本篇笔记记录于 May 30th, 2023
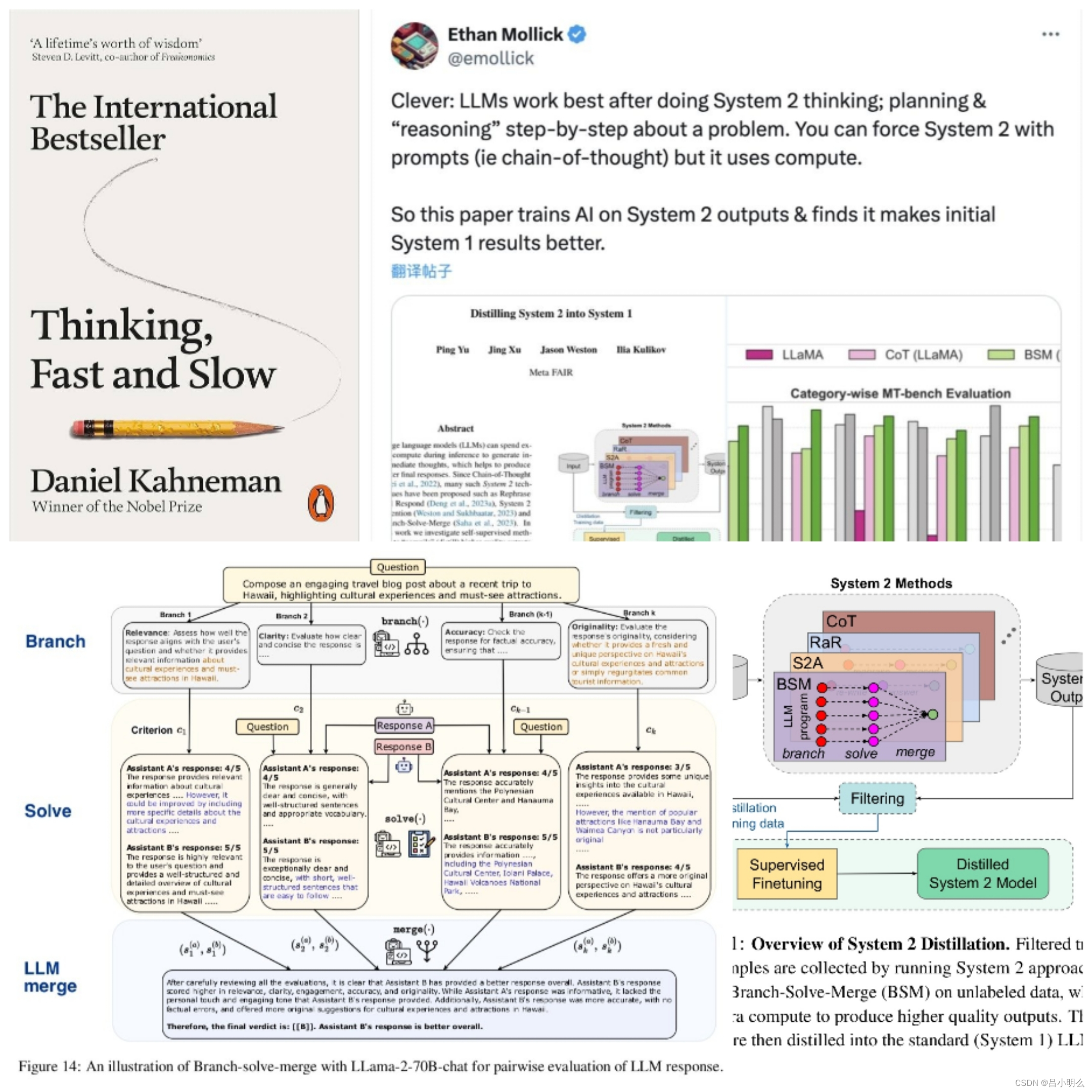
oai联合创始人Andrej曾在微软大会上的报告中有提到LLMs对于人类快、慢思考两种认知推理模式的当下探索与未来展望,这里曾经得到的启示是:未来在模型的训练与推理侧是否会出现一种新的长链认知范式?如在RLHF过程中,构建自主人类或机器标注反馈机制,从而实现模型的多步骤推理并生成思维链决策路径。
当然这两种推理模式之间在认知的内涵亦非绝对的割裂。
原因是对于自然语言本身来说其符号化的抽象序列表征是包罗万象的,其中的多步骤推理形式化表达直觉上亦可以基于这种类似语言符号化进行精细化表征并实现推理生成,其中的行动规划、推理步骤、思维过程或因果链本身对于当前自然语言表达来说也可能是一个更精细化的tokenize表征空间,除非所谓的这些“行动规划、推理步骤、思维过程或因果链不完全或不适合于采用类语言序列符号化去表征或需要其它更完备的形式化符号来进行表征。
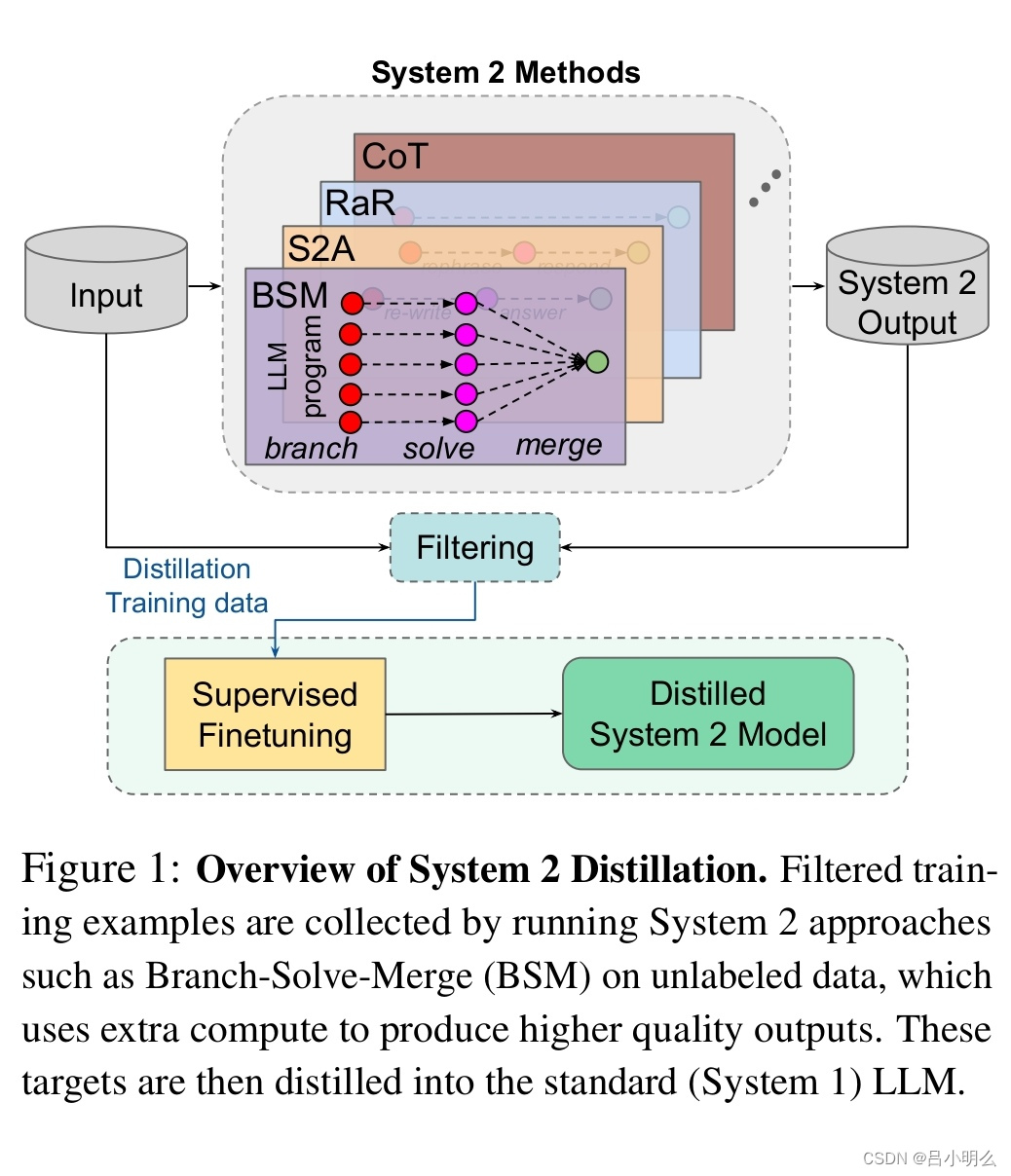
另一方面,多模态表征的增强也是一种实现路径,如融合CV像素化的表征去增强刻画真实细粒度物理世界规律并建立与概念空间中数据模态的映射。
同时,对于alphago中的MCTS模块在认知过程中的重要意义,同时考虑其在LLMs训练与推理过程中通过形式的变换加以运用的可行性也是未来非常值得深入探索的。
如:这里与chatpgt以生成内容的安全性和可用性出发为目标的align是有着一定的差异的,甚至这种差异也许要摒弃基于RM的PPO强化学习思想而寻其它,原因可能出在内容的安全性和可用性的align在整体tokenize空间中的数据分布与ToT alignment的差异。
因此,这种扩散式的生成从直觉上也许意味着能带来更多抽象的模式识别或“跨领域空间”的模式映射。即将初始问题或者任务中所囊括的状态空间分布向另一个状态空间分布迁移和匹配,如一个解代数问题运用几何方法过程进行形式化证明,如某一具体任务的执行采用多种策略进行空间采样探索。
最终的,能不能找到或构造一种能让其自动持续学习训练、推理、数据反馈的长链认知推理的范式。这就又抛出了另一个问题:systemⅡ的alignment是否与systemⅠ在本质上是一致的呢?或者说其两者在底层逻辑的数学变换上是等价的?即是否能将systemⅡ像systemⅠ一样建立起模型训练到推理的端到端(E2E)统一范式?还是说在完整的认知过程中,systemⅡ与systemⅠ在本质上存在根本的差异?
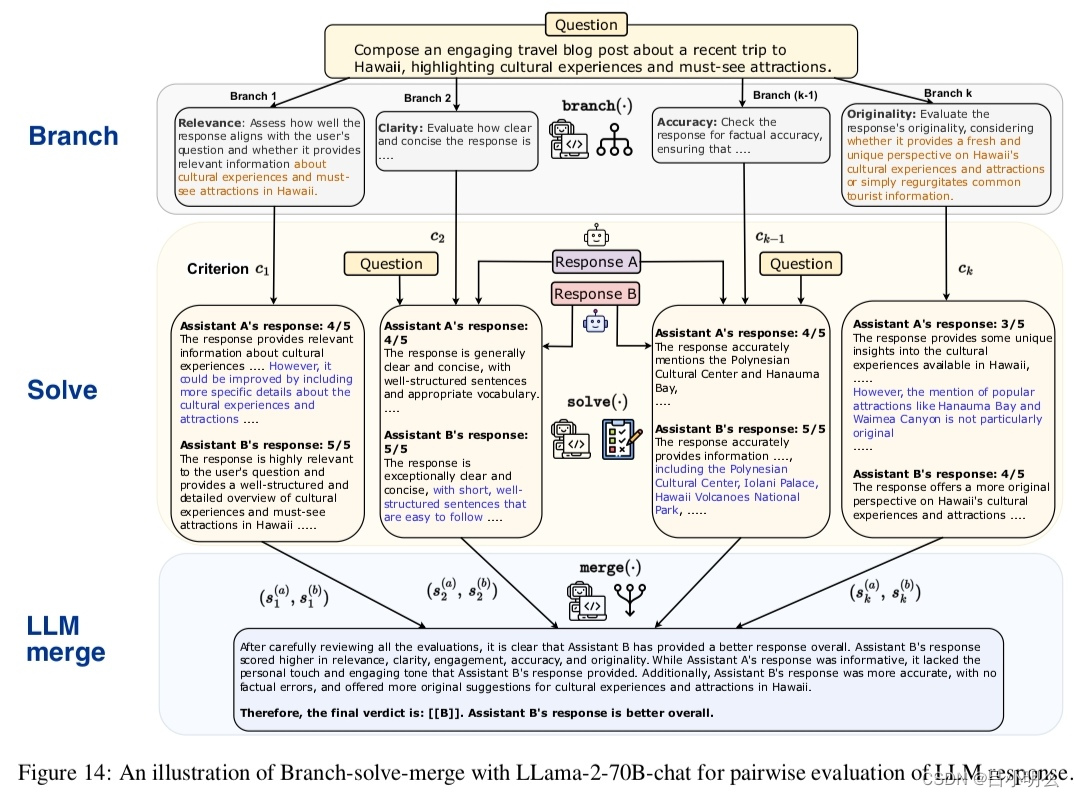




![[手机Linux PostmarketOS]五, docker安装和使用](https://i-blog.csdnimg.cn/direct/bede75e4dc194a69af06f1aa8b4c0015.png)











