文章目录
- 概述
- 字节序
- 必须转换字节序的的情况
- 不必转换字节序的的情况
- 字节序转换的例程
- 字节序转换函数
- 字节序转换可以不生硬
- 字节序和位序
概述
本文主要讲述了在哪些场景下必须要进行大小端字节序转换,在哪些场景下可以不用进行大小端字节序转换,IP和端口号转网络字节序的必要性、避免应用数据逐个字段生硬转字节序的方法。在 MSDN Windows Sockets: Byte Ordering 帮助文档案例的基础上,略微延伸,以对网络字节序应用场景、主机字节序与网络字节序结构定义和转换方法,形成更直观些的认识。
@History
对于大部分猿,很少会碰到真正需要字节序转换的场景,相关官方资料也并不多。偶然在MSDN中发现了, Windows Sockets: Byte Ordering 这篇文章,其讲述的是 Windows 套接字编程系列问题。你可以在MSDN查看器中搜索,也可以按照上述连接来跳转在线帮助页面,本文基于上述文章内容,进行了适当的展开说明,其大场景是基于 Windows Sockets 的,还掺杂了MFC的宣教,多少带着些片面,但这并不妨碍其给我们带来期望的启迪。
转载请标明出处,
https://blog.csdn.net/quguanxin/category_10527523.html
字节序
在《存储与传输/大小端字节序的概念、决定因素、给编程带来的困扰》文章中,已经详细的描述了大小端字节序的名称的来源及其概念的记忆方法,这里不再赘述。该小节是 MSDN 中对 Intel 处理器字节序的一个简短说明。
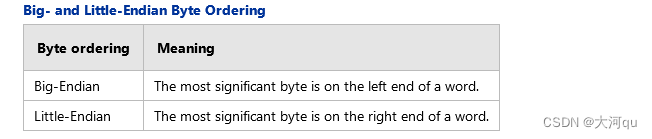
不同的机器架构有时会使用不同的字节顺序存储数据。例如,基于 Intel 的机器使用的字节顺序与 Macintosh (Motorola) 机器相反。Intel 的字节顺序被称为"小端"(Little-Endian),也与网络标准的"大端"(Big-Endian)顺序相反。大端字节序和小端字节序的具体表述如下:
通常情况下,在通过网络发送和接收数据时,你不需要担心字节顺序的转换。但是,也存在一些情况下你必须进行字节顺序的转换。

必须转换字节序的的情况
你需要在以下情况下进行字节顺序转换:

1、当你需要传递一些信息,而这些信息需要被 [network] ( 网络(设备))正确解释,而不是仅仅(as opposed to )传递数据(与前半句的待传递信息对应)给另一台机器。例如,你可能需要传递端口号和地址,这些信息必须被网络设备正确理解。而此处所谓的network网络设备可能是指,路由器、交换机、防火墙、负载均衡器等,如果不进行适当的字节顺序转换,这些网络设备可能无法正确地解析和处理端口号和IP地址等信息,更直接的描述是,人家这些通用网络设备都遵循了网络字节序规则,因此你也要遵循。
我们也该注意到另一个问题,就是上述网络设备,它只能解析到端口和地址等TCP/IP头的字段,而对于应用层数据段,它们不关心也没有依据去解析数据内容。只有参与通信的终端设备才会知道数据内容的真正含义,也才有可能进行多字节数据的字节序转换。
由上述分析可以衍生出来1个小结论,网路字节序在TCP/IP层,也即在网络设备上被解析的层次上,其强制性要更高,是必须要遵守的。对应的,在应用层数据段上,这种强制性显得略弱一些,不是必须遵守的。
2、如果你正在与一个服务器应用程序通信,而该服务程序不是 MFC 应用程序(并且你没有它的源代码)。这是因为(this calls for),两台机器可能使用不同的字节序,需要进行转换以确保数据能够正确传输和解释。
也要注意的是,并不是只有涉及到网络通信时才会产生大小端的需求。一些其他的情况,如,
1、存储和传输数据: 如果你需要在不同的平台之间传输数据,并且这些平台使用不同的字节顺序,则需要进行字节顺序转换。否则,数据可能会被错误地解释。
2、跨平台编程: 当在不同架构的机器上运行程序时,如果程序需要在本地使用数据,则必须确保数据的字节顺序正确。这通常需要在读取和写入数据时进行转换。
不必转换字节序的的情况
在如下情况下,没有必要进行字节序转换。

1、通信双方使用相同的字节序,且已经约定好了都不进行字节序变换。
2、你正在与之通信的服务是基于MFC应用程序。不要过度解读这句话,说这句话的前提是,上下文中谈论的是windows套接字,而不是其他平台或系统,MFC 的特殊性在于它与 Windows 操作系统深度集成,可以确保字节序的一致性,从而免去了手动转换的需要。
3、你正在与之通信的服务程序,你持有它的源代码,基于此,你可以清楚明确地(explicitly)辨别出是否需要进行字节序转换。
4、您可以将服务器程序port移植到 MFC 平台上。这通常比较容易实现,而且最终得到的代码通常会更小、运行更快。感觉是套话。
接下来的这两段,与MFC太过密切,
先简单扩展下,CAsyncSocket 是 MFC 提供的一个基础的异步 Socket 类。它提供了Socket编程的基本功能,如创建、连接、收发数据等,使用 CAsyncSocket 需要自己处理字节序转换等细节。CArchive 是 MFC 的一个序列化类,用于对数据进行序列化和反序列化。它会自动处理字节序转换的细节,确保数据在不同字节序的平台间传输正确。CSocket 是建立在 CAsyncSocket 之上的一个更高级的 Socket 类。它集成了数据流读写操作,使用更加方便,其内部会使用 CArchive 类来处理字节序转换。
在使用 CAsyncSocket 时,您必须自行管理任何必要的字节顺序转换。Windows Sockets 采用了"大端"字节顺序模型作为标准,并提供了函数来在这种顺序与其他顺序之间进行转换。但是,您在使用 CSocket 时会用到 CArchive,它使用的是相反的(“小端”)顺序。不过 CArchive 会自动处理好字节顺序转换的细节。通过在您的应用程序中使用这种标准的字节顺序,或者使用 Windows Sockets 提供的字节顺序转换函数,您可以使您的代码更加可移植。
使用 MFC Sockets 的理想情况是当您正在编写通信的双方都使用 MFC 时。但是,如果您正在编写一个应用程序,它需要与非 MFC 应用程序(如 FTP 服务器)进行通信,那么在将数据传递给 Archive 对象之前,您很可能需要自己管理字节交换,使用 Windows Sockets 提供的 ntohs、ntohl、htons 和 htonl 等转换函数。本文稍后会给出一个与非 MFC 应用程序进行通信时使用这些函数的示例。当通信的另一端不是 MFC 应用程序时,您还必须避免将从 CObject 派生的 C++ 对象流式传输到您的 Archive 中,因为接收端无法处理这些对象。
字节序转换的例程
很长的一段时间内,我苦于找不到有字节序转换的实际场景,我怀着一颗无比好奇的心开始了本例程的阅读。接下来的例程,向我们展示了一个使用Archive的CSocket对象的 serialization function 序列化函数。它还向我们阐明了(illustrates )如何在Windows Socket API 中使用字节序转换函数。示例中提出presents了一个如下场景scenario,
你要写一个客户端与服务端通信,但是该服务端不是基于MFC平台的,且你不能访问到该服务端程序的源代码。在此情景下,你必须假定这个服务端程序使用的是标准网络字节序。in contrast 相比之下,您的 MFC 客户端应用程序使用了一个 CSocket 对象和一个 CArchive 对象,而 CArchive 使用 “小端” 字节顺序,这与网络标准的 “大端” 字节顺序相反。
假设你计划与之通信的服务程序,已经制定 established 了的如下所示的消息包协议,protocol for a message packet

你要写的基于MFC的客户端,对应的消息结构如下,
struct Message {
long m_lMagicNumber;
short m_nCommand;
short m_nParam1;
long m_lParam2;
void Serialize( CArchive& ar );
};
在C++中,一个结构体本质上与一个类是一致的,上述Message结构可以具有一个成员函数,如上述Serialize成员函数,该函数实现大约如下,
void Message::Serialize(CArchive& ar) {
if (ar.IsStoring()) {
ar << (DWORD)htonl(m_lMagicNumber); //将网络字节序转换为主机字节序小端后,再序列化
ar << (WORD)htons(m_nCommand);
ar << (WORD)htons(m_nParam1);
ar << (DWORD)htonl(m_lParam2);
}
else {
WORD w;
DWORD dw;
ar >> dw;
m_lMagicNumber = ntohl((long)dw); //在反序列化的过程中,将小端存储的数据转成大端字节序
ar >> w ;
m_nCommand = ntohs((short)w);
ar >> w;
m_nParam1 = ntohs((short)w);
ar >> dw;
m_lParam2 = ntohl((long)dw);
}
}
如上,该示例需要进行字节顺序转换,因为非 MFC 的服务器应用程序,其字节顺序与 MFC 客户端应用程序使用的 CArchive 的字节顺序存在明显的不匹配。
字节序转换函数
上述示例演示了 Windows Sockets 提供的几个字节顺序转换函数。下表描述了这些函数:
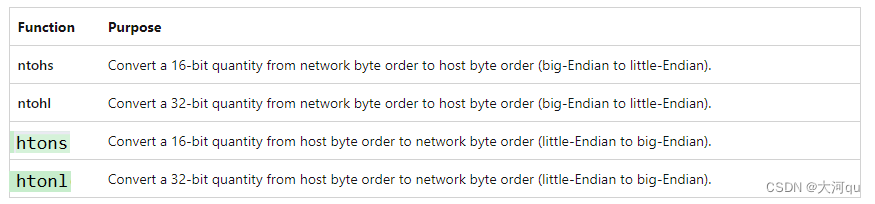
英语单词 quantity 不仅具有数量、大量等意思,还有数值的意思,如上 32-bit quantity 表示一个32比特的数值。 以htonl函数为例,
//host to net long int
u_long htonl([in] u_long hostlong);

如上,htonl的MSDN中提到了,使用该函数可以将一个本地字节序的IP地址转换成网络字节序的IP地址,但是不会检查作为输入参数的IP地址的合法性。字节序转换函数的使用,不依赖于WSAStart来初始化网络库。还有就是不要想多了,这是Windows网络库中的函数,这里的htonl就是完全的等价于将小端字节序转换成大端字节序,没有什么额外的其他处理。
字节序转换可以不生硬
看完上文小节中的中大小端字节序转换的例子,我不知道你想到了什么。我想到的是,如果 Message 不是只有4个待转换的多多字节字段,而是有10个,或者,还有Message2…Message50需要做类似的转换,呃呃呃,你会不会被搞得头大? 不禁要问,难道跨平台的大小端字节序转换,只能是逐个消息结构,逐个结构字段,如此生硬的进行转化? 显然那不可能!我们简单聊聊这个事情。
前文已经讨论过,在有些情况下可以不去进行字节序转换,有的时候必须要进行,这两种状态的大前提都是得有需要进行字节序转换的多字节数据。说到这里,就想到了围魏救赵解决字节序问题的一个思路,即,消除待传输信息中的多字节数据。这里的消除,可以是真正的消除,如传输结构中只使用字节数组,当然这不太现实;也可以是像文本文件加BOM的方式那样,显式的标记出传输的文件/字节流是大端还是小端字节序的。不过讲真的,好像很难回避啊?消息数据都是单字节,不靠谱。即使是文本文件,也必须要考虑多字节编码情况下的大小端问题。
如,HTTP消息是以文本形式传输的,通常使用ASCII编码或UTF-8编码。UTF-8 编码使用 1-4个字节来表示每个字符,当时多字节时,就要考虑大小端问题。我们就着文本文件编码这个事情,稍微深入下:
文本文件的字节序标记
在 MSDN 中还发现了 Using Byte Order Marks 这篇文章,一起写在这里,进一步加深对字节序的理解,并不打算具体深入展开。
始终为 Unicode 纯文本文件添加字节顺序标记的前缀(BOM),以告知接收文件的应用程序该文件的字节序。如此一来,传输此文件时,就不用关心其字节序了,由接收端按照BOM标记自行处理。必须先要理解的是,所谓文本文件,其中存储的并不是可见字符,而是字符的编码值,文本编辑器或其他应用程序替我们完成了字符编码值和可见字符之间的转换。文本文件的内容就是一串数字编码,比如ASCII编码或者Unicode编码。文本编辑器会根据文件中的编码值,查找对应的字形并显示出来。
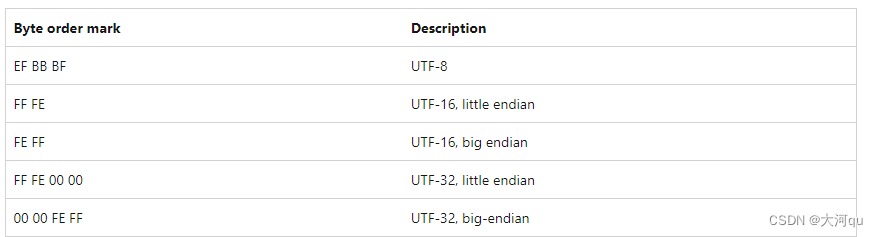
如果文件编码是UTF-32,则每个文本字符都使用4个字节表示,将所有编码显示为可见字符,这很好理解。使用 UTF-32 编码可以简化一些字符处理操作,但是它占用更多的存储空间。实际应用中,UTF-8 和 UTF-16 通常是更常见和推荐的 Unicode 编码方式,如微软使用的就是UTF16 编码,小端字节序。UTF-8 编码使用 1-4个字节来表示每个字符。UTF-16 编码使用 2 个字节或 4 个字节来表示每个字符。以UFT-8为例,它是如何知道,读取到1个字节后,就可以翻译成可见字符,而不是再读取下一个字节,联合成两个字节后再一起翻译成一个可见字符?时间有限,这个放在后续发布的字符串和字符编码的博文中继续讨论和讲述。
字节序和位序
这节内容,本不该写在这里,但是写着写着就契合啦。
以太网协议规定了数据的字节传输顺序,但并没有规定数据的位传输顺序。与之不同的是,CAN协议本身并没有规定字节发送顺序,它只规定了数据的位传输顺序(bit ordering),即 MSb First。关于字节序和位序的其他诸多问题,可参考《存储和传输/大小端字节序概念、决定因素、给编程带来的困扰》、《存储和传输/探究普通结构和位域结构体数据在内存中的字节对齐规》、《语言基础/分析和实践 C&C++ 位域结构数据类型》、《网络通信/协议栈内网络字节序与主机字节序的转换实现》等文章,这里不再赘述。