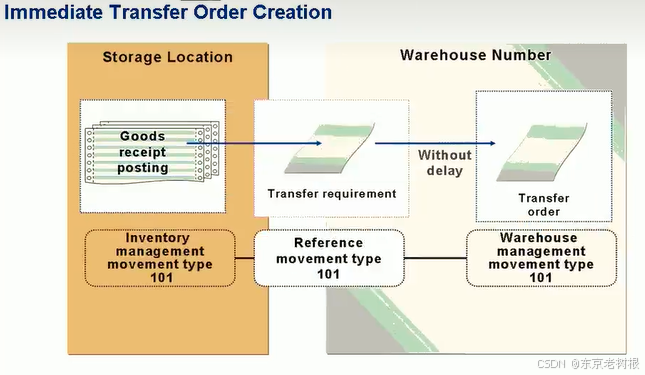
数据分布是指数据在统计图中的形状和特征,即数据取值的统计规律。在统计学中,数据分布是描述数据集中数值分布情况和规律的重要工具。通过数据分布,可以了解数据的集中程度、分散程度、偏态和峰态等信息,进而对数据进行合理的分析和处理。
在数据科学中,了解不同类型的数据分布及其扩散是至关重要的,因为它们可以深入了解数据的性质、行为和任何潜在模式。本文将带您了解数据分布的类型以及它们对您的数据的影响。
常用数据分布
作为数据专业人员,识别数据分布并理解其含义至关重要。它有助于选择正确的统计测试,机器学习模型,适当地转换数据,并得出准确的结论。
主要有以下这些类型的分布:
- 正态分布(高斯分布)
- 均匀分布
- 偏态分布
- 双峰分布
- 指数分布
正态分布(高斯分布)

正态分布通常被称为钟形曲线,因为它的特征是钟形,对称的外观。在正态分布中,大多数数据点聚集在均值(平均值)周围,当您向任一方向远离均值时,数据点较少。
许多统计方法和模型假设数据服从正态分布。这种分布在各个领域都很常见,包括社会科学,物理科学和商业。
当您遇到正态分布时,它表明数据以可预测的标准方式表现,从而更容易执行统计分析和进行预测。在自然界和社会科学中,很多现象都服从正态分布,如人的身高、体重等。
均匀分布

均匀分布显示为平坦的水平线,因为数据范围内的每个值都有相等的出现机会。与正态分布的钟形曲线不同,均匀分布没有明显的波峰或波谷。
在现实世界中,遇到均匀分布的情况相对较少,因为大多数数据自然会表现出一定程度的变化。
当你遇到均匀分布时,它表明数据集中的某些值并没有固有的偏好。在均匀分布中,每个值出现的概率是相等的。
偏态分布

偏态分布可以是右偏态(正偏态)或左偏态(负偏态)。在右偏分布中,右侧的尾部比左侧长或粗,表明有一些高离群值。相反,在左偏分布中,左尾更长或更粗,意味着一些低离群值。
偏态分布可能表明数据中存在离群值或异常,这可能需要解决或调查。偏态数据可能会使一些假设正态性的统计分析复杂化。
在处理偏斜数据时,可能需要数据转换或不同的统计方法来解释偏斜并做出准确的推断。
双峰分布

双峰分布有两个不同的峰值,表明数据集中有两个不同的系统或数据源。与正态分布中的单个中心峰不同,双峰分布显示两个独立的峰,每个峰代表一组不同的数据点。
双峰分布可能会使分析过程复杂化,因为数据不是均匀分布在单个均值周围。识别和理解数据中的两个独立组变得至关重要。
检测双峰分布提示进一步调查,以了解导致两种不同模式或组的存在的潜在因素。
指数分布

指数分布显示,随着远离零,值的概率迅速下降,这使其适合于对罕见事件进行建模。它通常用于对事件发生之前的时间进行建模,例如机器故障之前的时间或客户到达之间的时间。
这种分布对于关注罕见事件或等待时间的各个领域的风险评估和预测很有价值。
当处理遵循指数分布的数据时,必须考虑预测和管理罕见事件或过程的影响。
数据分布中的度量
除了了解数据分布之外,数据专业人员还需要考虑这些分布中的度量:
- 范围:范围表示数据集中最大值和最小值之间的差异。它提供了一个简单的测量数据的传播,但对离群值敏感。
- 四分位距(IQR):IQR是数据的第一四分位数(第25百分位数)和第三四分位数(第75百分位数)之间的范围。与范围相比,它受离群值的影响较小,并可以深入了解中间50%的数据。
- 方差和标准差:方差度量数据点与均值的差异,而标准差是方差的平方根。这些统计数据提供了围绕平均值的数据扩散的定量度量。
- 峰度:峰度测量分布的尾部。高峰度表明分布中的方差更多是由于与平均值的罕见极端偏差,而低峰度表明数据更接近正态分布,极端离群值较少。
总结
- 正态分布(高斯分布):在正态分布中,大多数数据点聚集在平均值周围,随着在任一方向上远离平均值,数据点会减少。
- 均匀分布:均匀分布显示为平坦的水平线,因为数据范围内的每个值都有相等的出现机会。
- 偏态分布:在右偏分布中,右侧的尾部比左侧长或粗,表明有一些高离群值。相反,在左偏分布中,左尾更长或更粗,意味着一些低离群值。
- 双峰分布:与正态分布中的单个中心峰不同,双峰分布显示两个独立的峰,每个峰代表一组不同的数据点。
- 指数分布:指数分布显示,随着远离零,值的概率迅速下降,这使其适合于对罕见事件进行建模。


![[Datawhale AI夏令营 2024 第四期] 从零入门大模型微调之旅的总结](https://i-blog.csdnimg.cn/direct/f89a1fe57d8f4d6b896d6e6e3e41d09d.png#pic_center)