我们可以通过 Milvus 轻松实现 BM25 算法,将文档和查询转化为稀疏向量。然后,这些稀疏向量可用于向量搜索,根据特定查询找到最相关的文档。
信息检索算法在搜索引擎中非常重要,可确保搜索结果与用户的查询相关。
想象一下,我们正在寻找一个特定主题的研究论文。当我们在搜索引擎中输入 "RAG "作为关键词时,我们显然希望得到的是关于不同 RAG 方法的论文集,而不是其他一般的 NLP 方法。这就是信息检索算法发挥作用的地方。它们能确保我们获得与关键词高度相关的论文。
有两种常用的信息检索算法:TF-IDF 和 BM25。在本文中,我们将讨论有关 BM25 的一切。不过,在深入探讨之前,我们最好先了解一下 TF-IDF 的基本原理,因为 BM25 基本上是 TF-IDF 的扩展。
TF-IDF 的基本原理
词频-反向文档频率(TF-IDF)是一种基于统计方法的信息检索算法。它衡量文档中的关键词相对于文档集合的重要性。
从其名称可以看出,TF-IDF 由两部分组成:术语频率(TF)和反向文档频率(IDF)。它们衡量的是不同的方面,但最终,我们会将这两个部分相乘,得到最终的分数,从而估算出文档中某个词的相关性。
传统 TF-IDF 的 TF 部分衡量文档中特定关键词的出现率。

上述等式非常直观:我们在文档中找到的关键词实例越多,TF 值就越高。
另一方面,IDF 部分衡量的是包含关键词的文档在文档集中所占的比例。换句话说,这一部分告诉我们有多少文档中出现了我们的关键词。

我们可以看到,关键词在文档中出现的频率越高,其 IDF 分数就越低。这是因为我们要惩罚 “a”、“an”、"is "等常用词,因为它们往往出现在许多文档中。
计算完 TF 和 IDF 分量后,我们将结果相乘,得到关键词的最终 TF-IDF 分数。
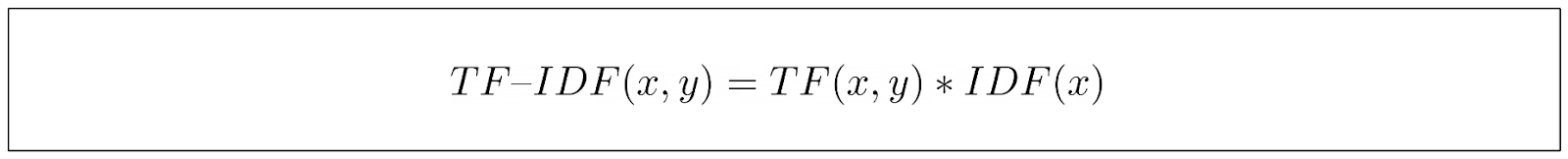
从上面的最后一个等式中,我们可以看出,TF-IDF 能够捕捉到关键词的重要性,如果关键词在某一文档中出现的频率很高,而在其他文档中出现的频率却很低,那么它就会获得更高的分数。
在给定用户关键词或查询时,搜索引擎可以使用 TF-IDF 分数来衡量关键词与文档集之间的相关性。然后,搜索引擎可以对文档进行排序,并将最相关的文档呈现给用户。
TF-IDF 的问题
TF-IDF 公式有两个问题可以改进。
首先,假设我们有一个查询词 "兔子 "和两个要比较的文档。在文档 A 中,"兔子 "出现了 10 次,而该文档有 1000 个单词。另一方面,我们的关键词在文档 B 中只出现了一次,而该文档有 10 个单词。
仔细观察后,我们就会发现 TF-IDF 的局限性。文档 A 的 TF 得分为 10,而文档 B 的得分为 1。因此,与文档 B 相比,文档 A 将被推荐给我们。
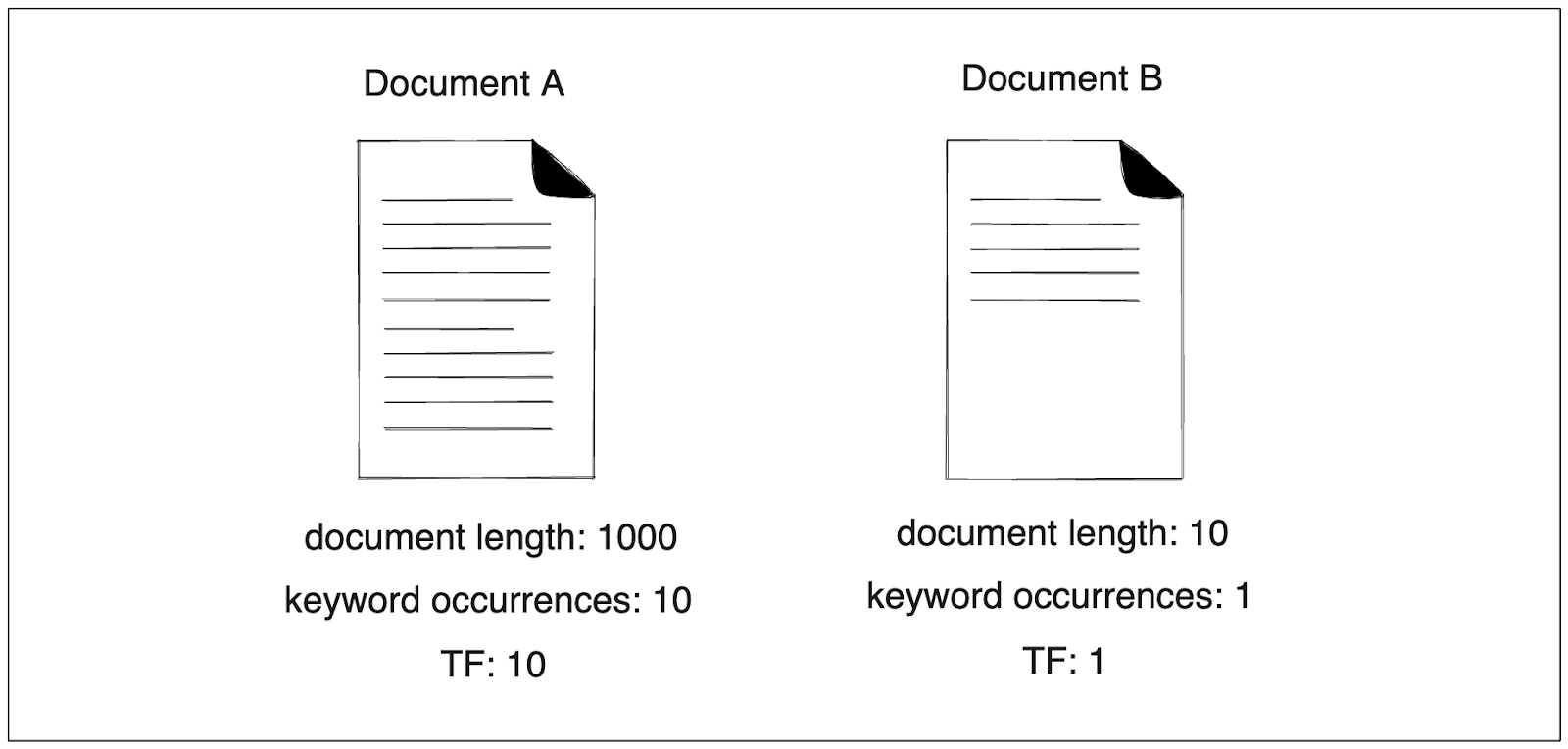
但是,如果考虑到文件的长度,我们可能会说,与文件 A 相比,我们更喜欢文件 B。
如果一篇文档很短,但只出现了一次 “兔子”,那就更能说明该文档确实在谈论兔子。反之,如果一篇文档有数千字,但其中有 10 次提到 “兔子”,我们就不能确定该文档是否具体谈论了兔子。
为了解决这个问题,TF-IDF 的规范化变体将 TF 除以文档长度。这样,TF 部分的 TF 等式就是这样的:
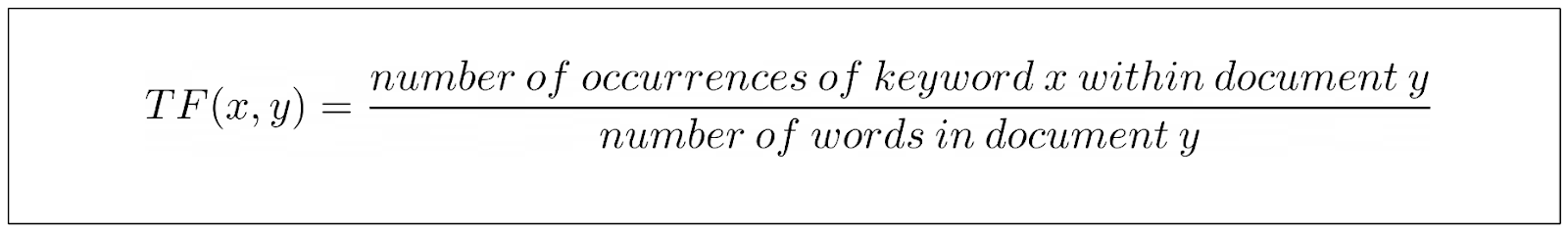
但仍有一个问题需要优化,那就是关键词饱和度。
如果我们看一下 TF-IDF 的 TF 部分,我们在文档中找到的关键词越多,TF 就会越高。这种关系是线性的,这似乎是件好事,因为我们希望不断奖励包含我们关键词的文档。但是,如果我们在一篇文档中找到关键词 "兔子 "400 次,这是否真的意味着这篇文档的相关性是另一篇只出现 200 次的文档的两倍呢?
我们可以说,如果关键字 "兔子 "在一篇文档中出现了这么多次,我们就可以说这篇文档肯定与我们的关键字相关。该文档中关键词的额外出现次数不应该线性地增加其相关性的可能性。
文档中关键字出现次数从 2 次到 4 次所造成的分数跃升应该比从 200 次到 400 次的跃升影响更大。而这正是 TF-IDF 公式目前所缺少的。
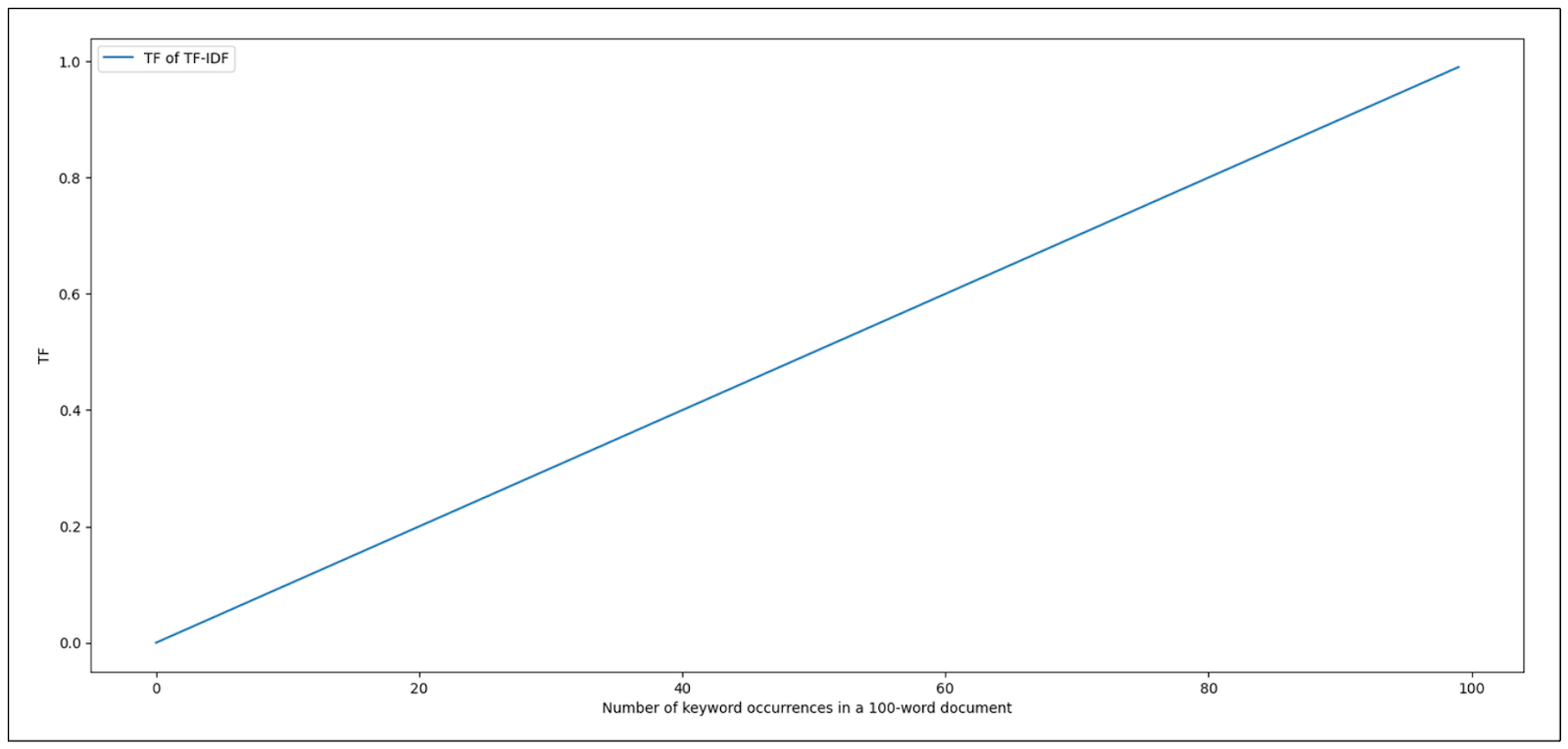
从上面的可视化图中可以看到,由于我们将文档中的字数固定为 100,TF-IDF 的 TF 分数随着关键词出现率的增加而线性增加。
那么,我们该如何改进 TF-IDF 呢?这就是我们需要 BM25 算法的地方。
BM25 的基本原理
最佳匹配 25 (BM25) 算法可以看作是对传统 TF-IDF 算法的改进,它解决了上一节提到的所有问题。
我们先来讨论关键词饱和的问题。TF-IDF 的 TF 部分会随着文档中关键词出现次数的增加而线性增长。从 2 个关键词到 4 个关键词的得分跃升与从 50 个关键词到 52 个关键词的得分跃升相同。
与 TF-IDF 相比,BM25 为 TF 部分引入了一个略有不同的公式,我们将逐一慢慢揭示每个组成部分,以便让我们更容易理解引擎盖下发生了什么。
首先,BM25 在其 TF 公式中引入了一个新参数,而不是仅仅依赖关键词的出现次数:

上述参数 k 的作用是控制关键词每次递增对 TF 分数的贡献。让我们看看下面的可视化图,了解 k 的影响。
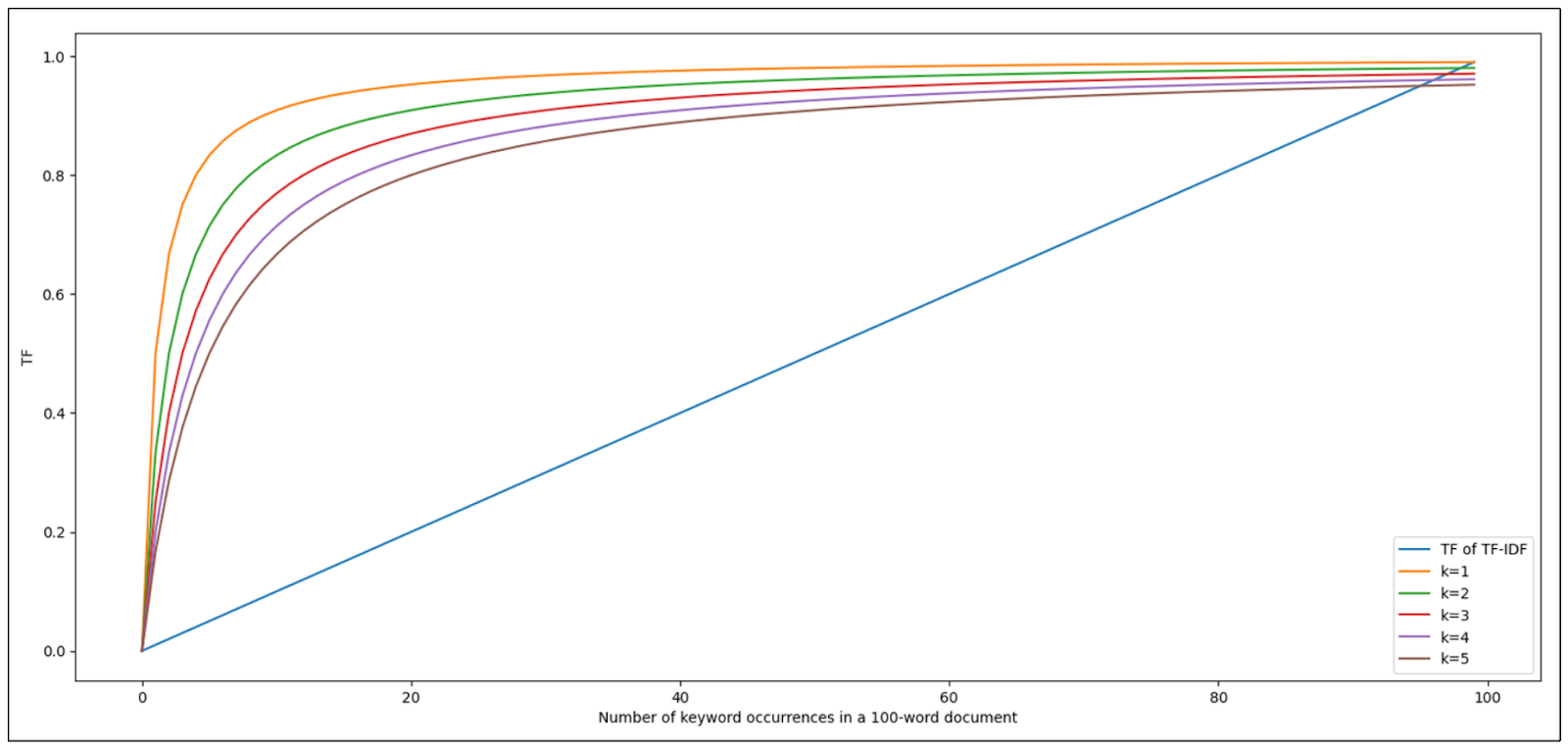
正如您所看到的,最初出现的几个关键词对整体 TF 分数的影响很大。但是,随着我们的关键词在文档中出现的次数越来越多,它对整体 TF 分数的贡献就变得越来越无关紧要了。k 值越大,每次出现的关键词对 TF 分数的贡献增长就越慢。这就解决了 TF-IDF 与关键词饱和度相关的缺点。
与传统的 TF-IDF 相比,BM25 的另一个基本改进是 BM25 将文档长度考虑在内。有了 BM25,包含一个关键词的 10 字文档会比包含 10 个关键词的 1000 字文档更有价值。

术语 ∣D∣ 代表文档长度,而 avg(D) 代表语料库中文档的平均长度。我们已经可以看到文档标准化对 k 参数的影响。如果文档比平均长度短,TF/(TF+k)的值就会增加,反之亦然。换句话说,较短的文档会比较长的文档更快接近饱和点。
不过,我们不能以同样的方式对待所有语料库。在某些语料库中,文档的长度非常重要,而在另一些语料库中,文档的长度则根本不重要。因此,我们在 TF 公式中引入了一个附加参数 b,以控制文档长度在总分中的重要性。

我们可以看到,如果我们将 b 的值设置为 0,那么 D/avgD 的比值就根本不会被考虑,这意味着我们并不重视文档的长度。而值为 1 则表示我们非常重视文档的长度。
以上等式是 BM25 中使用的 TF 部分的最终等式。那么 IDF 部分呢?
BM25 的 IDF 部分方程与 TF-IDF 稍有不同。BM25 的 IDF 公式定义如下:
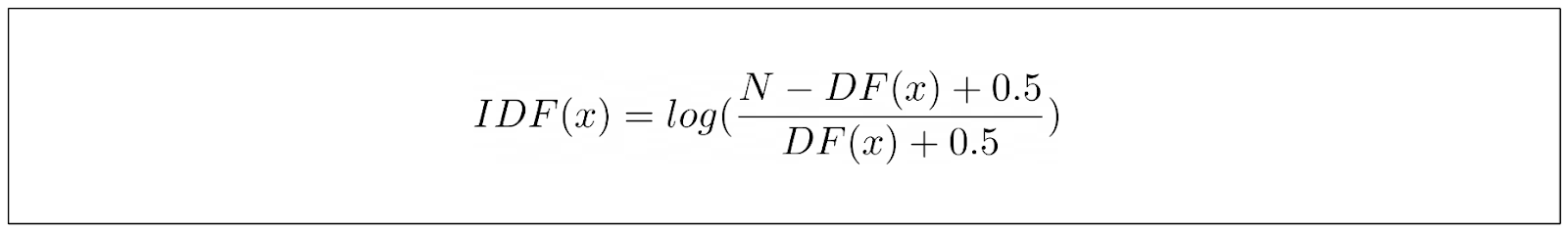
其中,N 是语料库中的文档总数,DF 是包含关键词的文档数量。上述等式源于研究人员的经验观察,他们希望能推导出一个能够捕捉排名函数行为的等式,而不是简单地试验各种值,希望能达到最佳效果。
然而,这个 IDF 等式有一个很大的问题:如果我们在超过一半的语料库中找到我们的关键词,它就会得出一个负值。这在信息检索使用案例中毫无意义。在信息检索中,如果我们的关键词在语料库中的任何文档中都找不到,那么得分就不会低。
为了缓解这个问题,通常会在 IDF 公式中加入一个标量值 1,使其与 TF-IDF 的 IDF 项相同。
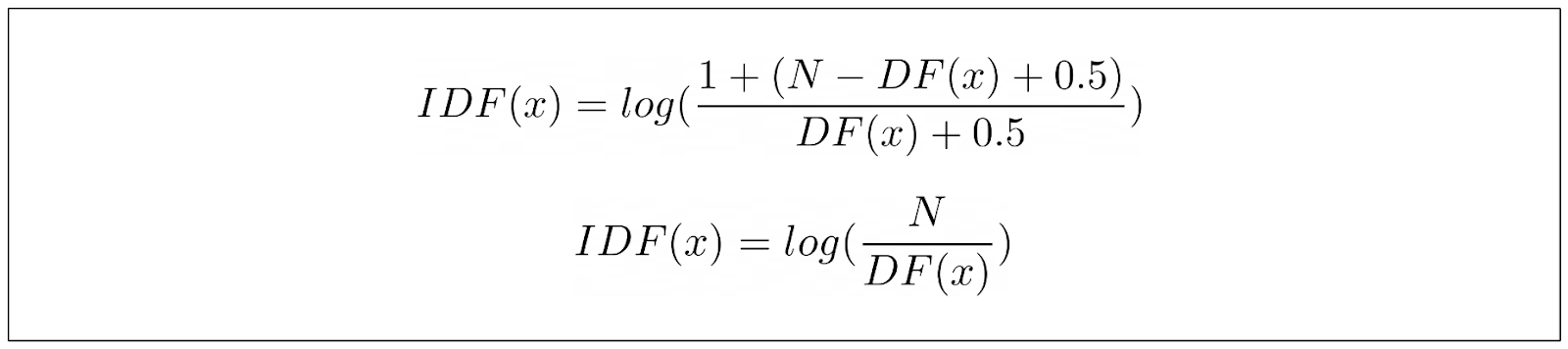
下面是 BM25 计算文档中特定关键词得分的最终公式:
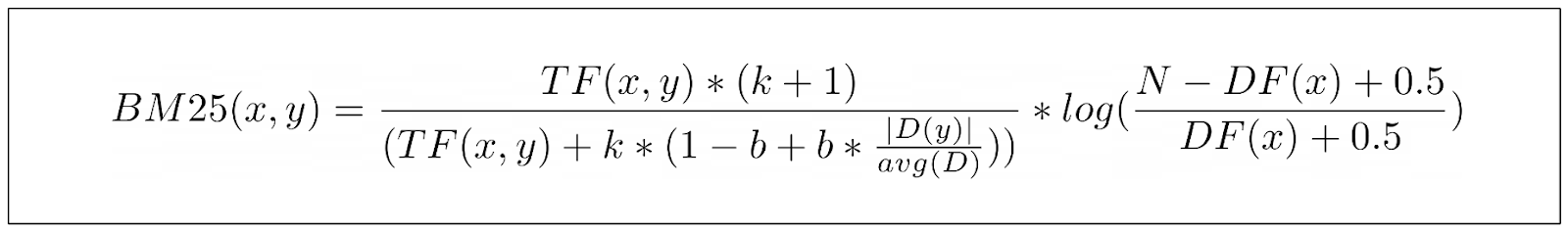
顺便提一句:我们并没有真正讨论过上面 TF 部分分子中的 (k+1) 项。不过,由于这个项并不影响 BM25 整体结果的关系,因此可以忽略这个项。
BM25 的参数
在上一节中,我们了解到 BM25 有两个参数可以根据我们的使用情况进行调整:一个叫做 k,另一个叫做 b。
在实际应用中,k = 1.2 和 b = 0.75 这两个值在大多数语料库中都很有效。不过,您可以尝试使用这两个参数的值,以找到最适合您使用情况的值。这是因为选择 k 和 b 值遵循的是 "天下没有免费的午餐 "理论,也就是说,并不存在适用于所有用例的通用 "最佳 "k 值和 b 值。
根据实验结果,k 值在 0.5 至 2 的范围内趋于最佳,而 b 值在 0.3 至 0.9 的范围内趋于最佳。
在调整 k 值时,请自问:我的文档平均长度是多少?
如果您有一个很长的文档集,那么一个关键词很可能会出现好几次,即使文档并没有真正讨论这个关键词。在这种情况下,您可能希望将 k 值设置在一个较高的范围内,这样就不会太快达到 TF 分数的饱和点。反之亦然。如果文档的平均长度较短,那么您可能希望将 k 值设置在较低的范围内。
关于 b 值,请扪心自问:我有什么样的文档?在我的使用案例中,文档的长度是否会影响关键词的相关性?
例如,如果您有一个长篇科学文档集,那么这些文档中包含的大部分单词很可能都很重要。因此,您可能希望将 b 设置在较低的范围内。与此同时,如果您收集的是意见性和主观性文档,您可能希望将 b 值设置在较高的范围内,以惩罚短文档和长文档中潜在的关键字垃圾邮件。
TF-IDF 与 BM25 的比较
BM25 的确是对传统 TF-IDF 方法的改进。但这并不意味着我们应该使用 BM25 而不是 TF-IDF。在某些情况下,使用 TF-IDF 可能就足够了,因为它比 BM25 更简单,计算成本也更低。
以下是 TF-IDF 和 BM25 在相关性评分(TF-IDF 和 BM25 的最终结果)、精确度、处理较长文档的能力以及最佳使用方案等方面的对比分析列表。
| 方面 | 传统 TF-IDF | BM25 |
| 相关性评分 | - 依靠词频 (TF) 和反向文档频率 (IDF) 计算相关性得分。 | - 通过引入饱和项以及根据经验观察调整参数 k 和 b,对 TF-IDF 进行了改进。 |
| - 对文档中出现频率较高但在整个文档集中较少出现的术语赋予较高权重。 | - 通过考虑术语饱和度和文档长度正常化,提供更复杂的相关性评分,尤其是针对较长的文档。 | |
| 精确度 | - 适用于较小的数据集或术语在文档中分布相对均匀的情况。 | - 比 TF-IDF 更稳健,更适应不同的数据集,能更有效地处理噪声或稀疏数据。 |
| - 对于需要精确匹配的任务(如文档相似性或基于关键字的搜索)非常有效。 | - 在数据质量存在差异或文件集中存在异常值的情况下,可提高精确度。 | |
| 处理较长的文件 | - 由于缺乏文件长度标准化,可能会偏向于较长的文件。 | - 通过将文档长度归一化,解决对较长文档的偏爱问题。 |
| - 与 BM25 相比,较长文档的排名或相关性得分不够准确。 | - 为较长的文档提供更准确的排名和相关性评分。 | |
| 场景 | - 简单易懂。 | - 稀疏和嘈杂的数据 |
| - 完全匹配。 | - 较长的文件。 |
用 Milvus 实现 BM25
在本节中,我们将为语义搜索实现 BM25,并将整个过程与 Milvus 集成。如果您想跟进,请查看本笔记本。
在我们深入研究 Milvus 与 BM25 的集成之前,请务必安装 Milvus 单机版和 SDK。你可以在我们的 Milvus 文档页面找到完整的安装指南。
让我们先加载所有必要的库。
import pymilvus
import pandas as pd
from pymilvus import MilvusClient
from pymilvus import (
utility,
FieldSchema, CollectionSchema, DataType,
Collection, AnnSearchRequest, RRFRanker, connections,
)
from pymilvus.model.sparse.bm25.tokenizers import build_default_analyzer
from pymilvus.model.sparse import BM25EmbeddingFunction
As the data, we'll use an e-commerce dataset that you can download freely on Kaggle. Let's load the dataset and instantiate BM25 model with Milvus.
df = pd.read_csv('.../amazon_products.csv')
df.columns
"""
Output:
Index(['asin', 'title', 'imgUrl', 'productURL', 'stars', 'reviews', 'price',
'listPrice', 'category_id', 'isBestSeller', 'boughtInLastMonth'],
dtype='object')
"""
如上图所示,我们的数据集有几列。出于向量搜索演示的目的,我们将只使用 title 列作为语料库。
BM25EmbeddingFunction 类是 Milvus 对 BM25 嵌入模型的实现,它能将文档或查询转换为稀疏嵌入表示。不过,在将任何文档和查询转化为稀疏嵌入之前,我们需要在语料库中拟合 BM25 模型,收集每个标记的统计数据。
analyzer = build_default_analyzer(language="en")
# Create corpus based on product title
corpus = df["title"].values.tolist()
corpus = [str(i) for i in corpus]
# Use the analyzer to instantiate the BM25EmbeddingFunction
bm25_ef = BM25EmbeddingFunction(analyzer)
# Fit the model on the corpus to get the statistics of the corpus
bm25_ef.fit(corpus)
上面的 build_default_analyzer 函数是 Milvus 的一个内置函数,它可以执行多种功能。首先,它会删除特定语言中常见的停顿词,对剩余的每个词进行标记化处理,然后收集每个标记相关性的统计数据。
现在,假设我们有 5 个产品标题。我们可以使用 encode_documents 方法将每个产品标题转化为稀疏向量表示。
product_title = ['7th Dragon III Code: VFD - Nintendo 3DS (Renewed)',
'Mesh Bags Drawstring Bag Set - Nylon Mesh Drawstring Bags with Cord Lock Closure',
'FIFA 20 Standard Edition - Xbox One',
'Head Case Designs Officially Licensed Tom and Jerry Outdoor Chase Comic Graphics Vinyl Sticker Gaming',
'Cloudz"The Big Bag" Travel & Sport Duffle Bag']
# Create embeddings for product title
product_title_embeddings = bm25_ef.encode_documents(product_title)
print("Sparse dim:", bm25_ef.dim, list(product_title_embeddings)[0].shape)
"""
Output:
Sparse dim: 673273 (1, 673273)
"""
每个文档的向量维数对应于我们的语料库中经过 build_default_analyzer 函数中的停止词过滤处理后的可用标记总数。每个向量元素代表文档中每个标记的相关性得分。
让我们将所有这些向量嵌入插入 Milvus 向量数据库。首先,我们要定义表的模式。然后,我们选择适当的索引和相似度指标,以便在进行向量搜索时使用。
由于 BM25 生成的是稀疏向量,因此我们可以使用倒排索引或 Weak-AND(WAND)算法等索引方法。不过,由于我们的稀疏向量具有高维性,因此我们可以使用倒排索引。这种方法可将每个维度映射到嵌入中的非零值,从而在搜索过程中直接访问相关数据。
作为向量搜索的度量指标,Milvus 目前只支持内积,因此我们将使用它。
connections.connect("default", host="localhost", port="19530")
fields = [
FieldSchema(name="pk", dtype=DataType.VARCHAR,
is_primary=True, auto_id=True, max_length=100),
FieldSchema(name="product_title", dtype=DataType.VARCHAR, max_length=512),
FieldSchema(name="product_title_vector", dtype=DataType.SPARSE_FLOAT_VECTOR),
]
schema = CollectionSchema(fields, "")
col = Collection("bm25_demo", schema)
sparse_index = {"index_type": "SPARSE_INVERTED_INDEX", "metric_type": "IP"}
col.create_index("product_title_vector", sparse_index)
# Insert data into schema
entities = [product_title, product_title_embeddings]
col.insert(entities)
col.flush()
现在我们可以执行矢量搜索了。假设我们有一个查询:“What product should I buy for traveling?” 然后,我们可以使用 encode_queries 将此查询转换为嵌入。接下来,我们可以执行向量搜索,以获得最相似的产品。
# Set up a Milvus client
client = MilvusClient(
uri="<http://localhost:19530>"
)
collection = Collection("bm25_demo") # Get an existing collection.
collection.load()
queries = ["What product should I buy for traveling"]
query_embeddings = bm25_ef.encode_queries(queries)
res = client.search(
collection_name="bm25_demo",
data=query_embeddings[0],
anns_field="product_title_vector",
limit=1,
search_params={"metric_type": "IP", "params": {}},
output_fields =["product_title"]
)
print(res)
"""
Output:
[[{'id': '449258959812952449', 'distance': 4.3612961769104, 'entity': {'product_title': 'Cloudz"The Big Bag" Travel & Sport Duffle Bag'}}]]
"""
我们找到了。根据搜索结果,与我们的查询最相似的产品是 “Cloudz “The Big Bag” Travel & Sport Duffle Bag”,考虑到我们拥有的产品标题目录,这是准确的。
使用 Milvus,您还可以执行其他复杂的矢量搜索。例如,您可以在进行矢量搜索的同时执行元数据过滤,以获得更高的搜索准确性。
此外,我们还可以执行混合搜索。这种搜索将 BM25 的稀疏向量与句子变形金刚或 OpenAI 的深度学习模型通常产生的密集向量相结合,从而提供更准确的产品推荐。
BM25 算法的进步
BM25 算法诞生后,研究人员提出了多种 BM25 优化变体,以扩展其在复杂信息检索场景中的功能。
第一个变体是 BM25F,即 “带字段的最佳匹配 25”。BM25F 对 BM25 算法进行了扩展,以处理具有结构化字段的文档,例如包含标题、正文、作者等多个字段的文档。在 BM25F 中,文档的每个字段都会被单独处理,每个字段的 BM25 分数都会被单独计算。然后使用加权和或其他汇总方法将这些分数合并,得出文档的最终相关性分数。
第二种是 BM25+ 或带相关性反馈的最佳匹配 25。在 BM25+ 中,来自之前搜索结果或用户互动的反馈信息被用来调整文档的相关性得分。用户给予正面评价或点击过的文档相关性得分较高,而给予负面评价的文档相关性得分较低。
结论
BM25 算法可以看作是对传统 TF-IDF 方法的改进,使其能够处理复杂的信息检索情况。BM25 算法的重要改进包括术语频率饱和和文档长度归一化。我们可以通过 BM25 变量(如 k 和 b)来调整这两个因素的影响。
我们可以通过 Milvus 轻松实现 BM25 算法,将文档和查询转化为稀疏向量。然后,这些稀疏向量可用于向量搜索,根据特定查询找到最相关的文档。