深度神经网络在识别模式和进行预测方面表现出色,但在涉及图像识别任务时,它们常常难以区分相似个体的图像。三元组损失是一种强大的训练技术,可以解决这个问题,它通过学习相似度度量,在高维空间中将相似图像准确地嵌入到彼此接近的位置。 在这篇文章中,我们将以简单的技术术语解析三元组损失及其变体批量三元组损失,并提供一个相关的例子来帮助你理解这些概念。

三元组损失
三元组损失是一种用于训练神经网络的损失函数,可以用于执行诸如人脸识别或目标分类等任务。三元组损失的目标是在高维嵌入空间(也称为特征空间)中学习一种相似度度量,在这个空间中,相似对象(例如,同一个人的图像)的表示彼此接近,而不相似对象的表示则相距较远。
三元组损失的核心概念是使用三元组,它由一个锚点样本、一个正样本和一个负样本组成。锚点样本和正样本是相似的实例,而负样本则是不相似的。算法学习以这样一种方式嵌入这些样本:锚点样本与正样本之间的距离小于锚点样本与负样本之间的距离。
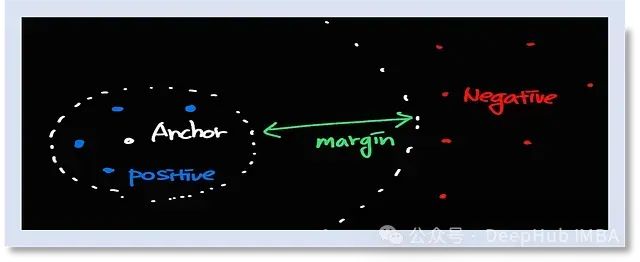
在实践中,三元组损失通常与一种称为孪生网络的神经网络架构一起使用,该架构在处理相同输入的两个或多个分支之间共享权重。这种共享表示允许网络在嵌入空间中学习一个稳健的相似度度量。
当锚点样本和正样本在嵌入空间中不够接近,或者锚点样本和负样本太接近时,三元组损失函数会对网络进行惩罚。这鼓励网络学习输入数据的有意义表示,捕捉相关样本之间的相似性。
三元组损失的例子
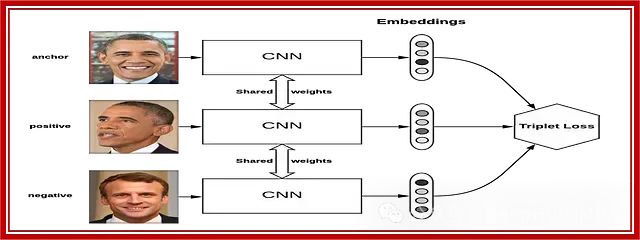
假设有一组不同人的照片,我们想训练一个人脸识别系统。目标是识别两张图像是否属于同一个人。三元组损失可以用来学习一个相似度度量,使系统能够准确识别人脸。
一个三元组由三张照片组成:一个锚点、一个正样本和一个负样本。锚点是特定人的照片,正样本是同一个人的另一张照片,负样本是不同人的照片。

在训练过程中,网络会呈现三元组,三元组损失函数计算锚点、正样本和负样本嵌入(高维特征表示)之间的距离。如果锚点和正样本嵌入之间的距离太大,或者锚点和负样本嵌入之间的距离太小,三元组损失函数就会惩罚网络。
通过基于这个损失函数迭代调整网络的权重,网络学会将相似的人脸(即锚点和正样本)嵌入到嵌入空间中彼此接近的位置,而不相似的人脸(即锚点和负样本)则被分开。
例如,如果同一个人的两张照片(锚点和正样本)的嵌入彼此接近,系统就能准确识别它们属于同一个人。相反,如果不同人的照片(锚点和负样本)的嵌入相距较远,系统就能自信地将它们归类为属于不同的个体。

批量三元组损失
批量三元组损失是传统三元组损失的一种变体,它在训练过程中对数据批次进行操作。在标准三元组损失中,一个批次由三张图像组成:一个锚点、一个正样本和一个负样本。目标是学习一个相似度度量,例如能够准确识别人脸。
而批量三元组损失,不是一次处理一个三元组,而是在一个批次中一起处理多个三元组。这种方法在计算上可能更高效,并且可以利用现代 GPU 的能力更快地训练深度神经网络。
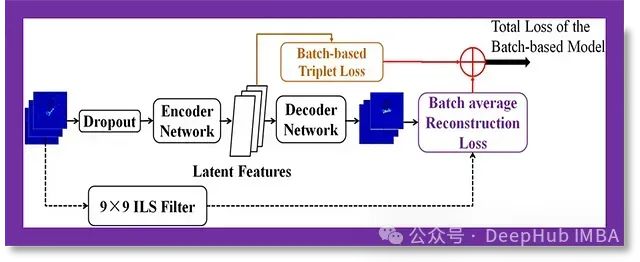
在训练过程中,网络会呈现一批三元组,三元组损失函数计算每个三元组内锚点、正样本和负样本嵌入(高维特征表示)之间的距离。如果锚点和正样本嵌入之间的距离太大,或者锚点和负样本嵌入之间的距离太小,批量三元组损失函数就会惩罚网络。
通过基于这个损失函数迭代调整网络的权重,网络学会将相似的特征(即锚点和正样本)嵌入到嵌入空间中彼此接近的位置,而不相似的特征(即锚点和负样本)则被分开。
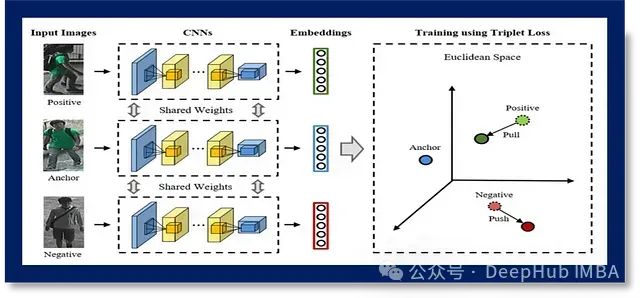
例如,如果同一个人的两张照片(锚点和正样本)的嵌入彼此接近,系统就能准确识别它们属于同一个人。相反,如果不同人的照片(锚点和负样本)的嵌入相距较远,系统就能自信地将它们归类为属于不同的个体。
批量三元组损失是一种有效的方法,用于训练深度神经网络进行人脸识别和其他需要相似度度量的应用。
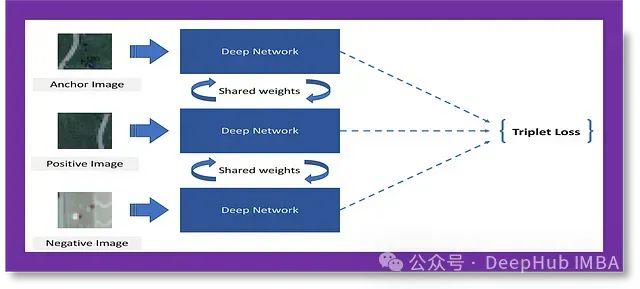
批量三元组损失的例子
假设你是机场的一名安保人员,你的任务是在安检站识别经过的个人。我们有一个手持设备,一次显示三张照片:一个锚点、一个正样本和一个负样本。目标是快速确定锚点照片中的人是否与正样本照片中的人相同,如果不同,还需要识别负样本照片中的人。
这个场景可以被构建为一个批量三元组损失问题。手持设备本质上是在执行一个使用批量三元组损失训练的深度神经网络。锚点、正样本和负样本图像是网络的输入,输出是一组嵌入(高维特征表示),捕捉图像之间的相似性。网络被训练以最小化同一个人的嵌入之间的距离(正对),同时最大化不同人的嵌入之间的距离(负对)。
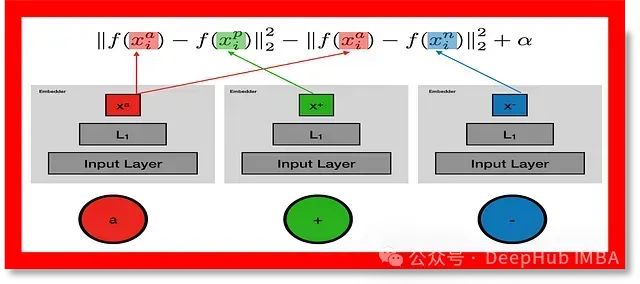
在这个安保场景中,当手持设备向你呈现一批三元组时,网络计算每个三元组内锚点、正样本和负样本图像嵌入之间的距离。如果锚点和正样本图像的嵌入之间的距离很小,你就可以自信地说它们属于同一个人。如果距离很大,你就可以将负样本图像中的人识别为一个不同的个体。
通过使用批量三元组损失和大型图像数据集训练网络,它学会将相似的图像(即同一个人的图像)嵌入到嵌入空间中彼此接近的位置,而不相似的图像(即不同人的图像)则被分开。
总结
本文介绍了三元组损失,这是一种用于训练深度神经网络的技术,主要应用于图像识别任务。三元组损失通过学习高维嵌入空间中的相似度度量,使相似图像的表示彼此接近,不相似图像的表示相距较远。
三元组损失的核心概念是使用由锚点、正样本和负样本组成的三元组进行训练。网络学习将锚点与正样本的距离最小化,同时最大化与负样本的距离。而批量三元组损失,这是一种在单个批次中处理多个三元组的变体,提高了计算效率。
https://avoid.overfit.cn/post/77f8b2530e5a473da038d4ebcd086258
作者:Jyoti Dabass, Ph.D