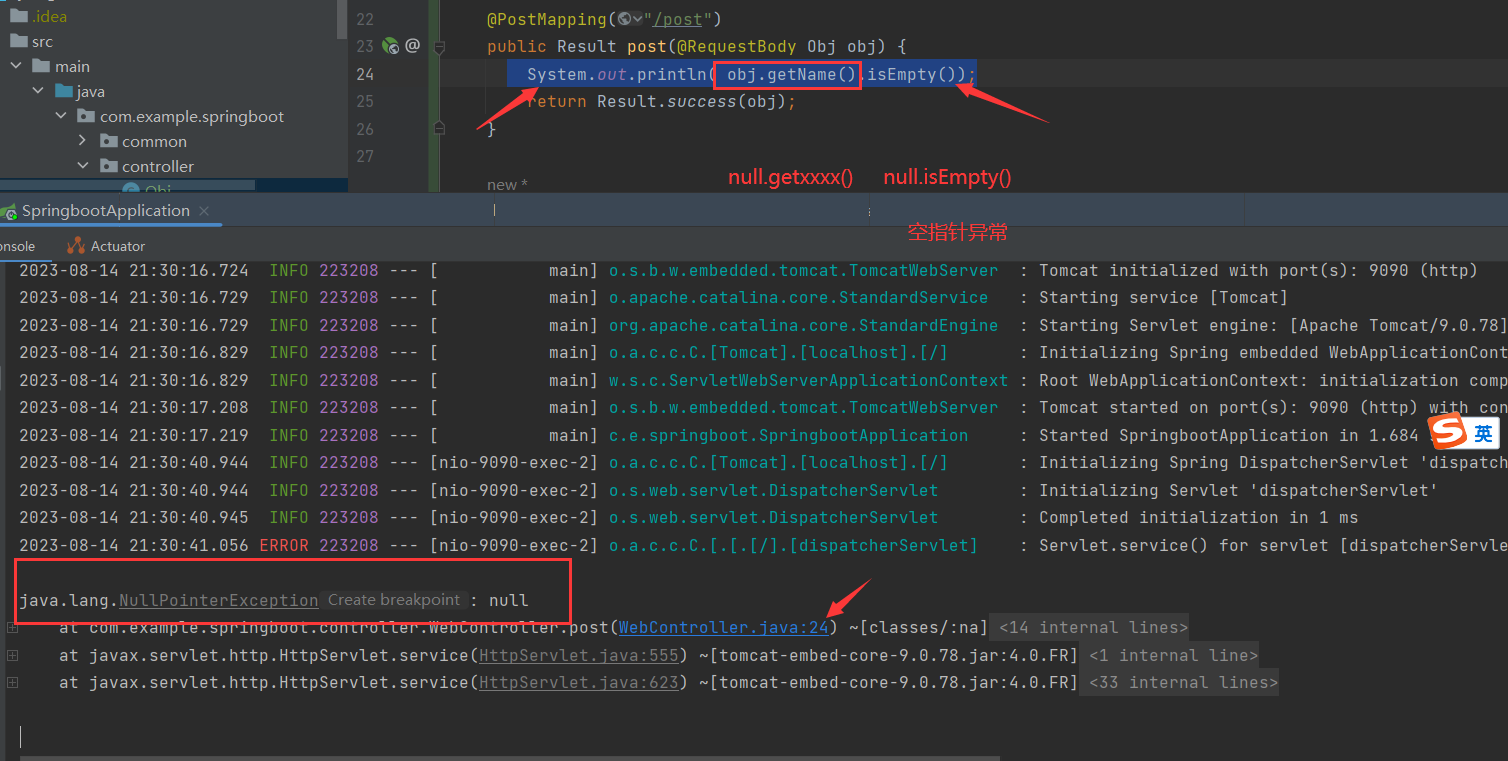
Kafka系列之:Kafka Connect深入探讨 - 错误处理和死信队列
- 一、快速失败
- 二、YOLO:默默忽略坏消息
- 三、如果一条消息掉在树林里,会发出声音吗?
- 四、将消息路由到死信队列
- 五、记录消息失败原因:消息头
- 六、记录消息失败原因的方法:日志记录
- 七、处理来自死信队列的消息
- 八、使用 KSQL 监控死信队列
- 九、Kafka Connect 未提供哪些错误处理?
- 十、错误处理配置方式
- 十一、结论
Kafka Connect是Apache Kafka®的一部分,是一个构建Kafka和其他技术之间流水线的强大框架。它可以用于从多个位置(包括数据库、消息队列和平面文件)将数据流式传输到Kafka,也可以将数据从Kafka流式传输到目标,如文档存储、NoSQL数据库、对象存储等。
在完美的世界中,不会出现任何问题,但当出现问题时,我们希望我们的流水线能够尽可能地优雅地处理。一个常见的例子是在特定序列化(期望为Avro时却收到JSON,反之亦然)的主题上收到消息。自Apache Kafka 2.0以来,Kafka Connect已经包含了错误处理选项,包括将消息路由到死信队列的功能,这是构建数据流水线的常见技术。
在这里,我们将探讨几种处理问题的常见模式,并探讨如何实现它们。
一、快速失败
有时候,当出现错误时,您可能希望立即停止处理。也许遇到坏数据是上游问题的一个征兆,必须解决这些问题,继续尝试处理其他消息没有意义。

这是 Kafka Connect 的默认行为,可以使用以下命令显式设置:
errors.tolerance = none
在此示例中,连接器配置为从主题读取 JSON 数据,并将其写入平面文件。这里需要注意的是,我使用 FileStream 连接器用于演示目的,但不建议在生产中使用。
curl -X POST http://localhost:8083/connectors -H "Content-Type: application/json" -d '{
"name": "file_sink_01",
"config": {
"connector.class": "org.apache.kafka.connect.file.FileStreamSinkConnector",
"topics":"test_topic_json",
"value.converter":"org.apache.kafka.connect.json.JsonConverter",
"value.converter.schemas.enable": false,
"key.converter":"org.apache.kafka.connect.json.JsonConverter",
"key.converter.schemas.enable": false,
"file":"/data/file_sink_01.txt"
}
}'
主题中的一些 JSON 消息无效,连接器立即中止,进入 FAILED 状态:
$ curl -s "http://localhost:8083/connectors/file_sink_01/status"| \
jq -c -M '[.name,.tasks[].state]'
["file_sink_01","FAILED"]
查看 Kafka Connect 工作日志,我们可以看到错误被记录并且任务中止:
org.apache.kafka.connect.errors.ConnectException: Tolerance exceeded in error handler
at org.apache.kafka.connect.runtime.errors.RetryWithToleranceOperator.execAndHandleError(RetryWithToleranceOperator.java:178)
…
Caused by: org.apache.kafka.connect.errors.DataException: Converting byte[] to Kafka Connect data failed due to serialization error:
at org.apache.kafka.connect.json.JsonConverter.toConnectData(JsonConverter.java:334)
…
Caused by: org.apache.kafka.common.errors.SerializationException: com.fasterxml.jackson.core.JsonParseException: Unexpected character ('b' (code 98)): was expecting double-quote to start field name
at [Source: (byte[])"{brokenjson-:"bar 1"}"; line: 1, column: 3]
为了修复流水线,我们需要解决源主题上的消息问题。除非我们告诉它,否则Kafka Connect不会简单地“跳过”坏消息。如果这是一个配置错误(例如,我们指定了错误的序列化转换器),那没关系,因为我们可以进行更正,然后重新启动连接器。然而,如果确实是主题上的坏记录,我们需要找到一种方法来不阻塞处理其他有效记录的方式。
二、YOLO:默默忽略坏消息
errors.tolerance = all

实际上,这看起来像:
curl -X POST http://localhost:8083/connectors -H "Content-Type: application/json" -d '{
"name": "file_sink_05",
"config": {
"connector.class": "org.apache.kafka.connect.file.FileStreamSinkConnector",
"topics":"test_topic_json",
"value.converter":"org.apache.kafka.connect.json.JsonConverter",
"value.converter.schemas.enable": false,
"key.converter":"org.apache.kafka.connect.json.JsonConverter",
"key.converter.schemas.enable": false,
"file":"/data/file_sink_05.txt",
"errors.tolerance": "all"
}
}'
现在,当我们启动连接器时(针对与之前相同的源主题,其中混合了有效和无效消息),它运行得很好:
$ curl -s "http://localhost:8083/connectors/file_sink_05/status"| \
jq -c -M '[.name,.tasks[].state]'
["file_sink_05","RUNNING"]
即使连接器读取源主题上的无效消息,Kafka Connect工作节点的输出中也没有错误记录。预期的是,有效消息的数据将被写入输出文件中:
$ head data/file_sink_05.txt
{foo=bar 1}
{foo=bar 2}
{foo=bar 3}
…
三、如果一条消息掉在树林里,会发出声音吗?
我们已经了解到设置errors.tolerance = all将使Kafka Connect可以忽略坏消息。默认情况下,它不会记录丢弃消息的事实。如果您确实设置了errors.tolerance = all,请确保仔细考虑是否以及如何希望了解发生的消息失败情况。在实践中,这意味着基于可用的指标进行监控/警报,并/或记录消息失败。
确定消息是否被丢弃的最简单方法是将源主题上的消息数量与写入输出的消息数量进行统计。
$ kafkacat -b localhost:9092 -t test_topic_json -o beginning -C -e -q -X enable.partition.eof=true | wc -l150$ wc -l data/file_sink_05.txt100 data/file_sink_05.txt
这种方法并不十分优雅,但它确实显示我们正在丢弃消息-由于日志中没有提及,我们将对此一无所知。
一个更可靠的方法是使用JMX指标,并主动监控和警报错误消息的速率:

我们可以看到发生了错误,但是我们不知道是哪些消息出现了问题。现在这可能是我们想要的(无视问题,不在乎是否丢失消息),但实际上,我们应该知道任何丢失的消息,即使稍后有意识地将其发送到/dev/null。这就是死信队列的概念发挥作用的地方。
四、将消息路由到死信队列
Kafka Connect可以配置为将无法处理的消息(如上面的“快速失败”中的反序列化错误)发送到一个独立的死信队列,即一个单独的Kafka主题。有效的消息将按照正常流程进行处理,流水线将继续运行。然后,可以从死信队列中检查无效的消息,并根据需要进行忽略、修复和重新处理。

要使用死信队列,需要设置:
errors.tolerance = all
errors.deadletterqueue.topic.name =
如果您在单节点 Kafka 集群上运行,您还需要设置errors.deadletterqueue.topic.replication.factor = 1——默认为3。
具有此配置的连接器示例如下所示:
curl -X POST http://localhost:8083/connectors -H "Content-Type: application/json" -d '{
"name": "file_sink_02",
"config": {
"connector.class": "org.apache.kafka.connect.file.FileStreamSinkConnector",
"topics":"test_topic_json",
"value.converter":"org.apache.kafka.connect.json.JsonConverter",
"value.converter.schemas.enable": false,
"key.converter":"org.apache.kafka.connect.json.JsonConverter",
"key.converter.schemas.enable": false,
"file": "/data/file_sink_02.txt",
"errors.tolerance": "all",
"errors.deadletterqueue.topic.name":"dlq_file_sink_02",
"errors.deadletterqueue.topic.replication.factor": 1
}
}'
使用与之前相同的源主题(混合了好坏 JSON 记录),新连接器成功运行:
$ curl -s "http://localhost:8083/connectors/file_sink_02/status"| \
jq -c -M '[.name,.tasks[].state]'
["file_sink_02","RUNNING"]
来自源主题的有效记录被写入目标文件:
$ head data/file_sink_02.txt
{foo=bar 1}
{foo=bar 2}
{foo=bar 3}
[…]
所以我们的管道完好无损并继续运行,现在我们在死信队列主题中也有数据。这可以从指标中看出:

从题目本身考察也可以看出:
ksql> LIST TOPICS; Kafka Topic | Registered | Partitions | Partition Replicas | Consumers | ConsumerGroups--------------------------------------------------------------------------------------------------- dlq_file_sink_02 | false | 1 | 1 | 0 | 0 test_topic_json | false | 1 | 1 | 1 | 1---------------------------------------------------------------------------------------------------ksql> PRINT 'dlq_file_sink_02' FROM BEGINNING;Format:STRING1/24/19 5:16:03 PM UTC , NULL , {foo:"bar 1"}1/24/19 5:16:03 PM UTC , NULL , {foo:"bar 2"}1/24/19 5:16:03 PM UTC , NULL , {foo:"bar 3"}…
在输出中,显示了消息的时间戳(1/24/19 5:16:03 PM UTC)和键(NULL),然后是值。正如您所看到的,值不是有效的JSON {foo:“bar 1”}(foo也应该用引号括起来),因此在处理它时,JsonConverter抛出了异常,因此它最终出现在死信主题上。但是,只有通过查看消息,我们才能看到它不是有效的JSON,即使这样,我们也只能假设为什么消息被拒绝。要确定为什么消息被Kafka Connect视为无效的实际原因,
有两个选项:
- 1.死信队列消息头
-
- Kafka Connect工作器日志让我们依次看一下这些。
五、记录消息失败原因:消息头
消息头是与Kafka消息的键、值和时间戳一起存储的附加元数据,引入于Kafka 0.11。Kafka Connect可以将关于消息被拒绝原因的信息写入消息本身的头部。在我看来,这个选项比仅仅写入日志文件更好,因为它直接将原因与消息关联起来。
要在死信队列消息的头部包含拒绝原因,只需设置:
errors.deadletterqueue.context.headers.enable = true
这给了我们一个如下所示的配置:
curl -X POST http://localhost:8083/connectors -H "Content-Type: application/json" -d '{
"name": "file_sink_03",
"config": {
"connector.class": "org.apache.kafka.connect.file.FileStreamSinkConnector",
"topics":"test_topic_json",
"value.converter":"org.apache.kafka.connect.json.JsonConverter",
"value.converter.schemas.enable": false,
"key.converter":"org.apache.kafka.connect.json.JsonConverter",
"key.converter.schemas.enable": false,
"file": "/data/file_sink_03.txt",
"errors.tolerance": "all",
"errors.deadletterqueue.topic.name":"dlq_file_sink_03",
"errors.deadletterqueue.topic.replication.factor": 1,
"errors.deadletterqueue.context.headers.enable":true
}
}'
和以前一样,连接器成功运行(因为我们设置了errors.tolerance=all):
$ curl -s "http://localhost:8083/connectors/file_sink_03/status"| \
jq -c -M '[.name,.tasks[].state]'
["file_sink_03","RUNNING"]
来自源主题的有效记录被写入目标文件:
$ head data/file_sink_03.txt
{foo=bar 1}
{foo=bar 2}
{foo=bar 3}
[…]
您可以使用任何消费者工具来检查死信队列上的消息(我们在上面使用了KSQL)。这里,我将使用kafkacat,并且您很快就会看到原因。
在最简单的操作中,它看起来像这样:
kafkacat -b localhost:9092 -t dlq_file_sink_03
% Auto-selecting Consumer mode (use -P or -C to override)
{foo:"bar 1"}
{foo:"bar 2"}
…
但是kafkacat有超能力!戴上你的X光眼镜,你将能够看到比仅仅消息值本身更多的信息:
kafkacat -b localhost:9092 -t dlq_file_sink_03 -C -o-1 -c1 \
-f '\nKey (%K bytes): %k
Value (%S bytes): %s
Timestamp: %T
Partition: %p
Offset: %o
Headers: %h\n'
这将获取最后一条消息(-o-1,即使用最后1条消息的偏移量),只读取一条消息(-c1)并按照-f参数指示的格式进行格式化,使用所有可用的好处:
Key (-1 bytes):
Value (13 bytes): {foo:"bar 5"}
Timestamp: 1548350164096
Partition: 0
Offset: 34
Headers: __connect.errors.topic=test_topic_json,__connect.errors.partition=0,__connect.errors.offset=94,__connect.errors.connector.name=file_sink_03,__connect.errors.task.id=0,__connect.errors.stage=VALU
E_CONVERTER,__connect.errors.class.name=org.apache.kafka.connect.json.JsonConverter,__connect.errors.exception.class.name=org.apache.kafka.connect.errors.DataException,__connect.errors.exception.message=Co
nverting byte[] to Kafka Connect data failed due to serialization error: ,__connect.errors.exception.stacktrace=org.apache.kafka.connect.errors.DataException: Converting byte[] to Kafka Connect data failed
due to serialization error:
[…]
您还可以从消息中选择仅头部,并使用一些简单的shell操作将它们拆分,以清晰地查看有关问题的所有信息:
$ kafkacat -b localhost:9092 -t dlq_file_sink_03 -C -o-1 -c1 -f '%h'|tr ',' '\n'
__connect.errors.topic=test_topic_json
__connect.errors.partition=0
__connect.errors.offset=94
__connect.errors.connector.name=file_sink_03
__connect.errors.task.id=0
__connect.errors.stage=VALUE_CONVERTER
__connect.errors.class.name=org.apache.kafka.connect.json.JsonConverter
__connect.errors.exception.class.name=org.apache.kafka.connect.errors.DataException
__connect.errors.exception.message=Converting byte[] to Kafka Connect data failed due to serialization error:
Kafka Connect处理的每个消息都来自源主题,并来自该主题中的特定位置(偏移量)。头部信息准确地显示了这一点,我们可以使用它来返回到原始主题并检查原始消息(如果需要)。由于死信队列有消息的副本,这种检查更像是一个备胎措施。
根据上面的头部信息,让我们检查以下源消息:
__connect.errors.topic=test_topic_json
__connect.errors.offset=94
将这些值分别插入 kafkacat 的主题和偏移量的 -t 和 -o 参数中,得到:
$ kafkacat -b localhost:9092 -C \ -t test_topic_json -o94 \ -f '\nKey (%K bytes): %k Value (%S bytes): %s Timestamp: %T Partition: %p Offset: %o Topic: %t\n' Key (-1 bytes): Value (13 bytes): {foo:"bar 5"} Timestamp: 1548350164096 Partition: 0 Offset: 94 Topic: test_topic_json
与上面来自死信队列的消息相比,您会发现它完全相同,甚至连时间戳都一样。唯一的区别是主题(显然)、偏移量和标题。
六、记录消息失败原因的方法:日志记录
记录拒绝消息原因的第二个选项是将其写入日志。根据您的安装方式,Kafka Connect将其写入标准输出或日志文件。无论哪种方式,每个失败的消息都会产生大量冗长的输出。要启用此功能,请设置:
errors.log.enable = true
您还可以选择通过设置errors.log.include.messages = true在输出中包含有关消息本身的元数据。此元数据包括您可以在上面的消息头中看到的一些相同项,包括源消息的主题和偏移量。请注意,尽管可能会根据参数名称假设,但它不包括消息的键或值本身。
这样就得到了一个类似于以下的连接器:
curl -X POST http://localhost:8083/connectors -H "Content-Type: application/json" -d '{
"name": "file_sink_04",
"config": {
"connector.class": "org.apache.kafka.connect.file.FileStreamSinkConnector",
"topics":"test_topic_json",
"value.converter":"org.apache.kafka.connect.json.JsonConverter",
"value.converter.schemas.enable": false,
"key.converter":"org.apache.kafka.connect.json.JsonConverter",
"key.converter.schemas.enable": false,
"file": "/data/file_sink_04.txt",
"errors.tolerance": "all",
"errors.log.enable":true,
"errors.log.include.messages":true
}
}'
连接器运行成功:
$ curl -s "http://localhost:8083/connectors/file_sink_04/status"| \
jq -c -M '[.name,.tasks[].state]'
["file_sink_04","RUNNING"]
Valid records from the source topic get written to the target file:
$ head data/file_sink_04.txt
{foo=bar 1}
{foo=bar 2}
{foo=bar 3}
[…]
在 Kafka Connect 工作日志中,每个失败记录都有错误:
ERROR Error encountered in task file_sink_04-0. Executing stage 'VALUE_CONVERTER' with class 'org.apache.kafka.connect.json.JsonConverter', where consumed record is {topic='test_topic_json', partition=0, offset=94, timestamp=1548350164096, timestampType=CreateTime}. (org.apache.kafka.connect.runtime.errors.LogReporter)
org.apache.kafka.connect.errors.DataException: Converting byte[] to Kafka Connect data failed due to serialization error:
at org.apache.kafka.connect.json.JsonConverter.toConnectData(JsonConverter.java:334)
[…]
Caused by: org.apache.kafka.common.errors.SerializationException: com.fasterxml.jackson.core.JsonParseException: Unexpected character ('f' (code 102)): was expecting double-quote to start field name
at [Source: (byte[])"{foo:"bar 5"}"; line: 1, column: 3]
所以我们得到错误本身,以及有关消息的信息:
{topic='test_topic_json', partition=0, offset=94, timestamp=1548350164096, timestampType=CreateTime}
如上所示,我们可以使用kafkacat等工具中的主题和偏移信息来检查消息的源头。根据抛出的异常,我们也可能会看到它被记录:
Caused by: org.apache.kafka.common.errors.SerializationException:
…
at [Source: (byte[])"{foo:"bar 5"}"; line: 1, column: 3]
七、处理来自死信队列的消息
所以我们已经设置了一个死信队列,但是我们怎么处理这些“死信”呢?嗯,既然它只是一个Kafka主题,我们可以像处理其他主题一样使用标准的Kafka工具。我们在上面使用kafkacat来检查头部,并且对于消息的内部和元数据的常规检查,kafkacat非常好用。也许我们选择只是重新播放这些消息,这取决于它们被拒绝的原因。
一个可能的情况是连接器使用Avro转换器,而主题上遇到了JSON消息(因此被路由到死信队列)?也许由于传统原因,我们的源主题既有JSON生产者,又有Avro生产者。我们知道这是不好的;我们知道我们需要修复它 - 但是现在,我们只需要让流水线正常运行,将所有数据写入到目标位置。
首先,我们从源主题开始,使用Avro进行反序列化,并将其路由到死信队列。
curl -X POST http://localhost:8083/connectors -H "Content-Type: application/json" -d '{
"name": "file_sink_06__01-avro",
"config": {
"connector.class": "org.apache.kafka.connect.file.FileStreamSinkConnector",
"topics":"test_topic_avro",
"file":"/data/file_sink_06.txt",
"key.converter": "io.confluent.connect.avro.AvroConverter",
"key.converter.schema.registry.url": "http://schema-registry:8081",
"value.converter": "io.confluent.connect.avro.AvroConverter",
"value.converter.schema.registry.url": "http://schema-registry:8081",
"errors.tolerance":"all",
"errors.deadletterqueue.topic.name":"dlq_file_sink_06__01",
"errors.deadletterqueue.topic.replication.factor":1,
"errors.deadletterqueue.context.headers.enable":true,
"errors.retry.delay.max.ms": 60000,
"errors.retry.timeout": 300000
}
}'
此外,我们创建一个第二个接收器,将第一个死信队列作为源主题,并尝试将记录反序列化为JSON。在这里,我们只需要更改value.converter和key.converter,源主题名称以及死信队列的名称(以避免如果此连接器必须将任何消息路由到死信队列时出现递归)。

curl -X POST http://localhost:8083/connectors -H "Content-Type: application/json" -d '{
"name": "file_sink_06__02-json",
"config": {
"connector.class": "org.apache.kafka.connect.file.FileStreamSinkConnector",
"topics":"dlq_file_sink_06__01",
"file":"/data/file_sink_06.txt",
"value.converter":"org.apache.kafka.connect.json.JsonConverter",
"value.converter.schemas.enable": false,
"key.converter":"org.apache.kafka.connect.json.JsonConverter",
"key.converter.schemas.enable": false,
"errors.tolerance":"all",
"errors.deadletterqueue.topic.name":"dlq_file_sink_06__02",
"errors.deadletterqueue.topic.replication.factor":1,
"errors.deadletterqueue.context.headers.enable":true,
"errors.retry.delay.max.ms": 60000,
"errors.retry.timeout": 300000
}
}'
首先,源主题获得了20个Avro记录,我们可以看到原始的Avro接收器读取了20条记录并写出了20条记录:

然后发送了8个JSON记录,8条消息被发送到死信队列,8条消息被JSON接收器写出:

现在我们发送了五个格式错误的JSON记录,我们可以看到从两个方面证明了来自两个接收器的“真正”失败消息:
- 从Avro接收器发送到死信队列的消息数量与成功发送的JSON消息数量之间的差异。
- JSON接收器将消息发送到死信队列。

八、使用 KSQL 监控死信队列
使用JMX监视死信队列的同时,我们还可以利用KSQL的聚合功能编写一个简单的流应用程序来监视消息写入队列的速率:
-- Register stream for each dead letter queue topic.
CREATE STREAM dlq_file_sink_06__01 (MSG VARCHAR) WITH (KAFKA_TOPIC='dlq_file_sink_06__01', VALUE_FORMAT='DELIMITED');
CREATE STREAM dlq_file_sink_06__02 (MSG VARCHAR) WITH (KAFKA_TOPIC='dlq_file_sink_06__02', VALUE_FORMAT='DELIMITED');-- Consume data from the beginning of the topic
SET 'auto.offset.reset' = 'earliest';-- Create a monitor stream with additional columns
-- that can be used for subsequent aggregation queries
CREATE STREAM DLQ_MONITOR WITH (VALUE_FORMAT='AVRO') AS \
SELECT 'dlq_file_sink_06__01' AS SINK_NAME, \
'Records: ' AS GROUP_COL, \
MSG \
FROM dlq_file_sink_06__01;-- Populate the same monitor stream with records from
-- the second dead letter queue
INSERT INTO DLQ_MONITOR \
SELECT 'dlq_file_sink_06__02' AS SINK_NAME, \
'Records: ' AS GROUP_COL, \
MSG \
FROM dlq_file_sink_06__02;-- Create an aggregate view of the number of messages
-- in each dead letter queue per minute window
CREATE TABLE DLQ_MESSAGE_COUNT_PER_MIN AS \
SELECT TIMESTAMPTOSTRING(WINDOWSTART(),'yyyy-MM-dd HH:mm:ss') AS START_TS, \
SINK_NAME, \
GROUP_COL, \
COUNT(*) AS DLQ_MESSAGE_COUNT \
FROM DLQ_MONITOR \
WINDOW TUMBLING (SIZE 1 MINUTE) \
GROUP BY SINK_NAME, \
GROUP_COL;
该聚合表可以交互查询。下面显示了一分钟内每个死信队列中有多少消息:
ksql> SELECT START_TS, SINK_NAME, DLQ_MESSAGE_COUNT FROM DLQ_MESSAGE_COUNT_PER_MIN;
2019-02-01 02:56:00 | dlq_file_sink_06__01 | 9
2019-02-01 03:10:00 | dlq_file_sink_06__01 | 8
2019-02-01 03:12:00 | dlq_file_sink_06__01 | 5
2019-02-01 02:56:00 | dlq_file_sink_06__02 | 5
2019-02-01 03:12:00 | dlq_file_sink_06__02 | 5
由于该表只是下面的 Kafka 主题,因此可以将其路由到您想要的任何监控仪表板。它还可用于驱动警报。让我们想象一下,预计会出现一些不良记录,但一分钟内超过 5 个则表明存在更大的麻烦:
CREATE TABLE DLQ_BREACH AS \
SELECT START_TS, SINK_NAME, DLQ_MESSAGE_COUNT \
FROM DLQ_MESSAGE_COUNT_PER_MIN \
WHERE DLQ_MESSAGE_COUNT>5;
现在我们有另一个主题(DLQ_BREACH),一个警报服务可以订阅它,当接收到任何消息时,可以触发适当的操作(例如,发送呼叫通知)。
ksql> SELECT START_TS, SINK_NAME, DLQ_MESSAGE_COUNT FROM DLQ_BREACH;
2019-02-01 02:56:00 | dlq_file_sink_06__01 | 9
2019-02-01 03:10:00 | dlq_file_sink_06__01 | 8
九、Kafka Connect 未提供哪些错误处理?
Kafka Connect 将处理连接器中的错误,如下表所示:
| 连接器生命周期阶段 | 描述 | 处理了吗? |
|---|---|---|
| start | 当连接器首次启动时,它将执行所需的初始化,例如连接到数据存储 | No |
| poll (for source connector) | 从源数据存储中读取记录 | No |
| convert | 从 Kafka 主题读取数据/将数据写入到 Kafka 主题并[反]序列化 JSON/Avro 等。 | Yes |
| transform | 应用任何配置的单消息转换 | Yes |
| put (for sink connector) | 将记录写入目标数据存储 | No |
请注意,源连接器没有死信队列。
十、错误处理配置方式
Kafka Connect 中的错误处理配置方式有几种排列方式。此流程图显示了如何选择使用哪一个:

十一、结论
- 处理错误是任何稳定可靠的数据流水线的重要部分。根据数据的使用方式,您可以选择以下两种选项之一。如果数据流水线中的任何错误消息都是意外的,并且表示上游存在严重问题,则立即失败(这是Kafka Connect的默认行为)是有意义的。
- 另一方面,如果您将数据流式传输到存储进行分析或低关键性处理,那么只要不传播错误,保持流水线运行更为重要。从这里开始,您可以自定义如何处理错误,但我的起点始终是使用死信队列,并密切监控来自Kafka Connect的可用JMX指标。