从文本构建知识图谱长期以来一直是一个令人着迷的研究领域。随着大型语言模型 (LLM) 的出现,该领域获得了更多主流关注。然而,LLM 的成本可能相当高。另一种方法是微调较小的模型,这种方法得到了学术研究的支持,可以产生更有效的解决方案。今天,我们将探索Relik,这是一个用于运行超快且轻量级的信息提取模型的框架,由罗马 Sapienza 大学的 NLP 小组开发。
没有 LLM 的典型信息提取流程如下所示:
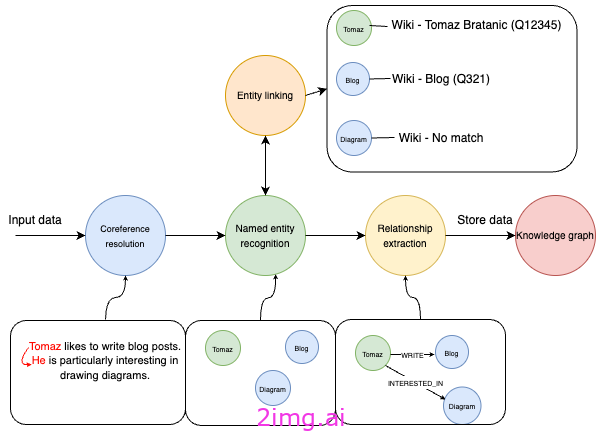
信息提取管道——图片来自作者
该图展示了一个信息提取流程,从包含提及“Tomaz 喜欢写博客文章。他对绘制图表特别感兴趣”的文本的输入数据开始。该过程从共指解析开始,以将“Tomaz”和“他”识别为同一实体。然后,命名实体识别 (NER) 识别诸如“Tomaz”、“博客”和“图表”之类的实体。
实体链接是 NER 之后的过程,其中识别的实体被映射到数据库或知识库中的相应条目。例如,“Tomaz”链接到“Tomaz Bratanic (Q12345)”,“Blog”链接到“Blog (Q321)”,但“Diagram”在知识库中没有匹配项。
关系提取是后续步骤,系统在此步骤中识别并提取已识别实体之间的有意义关系。此示例识别出“Tomaz”与“博客”之间存在关系,其特征为“WRITES”,表明 Tomaz 写博客。此外,它还识别出“Tomaz”与“图表”之间存在关系,其特征为“INTERESTED_IN”,表明 Tomaz 对图表感兴趣。
最后,这些结构化信息(包括实体及其关系)存储在知识图谱中,以便对数据进行组织和访问,以便进一步分析或检索。
传统上,如果没有 LLM 的强大功能,整个过程将依赖于一套专门的模型,每个模型都处理从共指解析到关系提取的特定任务。虽然整合这些模型需要更多的努力和协调,但它具有一个显著的优势:降低成本。通过微调较小的、特定于任务的模型,可以控制构建和维护系统的总体费用。
该代码可在GitHub上获取。
环境设置
我建议您使用单独的 Python 环境,例如Google Colab,因为我们将不得不尝试一些依赖项。模型在 GPU 上运行速度更快,因此如果您拥有 Pro 版本,则可以使用 GPU 驱动的运行时。
此外,我们需要设置原生图形数据库 Neo4j 来存储提取的信息。设置数据库实例的方法有很多。但我建议使用Neo4j Aura,它提供了一个免费的云实例,可以从 Google Colab 笔记本轻松访问。
创建数据库后,我们可以使用 LlamaIndex 定义连接:
从llama_index.graph_stores.neo4j导入Neo4jPGStore
用户名 = “neo4j”
密码 = “rubber-cuffs-radiator”
url = “bolt://54.89.19.156:7687”
graph_store = Neo4jPGStore(
用户名 = 用户名,
密码 = 密码,
url = url,
refresh_schema = False
)
数据集
我们将使用我前段时间通过Diffbot API获得的新闻数据集。该数据集可在 GitHub 上方便地获取,供我们重复使用:
将pandas导入为pd
NUMBER_OF_ARTICLES = 100
news = pd.read_csv(
“https://raw.githubusercontent.com/tomasonjo/blog-datasets/main/news_articles.csv”
)
news = news.head(NUMBER_OF_ARTICLES)
共指消解
流程的第一步是共指解析模型。共指解析是识别文本中所有表达是否指向同一实体的任务。
据我所知,目前可用的共指解析开源模型并不多。我尝试了maverick-coref,但在我的测试中, spaCy 的Coreferee效果更好,所以我们将使用它。使用 Coreferee 的唯一缺点是我们必须处理依赖地狱,这在笔记本中已经解决,但我们不会在这里讨论它。
您可以使用以下代码在 spaCy 中加载共指模型:
导入spacy,核心裁判 coref_nlp = spacy.load( 'en_core_web_lg' ) coref_nlp.add_pipe( 'coreferee' )
Coreferee 模型检测指向相同实体的表达簇。要根据这些簇重写文本,我们必须实现自己的函数:
def coref_text(文本):
coref_doc = coref_nlp(文本)
solved_text = “”
对于coref_doc中的标记:
repres = coref_doc._.coref_chains.resolve(token)
如果repres:
solved_text + = “” + “和” .join(
[
t.text
如果t.ent_type_ == “”
else [e.text for e in coref_doc.ents如果t in e][ 0 ]
for t in repres
]
)
else:
solved_text + = “” + token.text
返回solved_text
让我们测试该函数以确保模型和依赖项设置正确:
print (
coref_text( "Tomaz 太酷了。他可以解决各种 Python 依赖关系而不会哭泣" )
)
# Tomaz 太酷了。Tomaz 可以解决各种 Python 依赖关系而不会哭泣
在此示例中,模型识别出“Tomaz”和“He”指的是同一个实体。使用该coref_text函数,我们将“He”替换为“Tomaz”。
请注意,由于对集群内的实体使用了简单的替换逻辑,因此重写并不总是返回语法正确的句子。但是,对于大多数场景来说,这应该足够好了。
现在我们将共指解析应用到我们的新闻数据集并将结果包装为 LlamaIndex 文档:
从llama_index.core导入文档
新闻[ “coref_text” ] = 新闻[ “text” ].apply(coref_text)
文件 = [
文档(文本= f “ {row[ 'title' ]} : {row[ 'coref_text' ]} “ ) for i, row in news.iterrows()
]
实体链接和关系提取
Relik是一个包含实体链接 (EL) 和关系提取 (RE) 模型的库,它还支持将两者相结合的模型。在实体链接中,维基百科被用作目标知识库,将文本中的实体映射到百科全书中的相应条目。
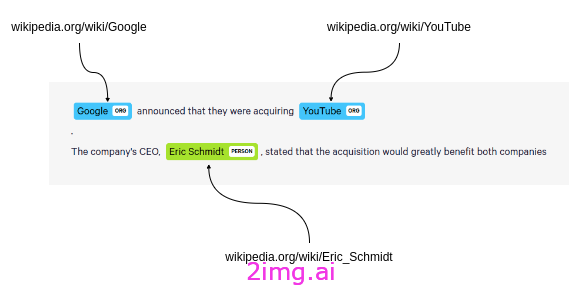
将实体链接到维基百科 - 作者提供的图片
另一方面,关系提取涉及识别和分类文本中实体之间的关系,从而能够从非结构化数据中提取结构化信息。
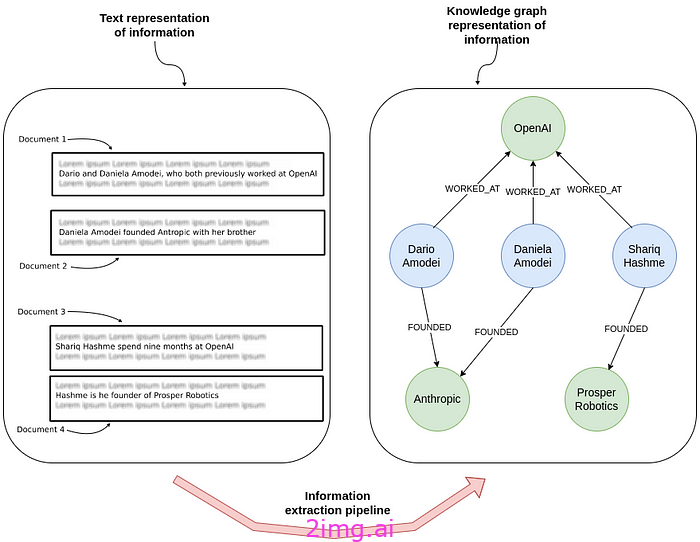
关系提取 - 作者图片
如果您使用的是免费版 Colab,请使用relik-ie/relik-relation-extraction-small仅执行关系提取的模型。如果您使用的是专业版,或者您将在更强大的本地机器上使用它,则可以测试relik-ie/relik-cie-small执行实体链接和关系提取的模型。
从llama_index.extractors.relik.base导入RelikPathExtractor
relik = RelikPathExtractor(
model= "relik-ie/relik-relation-extraction-small"
)
# 在 Pro Collab 上使用 GPU
# relik = RelikPathExtractor(
# model="relik-ie/relik-cie-small", model_config={"skip_metadata": True, "device":"cuda"}
# )
此外,我们必须定义用于嵌入实体的嵌入模型和用于问答流的 LLM:
从llama_index.embeddings.openai导入os从llama_index.llms.openai导入OpenAI os.environ [ “OPENAI_API_KEY” ] = “sk-” llm = OpenAI(model= “gpt-4o” ,temperature= 0.0 ) embed_model = OpenAIEmbedding(model_name= “text-embedding-3-small” )
请注意,在图形构建期间不会使用 LLM。
现在我们已经准备好一切,我们可以实例化PropertyGraphIndex并使用新闻文档作为知识图谱的输入数据。
此外,我们需要将relik模型作为kg_extractors值传递来提取关系:
从llama_index.core导入PropertyGraphIndex
index = PropertyGraphIndex.from_documents(
documents,
kg_extractors=[relik],
llm=llm,
embed_model=embed_model,
property_graph_store=graph_store,
show_progress= True ,
)
构建图表后,您可以打开 Neo4j 浏览器来验证导入的图表。通过运行以下 Cypher 语句,您应该会得到类似的可视化效果:
匹配 p=(:__Entity__)--(:__Entity__) 返回 p 限制 250
结果
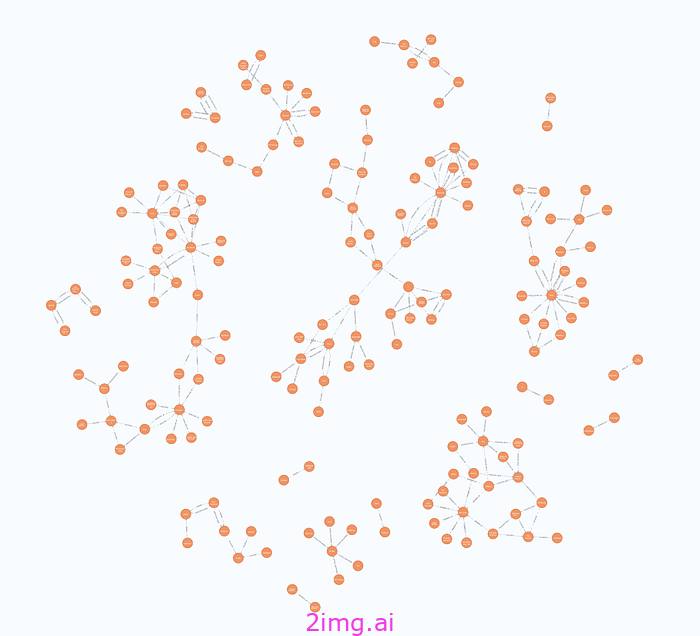
图形可视化 - 图片来自作者
问答
使用 LlamaIndex,现在可以轻松进行问答。要使用默认的图形检索器,您可以提出如下简单的问题:
query_engine = index.as_query_engine(include_text= True ) response = query_engine.query( “瑞安航空发生了什么事?” ) print ( str (response))
这就是定义的 LLM 和嵌入模型发挥作用的地方。当然,您也可以实现自定义检索器,以获得更好的准确性。
概括
不依赖 LLM 构建知识图谱不仅可行,而且经济高效。通过微调较小的、特定于任务的模型(例如 Relik 框架中的模型),您可以为检索增强生成 (RAG) 应用程序实现高性能信息提取。
实体链接是此过程中的关键步骤,可确保识别的实体准确映射到知识库中的相应条目,从而维护知识图谱的完整性和实用性。
通过使用 Relik 等框架和 Neo4j 等平台,可以构建高级知识图谱,以简化复杂的数据分析和检索任务,而无需部署 LLM 所需的高昂成本。这种方法不仅使强大的数据处理工具更易于访问,而且还促进了信息提取工作流程的创新和效率。



![HTML+CSS+JS实现商城首页[web课设代码+模块说明+效果图]](https://i-blog.csdnimg.cn/direct/41f0acdef9e64987abfa53283973f387.png)