概述
最近在对SQLModel做一些封装,本篇文章主要记录封装过程中的一些思路和实战代码。
实现or查询
原本的代码
from typing import Optional
from sqlmodel import Field, SQLModel, create_engine, Session, select, or_
class Hero(SQLModel, table=True):
id: Optional[int] = Field(default=None, primary_key=True)
name: str
secret_name: str
age: Optional[int] = None
# 创建数据库引擎
sqlite_url = "mysql+pymysql://root:root@127.0.0.1:3306/fastzdp_sqlmodel?charset=utf8mb4"
engine = create_engine(sqlite_url, echo=True)
# 创建所有表
SQLModel.metadata.drop_all(engine)
SQLModel.metadata.create_all(engine)
# 新增
hero_1 = Hero(name="Deadpond", secret_name="Dive Wilson")
hero_2 = Hero(name="Spider-Boy", secret_name="Pedro Parqueador")
hero_3 = Hero(name="Rusty-Man", secret_name="Tommy Sharp", age=48)
hero_4 = Hero(name="Tarantula", secret_name="Natalia Roman-on", age=32)
hero_5 = Hero(name="Black Lion", secret_name="Trevor Challa", age=35)
hero_6 = Hero(name="Dr. Weird", secret_name="Steve Weird", age=36)
hero_7 = Hero(name="Captain North America", secret_name="Esteban Rogelios", age=93)
with Session(engine) as session:
session.add(hero_1)
session.add(hero_2)
session.add(hero_3)
session.add(hero_4)
session.add(hero_5)
session.add(hero_6)
session.add(hero_7)
session.commit()
# or 查询
with Session(engine) as session:
statement = select(Hero).where(or_(Hero.age <= 35, Hero.age > 90))
results = session.exec(statement)
for hero in results:
print(hero)
思考
这个代码用起来虽然已经比较简单了,但是我觉得还可以更简单,更灵活,所以想要进一步封装一个方法,能够轻松的支持or查询。
初步设计
利用反射的一些特性,我初步做了如下方法的一个封装。
def get_by_dict_or(engine, model, query_dict: dict):
"""
根据查询字典指定的键值对查询数据,键值对之间的关系是or的关系
:param engine: 引擎对象
:param model: 模型类
:param query_dict: 查询字典 {age:{gt:3,lt:33}}
"""
with Session(engine) as session:
query = select(model)
if isinstance(query_dict, dict):
for k, v in query_dict.items():
if hasattr(model, k):
if isinstance(v, dict):
# or_(Hero.age <= 35, Hero.age > 90)
mk = getattr(model, k)
conditions = []
for kk, vv in v.items():
if kk == "==":
conditions.append(mk == vv)
elif kk == ">":
conditions.append(mk > vv)
elif kk == "<":
conditions.append(mk < vv)
elif kk == ">=":
conditions.append(mk >= vv)
elif kk == "<=":
conditions.append(mk <= vv)
query = query.where(or_(*conditions))
results = session.exec(query)
return results.all()
初步测试
这个方法能不能行呢?
先写个简单的测试代码测一下。
from typing import Optional
from sqlmodel import Field, SQLModel
import fastzdp_sqlmodel as fsqlmodel
class User(SQLModel, table=True):
id: Optional[int] = Field(default=None, primary_key=True)
name: str
age: Optional[int] = None
# 创建数据库引擎
engine = fsqlmodel.get_engine(database="fastzdp_sqlmodel")
# 初始化表格
fsqlmodel.init_table(engine)
# 创建数据
u = User(name="张三", age=23)
fsqlmodel.add(engine, u)
u = User(name="张三", age=33)
fsqlmodel.add(engine, u)
u = User(name="李四", age=24)
fsqlmodel.add(engine, u)
# 查询年龄等于23或者小于10的用户
query = {"age": {">": 23, "<": 10}}
users = fsqlmodel.get_by_dict_or(engine, User, query)
print(users)
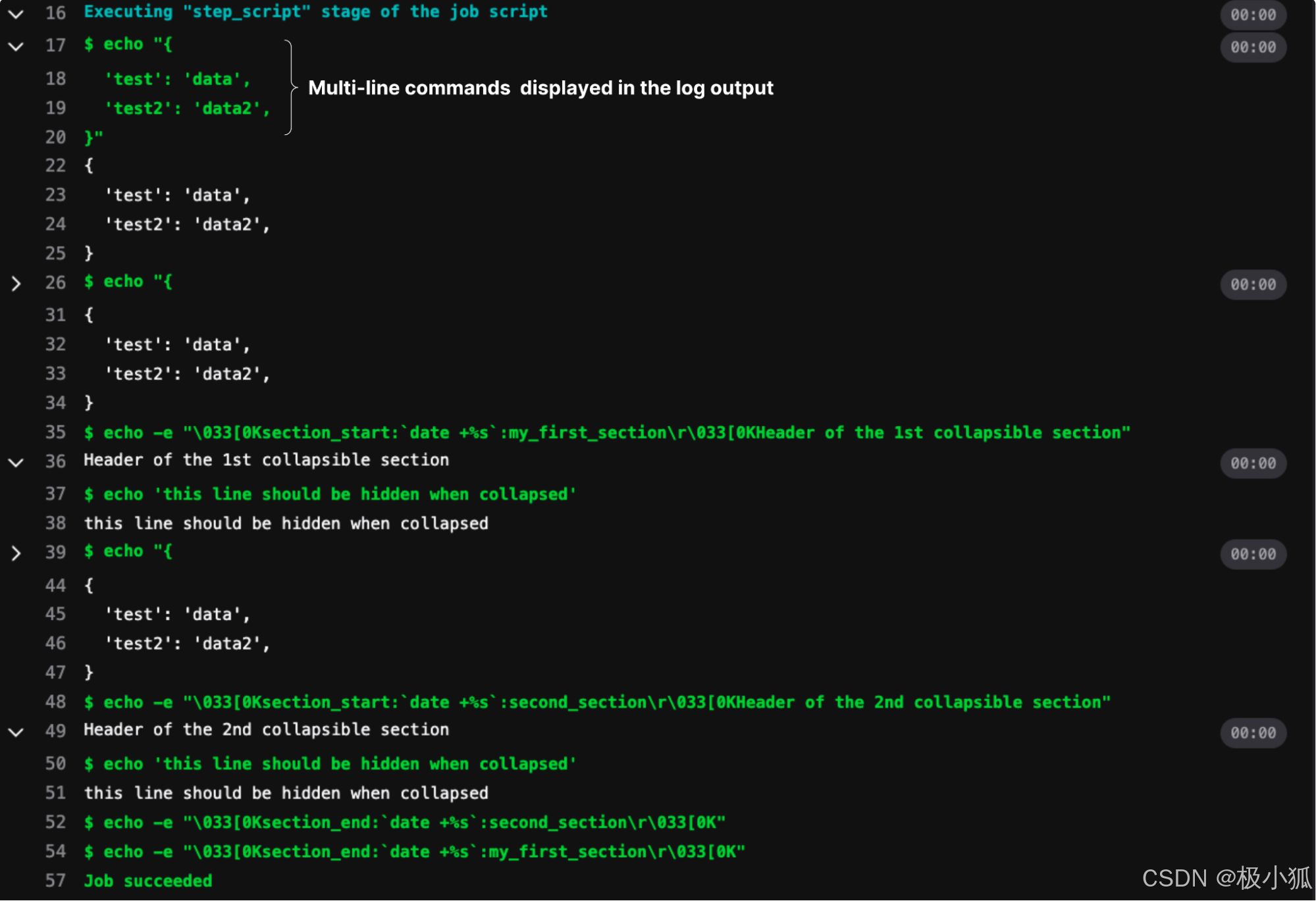
执行结果如下:

初步来看是比较符合预期的。
突然的想法
这种or字典查询的方式看上去比较易懂,能不能支持and查询呢。
比如 {age:{>:20, <:30}} 不就是一个非常容易看懂的range查询吗?
所以我决定对上面的这个方法做一个改造,封装另一个方法。
初步方法封装
将之前的方法复制过来改个名就行了。
def get_by_dict_and(engine, model, query_dict: dict):
"""
根据查询字典指定的键值对查询数据,键值对之间的关系是and的关系
:param engine: 引擎对象
:param model: 模型类
:param query_dict: 查询字典 {age:{gt:3,lt:33}}
"""
with Session(engine) as session:
query = select(model)
if isinstance(query_dict, dict):
for k, v in query_dict.items():
if hasattr(model, k):
if isinstance(v, dict):
# or_(Hero.age <= 35, Hero.age > 90)
mk = getattr(model, k)
conditions = []
for kk, vv in v.items():
if kk == "==":
conditions.append(mk == vv)
elif kk == ">":
conditions.append(mk > vv)
elif kk == "<":
conditions.append(mk < vv)
elif kk == ">=":
conditions.append(mk >= vv)
elif kk == "<=":
conditions.append(mk <= vv)
query = query.where(*conditions)
results = session.exec(query)
return results.all()
稍微测试一下
也是在上一个测试代码的基础上稍微改造一下。
from typing import Optional
from sqlmodel import Field, SQLModel
import fastzdp_sqlmodel as fsqlmodel
class User(SQLModel, table=True):
id: Optional[int] = Field(default=None, primary_key=True)
name: str
age: Optional[int] = None
# 创建数据库引擎
engine = fsqlmodel.get_engine(database="fastzdp_sqlmodel")
# 初始化表格
fsqlmodel.init_table(engine)
# 创建数据
u = User(name="张三", age=23)
fsqlmodel.add(engine, u)
u = User(name="张三", age=33)
fsqlmodel.add(engine, u)
u = User(name="李四", age=24)
fsqlmodel.add(engine, u)
# 查询年龄等于20或者小于30的用户
query = {"age": {">": 20, "<": 30}}
users = fsqlmodel.get_by_dict_and(engine, User, query)
print(users)
输出结果如下:

初步来看,也是非常符合预期的。
遗留问题
实际上上面的代码还有不少遗留的问题,比如我想要查询名字是张三或者年龄大于20的怎么查询呢?
不过我们有了初步的方法以后,后面就是增加功能和优化了,暂时不急。
我决定先把整个框架的大体架子给搭建起来。
封装根据ID查询的方法
原本的代码1
from typing import Optional
from sqlmodel import Field, SQLModel, create_engine, Session, select, or_
class Hero(SQLModel, table=True):
id: int | None = Field(default=None, primary_key=True)
name: str = Field(index=True)
secret_name: str
age: int | None = Field(default=None, index=True)
# 创建数据库引擎
sqlite_url = "mysql+pymysql://root:root@127.0.0.1:3306/fastzdp_sqlmodel?charset=utf8mb4"
engine = create_engine(sqlite_url, echo=True)
# 创建所有表
SQLModel.metadata.drop_all(engine)
SQLModel.metadata.create_all(engine)
# 新增
hero_1 = Hero(name="Deadpond", secret_name="Dive Wilson")
hero_2 = Hero(name="Spider-Boy", secret_name="Pedro Parqueador")
hero_3 = Hero(name="Rusty-Man", secret_name="Tommy Sharp", age=48)
hero_4 = Hero(name="Tarantula", secret_name="Natalia Roman-on", age=32)
hero_5 = Hero(name="Black Lion", secret_name="Trevor Challa", age=35)
hero_6 = Hero(name="Dr. Weird", secret_name="Steve Weird", age=36)
hero_7 = Hero(name="Captain North America", secret_name="Esteban Rogelios", age=93)
with Session(engine) as session:
session.add(hero_1)
session.add(hero_2)
session.add(hero_3)
session.add(hero_4)
session.add(hero_5)
session.add(hero_6)
session.add(hero_7)
session.commit()
# 查询
with Session(engine) as session:
statement = select(Hero).where(Hero.id == 1)
results = session.exec(statement)
hero = results.first()
print("Hero:", hero)
原本的代码2
from typing import Optional
from sqlmodel import Field, SQLModel, create_engine, Session, select, or_
class Hero(SQLModel, table=True):
id: int | None = Field(default=None, primary_key=True)
name: str = Field(index=True)
secret_name: str
age: int | None = Field(default=None, index=True)
# 创建数据库引擎
sqlite_url = "mysql+pymysql://root:root@127.0.0.1:3306/fastzdp_sqlmodel?charset=utf8mb4"
engine = create_engine(sqlite_url, echo=True)
# 创建所有表
SQLModel.metadata.drop_all(engine)
SQLModel.metadata.create_all(engine)
# 新增
hero_1 = Hero(name="Deadpond", secret_name="Dive Wilson")
hero_2 = Hero(name="Spider-Boy", secret_name="Pedro Parqueador")
hero_3 = Hero(name="Rusty-Man", secret_name="Tommy Sharp", age=48)
hero_4 = Hero(name="Tarantula", secret_name="Natalia Roman-on", age=32)
hero_5 = Hero(name="Black Lion", secret_name="Trevor Challa", age=35)
hero_6 = Hero(name="Dr. Weird", secret_name="Steve Weird", age=36)
hero_7 = Hero(name="Captain North America", secret_name="Esteban Rogelios", age=93)
with Session(engine) as session:
session.add(hero_1)
session.add(hero_2)
session.add(hero_3)
session.add(hero_4)
session.add(hero_5)
session.add(hero_6)
session.add(hero_7)
session.commit()
# 查询
with Session(engine) as session:
hero = session.get(Hero, 1)
print("Hero:", hero)
简单的思考
如果ID不存在,需不需要抛出异常?不需要
所以我这里决定选first这个方法。
初步封装
def get(engine, model, id):
"""
根据ID查询数据
:param engine: 连接数据库的引擎对象
:param model: 模型类
:param id: 要查找的id的值
:return: id对应的模型对象,如果不存在返回None
"""
with Session(engine) as session:
return session.exec(select(model).where(model.id == id)).first()
简单的测试
测试代码如下:
from typing import Optional
from sqlmodel import Field, SQLModel
import fastzdp_sqlmodel as fsqlmodel
class User(SQLModel, table=True):
id: Optional[int] = Field(default=None, primary_key=True)
name: str
age: Optional[int] = None
# 创建数据库引擎
engine = fsqlmodel.get_engine(database="fastzdp_sqlmodel")
# 初始化表格
fsqlmodel.init_table(engine)
# 创建数据
u = User(name="张三", age=23)
fsqlmodel.add(engine, u)
u = User(name="张三", age=33)
fsqlmodel.add(engine, u)
u = User(name="李四", age=24)
fsqlmodel.add(engine, u)
# 查询id为1的数据
u = fsqlmodel.get(engine, User, 1)
print(u)
# 查询id为11的数据
u = fsqlmodel.get(engine, User, 11)
print(u)
输出结果:

从输出结果来看,这个方法是比较符合预期的。
封装修改数据的方法
原本的代码
from typing import Optional
from sqlmodel import Field, SQLModel, create_engine, Session, select, or_
class Hero(SQLModel, table=True):
id: int | None = Field(default=None, primary_key=True)
name: str = Field(index=True)
secret_name: str
age: int | None = Field(default=None, index=True)
# 创建数据库引擎
sqlite_url = "mysql+pymysql://root:root@127.0.0.1:3306/fastzdp_sqlmodel?charset=utf8mb4"
engine = create_engine(sqlite_url, echo=True)
# 创建所有表
SQLModel.metadata.drop_all(engine)
SQLModel.metadata.create_all(engine)
# 新增
hero_1 = Hero(name="Deadpond", secret_name="Dive Wilson")
hero_2 = Hero(name="Spider-Boy", secret_name="Pedro Parqueador")
hero_3 = Hero(name="Rusty-Man", secret_name="Tommy Sharp", age=48)
hero_4 = Hero(name="Tarantula", secret_name="Natalia Roman-on", age=32)
hero_5 = Hero(name="Black Lion", secret_name="Trevor Challa", age=35)
hero_6 = Hero(name="Dr. Weird", secret_name="Steve Weird", age=36)
hero_7 = Hero(name="Captain North America", secret_name="Esteban Rogelios", age=93)
with Session(engine) as session:
session.add(hero_1)
session.add(hero_2)
session.add(hero_3)
session.add(hero_4)
session.add(hero_5)
session.add(hero_6)
session.add(hero_7)
session.commit()
# 查询
with Session(engine) as session:
statement = select(Hero).where(Hero.name == "Spider-Boy")
results = session.exec(statement)
hero = results.one()
print("Hero:", hero)
hero.age = 16
session.add(hero)
session.commit()
session.refresh(hero)
print("Updated hero:", hero)
简单的封装
def update(engine, model_obj, update_dict):
"""
修改数据
:param engine: 连接数据库的引擎对象
:param model_obj: 模型对象
:param update_dict: 更新字典
:return:
"""
with Session(engine) as session:
if not isinstance(update_dict, dict):
return
for k, v in update_dict.items():
if hasattr(model_obj, k):
setattr(model_obj, k, v)
session.add(model_obj)
session.commit()
session.refresh(model_obj)
return model_obj
测试
from typing import Optional
from sqlmodel import Field, SQLModel
import fastzdp_sqlmodel as fsqlmodel
class User(SQLModel, table=True):
id: Optional[int] = Field(default=None, primary_key=True)
name: str
age: Optional[int] = None
# 创建数据库引擎
engine = fsqlmodel.get_engine(database="fastzdp_sqlmodel")
# 初始化表格
fsqlmodel.init_table(engine)
# 创建数据
u = User(name="张三", age=23)
fsqlmodel.add(engine, u)
# 查询id为1的数据
u = fsqlmodel.get(engine, User, 1)
print(u)
# 修改
update_dict = {"name": "张三333"}
fsqlmodel.update(engine, u, update_dict)
# 查询id为1的数据
u = fsqlmodel.get(engine, User, 1)
print(u)
测试结果如下:

从测试结果来看是基本符合预期的。