文章目录
- 导入相应的库
- 正确地设置代码的基础部分
- 设置循环遍历
- 遍历URL
- 保存图片和文档
- 全部代码即详细注释
下面是通过requests库来对ajax页面进行爬取的案例,与正常页面不同,这里我们获取url的方式也会不同,这里我们通过爬取一个简单的ajax小说页面来为大家讲解。(注:结尾附赠全部代码与详细注释)
导入相应的库
爬取数据必须有相应的库,这里我们使用爬虫脚本中常用的几个Python库:os.path、fake_useragent 和 requests。
1.os.path:
- 这个模块主要用于处理文件和目录的路径。它提供了一系列的功能来进行路径的拼接、拆分、查询等操作,以确保路径的跨平台兼容性(比如Windows和Unix/Linux系统的路径分隔符不同)。
- 在爬虫中,os.path 通常用于构建本地文件系统的路径,以便保存从网络上下载的图片、文本数据等。
2.fake_useragent:
- 这个库用于生成随机的、看起来像是真实浏览器的User-Agent字符串。User-Agent是一个在HTTP请求中发送给服务器的头部信息,它告诉服务器发起请求的客户端(通常是浏览器)的类型、版本和操作系统等信息。
- 在爬虫中,由于许多网站会检查User-Agent来识别爬虫请求并阻止它们,因此使用fake_useragent可以帮助爬虫绕过这种简单的反爬虫机制。
3.requests:
- requests是Python中非常流行的HTTP库,用于发送HTTP/1.1请求。它提供了一个简单易用的API,用于处理各种HTTP请求,如GET、POST、PUT、DELETE等。
- 在爬虫中,requests库是发送网络请求并获取响应的主要工具。它支持会话(Session)对象、HTTPS请求、文件上传、Cookie处理、重定向、连接池等功能,非常适合用于构建复杂的爬虫系统。
import os.path
import fake_useragent
import requests
正确地设置代码的基础部分
这里我们生成一个随机的User-Agent、检查并创建目录以便储存爬取的图片、以及打开(或创建)一个文本文件来保存数据。
import os.path
import fake_useragent
import requests
# 判断是否是直接运行该脚本
if __name__ == '__main__':
head = {"User-Agent": fake_useragent.UserAgent().random}
if not os.path.exists("./biqugePic"):
os.mkdir("./biqugePic")
f = open("./biquge.txt", 'w', encoding='utf8')
设置循环遍历
循环遍历URL(这里为大家提供具体url的获取方法,并循环了1至9页的数据为大家做案例),并发送了带有随机User-Agent的GET请求。这是爬虫中常见的做法,用于从网站的不同页面获取数据。
for i in range(1, 10):
url = f"https://www.bqgui.cc/json?sortid=1&page={i}"
resp = requests.get(url, headers=head)
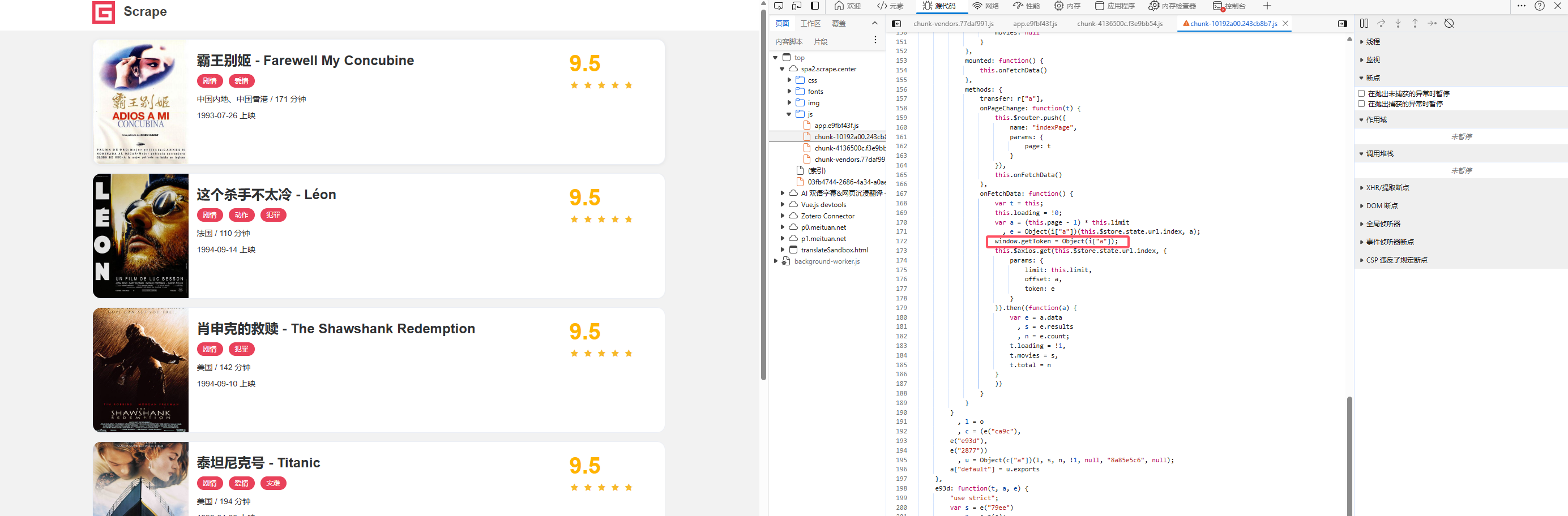
首先进入网页,点击F12打开自定义与控制工具,点击fecth/XHR,此时显示部分为空白。
这个时候我们滚动鼠标滚轮,就会出现相应的url,这里的https://www.bqgui.cc/json?sortid=1&page=2,其中尾部2表示滚轮页面第二页,想要获取1至9我们只需要进行一个简单的循环遍历即可。

遍历URL
遍历从URL获取的JSON响应,该响应包含多个项目。对于每个项目,您都提取了图片URL、文章名、作者和简介,并计划将这些信息打印到控制台以及下载图片和保存文本信息到文件。
for item in resp.json():
# 从每个JSON对象中提取所需的信息
img_url = item['url_img']
articlename = item['articlename']
author = item['author']
intro = item["intro"]
# 打印提取的信息到控制台
print(img_url, author, articlename, intro)
# 发送另一个GET请求到图片URL,以获取图片内容
img_rest = requests.get(img_url, headers=head)

保存图片和文档
设置代码来保存图片到以文章名命名的文件中,并将作者、文章名和简介信息写入到"./biquge.txt"文件中。
with open(f"./biqugePic/{articlename}.jpg", "wb") as fp:
# 将图片内容写入文件
fp.write(img_rest.content)
# 将作者、文章名和简介信息写入到"./biquge.txt"文件中
f.write(author + '#' + articlename + '#' + intro + "\n")
全部代码即详细注释
import os.path
import fake_useragent
import requests
# 判断是否是直接运行该脚本
if __name__ == '__main__':
# 创建一个包含随机User-Agent的HTTP请求头
head = {"User-Agent": fake_useragent.UserAgent().random}
# 检查是否存在名为"./biqugePic"的文件夹,如果不存在则创建它
if not os.path.exists("./biqugePic"):
os.mkdir("./biqugePic")
# 以写入模式打开(或创建)一个名为"./biquge.txt"的文件,用于保存数据
f = open("./biquge.txt", 'w', encoding='utf8')
# 循环从第1页到第9页(注意,range函数是左闭右开的,所以不包括10)
for i in range(1, 10):
# 构造请求URL,这里假设每个页面的数据都可以通过此URL以JSON格式获取
url = f"https://www.bqgui.cc/json?sortid=1&page={i}"
# 发送GET请求到URL,并带上之前创建的请求头
resp = requests.get(url, headers=head)
# 假设服务器返回的是JSON格式的数据,我们遍历这些数据
# 注意:这里有个潜在的问题,因为内部循环的变量也使用了'i',这会覆盖外层循环的'i'
# 为了避免混淆,应该使用另一个变量名,比如'item'
for item in resp.json():
# 从每个JSON对象中提取所需的信息
img_url = item['url_img']
articlename = item['articlename']
author = item['author']
intro = item["intro"]
# 打印提取的信息到控制台
print(img_url, author, articlename, intro)
# 发送另一个GET请求到图片URL,以获取图片内容
img_rest = requests.get(img_url, headers=head)
# 打开(或创建)一个文件,用于保存图片,文件名基于文章名
with open(f"./biqugePic/{articlename}.jpg", "wb") as fp:
# 将图片内容写入文件
fp.write(img_rest.content)
# 将作者、文章名和简介信息写入到"./biquge.txt"文件中
f.write(author + '#' + articlename + '#' + intro + "\n")
注意:
- 代码假设了服务器返回的JSON结构是固定的,并且每个对象都包含’url_img’, ‘articlename’, ‘author’, 和 'intro’键。
- 在实际应用中,网络请求可能会失败(如404、500等HTTP错误),应该添加错误处理逻辑。
- 由于网络延迟和带宽限制,大量请求可能会导致性能问题或被服务器封锁。
- 使用fake_useragent生成随机User-Agent可以帮助绕过一些简单的反爬虫机制,但不一定对所有网站都有效。