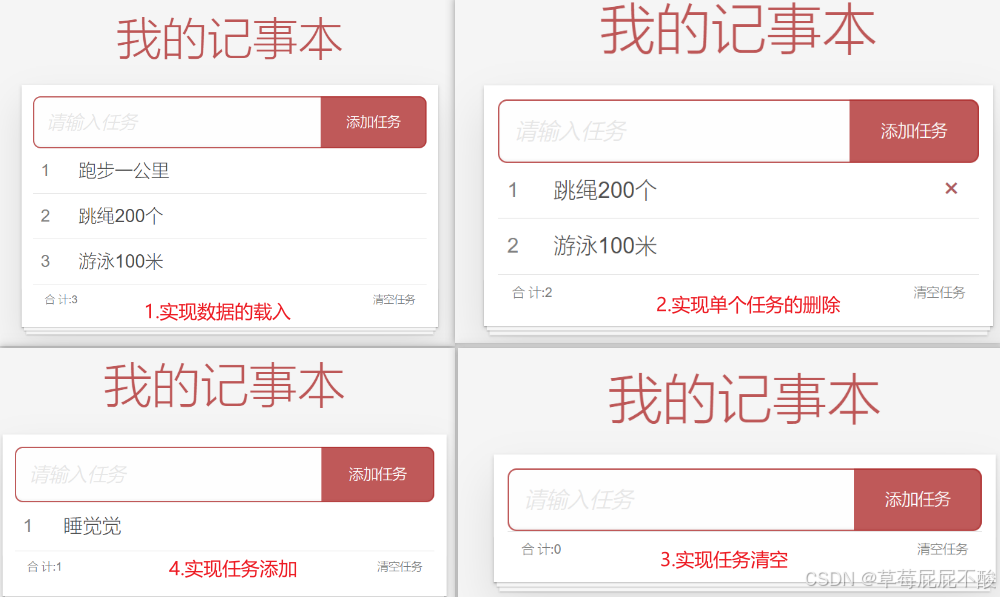
1. 基础了解
1.1 运行方式
Python有多种运行方式,以下是几种常见的执行Python代码的方法:
- 交互式解释器: 打开终端或命令提示符,输入python或python3(取决于你的系统配置),即可进入Python交互模式。你可以直接输入代码并立即看到结果。
- 脚本文件执行: 将Python代码保存到一个.py扩展名的文件中,例如hello.py。然后在终端或命令行中,通过python hello.py或python3 hello.py命令来运行这个脚本。
- 集成开发环境(IDE): 如PyCharm、VS Code(配Python插件)、Jupyter Notebook等,这些环境提供了编辑、调试和运行Python代码的图形界面。
- 在线编程平台: Repl.it、Google Colab、JupyterHub等在线平台允许用户在网页上编写并运行Python代码,无需本地安装Python环境。
- 模块导入与作为库使用: Python代码也可以被其他Python程序作为模块导入并执行,这种方式常用于组织大型项目或开发库供他人使用。
- 嵌入式Python: Python可以嵌入到其他应用程序中,允许在非Python环境中执行Python代码,如C/C++程序通过Python API调用Python函数。
每种方式有其特定的使用场景和优势,可根据需求选择合适的运行方式。
1.2 注释
- 注释的作用:
- 对关键代码的解释说明;
- 被注释的代码不会被执行;
- 增强代码的可读性;
- 注释的分类:
- 单行注释:以
#号开头,右边的所有东西都被当做说明文字,程序不进行编译运行。
# 输出
# print("he1lo wor1d") # 注释
单独一行的注释,# 后面建议先添加一个空格,然后再编写相应的说明文字;
代码后面增加的单行注释,注释应该至少离开代码 2 个空格;
- 多行注释三个单引号’‘’ ‘’’ 或三个双引号 “”" “”"
'''
这是第一行
这是第二行
'''
"""
这是第三行
这是第四行
"""
- 注释不能乱用
如果外面使用三个单引号,则里面要使用三个双引号,反之亦然。即,在嵌套使用注释的时候,两种多行注释形式交替使用。
- 注释的排错性
先注释一部分代码,然后执行另外一部分,看看是否报错,逐层缩小报错范围,找到最终错误点。
关于代码规范
Python官方提供有一系列 PEP(Python Enhancement Proposals) 文档- 其中第 8 篇文档专门针对 Python 的代码格式 给出了建议,也就是俗称的 PEP 8
- 文档地址:https://www.python.org/dev/peps/pep-0008/
- 谷歌有对应的中文文档:http://zh-google-styleguide.readthedocs.io/en/latest/google-python-styleguide/python_style_rules/
1.3 缩进规则
Python的缩进规则是Python语法中非常重要且独特的部分,它用来表示代码块的层次结构。Python中没有使用大括号 {} 来界定代码块,而是依靠缩进来区分代码块的开始和结束。
Python缩进规则的需要注意;
- 一致性:同一个代码块内的所有语句必须使用相同数量的空格或制表符进行缩进。推荐使用4个空格作为标准缩进量,虽然也可以使用制表符,但混合使用空格和制表符会导致错误。
- 严格性:Python解释器会严格检查代码块的缩进,不正确的缩进会导致IndentationError错误。
- 代码块定义:如if语句、for循环、while循环、def函数定义、class类定义等结构后面的第一行语句必须缩进,表示它们属于该代码块。
- 连续语句:同一代码块内连续的多行代码必须保持相同的缩进级别。
- 嵌套结构:如果一个代码块内部还有其他代码块(即嵌套结构),则内部代码块需要比外部代码块更进一步的缩进。
- 反向缩进结束代码块:当回到与上一层代码块相同的缩进级别时,表示当前代码块结束。对于像if语句这样可能只有单行执行语句的情况,即使只有一行,也需要正确缩进。
2. 变量
变量就是可以变化的量,量指的是事物的状态,比如人的年龄、性别,游戏角色的等级、金钱等等
为了让计算机能够像人一样去记忆事物的某种状态,并且状态是可以发生变化的。
详细地说:程序执行的本质就是一系列状态的变化,变是程序执行的直接体现,所以我们需要有一种机制能够反映或者说是保存下来程序执行时的状态。
2.1 变量的基本使用
变量使用的原则:先定义,后引用
name = 'zhangsan' # 定义 -> 存(开辟一个内存空间,绑定变量名)
print(name) # 引用 -> 取(通过变量名访问变量值)
补充知识:(了解即可)
内存管理:垃圾回收机制
- 垃圾回收机制(简称GC)是Python解释器自带一种机制,专门用来回收不可用的变量值所占用的内存空间。
- 当一个变量值被绑定的变量名的个数为0时,该变量值无法被访问到,称之为垃圾。
- 原理:Python的GC模块主要运用了“
引用计数”(reference counting)来跟踪和回收垃圾。在引用计数的基础上,还可以通过“标记-清除”(mark and sweep)解决容器对象可能产生的循环引用的问题,并且通过“分代回收”(generation collection)以空间换取时间的方式来进一步提高垃圾回收的效率。
引用计数
引用计数:变量值被变量名关联的次数
# 垃圾:当一个变量值被绑定的变量名的个数为0时,该变量值无法被访问到,称之为 垃圾 # 引用计数增加 x = 10 # 10的引用计数为1 y = x # 10的引用计数为2 z = x # 10的引用计数为3 # 引用计数减少 del x # 解除变量名x与值10的绑定关系,10的引用计数变为2 print(y) # 10 不受影响 del y #10的引用计数变为1 print(z) # 10 不受影响 z = 12345 print(z) # 12345 此时 10 已经没有变量名进行引用,引用计数为0循环引用
# 循环引用(交叉引用)=> 导致内存泄露问题 # 循环引用会导致:值不再被任何名字关联,但是值的引用计数并不会为0,应该被回收但不能被回收 l1=[111,] l2=[222,] l1.append(l2) # 此时l1存放的是[值111的内存地址,l2列表的内存地址] l2.append(l1) # 此时l2存放的是[值222的内存地址,l1列表的内存地址] # print(id(l1[1])) # print(id(l2)) # print(id(l2[1])) # print(id(l1)) # print(l2) # print(l1[1]) del l1 # 列表1的引用计数减1,列表1的引用计数变为1(还有一个间接引用) del l2 # 列表2的引用计数减1,列表2的引用计数变为1(还有一个间接引用) # 此时两个列表会出现永远取不到,但是引用计数不为0的情况标记清除
# 标记清除:用来解决循环引用带来的内存泄露问题 # 内存中有两块区域:堆区与栈区,在定义变量时,变量名与值内存地址的关联关系存放于栈区,变量值存放于堆区,内存管理回收的则是堆区的内容。
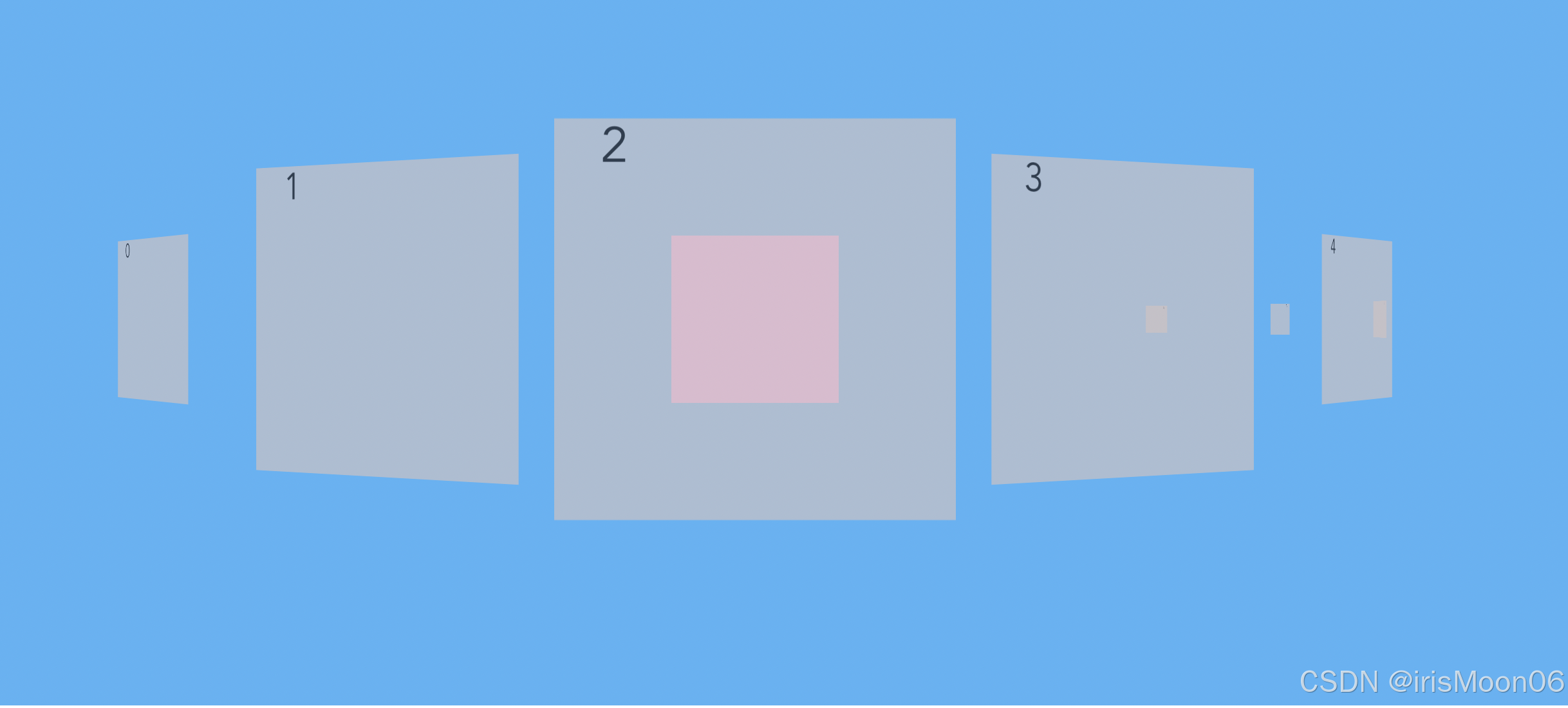
标记/清除算法的做法是当应用程序可用的内存空间被耗尽的时,就会停止整个程序,然后进行两项工作,第一项则是标记,第二项则是清除。 1. 标记。通俗地讲就是:标记的过程就行相当于从栈区出发一条线,“连接”到堆区,再由堆区间接“连接”到其他地址,凡是被这条自栈区起始的线连接到内存空间都属于可以访达的,会被标记为存活 具体地:标记的过程其实就是,遍历所有的GC Roots对象(栈区中的所有内容或者线程都可以作为GC Roots对象),然后将所有GC Roots的对象可以直接或间接访问到的对象标记为存活的对象,其余的均为非存活对象,应该被清除。 2. 清除。清除的过程将遍历堆中所有的对象,将没有标记存活的对象全部清除掉。 直接引用指的是从栈区出发直接引用到的内存地址,间接引用指的是从栈区出发引用到堆区后再进一步引用到的内存地址,以我们之前的两个列表l1与l2为例画出如下图像:
当我们同时删除l1与l2时,会清理到栈区中l1与l2的内容 这样在启用标记清除算法时,发现栈区内不再有l1与l2(只剩下堆区内二者的相互引用),于是列表1与列表2都没有被标记为存活,二者会被清理掉,这样就解决了循环引用带来的内存泄漏问题。
分代回收# 基于引用计数的回收机制,每次回收内存,都需要把所有对象的引用计数都遍历一遍,这是非常消耗时间的,于是引入了 分代回收 来提高回收效率,分代回收采用的是用“空间换时间”的策略。 # 分代回收的核心思想: 在历经多次扫描的情况下,都没有被回收的变量,gc机制就会认为,该变量是常用变量,gc对其扫描的频率会降低,具体实现原理如下: 1. 分代指的是根据存活时间来为变量划分不同等级(也就是不同的代) 2. 新定义的变量,放到新生代这个等级中,假设每隔1分钟扫描新生代一次,如果发现变量依然被引用,那么该对象的权重(权重本质就是个整数)加一,当变量的权重大于某个设定得值(假设为3),会将它移动到更高一级的青春代,青春代的gc扫描的频率低于新生代(扫描时间间隔更长),假设5分钟扫描青春代一次,这样每次gc需要扫描的变量的总个数就变少了,节省了扫描的总时间,接下来,青春代中的对象,也会以同样的方式被移动到老年代中。也就是等级(代)越高,被垃圾回收机制扫描的频率越低 3. 回收依然是使用引用计数作为回收的依据
# 分代回收的缺点: 例如一个变量刚刚从新生代移入青春代,该变量的绑定关系就解除了,该变量应该被回收,但青春代的扫描频率低于新生代,所以该变量的回收就会被延迟。




2.2 变量的三大组成部分
变量的定义由变量名、等号、变量值三部分组成。
变量名 = 变量值
# 变量名 相当于门牌号,指向值所在的内存地址,是访问至值的唯—方式。
# =号 为赋值符号,用来将变量值的内存地址绑定给变量名。
# 变量值 就是我们存储的数据,反映的是事物的伏态。
# 例如:
name = "jason" #记下人的名字为"Jason"
sex ='男' #记下人的性别为男牲
age = 18 #记下人的年龄为18岁
salary = 30080.1 #记下人的薪资为30000.1元
解释器执行到变量定义的代码时会申请内存空间存放变量值,然后将变量值的内存地址绑定给变量名.
2.3 变量名的命名的规则
变量名的命名原则:见名知意
-
变量名只能是
字母、数字或下划线的任意组合 -
变量名的第一个字符不能是数字
-
关键字不能声明为变量名,常用关键字如下:
import keyword; # 引入模块
print(keyword.kwlist); # 打印关键字
['and', 'as', 'assert', 'break', 'class', 'continue', 'def', 'del', 'elif', 'else', 'except', 'exec', 'finally', 'for', 'from','global', 'if', 'import', 'in', 'is', 'lambda', 'not', 'or', 'pass', 'print', 'raise', 'return', 'try', 'while', 'with', 'yield']
PS:不要用拼音,不要用中文,在见名知意的前提下尽可能短(规范)。
变量名的命名风格:
纯小写加下划线的方式(在python中,关于变量名的命名 推荐 使用这种方式)
age_of_alex = 73 print(age_of_alex)大驼峰法(首字母大写)
AgeOfAlex = 73 print(AgeOfAlex)
2.4 变量值三个重要的特征
-
id:反映的是变量值的内存地址,内存地址不同id则不同 -
type:不同类型的值用来表示记录不同的状态 -
value:值本身
name = 'zhangsan'
print(id(name)) # id = 2429388598384
print(type(name)) # <class 'str'>
print(name) # zhangsan
补充:
is 与 == 的区别
is:比较左右两个值身份id是否相等==:比较左右两个值他们的值value是否相等id不同的情况下,值有可能相同,即两块不同的内存空间里可以存相同的值
id相同的情况下,值一定相同,x is y成立,x == y也必然成立
x='info:18' y='info:18' print(x,y) info:18 info:18 # value相同 print(id(x),id(y)) 4565819264 4566192176 # id不同 print(x == y) # True print(x is y) # False内存优化机制:小整数池[-5,256]
- 从python解释器启动那一刻开始,就会在内存中事先申请好一系列内存空间存放好常用的整数。
- 其取值范围在
[-5,256]之间。x=-5 y=-5 print(x is y) # True x=-6 y=-6 print(x is y) # False
2.5 常量:不变的量
注意:python语法中没有常量的概念,但是在程序的开发过程中会涉及到常量的概念。
小写字母全为大写代表常量,这只是一种约定、规范。
AGE_OF_ALEX = 73
AGE_OF_ALEX = 74
单从语法层面去讲,常量的使用与变量完全一致。