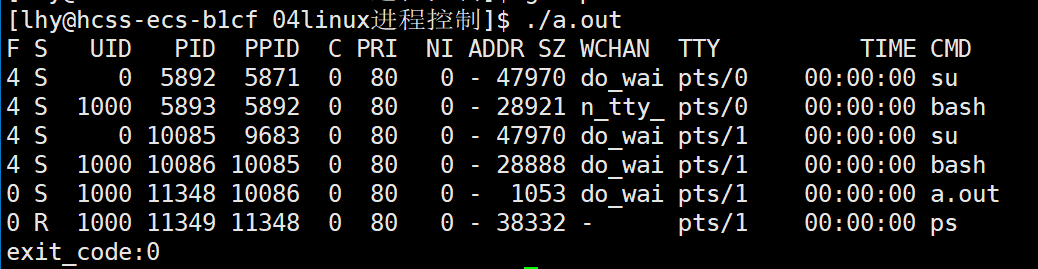
前言
安装 — 动手学深度学习 2.0.0 documentation (d2l.ai)![]() https://zh.d2l.ai/chapter_installation/index.html
https://zh.d2l.ai/chapter_installation/index.html
安装
我们需要配置一个环境来运行 Python、Jupyter Notebook、相关库以及运行本书所需的代码,以快速入门并获得动手学习经验。
安装 Miniconda
最简单的方法就是安装依赖Python 3.x的Miniconda。 如果已安装conda,则可以跳过以下步骤。访问Miniconda网站,根据Python3.x版本确定适合的版本。Miniconda — Anaconda documentation![]() https://docs.anaconda.com/miniconda/
https://docs.anaconda.com/miniconda/
友友们我们要下载安装的是Miniconda,千万不要再去下一边Anaconda哈~
如果我们使用macOS,假设Python版本是3.9(我们的测试版本),将下载名称包含字符串“MacOSX”的bash脚本,并执行以下操作:
# 以Intel处理器为例,文件名可能会更改
sh Miniconda3-py39_4.12.0-MacOSX-x86_64.sh -b如果我们使用Linux,假设Python版本是3.9(我们的测试版本),将下载名称包含字符串“Linux”的bash脚本,并执行以下操作:
# 文件名可能会更改
sh Miniconda3-py39_4.12.0-Linux-x86_64.sh -b




接下来,初始化终端Shell,以便我们可以直接运行conda。
~/miniconda3/bin/conda init现在关闭并重新打开当前的shell。并使用下面的命令创建一个新的环境:
conda create --name d2l python=3.9 -y 现在激活
现在激活 d2l 环境:
conda activate d2l 安装深度学习框架和
安装深度学习框架和d2l软件包
在安装深度学习框架之前,请先检查计算机上是否有可用的GPU。 例如可以查看计算机是否装有NVIDIA GPU并已安装CUDA。 如果机器没有任何GPU,没有必要担心,因为CPU在前几章完全够用。 但是,如果想流畅地学习全部章节,请提早获取GPU并且安装深度学习框架的GPU版本。
我们可以按如下方式安装PyTorch的CPU或GPU版本:
pip install torch==1.12.0
pip install torchvision==0.13.0 我们的下一步是安装
我们的下一步是安装d2l包,以方便调取本书中经常使用的函数和类:
pip install d2l==0.17.6
下载 D2L Notebook
接下来,需要下载这本书的代码。 可以点击本书HTML页面顶部的“Jupyter 记事本”选项下载后解压代码,或者可以按照如下方式进行下载:
mkdir d2l-zh && cd d2l-zh
curl https://zh-v2.d2l.ai/d2l-zh-2.0.0.zip -o d2l-zh.zip
unzip d2l-zh.zip && rm d2l-zh.zip
cd pytorch
注意:如果没有安装
unzip,则可以通过运行sudo apt install unzip进行安装。(Windows 默认情况下并不包含
unzip命令,因为它不是 Windows 操作系统的一部分。但是,你可以通过以下几种方法来解决这个问题:1. 安装解压软件
选项 A:使用 7-Zip
7-Zip 是一个非常流行的压缩和解压缩工具,它支持多种格式,包括 ZIP。你可以从 7-Zip 官网 下载并安装它。安装后,你可以通过 7-Zip 的图形界面或命令行工具来解压 ZIP 文件。
7-Zip
https://www.7-zip.org/
对于命令行,你可能需要使用
7z命令而不是unzip。例如:bash7z x d2l-zh.zip这条命令会解压
d2l-zh.zip到当前目录。选项 B:安装其他包含 unzip 的软件
有些第三方软件可能包含了
unzip工具,如 Cygwin 或 MinGW。但通常 7-Zip 是最简单的选择。2. 修改 PATH 环境变量
如果你已经安装了包含
unzip的软件(如 Cygwin 或其他 UNIX 风格的环境),但你仍然无法在 CMD 中使用它,那么你可能需要将该软件的 bin 目录添加到你的 PATH 环境变量中。这可以通过“系统属性” -> “高级” -> “环境变量”来完成。3. 使用 PowerShell
Windows PowerShell 支持更复杂的命令和脚本,但它默认也不包含
unzip命令。不过,你可以使用 PowerShell 的内置功能来解压 ZIP 文件,或者通过安装扩展来添加unzip支持。一个使用 PowerShell 解压 ZIP 文件的简单例子是:
Expand-Archive -Path d2l-zh.zip -DestinationPath .这条命令会将
d2l-zh.zip解压到当前目录。4. 使用第三方工具
除了上述方法外,你还可以搜索是否有其他第三方工具或脚本可以帮助你在 Windows CMD 中解压 ZIP 文件。但请注意,使用未知来源的软件可能会带来安全风险。
小结
对于你的具体情况,我建议安装 7-Zip 并使用其命令行工具
7z来解压 ZIP 文件。如果你熟悉 PowerShell,也可以使用 PowerShell 的Expand-Archive命令。)
安装完成后我们可以通过运行以下命令打开Jupyter笔记本(在Window系统的命令行窗口中运行以下命令前,需先将当前路径定位到刚下载的本书代码解压后的目录):
jupyter notebook现在可以在Web浏览器中打开http://localhost:8888(通常会自动打开)。 由此,我们可以运行这本书中每个部分的代码。 在运行书籍代码、更新深度学习框架或d2l软件包之前,请始终执行conda activate d2l以激活运行时环境。 要退出环境,请运行conda deactivate。

线性回归
回归(regression)是能为一个或多个自变量与因变量之间关系建模的一类方法。 在自然科学和社会科学领域,回归经常用来表示输入和输出之间的关系。
在机器学习领域中的大多数任务通常都与预测(prediction)有关。 当我们想预测一个数值时,就会涉及到回归问题。 常见的例子包括:预测价格(房屋、股票等)、预测住院时间(针对住院病人等)、 预测需求(零售销量等)。 但不是所有的预测都是回归问题。 在后面的章节中,我们将介绍分类问题。分类问题的目标是预测数据属于一组类别中的哪一个。
1.生成数据集

def synthetic_data(w, b, num_examples): #@save
"""生成y=Xw+b+噪声"""
X = torch.normal(0, 1, (num_examples, len(w)))
y = torch.matmul(X, w) + b
y += torch.normal(0, 0.01, y.shape)
return X, y.reshape((-1, 1))
true_w = torch.tensor([2, -3.4])
true_b = 4.2
features, labels = synthetic_data(true_w, true_b, 1000)注意,features中的每一行都包含一个二维数据样本, labels中的每一行都包含一维标签值(一个标量)。
print('features:', features[0],'\nlabel:', labels[0])features: tensor([1.4632, 0.5511]) label: tensor([5.2498])
通过生成第二个特征features[:, 1]和labels的散点图, 可以直观观察到两者之间的线性关系。

2.读取数据集
回想一下,训练模型时要对数据集进行遍历,每次抽取一小批量样本,并使用它们来更新我们的模型。 由于这个过程是训练机器学习算法的基础,所以有必要定义一个函数, 该函数能打乱数据集中的样本并以小批量方式获取数据。
在下面的代码中,我们定义一个data_iter函数, 该函数接收批量大小、特征矩阵和标签向量作为输入,生成大小为batch_size的小批量。 每个小批量包含一组特征和标签。
def data_iter(batch_size, features, labels):
num_examples = len(features)
indices = list(range(num_examples))
# 这些样本是随机读取的,没有特定的顺序
random.shuffle(indices)
for i in range(0, num_examples, batch_size):
batch_indices = torch.tensor(
indices[i: min(i + batch_size, num_examples)])
yield features[batch_indices], labels[batch_indices]通常,我们利用GPU并行运算的优势,处理合理大小的“小批量”。 每个样本都可以并行地进行模型计算,且每个样本损失函数的梯度也可以被并行计算。 GPU可以在处理几百个样本时,所花费的时间不比处理一个样本时多太多。
我们直观感受一下小批量运算:读取第一个小批量数据样本并打印。 每个批量的特征维度显示批量大小和输入特征数。 同样的,批量的标签形状与batch_size相等。
batch_size = 10
for X, y in data_iter(batch_size, features, labels):
print(X, '\n', y)
breaktensor([[ 0.3934, 2.5705], [ 0.5849, -0.7124], [ 0.1008, 0.6947], [-0.4493, -0.9037], [ 2.3104, -0.2798], [-0.0173, -0.2552], [ 0.1963, -0.5445], [-1.0580, -0.5180], [ 0.8417, -1.5547], [-0.6316, 0.9732]]) tensor([[-3.7623], [ 7.7852], [ 2.0443], [ 6.3767], [ 9.7776], [ 5.0301], [ 6.4541], [ 3.8407], [11.1396], [-0.3836]])
当我们运行迭代时,我们会连续地获得不同的小批量,直至遍历完整个数据集。 上面实现的迭代对教学来说很好,但它的执行效率很低,可能会在实际问题上陷入麻烦。 例如,它要求我们将所有数据加载到内存中,并执行大量的随机内存访问。 在深度学习框架中实现的内置迭代器效率要高得多, 它可以处理存储在文件中的数据和数据流提供的数据。
3.初始化模型参数
在我们开始用小批量随机梯度下降优化我们的模型参数之前, 我们需要先有一些参数。 在下面的代码中,我们通过从均值为0、标准差为0.01的正态分布中采样随机数来初始化权重, 并将偏置初始化为0。
w = torch.normal(0, 0.01, size=(2,1), requires_grad=True)
b = torch.zeros(1, requires_grad=True)在初始化参数之后,我们的任务是更新这些参数,直到这些参数足够拟合我们的数据。 每次更新都需要计算损失函数关于模型参数的梯度。 有了这个梯度,我们就可以向减小损失的方向更新每个参数。 因为手动计算梯度很枯燥而且容易出错,所以没有人会手动计算梯度。 我们使用 2.5节中引入的自动微分来计算梯度。
4.定义模型

def linreg(X, w, b): #@save
"""线性回归模型"""
return torch.matmul(X, w) + b5.定义优化算法
正如我们在 3.1节中讨论的,线性回归有解析解。 尽管线性回归有解析解,但本书中的其他模型却没有。 这里我们介绍小批量随机梯度下降。
在每一步中,使用从数据集中随机抽取的一个小批量,然后根据参数计算损失的梯度。 接下来,朝着减少损失的方向更新我们的参数。 下面的函数实现小批量随机梯度下降更新。 该函数接受模型参数集合、学习速率和批量大小作为输入。每 一步更新的大小由学习速率lr决定。 因为我们计算的损失是一个批量样本的总和,所以我们用批量大小(batch_size) 来规范化步长,这样步长大小就不会取决于我们对批量大小的选择。
def sgd(params, lr, batch_size): #@save
"""小批量随机梯度下降"""
with torch.no_grad():
for param in params:
param -= lr * param.grad / batch_size
param.grad.zero_()6.训练
现在我们已经准备好了模型训练所有需要的要素,可以实现主要的训练过程部分了。 理解这段代码至关重要,因为从事深度学习后, 相同的训练过程几乎一遍又一遍地出现。 在每次迭代中,我们读取一小批量训练样本,并通过我们的模型来获得一组预测。 计算完损失后,我们开始反向传播,存储每个参数的梯度。 最后,我们调用优化算法sgd来更新模型参数。
概括一下,我们将执行以下循环:
在每个迭代周期(epoch)中,我们使用data_iter函数遍历整个数据集, 并将训练数据集中所有样本都使用一次(假设样本数能够被批量大小整除)。 这里的迭代周期个数num_epochs和学习率lr都是超参数,分别设为3和0.03。 设置超参数很棘手,需要通过反复试验进行调整。 我们现在忽略这些细节,以后会详细介绍。
lr = 0.03
num_epochs = 3
net = linreg
loss = squared_loss
for epoch in range(num_epochs):
for X, y in data_iter(batch_size, features, labels):
l = loss(net(X, w, b), y) # X和y的小批量损失
# 因为l形状是(batch_size,1),而不是一个标量。l中的所有元素被加到一起,
# 并以此计算关于[w,b]的梯度
l.sum().backward()
sgd([w, b], lr, batch_size) # 使用参数的梯度更新参数
with torch.no_grad():
train_l = loss(net(features, w, b), labels)
print(f'epoch {epoch + 1}, loss {float(train_l.mean()):f}')epoch 1, loss 0.042790 epoch 2, loss 0.000162 epoch 3, loss 0.000051
因为我们使用的是自己合成的数据集,所以我们知道真正的参数是什么。 因此,我们可以通过比较真实参数和通过训练学到的参数来评估训练的成功程度。 事实上,真实参数和通过训练学到的参数确实非常接近。
print(f'w的估计误差: {true_w - w.reshape(true_w.shape)}')
print(f'b的估计误差: {true_b - b}')w的估计误差: tensor([-1.3804e-04, 5.7936e-05], grad_fn=<SubBackward0>) b的估计误差: tensor([0.0006], grad_fn=<RsubBackward1>)
注意,我们不应该想当然地认为我们能够完美地求解参数。 在机器学习中,我们通常不太关心恢复真正的参数,而更关心如何高度准确预测参数。 幸运的是,即使是在复杂的优化问题上,随机梯度下降通常也能找到非常好的解。 其中一个原因是,在深度网络中存在许多参数组合能够实现高度精确的预测。
总结
我们学习了深度网络是如何实现和优化的。在这一过程中只使用张量和自动微分,不需要定义层或复杂的优化器。
这一节只触及到了表面知识。在下面的部分中,我们将基于刚刚介绍的概念描述其他模型,并学习如何更简洁地实现其他模型。
补充:PPT(机器学习、神经网络————原理、理论)












...














![HTML+CSS+JS实现商城首页[web课设代码+模块说明+效果图]](https://i-blog.csdnimg.cn/direct/41f0acdef9e64987abfa53283973f387.png)