(Wint * Sw)
- 重排后的公式:Y = Sx * (Xint.Wint) * Sw
这里,Sx 和 Sw 是缩放因子,Xint 和 Wint 是量化后的整数值。
- 动态量化流程图:
- 开始于浮点权重(Float Weight)和浮点激活值(Float Activation)
- 权重在预处理阶段进行量化(Quantize (preprocess))
- 激活值在运行时进行量化(Quantize)
- 使用 Int8 进行乘法运算(Multiplication (Int8))
- 使用 Int32 进行累加运算(Accumulation (Int32))
- 最后将结果重新缩放(Rescale (Float))回浮点数
- 输出浮点激活值(Float Activation)
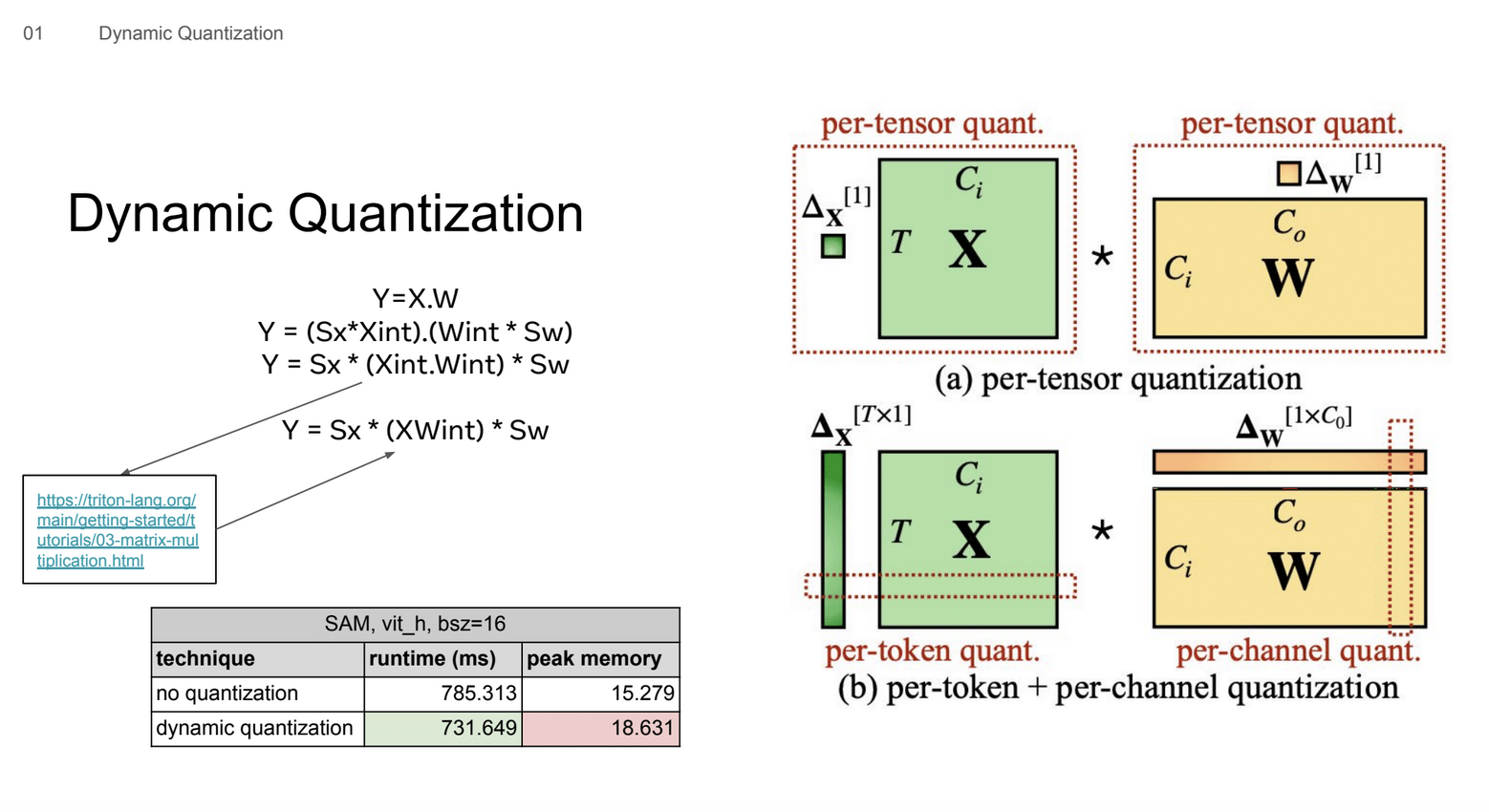
这张Slides展示了逐张量量化(per-tensor quantization)和逐token量化 + 逐通道量化(per-token + per-channel quantization)两种动态量化方式。
性能比较(以SAM模型为例,vit_h, bsz=16):
- 无量化:运行时间 785.313 ms,峰值内存 15.279(单位未指明,可能是GB)
- 动态量化:运行时间 731.649 ms,峰值内存 18.631
另外,这里的链接是Triton的矩阵乘法教程。
结论:动态量化可以提高计算效率,在这个例子中,运行时间减少了约7%。不同的量化策略(逐张量、逐token、逐通道)可以应用于不同的张量,以优化性能和精度。虽然动态量化提高了计算速度,但它的显存占用却更多了大概是15%-20%。

这张Slides指出,显存增加的原因是要把int8的结果累加到int32类型中,因此相比于BFloat1增加了额外的显存。

这张Slides进一步详细介绍了动态量化(Dynamic Quantization)的概念、方法和性能比较:
- 动态量化的数学表达:
- 原始公式:Y = X.W
- 量化公式:Y = (Sx*Xint).(Wint * Sw)
- 重排公式:Y = Sx * (Xint.Wint) * Sw
- 进一步优化:Sx * (XWrescaled)
其中使用了不同的数据类型:
- int8:用于Xint和Wint
- bf16:用于Sx和Sw
- int32:用于中间计算结果XWint
- 性能比较(以SAM模型为例,vit_h, bsz=16):
- 无量化:运行时间 785.313 ms,峰值内存 15.279 GB
- 动态量化:运行时间 731.649 ms,峰值内存 18.631 GB
- 动态量化with fusion:运行时间 695.115 ms,峰值内存 14.941 GB
结论:动态量化可以显著提高计算效率,运行时间减少约7%。动态量化with fusion进一步优化了性能,运行时间比无量化减少约11.5%,同时还略微降低了内存使用。
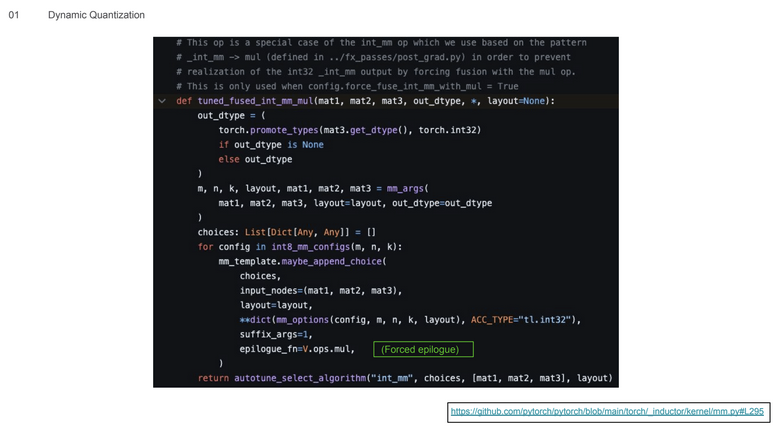
这里展示的是要在Torch Compile中实现动态量化with fusion需要做出的努力,因为Torch Compile并不愿意融合乘法操作,所以作者不得不在Torch Compile的矩阵乘法kernel后强制添加一个乘法的epilogue(实际上这是一个编译器的PASS,需要匹配到矩阵乘法+乘法才能生效)。图片比较难看代码,这里贴一下:
# This op is a special case of the int_mm op which we use based on the pattern
# _int_mm -> mul (defined in ../fx_passes/post_grad.py) in order to prevent
# realization of the int32 _int_mm output by forcing fusion with the mul op.
# This is only used when config.force_fuse_int_mm_with_mul = True
def tuned_fused_int_mm_mul(mat1, mat2, mat3, out_dtype, *, layout=None):
out_dtype = (
torch.promote_types(mat3.get_dtype(), torch.int32)
if out_dtype is None
else out_dtype
)
m, n, k, layout, mat1, mat2, mat3 = mm_args(
mat1, mat2, mat3, layout=layout, out_dtype=out_dtype
)
choices: List[Dict[Any, Any]] = []
for config in int8_mm_configs(m, n, k):
mm_template.maybe_append_choice(
choices,
input_nodes=(mat1, mat2, mat3),
layout=layout,
**dict(mm_options(config, m, n, k, layout), ACC_TYPE="tl.int32"),
suffix_args=1,
epilogue_fn=V.ops.mul,
)
return autotune_select_algorithm("int_mm", choices, [mat1, mat2, mat3], layout)
然后,Triton在实现这个需求时相比于Torch Compile会很简单,一行代码即可。


这张Slides介绍了Int8权重量化(Int8 Weight Only Quantization)的概念和流程。主要内容:
- 数学表达:
- 原始公式:Y = X.W
- 量化公式:Y = X.(Wint * Sw)
- 重排公式:Y = (X.Wint) * Sw
- 权重量化流程图:
- 从浮点权重(Float Weight)开始
- 量化(Quantize)步骤:在预处理阶段进行
- 反量化(Dequantize)步骤:将量化后的权重转回浮点
- 浮点激活(Float Activation)保持不变
- 乘法运算使用浮点(Multiplication (Float))
- 累加使用fp32(Accumulation (fp32))
- 重新缩放(Rescale (Float))
- 最后输出浮点激活(Float Activation)
- 特点:
- 只对权重进行量化,而不是对激活值进行量化
- 在实际计算前,量化的权重被反量化回浮点格式
- 所有的计算(乘法和累加)都在浮点精度下进行
- 其它:
- 减少模型存储空间,因为权重以Int8格式存储
- 保持了计算精度,因为实际运算仍在浮点下进行
- 可能比全量化方法(如动态量化)具有更高的精度
- 适用于对精度要求较高,但仍希望减少模型大小的场景
- 可能在某些硬件上比全量化方法更容易实现和优化
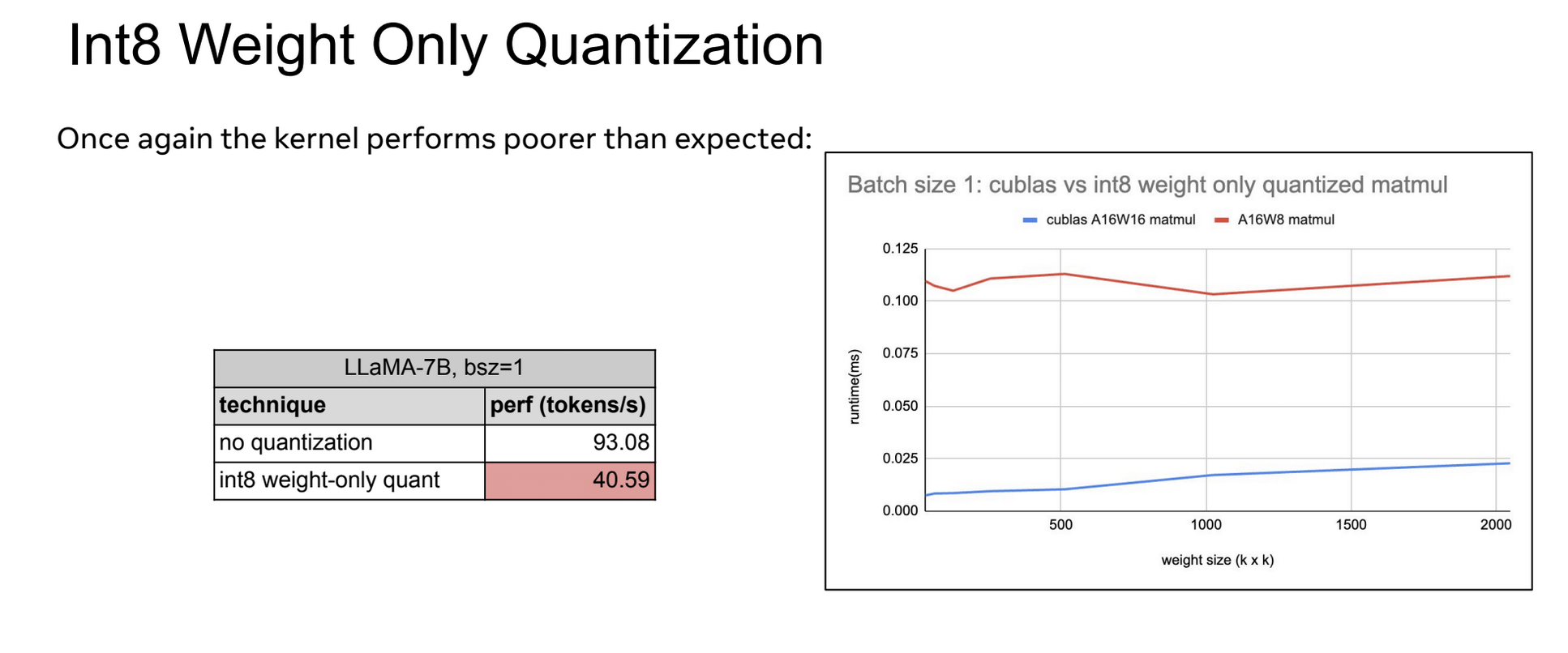
这张Slides展示了Int8权重量化(Int8 Weight Only Quantization)的性能表现,无量化: 93.08 tokens/s,int8权重量化: 40.59 tokens/s,可以看到int8权重量化反而降低了处理速度,约为无量化版本的43.6%。
在图表中,对比了Batch size 1: cublas 和 int8 weight only quantized matmul。蓝线: cublas A16W16 matmul (使用16位精度的cublas矩阵乘法)。红线: A16W8 matmul (使用16位激活和8位权重的矩阵乘法)
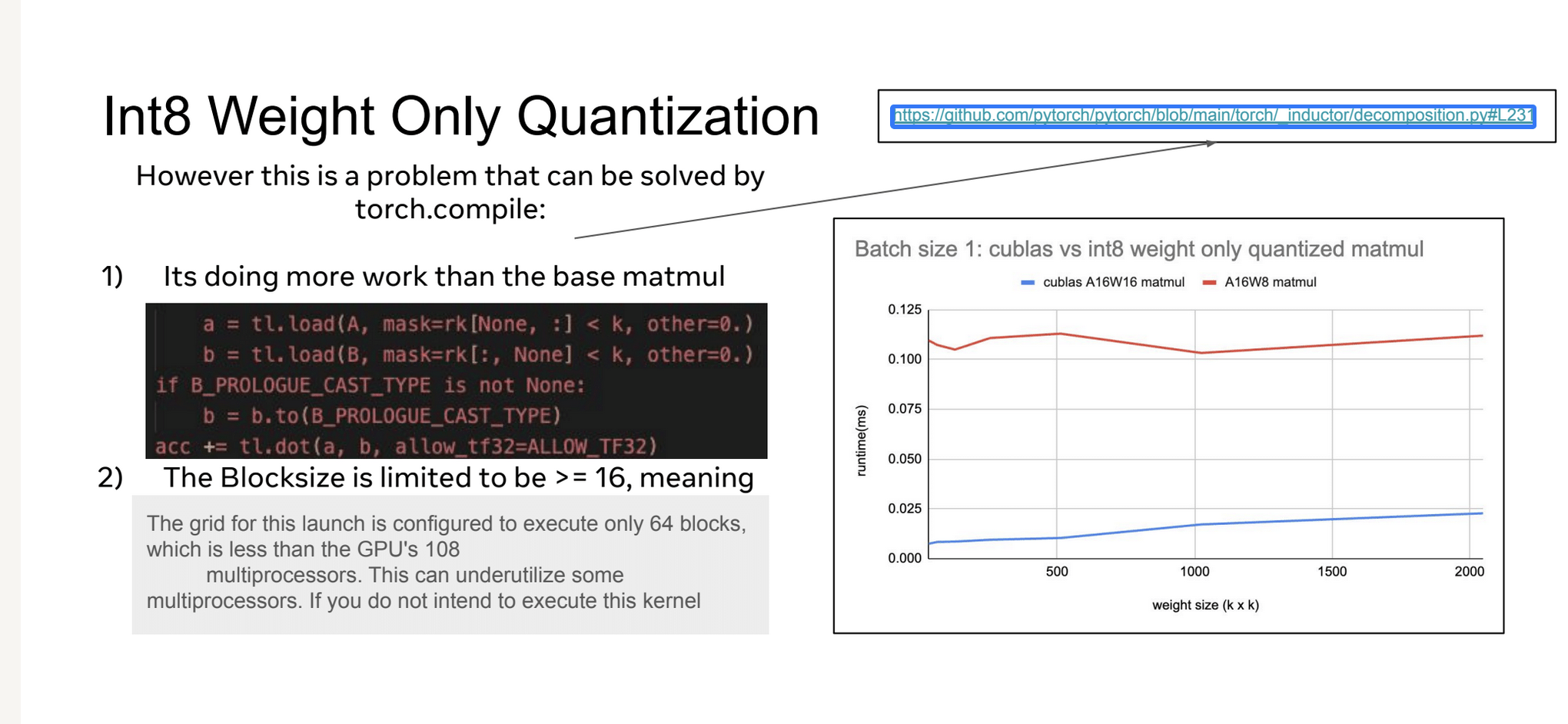
这张Slides讲到如果按照普通的gemm triton kernel模板,上面的Int8权重量化的性能低于预期的原因是:
- 执行了比基础matmul更多的工作,展示了一段代码,显示了额外的加载和类型转换操作,这些额外操作可能导致性能下降
- 块大小被限制为大于等于16,当前配置只执行64个块,少于A 100GPU的108个多处理器,这可能导致一些多处理器未被充分利用
然后Torch Compile通过链接里的代码解决了这个问题,贴一下:
@register_decomposition([aten.mm])
@pw_cast_for_opmath
def mm(self, input2):
# Our matrix vector multiplies only achieve peak bandwidth with coordinate descent tuning.
# todo: Look into why and fix it (hopefully)
if config.coordinate_descent_tuning:
if guard_size_oblivious(self.shape[0] == 1) or guard_size_oblivious(
input2.shape[1] == 1
):
return (self.unsqueeze(2) * input2.unsqueeze(0)).sum(dim=1)
...
return NotImplemented
实际上这个操作就是让GEMV用Cuda Core而不是Tensor Core来完成计算,具体做法就是把GEMV操作等价为一个element-wise乘法加一个reduce操作。这个操作通过Torch Compile生成的Triton Kernel代码如下:

这张Slides展示了一个名为 triton_() 的函数(由Torch编译器生成),该函数实现了 Int8 权重量化的GEMV操作。完整流程为:
- xnumel 和 rnumel 都设置为 4096
- X 对应 N 维度,R 对应 K 维度
- 使用 program_id(0) 和 XBLOCK 计算偏移量
- XBLOCK 始终为 1,每个 program_id 处理输出的单个值
- 加载完整的激活张量(fp32 格式)
- 对权重的一列进行循环
- 加载权重的一列的一个chunk(可能是 int8 格式)
- 将权重列转换为 fp32 格式
- 执行矩阵乘法的核心计算
- 使用广播和累加操作
- 对结果进行掩码处理和ReduceSum求和
- 加载额外的数据(可能是偏置或缩放因子)
- 执行最后的乘法和加法操作
- 将结果存储回内存
def triton_(in_ptr0, in_ptr1, in_ptr2, in_ptr3, out_ptr1, xnumel, rnumel, XBLOCK: tl.constexpr, RBLOCK: tl.constexpr):
xnumel = 4096
rnumel = 4096
xoffset = tl.program_id(0) * XBLOCK
xindex = xoffset + tl.arange(0, XBLOCK)[:, None]
xmask = xindex < xnumel
rbase = tl.arange(0, RBLOCK)[None, :]
x0 = xindex
_tmp6 = tl.full([XBLOCK, RBLOCK], 0, tl.float32)
for roffset in range(0, rnumel, RBLOCK):
rindex = roffset + rbase
rmask = rindex < rnumel
r1 = rindex
tmp0 = tl.load(in_ptr0 + (r1), None, eviction_policy='evict_last').to(tl.float32)
tmp2 = tl.load(in_ptr1 + (r1 + (4096*x0)), xmask, eviction_policy='evict_first', other=0.0)
tmp1 = tmp0.to(tl.float32)
tmp3 = tmp2.to(tl.float32)
tmp4 = tmp1 * tmp3
tmp5 = tl.broadcast_to(tmp4, [XBLOCK, RBLOCK])
tmp7 = _tmp6 + tmp5
_tmp6 = tl.where(xmask, tmp7, _tmp6)
tmp6 = tl.sum(_tmp6, 1)[:, None]
tmp9 = tl.load(in_ptr2 + (x0), xmask, eviction_policy='evict_last').to(tl.float32)
tmp11 = tl.load(in_ptr3 + (x0), xmask, eviction_policy='evict_last').to(tl.float32)
tmp8 = tmp6.to(tl.float32)
tmp10 = tmp8 * tmp9
tmp12 = tmp10 + tmp11
tl.store(out_ptr1 + (x0), tmp12, xmask)

这张Slides主要讲述了Int8权重量化(Int8 Weight Only Quantization)的优化过程和结果。
- 性能问题解决:通过使用torch.compile可以解决之前遇到的性能问题。
- 性能对比(LLaMA-7B模型,批次大小为1):
- 无量化:93.08 tokens/s
- int8权重量化:40.59 tokens/s
- int8权重量化优化后:135.01 tokens/s
- 这显示优化后的int8权重量化性能显著提升,超过了无量化版本。
- 微基准测试结果:
- 图表显示了不同权重大小下的性能比较
- cublas A16W16 matmul(蓝线)性能最佳
- A16W8 matmul(红线)性能较差
- A16W8 fixed matmul(黄线)性能介于两者之间
- 优化过程中的发现:
- 尽管性能提升明显,但仍未完全匹配默认bf16的性能
- 这主要是由于torch.compile的开销,在端到端测试中这个差距会减小
- 在优化过程中遇到了triton的一些限制,通过避免使用tensor cores来绕过这些限制
- 目前仍然缺乏对批次大小大于1(bsz>1)的高性能内核
- 未来工作:
- 需要进一步优化以完全匹配或超越bf16的性能
- 开发支持更大批次大小的高性能内核
这里bsz=1的时候是memory bound的GEMV,如果bsz>1,这个时候就是GEMM Kernel了,很可能就是compute bound了,普通的kernel优化预计很难超越cuBLAS的性能。


从Int4 Weight Only开始,Triton开始力不从心了。要点为:
- 目前PyTorch没有原生的int4/uint4数据类型(dtype)。
- 这意味着我们需要将更大尺寸的张量拆解成多个int4类型。
- 由于Triton在类型转换和乘法操作上的限制,我们在实际操作中会失去更多性能。
- 图示展示了int4数据(4位整数)如何被打包进更大的数据类型中。

“But we can see how far we can get with just triton”(但我们可以看看仅使用triton能走多远)说明了作者打算在现有Triton框架限制下探索Int4量化的潜力。右上角显示了一个int4x2的基本结构,每个元素包含两个4位整数。下方展示了四种不同的打包/解包布局,展示了如何在更大的数据结构中组织int4数据。
Slides里面的右下角的4张图有拼写错误,注意鉴别。比如最后一张图的第一列应该是ABEF才对。

这张Slides详解了Int4权重量化(Int4 Weight Only Quantization)在矩阵乘法(matmul)中的实现策略,特别是关于数据打包和解包的选择。
- 在进行矩阵乘法时,由于这是权重,我们希望在int4x2格式中连续的信息在解包后仍然保持连续。
- 因此,我们应该使用右边两种选项之一。
- 由于矩阵乘法的实现通常让单个线程处理所有的K维度,所以选择了右下角的选项。这种选择可以避免因打包方式导致线程加载不必要的数据。
Slides里面的右下角的4张图有拼写错误,注意鉴别。比如最后一张图的第一列应该是ABEF才对。

这里提供了具体的代码来展示如何打包/解包uint8和int4:
int4[2*k,n]=(uint4x2[k,n] & 0xF) - 8
int4[2*k+1,n]=(uint4x2[k,n] >> 4) - 8
解释说选择uint8是因为triton框架对int8的位移操作存在问题。这里的uint4x2量化Kernel代码在:https://github.com/pytorch/pytorch/blob/main/torch/_inductor/kernel/unpack_mixed_mm.py

这张Slides主要讨论了Int4权重量化(Int4 Weight Only Quantization)的性能表现和一些相关观察。
- 性能数据表格(LLaMA-7B, bsz=1):
- 无量化:93.08 tokens/s
- int8权重量化:40.59 tokens/s
- int8权重量化优化版:135.01 tokens/s
- uint4x2权重量化:43.59 tokens/s
- Int4分组量化:187.8 tokens/s
uint4x2量化的性能(Triton实现)只有无量化情况下的1/2,而不是预期的4倍快。作者提到如果现在重新实现,会参考fast int8 kernel的方法,而不是slow int8 kernel。此外,提到Jeff Johnson(PyTorch GPU后端的开发者)使用CUDA开发了一个int4 kernel并集成到了PyTorch中,速度非常快,也就是上面表格的Int4分组量化。代码:https://github.com/pytorch/pytorch/blob/main/aten/src/ATen/native/native_functions.yaml

这个是kernel的签名,感兴趣的读者可以自行查看代码。
从这个Int4 Weight Only的cuda量化kernel实现可以看到Triton的局限性。

这张Slides讨论了Triton的一些局限性:
- 复杂操作和非标准数据类型的问题:
- Triton在处理复杂操作和非标准数据类型时会遇到困难。
- 具体提到了Int4(4位整数)类型。
- 当批处理大小大于1时,int8/int4权重量化也会遇到问题。
- L2缓存优化在这些情况下可能会受到影响。
- 配置一致性问题:
- 在一些测试中,启发式算法存在问题。
- 最佳配置可能无法使用或被启发式算法错误地丢弃。

这张Slides介绍了Trito的优势:
-
擅长组合"简单"操作:
- Triton在将简单操作组合在一起方面表现出色。
- 提到了两个具体例子:
a) Fused_int_mm_mul(融合整数矩阵乘法和乘法操作)
b) SAM flash attention(Segment Anything Model中使用的快速注意力机制)
-
性能接近CUDA,但使用更简单:
- Triton能够达到CUDA速度的约75%。
- 最重要的是,使用Triton可以达到这种性能水平,而无需直接处理.cu文件(CUDA源代码文件)。
-
代码:
- https://github.com/facebookresearch/segment-anything/blob/main/segment_anything/modeling/image_encoder.py#L325
- https://github.com/pytorch-labs/segment-anything-fast/blob/main/segment_anything_fast/flash_4.py#L13
这里讲的就是SAM里面的Attention操作相比于标准的SelfAttention需要融合两个MASK,这个时候使用Triton实现的FlashAttention就可以非常快的实现这个需求,并且性能很好。

要复现作者的实验或者学习GPU上量化Kernel的实现可以点击这张Slides里的链接。
作者分享的Slides里面还有一些有趣的内容作为附录,这里挑选其中的一些来解读,主要是实验结果和概念部分,对torchao的使用部分的Slides有需要的读者可以自行查看。
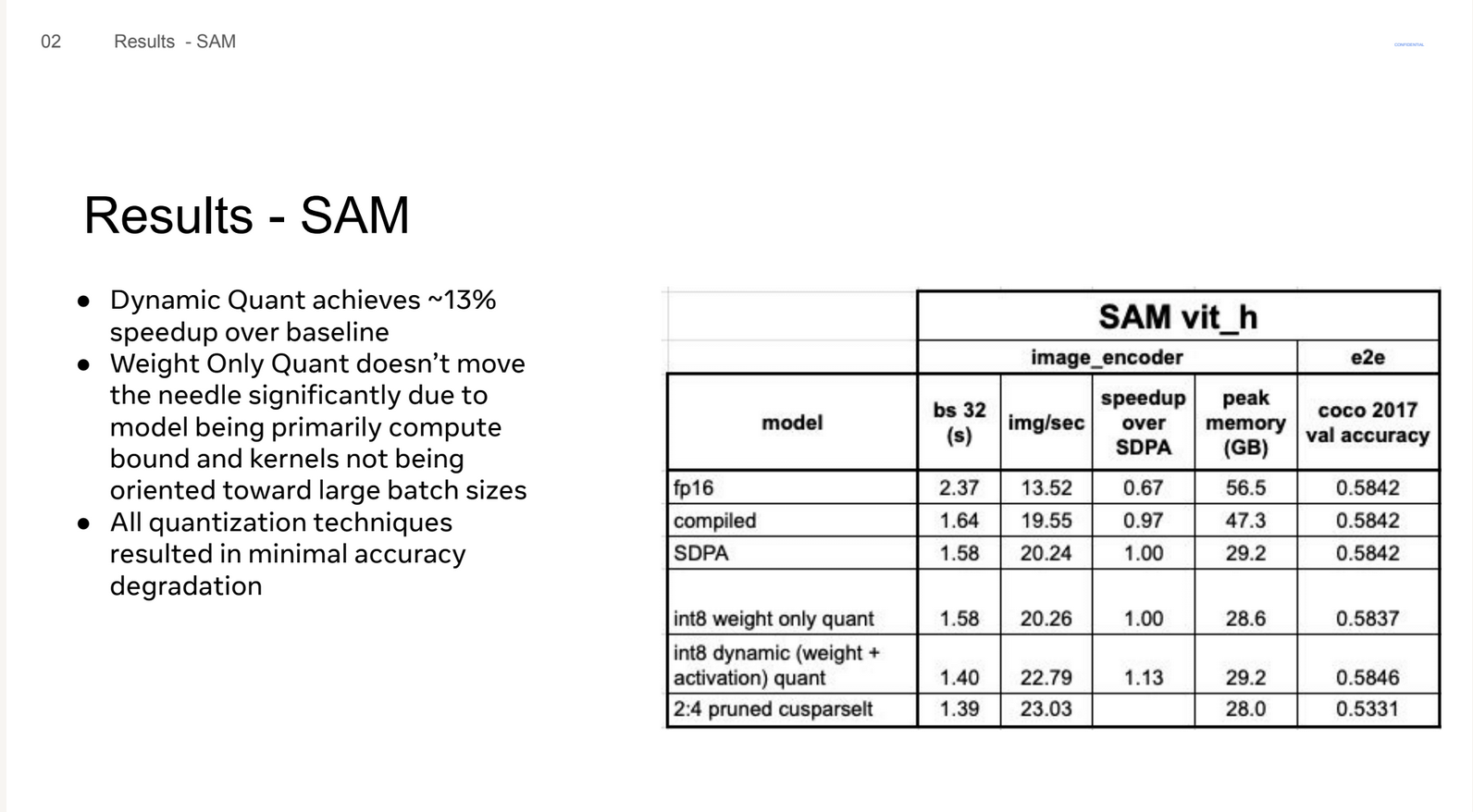
这张Slides展示了对SAM(Segment Anything Model)模型进行不同量化和优化技术的实验结果。主要内容如下:
- 动态量化(Dynamic Quant)相比基准模型获得了约13%的速度提升。
- 仅权重量化(Weight Only Quant)对性能提升不明显,原因是模型主要受计算限制,且其内核设计并不针对大Batch进行优化。
- 所有的量化技术都只导致了很小的精度损失。
图表详细展示了不同方法的性能对比: - fp16(半精度浮点)
- compiled(编译优化)
- SDPA
- int8 weight only quant(8位整数仅权重量化)
- int8 dynamic quant(8位整数动态量化,包括权重和激活)
- 2:4 pruned cusparselt(一种稀疏化技术)
表格中比较了这些方法在以下几个方面的表现: - 批处理大小为32的处理时间(bs 32(s))
- 每秒处理的图像数(img/sec)
- 相对于SDPA的加速比(speedup over SDPA)
- 峰值内存使用(peak memory (GB))
- COCO 2017验证集上的准确率(coco 2017 val accuracy)
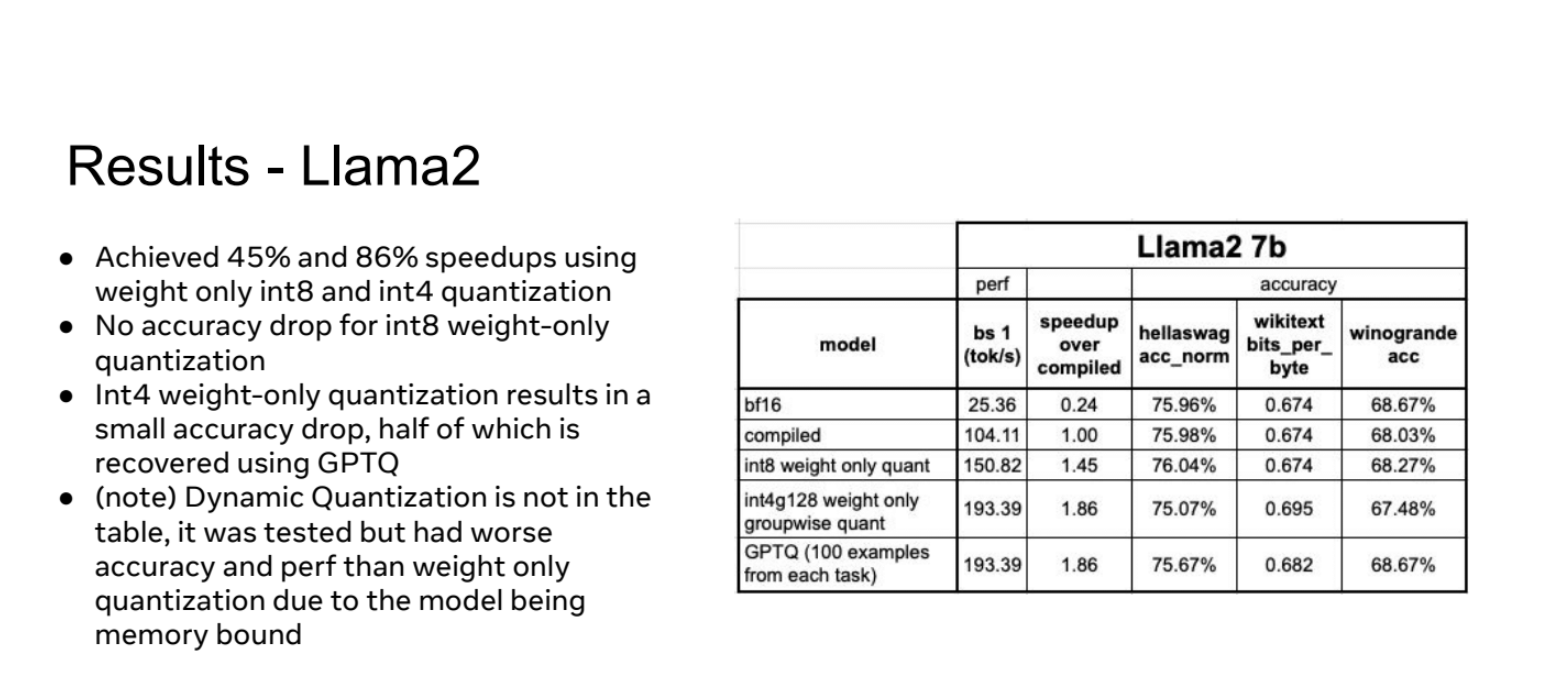
这张Slides展示了对Llama2 7B模型进行不同量化方法的实验结果。主要内容如下:
- 使用仅权重int8和int4量化分别实现了45%和86%的加速。
- 对于int8仅权重量化,没有观察到精度下降。
- int4仅权重量化导致了小幅度的精度下降,但使用GPTQ(一种量化技术)可以恢复其中一半的精度损失。
- 动态量化(Dynamic Quantization)虽然测试过,但因为模型受内存限制,其精度和性能都不如仅权重量化,所以未列入表格。
- 表格详细展示了不同方法的性能和精度对比:
- bf16
- compiled(Torch 编译优化版本)
- int8 weight only quant(8位整数仅权重量化)
- int4g128 weight only groupwise quant(4位整数分组仅权重量化)
- GPTQ(使用每个任务100个样本)
- 性能指标包括:
- 每秒处理的token数(bs 1 (tok/s))
- 相对于compiled版本的加速比
- hellaswag_acc_norm
- wikitext bits_per_byte(困惑度相关指标)
- winogrande acc
- 结果显示,int4量化提供了最大的速度提升(1.86倍),但有轻微的精度损失。int8量化在保持精度的同时也提供了显著的速度提升(1.45倍)。
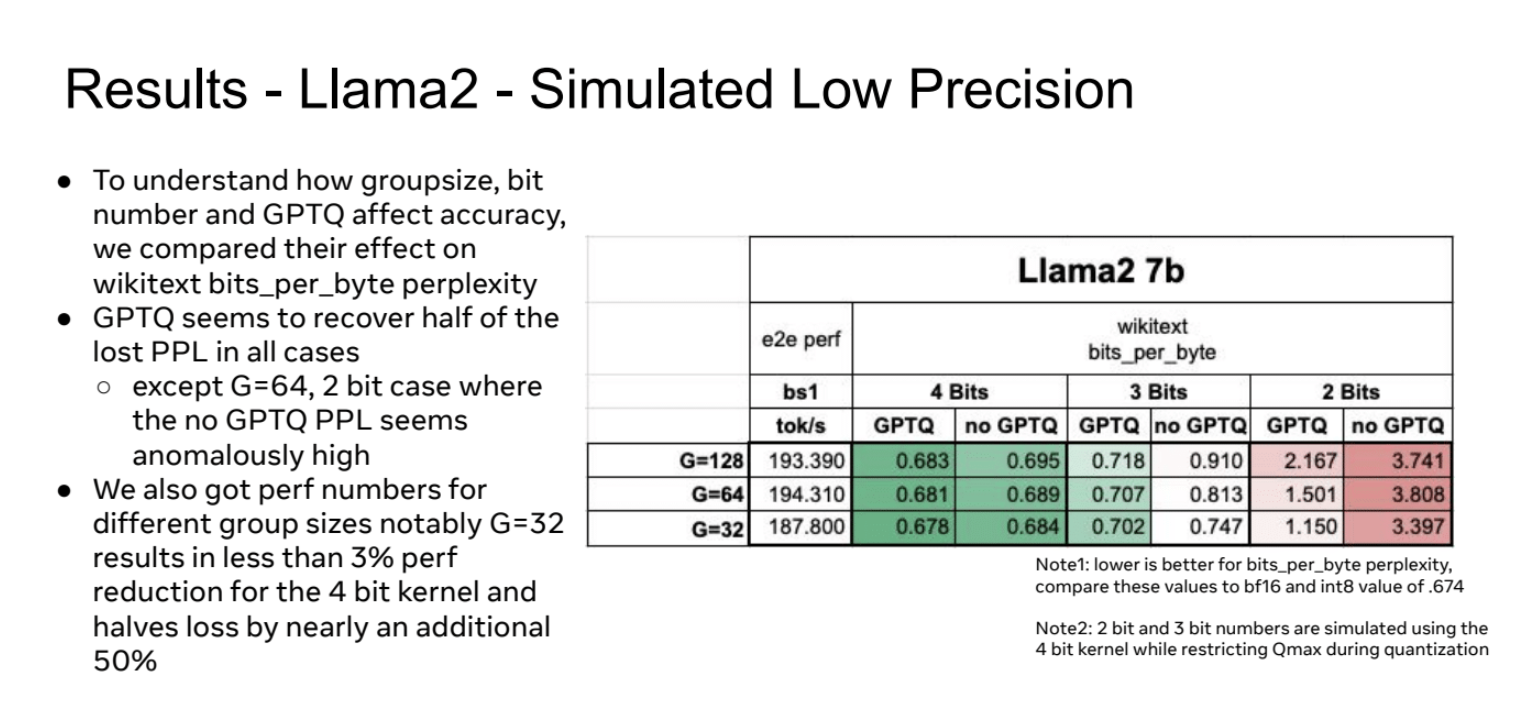
这张Slides展示了对Llama2 7B模型进行模拟低精度量化的实验结果。主要内容如下:
- 实验目的:了解分组大小(groupsize)、位数(bit number)和GPTQ(量化技术)如何影响模型准确性。实验使用wikitext bits_per_byte困惑度作为评估指标。
- GPTQ效果:在大多数情况下,GPTQ能够恢复约一半的性能损失(PPL,困惑度)。特例:在G=64、2位量化的情况下,未使用GPTQ时的PPL异常地高。
- 分组大小影响:测试了不同的分组大小(G=128, 64, 32)。G=32时,4位量化的性能损失不到3%,并且GPTQ将损失进一步减少了近50%。
- 量化位数影响:比较了4位、3位和2位量化的效果。位数越低,通常性能损失越大,但GPTQ能在一定程度上缓解这种损失。
- 性能数据:表格展示了不同配置下的推理速度(tok/s)和wikitext bits_per_byte值。较低的bits_per_byte值表示更好的性能(注1)。
- 模拟低精度:3位和2位的数据是通过在4位内核上模拟得到的,方法是在量化过程中限制Qmax(注2)。
- 基准比较:结果应与bf16(bfloat16)和int8量化的基准值0.674进行比较(注1)。

这张Slides介绍了一些与量化相关的代码资源和工具:
- 量化API:
- 量化API可在torchao仓库中找到
- 链接:https://github.com/pytorch-labs/ao
- segment-anything-fast仓库:
- 这个仓库展示了如何将这些API与其他技术结合使用
- 链接:https://github.com/pytorch-labs/segment-anything-fast
- gpt-fast仓库:
- 使用相关API来执行量化
- 包含了int4量化和GPTQ的实现,这些实现目前在其他地方还没有
- 链接:https://github.com/pytorch-labs/gpt-fast
后面还有几页Slides介绍了不同的量化方法。

这张Slides介绍了动态量化(Dynamic Quantization)的过程和特点:
- 动态量化流程 (Dynamic Quantization Flow):
- 权重和激活都从浮点开始
- 权重在预处理阶段量化
- 激活在运行时量化
- 使用Int8进行乘法运算
- 使用Int32进行累加
- 最后rescale回浮点数
- 动态量化的特点:
- 为每个样本重新计算量化参数
- 对非平稳分布不敏感
- 对频繁出现的异常值敏感
- 为每个样本重新计算量化参数
- 浮点激活:
- 用于替代非量化操作
- 可能比允许一系列量化操作而不需要反量化的技术要慢
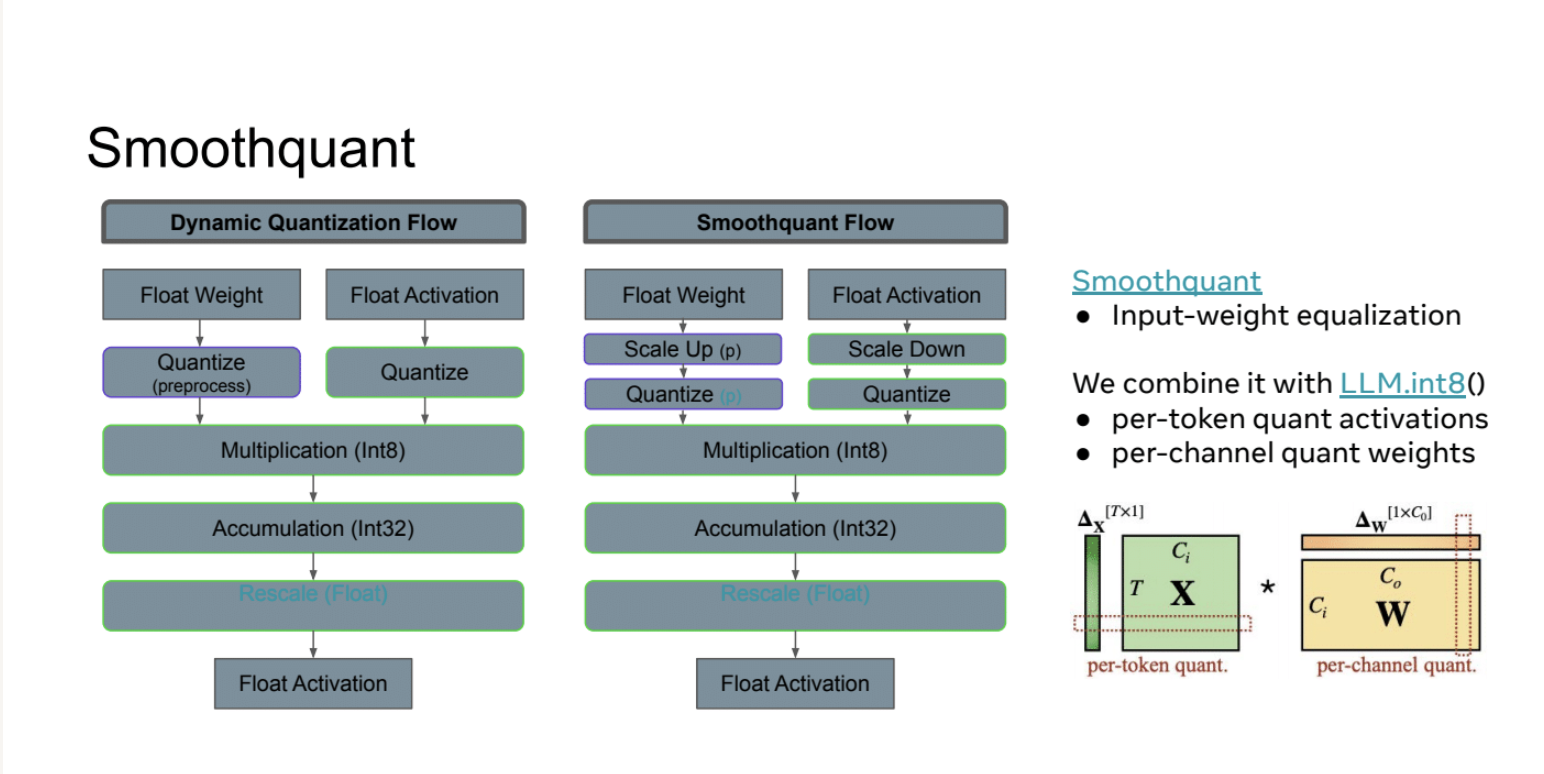
这张Slides介绍了Smoothquant(平滑量化)技术,并将其与动态量化进行了对比:
- 对比两种量化流程:
- 左侧是动态量化流程(与前一张Slides相同)
- 右侧是Smoothquant流程,主要区别在于:
- a. 权重先进行放大(Scale Up)
- b. 激活先进行缩小(Scale Down)
- c. 然后再进行量化
- Smoothquant的特点:使用输入权重均衡化(Input-weight equalization)技术
- Smoothquant与LLM.int8()的结合:
- 对激活使用逐token量化(per-token quant activations)
- 对权重使用逐通道量化(per-channel quant weights)
- Smoothquant的优势:
- 通过预先的缩放操作,可以更好地平衡权重和激活的数值范围
- 有助于减少量化过程中的信息损失
- 结合LLM.int8()技术,可以在保持精度的同时提高效率

这张Slides展示了不同量化方法在OPT-175B、BLOOM-176B和GLM-130B*模型上的性能,Smoothquant(O1、O2、O3)在大多数情况下表现接近或优于FP16和LLM.int8()。

这张Slides介绍了仅权重量化(Weight Only Quantization)为Int8的技术。
- 量化流程:
- 浮点权重先进行量化(Quantize)
- 然后进行反量化(DeQuantize)
- 使用16位权重和16位激活进行乘法运算(Multiplication W16A16)
- 最后得到浮点激活输出
- 优点:比包含激活量化的方法更精确;原因:在实践中,激活通常是更难量化的部分
计算特性: - 混合数据类型的矩阵乘法(Mixed dtype matmul)在计算上比fp16-fp16矩阵乘法更昂贵
但在内存使用上更高效 - 实际应用:在实践中,对int8使用逐通道量化(per-channel quantization)
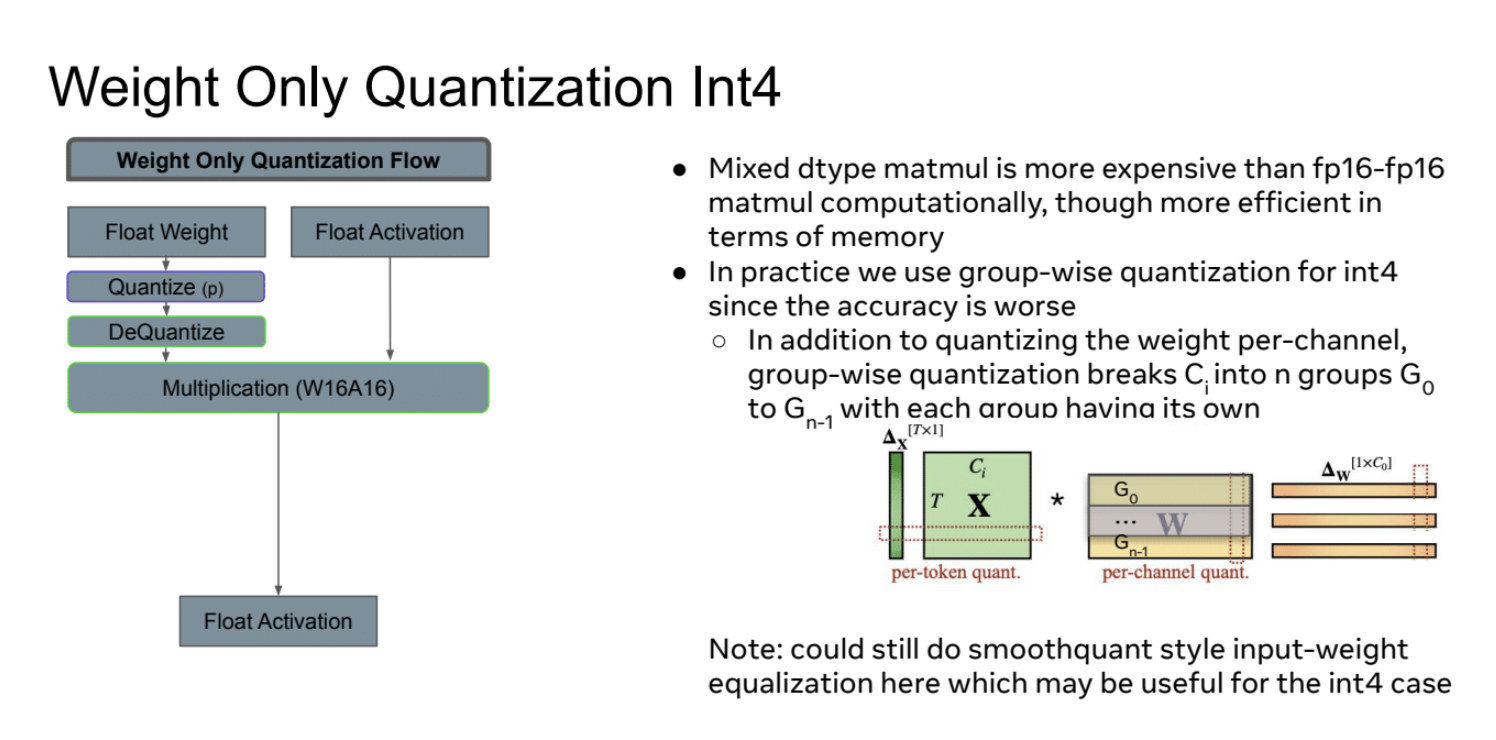
这张Slides介绍了仅权重量化为Int4的技术。
- 量化流程与Int8量化类似,包括权重量化、反量化和16位乘法运算。
- 实际应用中的量化策略:对int4使用分组量化(group-wise quantization)。原因是int4的精度较低,分组量化可以提高精度。
- 分组量化的具体操作:除了对每个通道进行量化外,还将通道Ci分成n个组(G0到Gn-1)。每个组有自己的量化参数。
- 右边还展示了per-token量化的激活矩阵和per-channel分组量化的权重矩阵。
- 可以考虑使用smoothquant风格的输入-权重均衡化技术。这对int4的情况可能特别有用,因为int4精度较低,更需要优化。

这张Slides介绍了GPTQ (Generative Pre-trained Transformer Quantization) 技术。
- GPTQ的核心思想:使用期望Hessian(Expected Hessian)来量化权重W,目标是最小化 argmin ||WX - ŴX||²₂,其中Ŵ是量化后的权重。
- 量化方案:可以是分组量化(group-wise)或逐通道量化(per-channel)
- GPTQ的重要性:对于获得较好的int4仅权重量化精度是必要的
- GPTQ宏观算法流程:
- 对某一层估计多个batch的Hessian矩阵
- 量化W的一列
- 使用Hessian矩阵H更新未量化的W列(以保持上述方程最小化)
- 重复步骤2和3,直到所有列都被量化
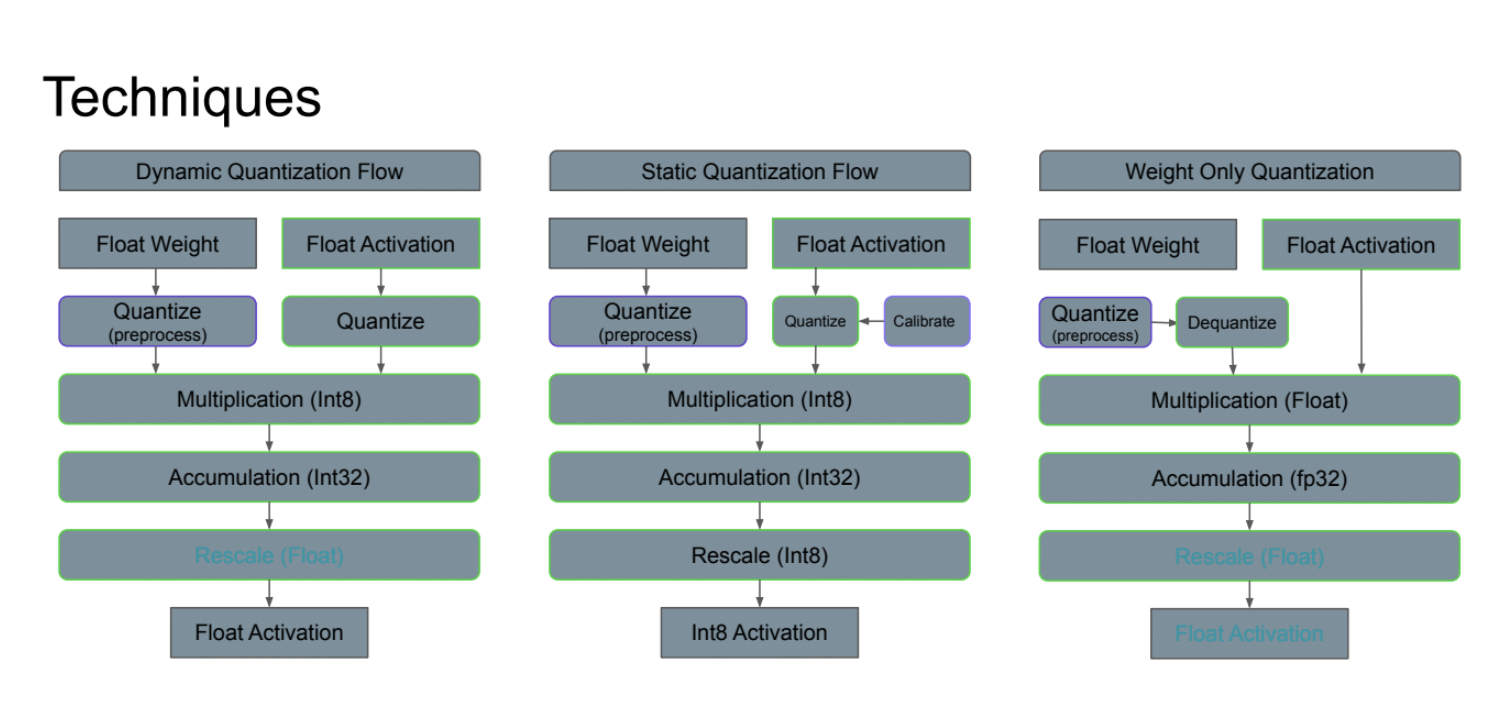
这张Slides比较了三种不同的量化技术:动态量化、静态量化和仅权重量化。特别的,对于静态量化流程(其它两种已经讲过了):
- 权重预处理量化
- 激活量化前需要校准
- 使用Int8进行乘法运算
- Int32累加
- 重新缩放到Int8
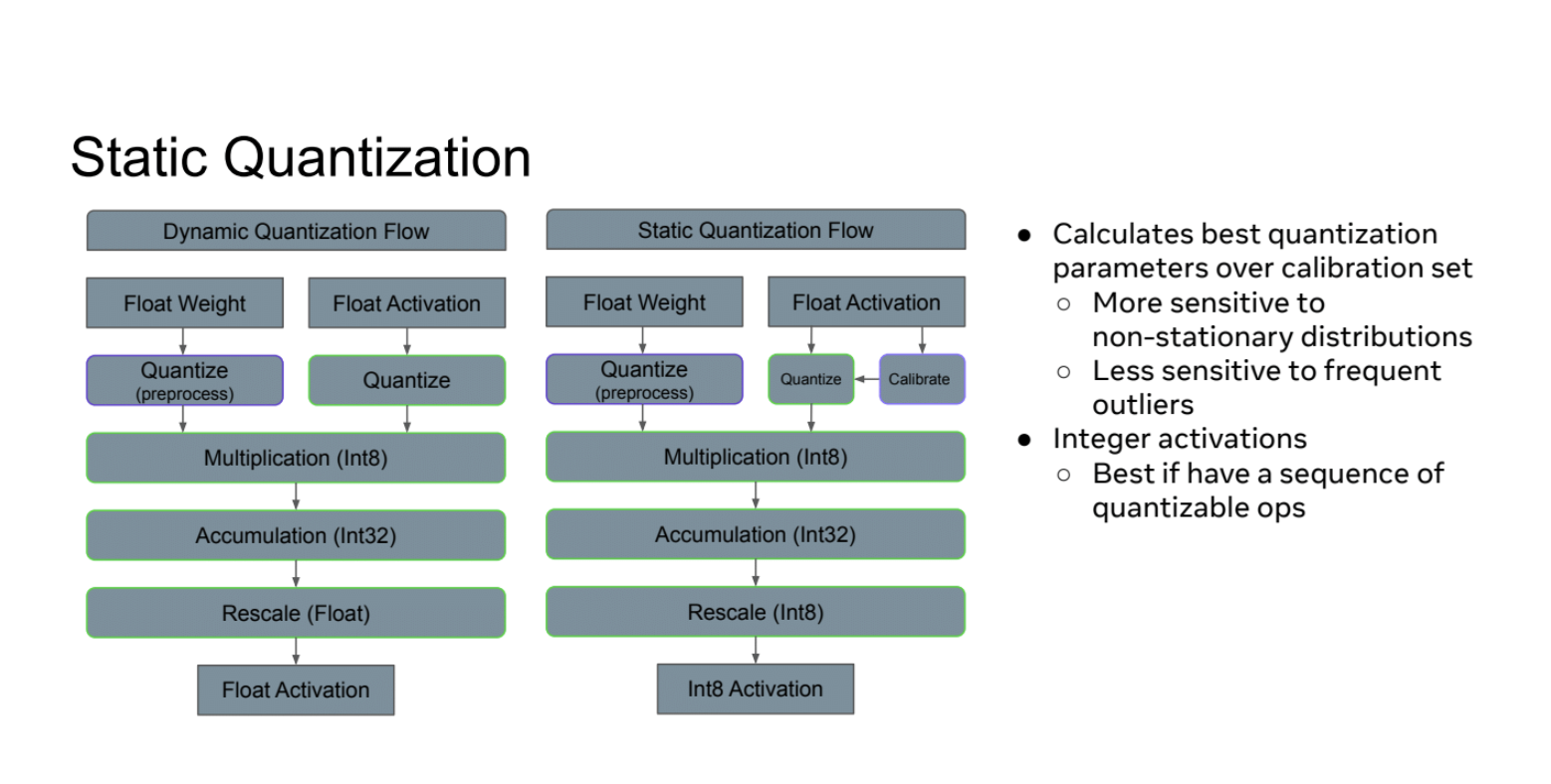
这张Slides继续介绍了静态量化(Static Quantization)技术,并将其与动态量化进行了对比。
- 量化流程对比:左侧是动态量化流程;右侧是静态量化流程
- 静态量化的特点:通过校准集计算最佳量化参数;包含校准步骤,用于确定激活的量化参数
- 静态量化的优势:对非平稳分布更敏感(能更好地适应数据分布的变化);对频繁出现的异常值不太敏感
- 整数激活:静态量化使用整数激活(Int8 Activation);最适合有一系列可量化操作的情况
- 计算过程:两种方法都使用Int8乘法和Int32累加;静态量化在最后阶段重新缩放到Int8,而动态量化重新缩放到浮点数
另外,静态量化的输出也可以Rescale回Float。
总结
Lecture 7主要介绍了基于CUDA和Triton的量化技术在生成式AI模型中的应用。内容包括动态量化、仅权重量化(int8/int4)等不同量化方法的原理、实现和性能比较,以及Smoothquant、GPTQ等量化优化技术的简介。在动态量化和int8/int4 weight only量化实现讲解中,作者分析了Triton相对于CUDA在这些场景的优劣,比如对于int4 weight only 因此Triton本身的限制就不太适合来实现这个cuda kernel。up主还讨论了很多Torch Compiler针对这些量化的优化,比如decode阶段的gemv就让编译器走elementwise mul+reduce的特殊分支以提升性能。学Lecture 7能对量化,CUDA/Triton/Torch Compiler的应用有一个更好的了解,有余力的读者可以看看原视频。视频最后的QA环节也有一些有意思的问题和见解。