目录
前言
1.实现效果
2.非端到端实现的原因
3.分类网络与数据准备
4.训练结果
5.测试结果
6.训练代码
7.训练日志
7.1ResNet18训练日志
7.2ShuffleNet_v2训练日志
前言
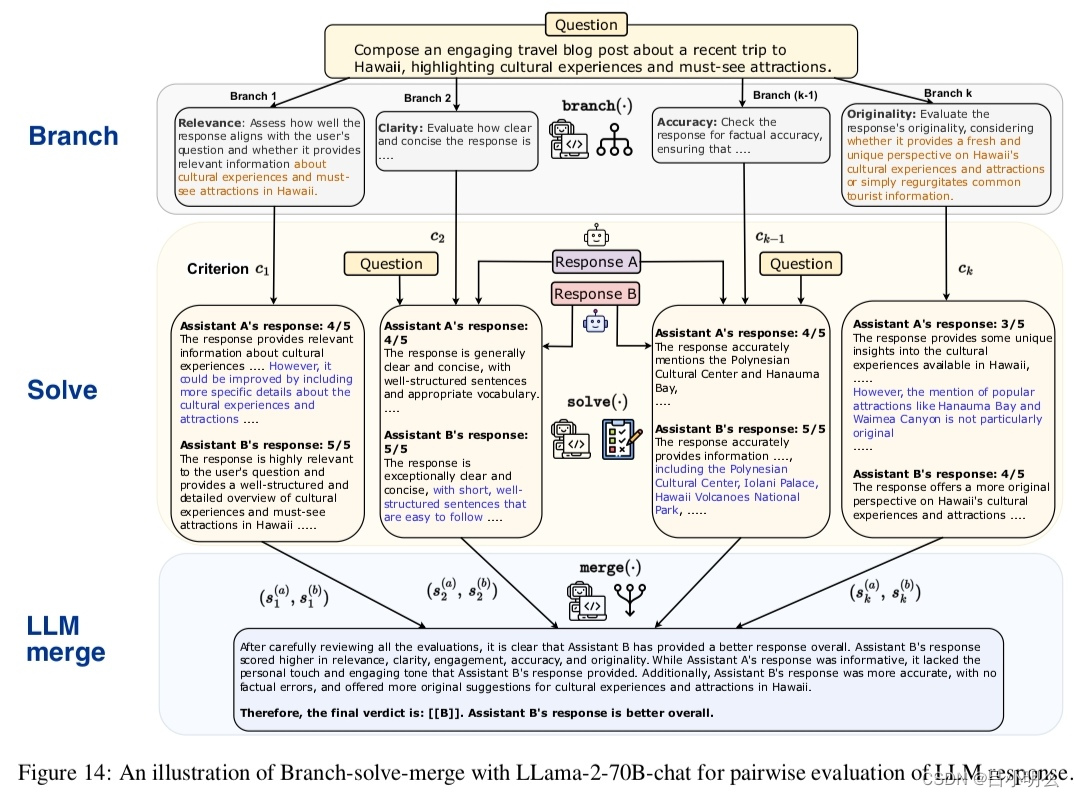
利用YOLOv8获取手部区域,然后对手部区域进行分类,实现手势识别。
本文使用检测+分类,对于一类手势只需200张训练图片,即可达到99%的准确率。
在下一篇基于关键点+关键点分类,无需训练图片,即可实现对任意手势的识别,且达到99%的准确率。
手部检测数据集准备:基于YOLOv8的手部检测(1)- 手部数据集获取(数据集下载、数据清洗、处理与增强)
手部检测模型训练与调优:
基于YOLOv8的手部检测(2)- 模型训练、结果分析和超参数优化
1.实现效果
hand使用yolov8-m检测得到,resnt表示ResNet18的分类结果,shfnt表示用shufflenet_v2的分类结果,conf是置信度。

2.非端到端实现的原因
手可以灵活地做出各种动作,导致手势含有模棱两可的语义。使用端到端的检测,会依赖大量的训练数据(标定大量的标准的动作)。
用于手部检测分类的动作参考:
基于YOLOv8的手部检测(1)- 手部数据集获取(数据集下载、数据清洗、处理与增强)
总共分为以下18个类(外加1个无效类no_gesture):

考虑以下动作:

该动作在HaGRID中的标签为:no_gesture。而在观察上,该动作“类似”于将“paml”或者“stop inv”旋转了一定角度。
一方面,如果存在模棱两可的动作,使用端到端检测时,假设“paml”获得0.35的置信度,“stop inv”获得0.25的置信度,“no_gesture”获得0.3的置信度。这样会导致max(conf)=0.35,经过nms或者置信度阈值筛选后,导致手部都被无法检测。
另一方面,就是数据问题,每遇到一个新的手势,端到端网络就还需要重新训练(还需要考虑数据不平衡、各种参数微调等一系列问题)。
因此,为我们可以训练一个高精度的手部检测模型,再将手势识别作为下游任务,训练一个简单模型去解决。
本质上,这里还是使用RCNN的思想,用大量的手部数据(容易获得的)训练yolov8,获取高精度手部检测模型。再针对下游任务(手势识别、动作识别等)设计轻量化网络,仅需少量数据(难以获得的),即可进行调优。
3.分类网络与数据准备
选用ResNet18()和shuffle_net_v2。数据集从HaGRID中随机选取,然后读取标签获取标签内的patch:
test每类选200张作为训练集,共200×18=3,600张;
val每类选200张作为验证集,共200×18=3,600张;
train每类选200张作为测试集,共500×18=9,000张。如下图所示,


还有一类no_gesture类作废(缺乏背景语义下,部分手势和其他类别太像):
4.训练结果
两个网络均使用pytorch官方的预训练模型进行微调,初始学习率设置为0.001,每轮衰减5%,总共训练10轮。
因为只训练了10轮,ResNet18在测试集上还没有ShuffleNet_v2高,但实测ResNet18效果更好。
ResNet18训练结果如下:
accuracy macro avg weighted avg call dislike fist four like mute ok one palm peace peace_inverted rock stop stop_inverted three three2 two_up two_up_inverted
support 9000 9000 9000 500 500 500 500 500 500 500 500 500 500 500 500 500 500 500 500 500 500
precision 0.98 0.98 0.98 0.97 1.00 0.99 0.99 0.99 0.99 0.99 0.98 0.99 0.96 0.98 0.99 0.96 1.00 0.98 0.98 0.99 1.00
recall 0.98 0.98 0.98 1.00 0.99 1.00 0.99 0.97 0.99 0.99 0.97 0.96 0.96 0.99 0.99 0.99 1.00 0.97 0.98 0.99 0.99
f1-score 0.98 0.98 0.98 0.99 1.00 0.99 0.99 0.98 0.99 0.99 0.98 0.97 0.96 0.99 0.99 0.97 1.00 0.98 0.98 0.99 0.99
ShuffleNet_v2训练结果如下:
accuracy macro avg weighted avg call dislike fist four like mute ok one palm peace peace_inverted rock stop stop_inverted three three2 two_up two_up_inverted
support 9000 9000 9000 500 500 500 500 500 500 500 500 500 500 500 500 500 500 500 500 500 500
precision 0.99 0.99 0.99 0.98 1.00 0.99 0.99 1.00 0.99 0.99 0.99 0.98 0.98 0.97 0.98 0.98 1.00 0.99 0.98 1.00 0.99
recall 0.99 0.99 0.99 1.00 1.00 1.00 0.99 0.99 0.99 0.98 0.97 0.98 0.96 1.00 1.00 0.98 1.00 0.99 0.97 0.99 1.00
f1-score 0.99 0.99 0.99 0.99 1.00 1.00 0.99 0.99 0.99 0.99 0.98 0.98 0.97 0.98 0.99 0.98 1.00 0.99 0.98 0.99 1.00
5.测试结果
如果动作比较“标注”还是很准的,但是存在视角、遮挡问题时候,准确率就低很多了。尤其视角问题,不加入深度估计,仅用2D识别,限制了准确率的上限。

6.训练代码
训练用的代码如下,只需指定数据集地址和选用的模型:
import os
import torch
import torch.nn as nn
import torch.optim as optim
from torchvision import datasets, transforms, models
from torchvision.models import ResNet18_Weights
from torchvision.models import shufflenet_v2_x1_0, ShuffleNet_V2_X1_0_Weights
from torch.utils.data import DataLoader
from tqdm import tqdm
from sklearn.metrics import classification_report, accuracy_score, recall_score
import logging
import time
import datetime
# 训练和验证函数
def train_model(model, criterion, optimizer, scheduler, num_epochs=10):
best_model_wts = model.state_dict()
best_acc = 0.0
for epoch in range(num_epochs):
print(f'Epoch {epoch + 1}/{num_epochs}')
logger.info(f'Epoch {epoch + 1}/{num_epochs}')
print('-' * 50)
logger.info('-' * 50)
# 每个epoch都有训练和验证阶段
for phase in ["train", "val"]:
if phase == "train":
model.train() # 设置模型为训练模式
else:
model.eval() # 设置模型为评估模式
running_loss = 0.0
running_corrects = 0
all_labels = []
all_preds = []
# 遍历数据
for inputs, labels in tqdm(dataloaders[phase]):
inputs = inputs.to(device)
labels = labels.to(device)
# 清零梯度
optimizer.zero_grad()
# 前向传播
with torch.set_grad_enabled(phase == "train"):
outputs = model(inputs)
_, preds = torch.max(outputs, 1)
loss = criterion(outputs, labels)
# 仅在训练阶段进行反向传播和优化
if phase == "train":
loss.backward()
optimizer.step()
# 统计
running_loss += loss.item() * inputs.size(0)
running_corrects += torch.sum(preds == labels.data)
all_labels.extend(labels.cpu().numpy())
all_preds.extend(preds.cpu().numpy())
epoch_loss = running_loss / dataset_sizes[phase]
epoch_acc = running_corrects.double() / dataset_sizes[phase]
epoch_recall = recall_score(all_labels, all_preds, average='macro')
print(f'{phase} Loss: {epoch_loss:.4f} Acc: {epoch_acc:.4f} Recall: {epoch_recall:.4f}')
logger.info(f'{phase} Loss: {epoch_loss:.4f} Acc: {epoch_acc:.4f} Recall: {epoch_recall:.4f}')
# 深度复制模型
if phase == "val" and epoch_acc > best_acc:
best_acc = epoch_acc
best_model_wts = model.state_dict()
# 保存当前最好的模型
torch.save(best_model_wts, f"best_model_{model_choose}.pth")
print(f"模型在第 {epoch + 1} 轮取得最好表现,已保存。")
logger.info(f"模型在第 {epoch + 1} 轮取得最好表现,已保存。")
# 学习率衰减
scheduler.step()
time.sleep(0.2)
print(f'Best val Acc: {best_acc:.4f}')
logger.info(f'Best val Acc: {best_acc:.4f}')
logger.info(f"最佳模型已保存为: best_model_{model_choose}.pth")
return model
# 测试模型
def test_model(model):
model.eval()
running_corrects = 0
all_labels = []
all_preds = []
with torch.no_grad():
for inputs, labels in tqdm(dataloaders["test"]):
inputs = inputs.to(device)
labels = labels.to(device)
outputs = model(inputs)
_, preds = torch.max(outputs, 1)
running_corrects += torch.sum(preds == labels.data)
all_labels.extend(labels.cpu().numpy())
all_preds.extend(preds.cpu().numpy())
test_acc = accuracy_score(all_labels, all_preds)
test_recall = recall_score(all_labels, all_preds, average='macro')
print(f'Test Acc: {test_acc:.4f} Recall: {test_recall:.4f}')
logger.info(f'Test Acc: {test_acc:.4f} Recall: {test_recall:.4f}')
print("Per-class accuracy:")
logger.info("Per-class accuracy:")
report = classification_report(all_labels, all_preds, target_names=class_names)
print(report)
logger.info(report)
if __name__ == "__main__":
# 设置自定义参数
model_choose = "resnet18" # "shuffle_net_v2"
assert model_choose in ["resnet18", "shuffle_net_v2"], "输入模型名称为:resnet18 或者 shuffle_net_v2"
# 设置日志文件路径和配置
timestamp = datetime.datetime.now().strftime('%Y-%m-%d_%H-%M-%S')
log_filename = f"train_{timestamp}_{model_choose}.log"
logging.basicConfig(filename=log_filename, level=logging.INFO, format='%(asctime)s - %(message)s')
logger = logging.getLogger()
# 指定数据路径和类别标签
data_dir = {
"train": "F:/datasets/hagrid/yolo_cls/test", # 测试集和验证集每个类都是200张
"val": "F:/datasets/hagrid/yolo_cls/val",
"test": "F:/datasets/hagrid/yolo_cls/train" # 训练集数量多作为测试集
}
# 指定类别标签
hagrid_cate_file = ["call", "dislike", "fist", "four", "like", "mute", "ok", "one", "palm", "peace",
"peace_inverted",
"rock", "stop", "stop_inverted", "three", "three2", "two_up", "two_up_inverted"]
hagrid_cate_dict = {hagrid_cate_file[i]: i for i in range(len(hagrid_cate_file))}
print(hagrid_cate_dict)
logger.info(f"类别字典: {hagrid_cate_dict}")
# 超参数设置
batch_size = 32
num_epochs = 10
learning_rate = 0.001
# 数据预处理和增强
data_transforms = {
"train": transforms.Compose([
transforms.Resize((224, 224)),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])
]),
"val": transforms.Compose([
transforms.Resize((224, 224)),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])
]),
"test": transforms.Compose([
transforms.Resize((224, 224)),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])
]),
}
# 数据集加载
image_datasets = {x: datasets.ImageFolder(os.path.join(data_dir[x]), data_transforms[x]) for x in
["train", "val", "test"]}
dataloaders = {x: DataLoader(image_datasets[x], batch_size=batch_size, shuffle=True, num_workers=0) for x in
["train", "val", "test"]}
dataset_sizes = {x: len(image_datasets[x]) for x in ["train", "val", "test"]}
class_names = image_datasets["train"].classes
# 检查类别数是否正确
assert len(class_names) == len(
hagrid_cate_file), f"类别数[{len(class_names)}]不匹配文件夹数[{len(hagrid_cate_file)}],请检查数据集文件夹是否正确。"
# 检查是否有GPU
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
# 使用选择的模型
if model_choose == "resnet18":
model = models.resnet18(weights=ResNet18_Weights.IMAGENET1K_V1)
else:
model = shufflenet_v2_x1_0(weights=ShuffleNet_V2_X1_0_Weights.IMAGENET1K_V1)
# 修改全连接层以适应新任务的类别数
num_ftrs = model.fc.in_features
model.fc = nn.Linear(num_ftrs, len(hagrid_cate_file))
# 将模型移动到GPU(如果有的话)
model = model.to(device)
# 定义损失函数和优化器
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=learning_rate)
# 定义学习率调度器,每个 epoch 衰减 5%
scheduler = optim.lr_scheduler.StepLR(optimizer, step_size=1, gamma=0.95)
# 训练模型
model = train_model(model, criterion, optimizer, scheduler, num_epochs=num_epochs)
# 测试模型
test_model(model)
7.训练日志
7.1ResNet18训练日志
2024-08-17 11:21:23,641 - 类别字典: {'call': 0, 'dislike': 1, 'fist': 2, 'four': 3, 'like': 4, 'mute': 5, 'ok': 6, 'one': 7, 'palm': 8, 'peace': 9, 'peace_inverted': 10, 'rock': 11, 'stop': 12, 'stop_inverted': 13, 'three': 14, 'three2': 15, 'two_up': 16, 'two_up_inverted': 17}
2024-08-17 11:21:23,889 - Epoch 1/10
2024-08-17 11:21:23,890 - --------------------------------------------------
2024-08-17 11:21:40,028 - train Loss: 0.5494 Acc: 0.8342 Recall: 0.8342
2024-08-17 11:21:47,005 - val Loss: 0.2359 Acc: 0.9264 Recall: 0.9264
2024-08-17 11:21:48,996 - 模型在第 1 轮取得最好表现,已保存。
2024-08-17 11:21:49,204 - Epoch 2/10
2024-08-17 11:21:49,204 - --------------------------------------------------
2024-08-17 11:22:02,927 - train Loss: 0.1531 Acc: 0.9553 Recall: 0.9553
2024-08-17 11:22:10,354 - val Loss: 0.1603 Acc: 0.9503 Recall: 0.9503
2024-08-17 11:22:12,926 - 模型在第 2 轮取得最好表现,已保存。
2024-08-17 11:22:13,131 - Epoch 3/10
2024-08-17 11:22:13,131 - --------------------------------------------------
2024-08-17 11:22:27,164 - train Loss: 0.0930 Acc: 0.9733 Recall: 0.9733
2024-08-17 11:22:34,581 - val Loss: 0.1362 Acc: 0.9564 Recall: 0.9564
2024-08-17 11:22:36,373 - 模型在第 3 轮取得最好表现,已保存。
2024-08-17 11:22:36,577 - Epoch 4/10
2024-08-17 11:22:36,577 - --------------------------------------------------
2024-08-17 11:22:50,791 - train Loss: 0.0715 Acc: 0.9814 Recall: 0.9814
2024-08-17 11:22:57,828 - val Loss: 0.2039 Acc: 0.9286 Recall: 0.9286
2024-08-17 11:22:58,034 - Epoch 5/10
2024-08-17 11:22:58,034 - --------------------------------------------------
2024-08-17 11:23:12,574 - train Loss: 0.0669 Acc: 0.9808 Recall: 0.9808
2024-08-17 11:23:19,866 - val Loss: 0.0915 Acc: 0.9717 Recall: 0.9717
2024-08-17 11:23:21,782 - 模型在第 5 轮取得最好表现,已保存。
2024-08-17 11:23:21,991 - Epoch 6/10
2024-08-17 11:23:21,991 - --------------------------------------------------
2024-08-17 11:23:36,421 - train Loss: 0.0390 Acc: 0.9883 Recall: 0.9883
2024-08-17 11:23:43,620 - val Loss: 0.0788 Acc: 0.9731 Recall: 0.9731
2024-08-17 11:23:45,665 - 模型在第 6 轮取得最好表现,已保存。
2024-08-17 11:23:45,880 - Epoch 7/10
2024-08-17 11:23:45,880 - --------------------------------------------------
2024-08-17 11:24:00,492 - train Loss: 0.0200 Acc: 0.9936 Recall: 0.9936
2024-08-17 11:24:07,786 - val Loss: 0.0890 Acc: 0.9731 Recall: 0.9731
2024-08-17 11:24:07,995 - Epoch 8/10
2024-08-17 11:24:07,995 - --------------------------------------------------
2024-08-17 11:24:22,876 - train Loss: 0.0191 Acc: 0.9944 Recall: 0.9944
2024-08-17 11:24:30,326 - val Loss: 0.0578 Acc: 0.9808 Recall: 0.9808
2024-08-17 11:24:32,870 - 模型在第 8 轮取得最好表现,已保存。
2024-08-17 11:24:33,082 - Epoch 9/10
2024-08-17 11:24:33,082 - --------------------------------------------------
2024-08-17 11:24:47,532 - train Loss: 0.0102 Acc: 0.9983 Recall: 0.9983
2024-08-17 11:24:54,677 - val Loss: 0.0308 Acc: 0.9894 Recall: 0.9894
2024-08-17 11:24:56,289 - 模型在第 9 轮取得最好表现,已保存。
2024-08-17 11:24:56,505 - Epoch 10/10
2024-08-17 11:24:56,505 - --------------------------------------------------
2024-08-17 11:25:11,238 - train Loss: 0.0059 Acc: 0.9983 Recall: 0.9983
2024-08-17 11:25:18,503 - val Loss: 0.0405 Acc: 0.9878 Recall: 0.9878
2024-08-17 11:25:18,712 - Best val Acc: 0.9894
2024-08-17 11:25:18,712 - 最佳模型已保存为: best_model_resnet18.pth
2024-08-17 11:25:37,443 - Test Acc: 0.9849 Recall: 0.9849
2024-08-17 11:25:37,443 - Per-class accuracy:
2024-08-17 11:25:37,461 - precision recall f1-score support
call 0.97 1.00 0.99 500
dislike 1.00 0.99 1.00 500
fist 0.99 1.00 0.99 500
four 0.99 0.99 0.99 500
like 0.99 0.97 0.98 500
mute 0.99 0.99 0.99 500
ok 0.99 0.99 0.99 500
one 0.98 0.97 0.98 500
palm 0.99 0.96 0.97 500
peace 0.96 0.96 0.96 500
peace_inverted 0.98 0.99 0.99 500
rock 0.99 0.99 0.99 500
stop 0.96 0.99 0.97 500
stop_inverted 1.00 1.00 1.00 500
three 0.98 0.97 0.98 500
three2 0.98 0.98 0.98 500
two_up 0.99 0.99 0.99 500
two_up_inverted 1.00 0.99 0.99 500
accuracy 0.98 9000
macro avg 0.98 0.98 0.98 9000
weighted avg 0.98 0.98 0.98 9000
7.2ShuffleNet_v2训练日志
2024-08-17 11:17:30,440 - 类别字典: {'call': 0, 'dislike': 1, 'fist': 2, 'four': 3, 'like': 4, 'mute': 5, 'ok': 6, 'one': 7, 'palm': 8, 'peace': 9, 'peace_inverted': 10, 'rock': 11, 'stop': 12, 'stop_inverted': 13, 'three': 14, 'three2': 15, 'two_up': 16, 'two_up_inverted': 17}
2024-08-17 11:17:30,621 - Epoch 1/10
2024-08-17 11:17:30,621 - --------------------------------------------------
2024-08-17 11:17:43,236 - train Loss: 1.5118 Acc: 0.6367 Recall: 0.6367
2024-08-17 11:17:49,254 - val Loss: 0.3228 Acc: 0.9358 Recall: 0.9358
2024-08-17 11:17:49,451 - 模型在第 1 轮取得最好表现,已保存。
2024-08-17 11:17:49,656 - Epoch 2/10
2024-08-17 11:17:49,656 - --------------------------------------------------
2024-08-17 11:17:59,048 - train Loss: 0.2338 Acc: 0.9414 Recall: 0.9414
2024-08-17 11:18:05,083 - val Loss: 0.1439 Acc: 0.9594 Recall: 0.9594
2024-08-17 11:18:05,439 - 模型在第 2 轮取得最好表现,已保存。
2024-08-17 11:18:05,642 - Epoch 3/10
2024-08-17 11:18:05,642 - --------------------------------------------------
2024-08-17 11:18:15,266 - train Loss: 0.1144 Acc: 0.9706 Recall: 0.9706
2024-08-17 11:18:21,317 - val Loss: 0.1059 Acc: 0.9675 Recall: 0.9675
2024-08-17 11:18:21,512 - 模型在第 3 轮取得最好表现,已保存。
2024-08-17 11:18:21,717 - Epoch 4/10
2024-08-17 11:18:21,717 - --------------------------------------------------
2024-08-17 11:18:31,382 - train Loss: 0.0764 Acc: 0.9803 Recall: 0.9803
2024-08-17 11:18:37,578 - val Loss: 0.0775 Acc: 0.9761 Recall: 0.9761
2024-08-17 11:18:37,789 - 模型在第 4 轮取得最好表现,已保存。
2024-08-17 11:18:37,990 - Epoch 5/10
2024-08-17 11:18:37,990 - --------------------------------------------------
2024-08-17 11:18:47,682 - train Loss: 0.0589 Acc: 0.9833 Recall: 0.9833
2024-08-17 11:18:53,721 - val Loss: 0.0632 Acc: 0.9817 Recall: 0.9817
2024-08-17 11:18:53,918 - 模型在第 5 轮取得最好表现,已保存。
2024-08-17 11:18:54,125 - Epoch 6/10
2024-08-17 11:18:54,125 - --------------------------------------------------
2024-08-17 11:19:03,877 - train Loss: 0.0449 Acc: 0.9869 Recall: 0.9869
2024-08-17 11:19:10,379 - val Loss: 0.0748 Acc: 0.9775 Recall: 0.9775
2024-08-17 11:19:10,592 - Epoch 7/10
2024-08-17 11:19:10,592 - --------------------------------------------------
2024-08-17 11:19:20,337 - train Loss: 0.0188 Acc: 0.9964 Recall: 0.9964
2024-08-17 11:19:26,734 - val Loss: 0.0469 Acc: 0.9833 Recall: 0.9833
2024-08-17 11:19:27,107 - 模型在第 7 轮取得最好表现,已保存。
2024-08-17 11:19:27,320 - Epoch 8/10
2024-08-17 11:19:27,320 - --------------------------------------------------
2024-08-17 11:19:37,212 - train Loss: 0.0240 Acc: 0.9942 Recall: 0.9942
2024-08-17 11:19:43,468 - val Loss: 0.0517 Acc: 0.9853 Recall: 0.9853
2024-08-17 11:19:43,664 - 模型在第 8 轮取得最好表现,已保存。
2024-08-17 11:19:43,872 - Epoch 9/10
2024-08-17 11:19:43,872 - --------------------------------------------------
2024-08-17 11:19:53,617 - train Loss: 0.0144 Acc: 0.9953 Recall: 0.9953
2024-08-17 11:19:59,916 - val Loss: 0.0415 Acc: 0.9867 Recall: 0.9867
2024-08-17 11:20:00,167 - 模型在第 9 轮取得最好表现,已保存。
2024-08-17 11:20:00,369 - Epoch 10/10
2024-08-17 11:20:00,369 - --------------------------------------------------
2024-08-17 11:20:10,223 - train Loss: 0.0082 Acc: 0.9992 Recall: 0.9992
2024-08-17 11:20:16,711 - val Loss: 0.0369 Acc: 0.9892 Recall: 0.9892
2024-08-17 11:20:16,910 - 模型在第 10 轮取得最好表现,已保存。
2024-08-17 11:20:17,121 - Best val Acc: 0.9892
2024-08-17 11:20:17,121 - 最佳模型已保存为: best_model_shuffle_net_v2.pth
2024-08-17 11:20:36,232 - Test Acc: 0.9877 Recall: 0.9877
2024-08-17 11:20:36,232 - Per-class accuracy:
2024-08-17 11:20:36,251 - precision recall f1-score support
call 0.98 1.00 0.99 500
dislike 1.00 1.00 1.00 500
fist 0.99 1.00 1.00 500
four 0.99 0.99 0.99 500
like 1.00 0.99 0.99 500
mute 0.99 0.99 0.99 500
ok 0.99 0.98 0.99 500
one 0.99 0.97 0.98 500
palm 0.98 0.98 0.98 500
peace 0.98 0.96 0.97 500
peace_inverted 0.97 1.00 0.98 500
rock 0.98 1.00 0.99 500
stop 0.98 0.98 0.98 500
stop_inverted 1.00 1.00 1.00 500
three 0.99 0.99 0.99 500
three2 0.98 0.97 0.98 500
two_up 1.00 0.99 0.99 500
two_up_inverted 0.99 1.00 1.00 500
accuracy 0.99 9000
macro avg 0.99 0.99 0.99 9000
weighted avg 0.99 0.99 0.99 9000




![[手机Linux PostmarketOS]五, docker安装和使用](https://i-blog.csdnimg.cn/direct/bede75e4dc194a69af06f1aa8b4c0015.png)









