复旦&腾讯优图等提出MDT-A2G,这是一个专门用来生成与语音同步手势的先进模型。想象一下,当我们说话时,身体自然会做出手势。这个模型的目的是让计算机也能像人类一样,根据说话的内容来生成合适的手势。它的运作方式像是一个人边听边做笔记,只有把真正重要的东西记下来,然后加以整理并用来进行表达。
模型利用语音、文本和情感等多种信息,进行综合分析,然后通过去噪的过程,修正出准确的手势动作。为了更快地得到结果,它还使用了一些聪明的技巧,像是用已知的参考来加速生成过程。所有这些方法使得MDT-A2G能够生成丰富多彩的手势,而不只是单一的动作。这就是这个模型的基本工作原理,让计算机的“表演”更加生动和自然。
相关链接
论文地址:http://arxiv.org/abs/2408.03312v1
项目地址:https://xiaofenmao.github.io/web-project/MDT-A2G/
论文阅读

摘要
Diffusion Transformer领域的最新进展大大提高了高质量二维图像、三维视频和三维形状的生成。然而,Transformer 架构在同语音手势生成领域的有效性仍然相对未被探索,因为之前的方法主要采用卷积神经网络 (CNN) 或简单的几个变换器层。
为了弥补这一研究空白,我们引入了一种用于同语音手势生成的新型掩蔽Diffusion Transformer,称为 MDT-A2G,它直接在手势序列上实现去噪过程。为了增强时间对齐的语音驱动手势的上下文推理能力,我们采用了一种新型的掩蔽扩散变换器。该模型采用了一种掩蔽建模方案,专门用于加强序列手势之间的时间关系学习,从而加快学习过程并产生连贯而逼真的动作。除了音频,我们的 MDT-A2G 模型还集成了多模态信息,包括文本、情感和身份。
此外,我们提出了一种高效的推理策略,通过利用先前计算的结果来减少去噪计算,从而实现加速,而性能损失几乎可以忽略不计。实验结果表明,MDT-A2G 在手势生成方面表现出色,其学习速度比传统扩散变压器快 6 倍以上,推理速度比标准扩散模型快 5.7 倍。
方法
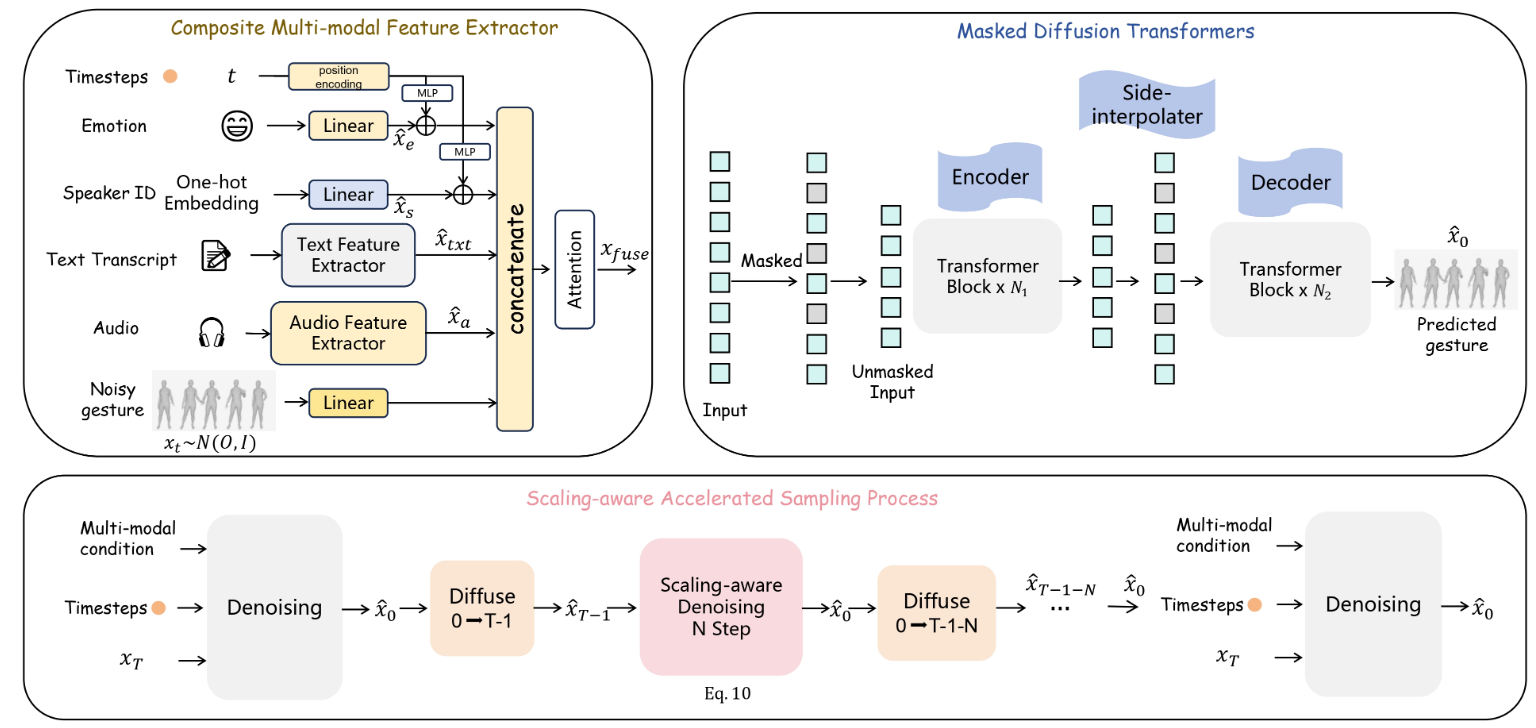
MDT-A2G 概述。它主要由三个组件组成:
-
复合多模态特征提取器
-
掩蔽扩散变换器
-
缩放感知加速采样过程。
对于多模态特征提取器,我们提出了一种创新的特征融合策略,将时间嵌入与情感和 ID 特征相结合。这些将进一步与文本、音频和手势特征连接起来,从而产生全面的特征表示。此外,我们设计了一个掩蔽扩散变换器结构来加速去噪网络的收敛,从而实现更连贯的运动。最后,我们通过利用来自先前时间步骤的扩散结果引入了一个缩放感知加速采样过程,从而加快了采样过程。
效果

整体运动生成的定性比较。参考补充视频获得更直观的比较。
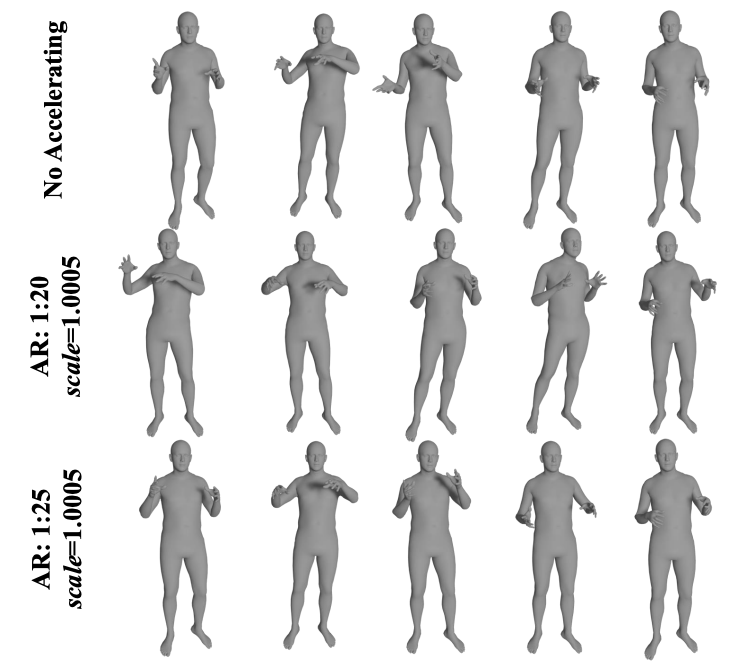
不同加速比对比。AR为加速比。全部采用MDT-A2G-B。
结论
我们介绍了一种新型的 MDT-A2G,一种用于同声手势生成的掩码扩散变换器。得益于独特的掩码建模方案,MDT-A2G 增强了手势之间的时间和语义关系学习,从而加速了学习过程。多模态信息的整合已被证明可以有效地生成更逼真的手势。此外,我们高效的推理策略减少了去噪计算,从而将速度提高了 5.7 倍,而性能下降却微乎其微。实验结果证实了 MDT-A2G 在手势生成方面的优势,其训练和推理速度明显快于传统同类产品。这项研究弥补了同声手势生成方面的重大差距,为未来的研究开辟了道路。