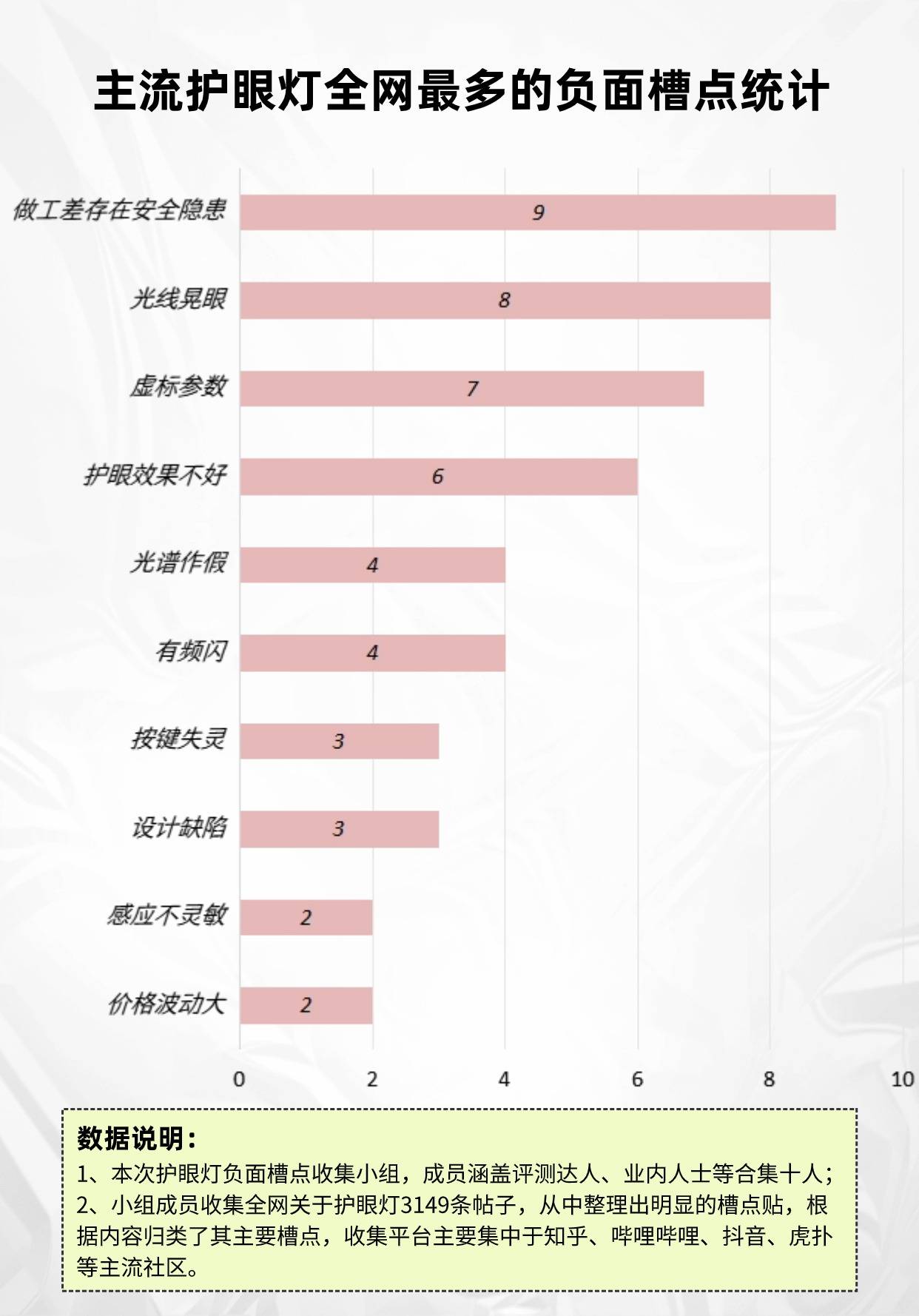
在GitHub上挑选和优化语料库的开源工具与方法
在GitHub上挑选和优化语料库的开源工具与方法
在数据科学和自然语言处理(NLP)的世界里,拥有一个干净且高质量的语料库是成功的关键。然而,随着数据量的增加,处理和优化这些数据变得尤为重要。幸运的是,GitHub上提供了许多开源工具和方法,可以帮助你减少重复、提高语料质量。本文将介绍一些常用的工具和方法,帮助你更高效地处理语料库。
1. 文本相似度计算库
Sentence Transformers
Sentence Transformers 是一个基于 BERT 等模型的库,它能够将句子转换为向量,并利用余弦相似度计算句子之间的相似度。这使得它非常适合用于识别和去除重复或相似的句子。通过比较句子之间的向量表示,我们可以轻松找出那些具有高度相似性的句子,并将其剔除,从而优化语料库的质量。
Spacy
Spacy 是一个功能强大的 NLP 库,它提供了多种文本