1 引言
在2017年的开创性论文《Attention is All You Need(注意力就是你所需要的一切)》中,Vaswani等人提出了Transformer架构,这不仅在语音识别领域引起了一场革命,也对其他多个领域产生了深远的影响。本文将探讨Transformer架构的发展历程,从其最初的设计到当前的先进模型,并重点介绍这一过程中取得的关键性进展。
2 原始的Transformer
原始的Transformer模型引入了数个创新性概念,这些概念对自然语言处理领域产生了重大影响:
-
自注意力机制(Self-Attention Mechanism):该机制使得模型能够评估输入序列中各个元素的重要性,从而更有效地捕捉序列内部的依赖关系。
-
位置编码(Positional Encoding):通过向模型提供关于序列中各个元素位置的信息,确保了模型能够理解序列的顺序性。
-
多头注意力(Multi-Head Attention):这一特性允许模型同时从不同角度关注输入序列,增强了模型捕捉复杂关系的能力。
-
编码器-解码器架构(Encoder-Decoder Architecture):通过分离处理输入和输出序列,该架构优化了序列到序列的学习过程,提高了模型的效率和灵活性。
这些创新的结合,使得Transformer架构在机器翻译等任务中展现出了卓越的性能,超越了以往的序列到序列(sequence-to-sequence,S2S)模型。
3 编码器-解码器的Transformer及其他
随着时间的推移,原始的编码器-解码器结构在Transformer模型中经历了不断的优化和改进,带来了一系列显著的进步:
-
BART(Bidirectional and Auto-Regressive Transformers):通过结合双向编码和自回归解码,BART在文本生成任务中取得了显著的成果,提升了生成文本的连贯性和准确性。
-
T5(Text-to-Text Transfer Transformer):T5通过将各种自然语言处理任务统一转化为文本到文本的问题,极大地促进了多任务学习和迁移学习的发展,使模型能够更灵活地应用于不同的语言处理场景。
-
mT5(Multilingual T5):mT5扩展了T5的功能,支持多达101种语言,展示了其在多语言环境下的强大适应性和灵活性,进一步推动了跨语言自然语言处理技术的进步。
-
MASS(Masked Sequence-to-Sequence Pre-training):MASS通过引入新的预训练目标,为序列到序列学习提供了新的视角,增强了模型在处理复杂序列任务时的性能。
-
UniLM(Unified Language Model):UniLM通过整合双向、单向和序列到序列语言建模,为各种自然语言处理任务提供了一种统一的方法,提高了模型在不同任务中的泛化能力。
这些改进和创新不仅提升了Transformer模型在特定任务上的表现,也使得它们在更广泛的应用场景中展现出更大的潜力。
4 BERT与预训练的兴起
2018年,Google 推出了 BERT(Bidirectional Encoder Representations from Transformers),这一创新标志着自然语言处理(NLP)领域的一个重要里程碑。BERT 通过其双向编码器的表示,普及并完善了大规模文本语料库的预训练概念,引领了NLP任务方法的范式转变。接下来,让我们深入探讨BERT的创新之处及其对领域的影响。
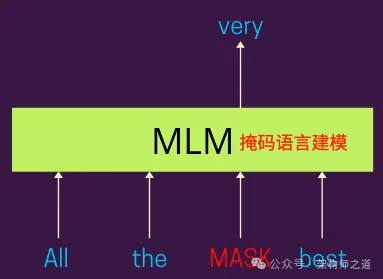
4.1 掩码语言建模(Masked Language Modeling,MLM)
-
处理方式:BERT 随机掩码输入序列中15%的标记,然后模型尝试根据周围的上下文预测这些被屏蔽的标记。
-
双向上下文:与以往仅从左到右或从右到左处理文本的模型不同,MLM 允许 BERT 同时考虑文本的前向和后向上下文。
-
深入理解:这种方法促使模型对语言的理解更加深入,包括语法、语义和上下文关系。
-
变体掩码:为了防止模型在微调过程中过度依赖 [MASK] 标记,80% 的被屏蔽标记被替换为 [MASK],10% 被替换为随机词,10% 保持原样。
4.2 下一句话预测(Next Sentence Prediction,NSP)
-
处理方式:BERT 接收一对句子,并预测第二个句子是否是紧随原始文本中第一个句子的下一句。
-
实施策略:在训练中,50% 的情况下,第二句是实际的下一句;另外50% 的情况下,第二句是随机选取的句子。
-
目的:这项任务有助于BERT理解句子之间的关系,这对于问答系统和自然语言推理等任务至关重要。

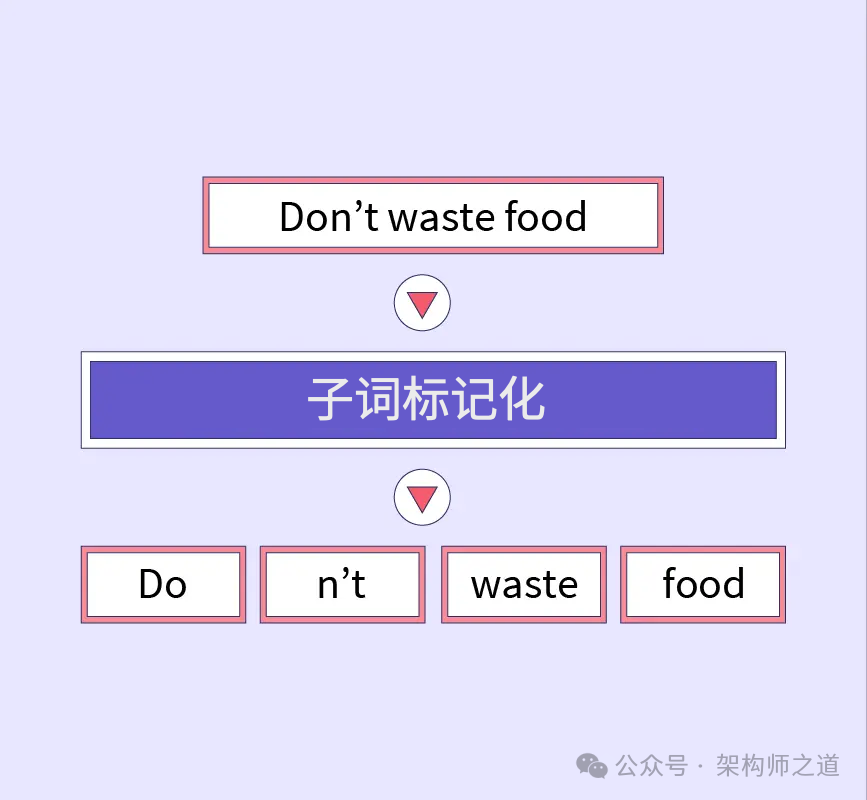
4.3 子词标记化(Subword Tokenization)
-
处理方式:BERT 将单词划分为子词单元,以平衡词汇表的大小和处理未知词汇的能力。
-
优势:这种方法使BERT能够处理多种语言,并有效地处理形态丰富的语言,如德语和芬兰语。
5 GPT:生成式预训练Transformer
OpenAI 的生成式预训练Transformer(GPT)系列代表了语言建模的重大进步,专注于用于生成任务的Transformer解码器架构。GPT的每次迭代都带来了规模、功能和对自然语言处理(NLP)影响的重大改进。
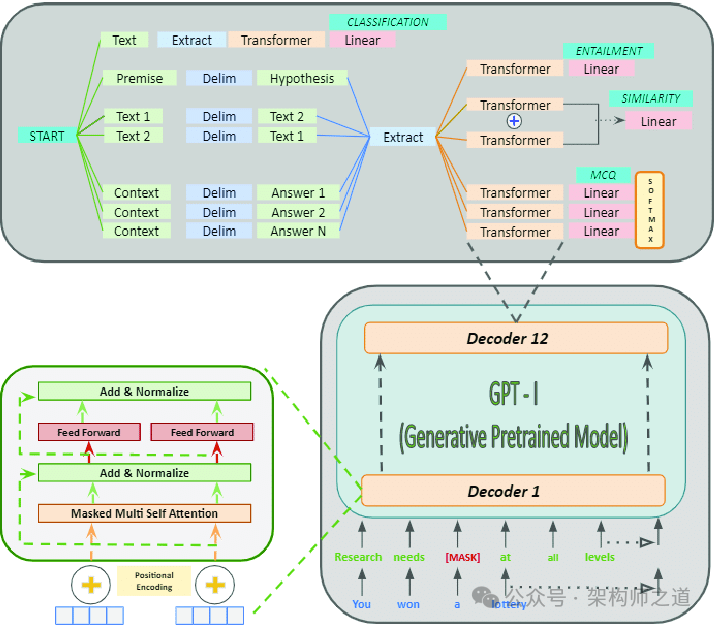
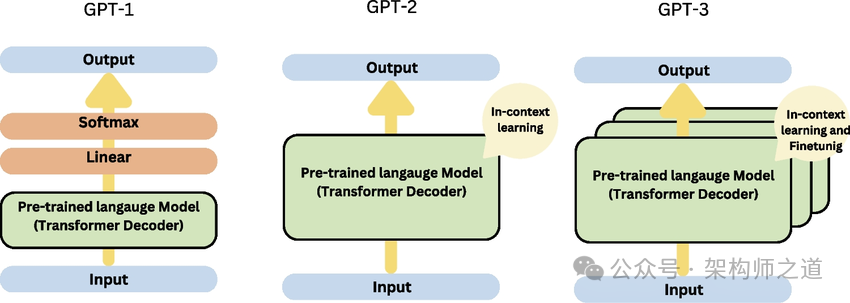
5.1 GPT-1(2018年)
GPT-1作为系列的开篇之作,引入了大规模无监督语言理解的预训练概念:
-
架构:基于具有12层和1.17亿个参数的Transformer解码器。
-
预训练:利用了各种在线文本。
-
任务:预测给定前文的下一个单词。
-
创新:证明了单一无监督模型可以针对不同的下游任务进行微调,实现高性能。
-
影响:GPT-1展示了NLP中迁移学习的潜力,预训练模型可以针对数据较少的任务进行微调。
5.2 GPT-2 (2019年)
GPT-2显著增加了模型规模,并表现出令人印象深刻的零样本学习能力:
-
架构:最大版本拥有15亿个参数,是GPT-1的10倍以上。
-
训练数据:使用了更大、更多样化的网页数据集。
-
特征:展示了在各种主题和风格上生成连贯且与上下文相关的文本的能力。
-
零样本学习:通过提供简单的输入提示,展示了执行未经过专门训练的任务的能力。
-
影响:GPT-2强调了语言模型的可扩展性,并引发了关于强大文本生成系统的伦理影响的讨论。

5.3 GPT-3(2020年)
GPT-3代表了规模和能力的巨大飞跃:
-
架构:由1750亿个参数组成,比GPT-2大100多倍。
-
训练数据:利用了来自互联网、书籍和维基百科的大量文本。
-
小样本学习:表现出只需几个示例或提示即可执行新任务的能力,无需进行微调。
-
多面性:熟练掌握各种任务,包括翻译、问答、文本摘要,甚至基本编程。
5.4 GPT-4(2023年)
GPT-4在其前辈奠定的基础上,进一步突破了语言模型的可能性界限:
-
架构:虽然具体的架构细节和参数数量尚未公开,但GPT-4被认为比GPT-3更大、更复杂,并进行了底层架构的增强以提高效率和性能。
-
训练数据:在更广泛和多样化的数据集上进行了训练,包括广泛的互联网文本、学术论文、书籍等,确保了对各种主题的全面理解。
-
高级少样本和零样本学习:表现出更强的能力,可以用最少的示例执行新任务,进一步减少了对特定任务微调的需求。
-
增强对情境的理解:情境感知的改进使GPT-4能够生成更准确和符合情境的响应,使其在对话系统、内容生成和复杂问题解决等应用中更加有效。
-
多模态能力:GPT-4将文本与其他模态(例如图像和可能的音频)集成在一起,实现更复杂、更通用的AI应用程序。
-
道德考虑和安全性:OpenAI非常重视GPT-4的道德部署,实施了先进的安全机制,以减少潜在的滥用并确保负责任地使用该技术。
6 注意力机制的创新
在Transformer架构的发展过程中,研究人员对注意力机制进行了多项创新性修改,这些修改显著提升了模型的性能和效率:
-
稀疏注意力(Sparse Attention):通过仅关注输入序列中与当前任务最相关的元素,稀疏注意力机制使得模型能够更高效地处理长序列,减少了计算量和提高了处理速度。
-
自适应注意力(Adaptive Attention):自适应注意力机制允许模型根据输入动态调整其注意力分配,从而增强了模型处理多样化任务的灵活性和适应性。
-
交叉注意力变体(Cross-Attention Variants):改进了解码器处理编码器输出的方式,使得生成的输出更加准确且与上下文紧密相关,这对于提高翻译质量和文本生成的连贯性至关重要。
7 结论
Transformer架构的发展历程是令人瞩目的。自最初被引入以来,Transformers不仅在自然语言处理(NLP)领域取得了革命性的进展,还在推动整个人工智能领域的边界。编码器-解码器结构的多功能性,结合不断创新的注意力机制和模型架构,持续推动着NLP及其他领域的技术进步。
随着研究的深入,我们可以预见到更多的创新将不断涌现,这些创新将进一步扩展Transformer模型在各个领域的应用范围和能力。Transformer架构的未来发展无疑将为人工智能带来更多令人兴奋的可能性,为解决现实世界中的复杂问题提供新的解决方案。
在大模型时代,我们如何有效的去学习大模型?
现如今大模型岗位需求越来越大,但是相关岗位人才难求,薪资持续走高,AI运营薪资平均值约18457元,AI工程师薪资平均值约37336元,大模型算法薪资平均值约39607元。

掌握大模型技术你还能拥有更多可能性:
• 成为一名全栈大模型工程师,包括Prompt,LangChain,LoRA等技术开发、运营、产品等方向全栈工程;
• 能够拥有模型二次训练和微调能力,带领大家完成智能对话、文生图等热门应用;
• 薪资上浮10%-20%,覆盖更多高薪岗位,这是一个高需求、高待遇的热门方向和领域;
• 更优质的项目可以为未来创新创业提供基石。
可能大家都想学习AI大模型技术,也_想通过这项技能真正达到升职加薪,就业或是副业的目的,但是不知道该如何开始学习,因为网上的资料太多太杂乱了,如果不能系统的学习就相当于是白学。为了让大家少走弯路,少碰壁,这里我直接把都打包整理好,希望能够真正帮助到大家_。
一、AGI大模型系统学习路线
很多人学习大模型的时候没有方向,东学一点西学一点,像只无头苍蝇乱撞,下面是我整理好的一套完整的学习路线,希望能够帮助到你们学习AI大模型。

第一阶段: 从大模型系统设计入手,讲解大模型的主要方法;
第二阶段: 在通过大模型提示词工程从Prompts角度入手更好发挥模型的作用;
第三阶段: 大模型平台应用开发借助阿里云PAI平台构建电商领域虚拟试衣系统;
第四阶段: 大模型知识库应用开发以LangChain框架为例,构建物流行业咨询智能问答系统;
第五阶段: 大模型微调开发借助以大健康、新零售、新媒体领域构建适合当前领域大模型;
第六阶段: 以SD多模态大模型为主,搭建了文生图小程序案例;
第七阶段: 以大模型平台应用与开发为主,通过星火大模型,文心大模型等成熟大模型构建大模型行业应用。
二、640套AI大模型报告合集
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。

三、AI大模型经典PDF书籍
随着人工智能技术的飞速发展,AI大模型已经成为了当今科技领域的一大热点。这些大型预训练模型,如GPT-3、BERT、XLNet等,以其强大的语言理解和生成能力,正在改变我们对人工智能的认识。 那以下这些PDF籍就是非常不错的学习资源。


四、AI大模型各大场景实战案例

结语
【一一AGI大模型学习 所有资源获取处(无偿领取)一一】
所有资料 ⚡️ ,朋友们如果有需要全套 《LLM大模型入门+进阶学习资源包》,扫码获取~
👉[CSDN大礼包🎁:全网最全《LLM大模型入门+进阶学习资源包》免费分享(安全链接,放心点击)]()👈