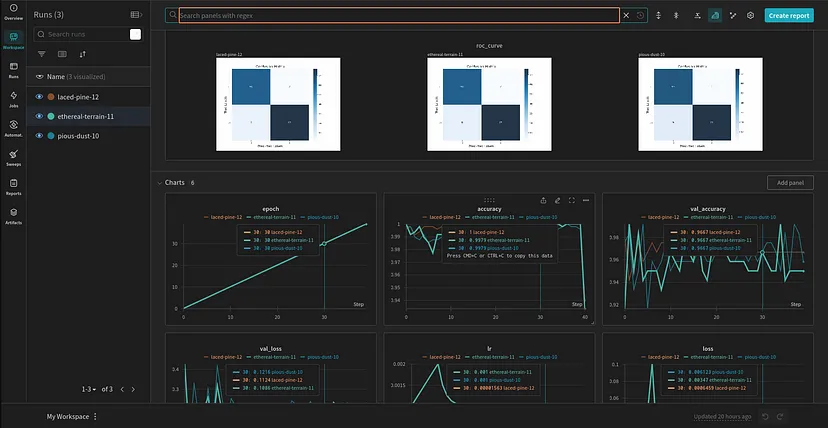
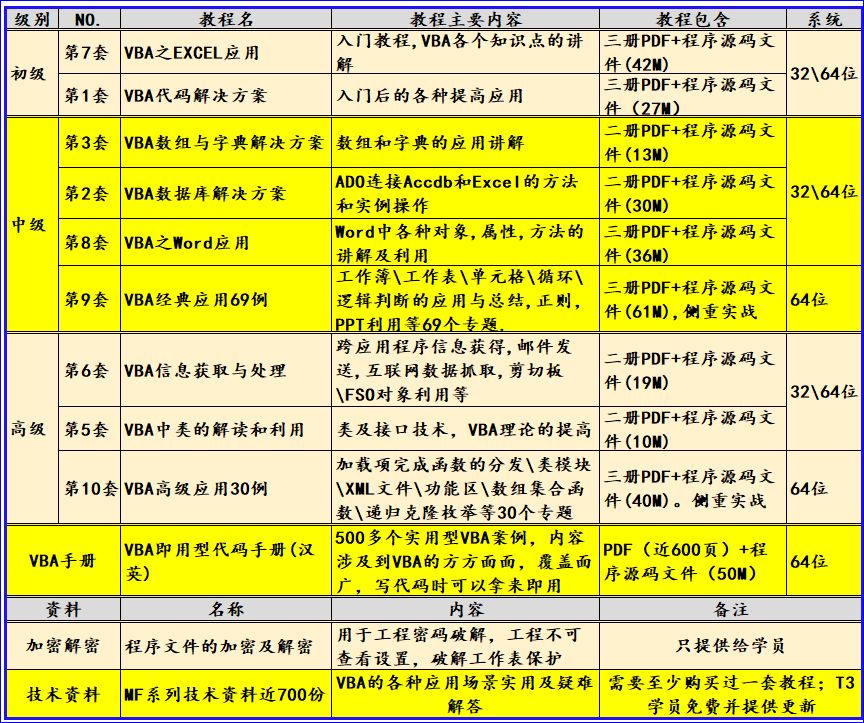
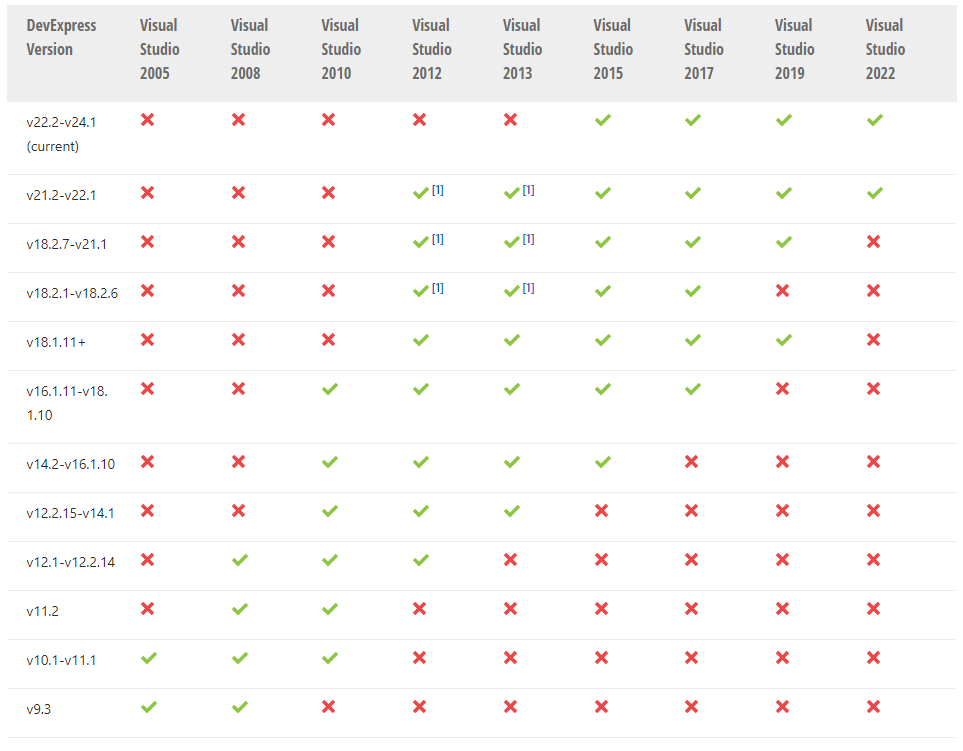
前提条件
- 已经创建好了conda环境
- 已经安装好了scrapy框架
- 项目初始化完成
编写一个爬虫脚本
import scrapy
class StackOverflowSpider(scrapy.Spider):
name = 'stackoverflow'
start_urls = ['http://stackoverflow.com/questions?sort=votes']
def parse(self, response):
print("stackoverflow parse is run ....")
把脚本保存到spiders文件目录内
添加配置
conda环境对应的cmdline.py脚本
先在计算机目录中找到conda环境中安装的scrapy的comline.py位置。一般是:XXX\envs\scrapy_study\Lib\site-packages\scrapy\cmdline.py
配置pycharm
crawl 后面的脚本名就是我们前面编写脚本中name属性值。