一. 为什么要用 RAG ?
如果使用 pretrain 好的 LLM 模型,应用在你个人的情境中,势必会有些词不达意的地方,例如问 LLM 你个人的信息,那么它会无法回答;这种情况在企业内部也是一样,例如使用 LLM 来回答企业内部的规章条款等。
这种时候主要有三种方式来让 LLM 变得更符合你的需求:
-
Promt Enginerring: 输入提示来指导 LLM 产生所需回应。 例如常见的 In-context Learning,通过在提示中提供上下文或范例,来形塑模型的回答方式。 例如,提供特定回答风格的示例或包含相关的情境信息,可以引导模型产生更合适的答案。
-
Fine tuning: 这个过程包括在特定数据集上训练 LLM,使其响应更符合特定需求。 例如,一家公司可能会使用其内部文件 Fine tuning ChatGPT ,使其能够更准确地回答关于企业内部规章条款等问题。 然而,Fine tuning需要代表性的数据集且量也有一定要求,且 Fine tuning 并不适合于在模型中增加全新的知识,或应对那些需要快速迭代新场景的情况。
-
RAG (Retrieval Augmented Generation): 结合了神经语言模型和撷取系统。 撷取系统从数据库或一组文件中提取相关信息,然后由语言模型使用这些信息来生成回应。 可以把RAG想像成给模型提供一本教科书,让它根据特定的问题去找信息。 此方法适用于模型需要整合实时、最新或非常特定的信息非常有用。 但RAG并不适合教会模型理解广泛的领域或学习新的语言、格式或风格。
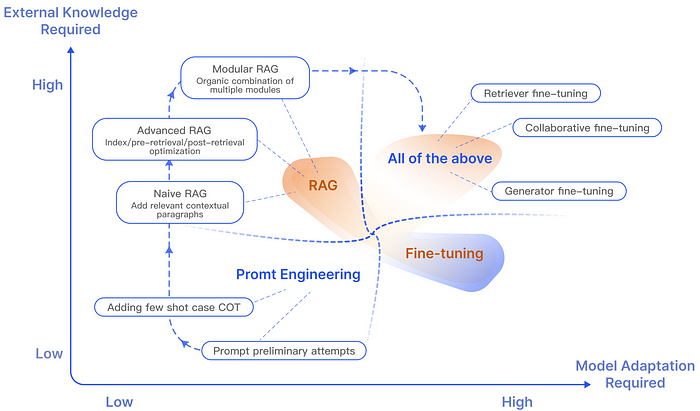
RAG 与方法的比较[
](https://arxiv.org/abs/2312.10997)Gao, Yunfan et al. “Retrieval-Augmented Generation for Large Language Models: A Survey.” (2023).
目前的研究已经表明,RAG 在优化 LLM 方面,相较于其他方法具有显著的优势 (Shuster et al. , 2021 ; Yasunaga et al. , 2022; Wang et al. , 2023c; Borgeaud et al. , 2022),主要的优势可以体现在以下几点:
-
- RAG 通过外部知识来提高答案的准确性,有效地减少了虚假信息,使得产生的回答更加准确可信。
-
- 使用撷取技术能够识别到最新的信息(用户提供),这使得 LLM 的回答能保持及时性。
-
- RAG 引用信息来源是用户可以核实答案,因此其透明透非常高,这增强了人们对模型输出结果的信任。
-
- 透过获取与特定领域数据,RAG能够为不同领域提供专业的知识支持,定制能力非常高。
-
- 在安全性和隐私管理方面,RAG 通过数据库来存储知识,对数据使用有较好控制性。 相较之下,经过 Fine tuning 的模型在管理数据存取权限方面不够明确,容易外泄,这对于企业是一大问题。
-
- 由于 RAG 不需更新模型参数,因此在处理大规模数据集时,经济效率方面更具优势。
不过虽然RAG有许多优势在,但这3种方法并不是互斥的,反而是相辅相成的。 结合 RAG 和 Fine tuning ,甚至 Promt Enginerring 可以让模型能力的层次性得增强。 这种协同作用特别在特定情境下显得重要,能够将模型的效能推至最佳。 整体过程可能需要经过多次迭代和调整,才能达到最佳的成效。 这种迭代过程涵盖了对模型的持续评估和改进,以满足特定的应用需求。
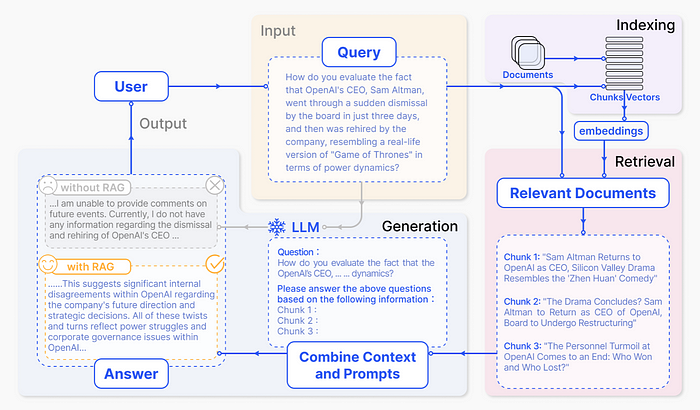
RAG 实际应用的过程[
](https://arxiv.org/abs/2312.10997)Gao, Yunfan et al. “Retrieval-Augmented Generation for Large Language Models: A Survey.” (2023).
二. 什么是 RAG ?
这篇章旨在介绍 RAG 的过程与其使用的相关技术。 总结来说RAG有两个关键技术:撷取与生成
-
- 撷取(Retrieval):从大量知识库中撷取出最相关的前几个文件
-
- 生成(Generation):将撷取到的信息转成为自然流畅的文字。
提取(Retrieval)
为了使 RAG 技术中的撷取更准确,关键在于如何获得准确的语意空间、匹配查询和文件的语意空间,以及如何使撷取器的输出与大型语言模型的偏好相协调,我们在以下分别探讨:
a.) 如何获得准确的语意空间
通常我们会把查询和文件映射的多维空间,称之为语意空间(semantic space),而进行撷取时,我们是在语意空间中进行,因此若映射的不够好,那么对于整个RAG系统是个大灾难。 这边介绍2步建立准确语意空间的方法。
-
- 区块优化 (Chunk optimization)
在处理外部文档时,首先需要将其拆分成更小的碎块以提取细粒度特征,然后将这些特征嵌入(embedded)以表达其语义。 然而,嵌入过大或过小的文本碎块可能会导致较差的结果,因此需要考虑几个重要的因素,例如撷取内容的性质、嵌入模型及其最佳块大小、用户查询的预期长度和复杂性,以及具体应用对撷取结果的利用方式。 因此目前有许多研究提出多种区块优化方法:
-
- Sliding window technology:通过合并跨多个撷取过程的全球相关信息,实现分层撷取。
-
- small2big:它在初始搜索阶段使用小文本块,然后提供较大的相关文本块供语言模型处理。
-
- **Abstract embedding:**优先考虑基于文档摘要(或摘要)的前K次撷取,提供对整个文档内容的全面理解。
-
- Metadata Filtering:技术通过文件的元资料进行过滤。
-
- Graph Indexing:将实体和关系转化为节点和连接,显著提高了相关性,特别是在多跳问题的情境下。
2. 微调嵌入模型 (Fine-tuning Embedding Models)
确定了Chunk的适当大小之后,我们需要通过一个嵌入模型(Embedding model)将 Chunk 和查询嵌入到语意空间中。 因此,嵌入模型是否能有效代表整个语料库变得极为重要。 传统常用的嵌入模型有以下两种:
-
• Sentence-Transformers: 是一种 python 的 BERT NLP 套件,提供各种训练好的BERT 模型套件,适合单个句的处理。
-
• text-embedding-ada-002: OpenAI 提出的新嵌入模型,适合处理包含256 或 512 Token 的文字区块。
而如今,一些出色的嵌入模型已经问世,例如 AngIE(Li and Li, 2023)、Voyage(VoyageAI, 2023)、BGE(BAAI, 2023) 等,这些模型已经在大型模语料库上 pre-training。 然而,当应用于特定领域时,它们准确捕捉领域特定信息的能力可能会受到限制。
此外我们还得对嵌入模型进行 Fine tuning,以确保模型能理解用户查询,这步对下游应用是必不可少的。 嵌入模型 Fine tuning 的方法主要有 2 种:
-
领域知识 Fine tuning: 嵌入模型的 Fine tuning 与 LLM 的 Fine tuning 不一样,主要差别在嵌入模型的数据集包括查询(Queries)、语料库(Corpus)和相关文件(Relevant Docs)。 资料集收集的过程非常繁杂,因此 LlamaIndex 专门为此引入了一系列关键的类别和函数,旨在简化工作流程。
-
针对下游任务 Fine tuning: 目前有研究使用 LLM 来 Fine tuning 嵌入模型。 例如,PROMPTAGATOR (Dai et al. , 2022),如此可以解决一些由于数据不足而难以 Fine tuning 的问题。
b.) 如何协调查询和文件的语意空间?
在RAG应用中,有些撷取器用同一个嵌入模型来处理查询和文档,而有些则使用两个不同的模型。 此外,用户的原始查询可能表达不清晰或缺少必要的语义信息。 RAG 使用 2 种关键技术,来实现这个目标:
- Query Rewriting
方法如 Query2Doc 和 ITER-RETGEN 利用 LLMs,通过将原始查询与额外的指导信息相结合,创建一个虚拟文档(Wang et al. , 2023;Shao et al. , 2023)。 其他还有如 HyDE (Gao et al. , 2022)、RRR (Ma et al. , 2023)、STEP-BACKPROMPTING (Zheng et al. , 2022)等。
- Embedding Transformation
相较于 Query Rewriting,这是一个更微观的技术。 LlamaIndex 在查询编码器后加入一个特殊的适配器,并对其进行微调,从而优化查询的嵌入表示,使之更适合特定的任务。
c.) 根据 LLM 的需求调整撷取结果
上述的方法旨在帮助我们提升撷取的效果,但是那些做法可能不能提升 LLM 模型的准确度,原因在于撷取的结果可能不是很符合 LLM 的偏好,因此如何让撷取结果往 LLM 的偏好靠齐,是一个重要的领域。
- Fine-tuning Retrievers
核心概念是通过从 LLM 获得的回馈信号来调整嵌入模型,也就是使用 LLM 提供的分数来指导撷取器的训练,这相当于用大语言模型来对数据集进行标注。 近期的方法如 AAR (Yu et al. , 2023)
- Adapters
上述的 Fine tuning 方法在实现上会有难度,如 API 的实现与算力的考量。 因此,一些研究选择外接Adapters来进行模型对齐。 PRCA (Yang et al. , 2023) 在上下文提取阶段和奖励驱动阶段训练适配器,并通过基于 Token 的autoregressiv 策略来优化撷取器的输出。
生成(Generation)
生成器是 RAG 的关键之一,它负责将撷取到的信息转换为连贯和流畅的文本。 在 RAG 中,生成器的输入不仅包括典型的上下文信息,还包括通过检索器获得的相关文本片段。 这种全面的输入使生成器能够深入理解问题的上下文,从而产生更具信息性和上下文相关性的回答。 生成器会根据撷取到的文字来指导内容的生成,确保产生的内容与撷取信息一致。
但撷取的内容五花八门,因此目前有一系列研究在探讨生成器的适应性,让其能应付来自查询和文件的输入资料。
a). 如何优化撷取到的讯息?
目前大宗做法是依赖无法调整但训练完好的 LLM 模型(如 ChatGPT-4)来生成,不过这些 LLM 仍然存在一些问题,例如上下文长度限制和对冗余信息的敏感度。 为了解决这个问题,目前一些研究开始专注在撷取后处理(post-retrieval processing),这个作法是将经由撷取器得到的信息去做进一步的处理、过滤或最佳化,提高撷取结果的品质,主要有 2 种主流作法:
-
- 信息压缩 (Information Compression)
即使撷取器能很棒的从庞大的知识库中撷取到相关信息,但管理大量的撷取信息仍是一个挑战。 目前做法是扩大LLM的上下文长度来解决此问题,但这并不能很有效解决问题,上下文长度限制仍是一大问题。 因此,压缩信息变得必要。 信息压缩对减少噪声、解决上下文长度限制和增强生成效果具有重要意义。
PRCA 通过训练一个信息撷取器来解决这个问题(Yang et al. , 2023)。 在上下文撷取阶段,提供输入文字 Sinput 时,它能够产生一个输出序列 Cextracted,代表从输入文件中压缩得到的上下文。 训练过程旨在最小化 Cextracted 和实际上下文 Ctruth 之间的差异。
其他如 RECOMP (Xu et al. , 2023) 或 Filter-Ranker (Ma et al. , 2023)。 Filter-Ranker 结合了大语言模型 (LLM) 和小语言模型 (SLM) 的优点。 SLM 充当过滤器,LLM 则作为排序器。 研究表明,指导 LLM 重排 SLM 识别出的挑战性样本,能够在各种信息提取 (IE) 任务中带来显著的改进。
- 重排序 (Reranking)
主要功能是优化撷取的信息集合。 LLM常常在引入额外上下文时面临性能下降,而Reranking有效地解决了这一问题。 其核心概念涉及重新排列文档记录,以使最相关的项目优先排在最前,从而限制文档的总数量。 这不仅解决了检索过程中上下文窗口扩展的挑战,而且还提升了检索效率和响应速度。
b). 如何根据撷取到的讯息优化生成器?
在使用一般 LLM 时,输入通常只会有一段文字查询。 但在 RAG 中,输入不仅结合了查询,还包括了撷取器撷取到的各种文档,其中包含结构化与非结构化的信息。 这个额外的信息会显著影响 LLM 的理解,特别是对于较小的 LLM。
在这种情况下,Fine tuning 模型以适应 「查询+撷取文档」的输入变得至关重要。 RAG 中生成器的 Fine tuning 方法与 LLM 的一般微调方法基本一样。 接下来,我们将简要描述一些涉及数据(格式化/非格式化)和优化功能的代表性工作。
- 通用优化流程 (General Optimization Process)
Self-mem (Cheng et al. , 2023) 采用了传统训练方法。 其中给定输入 x,撷取讯息 z,然后结合(x, z),模型生成输出 y。 论文探讨了两种主流 Fine tuning方法,分别为 Joint-Encoder (Arora et al. , 2023, Wang et al. , 2022b, Lewis et al. , 2020) 和 Dual-Encoder (Xia et al. , 2019, Cai et al. , 2021, Cheng et al. , 2022)。
在Joint-Encoder中,使用基于encoder-decoder的标准模型。 其中,encoder 首先对输入进行编码,decoder 通过注意力机制结合编码结果,并以自回归方式生成 Token。 另一方面,在 Dual-Encoder 中,系统设置了两个独立的 encoder,每个 encoder 分别对输入 (查询、上下文) 和文档进行编码,之后将输出依序经由 decoder,进行双向交叉注意力处理。 这两种架构都利用 Transformer 作为基础。
- 利用对比学习 (Utilizing Contrastive Learning)
在为 LLM 准备训练数据的阶段中,通常会建立输入和输出的配对。 这种传统方法可能导致「暴露偏差」,即模型仅在个别正确的输出示例上进行训练,接触到单一的正确反馈,无法了解其他可能的生成 Token。 这种限制可能会阻碍模型在真实世界中的表现,因为它可能过度适应训练集中的特定示例,从而降低了其在不同上下文中泛化的能力。
为了缓解暴露偏差,SURGE (Kang et al., 2023) 提出使用图文对比学习。 这种方法包括一个对比学习目标,促使模型产生一系列可行且连贯的回应,扩展到训练数据中遇到的实例之外。 这种方法在减少过度适应和加强模型的泛化能力方面至关重要。
三. RAG 生态系 ?
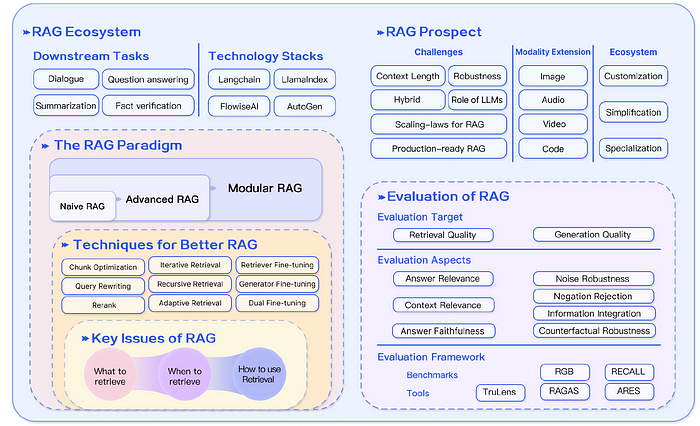
RAG 的生态系蓬勃发展,在水平领域,从最初的文本问答领域以外,RAG 的应用逐渐拓展到更多模态数据,包括图像、代码、结构化知识、影音等。 在这些领域,已经涌现许多相关研究成果。
而相关的Technical Stack发展也满迅速,如有名的LangChain和LLamaIndex这样的关键工具,随着ChatGPT的出现迅速获得了人气,它们提供了广泛的与RAG相关的API,并成为LLM领域的佼佼者。
同时新兴的Technical Stack也逐渐在发展,例如,Flowise AI10优先考虑低代码方法,用户能够通过简单的拖曳界面部署包括RAG在内的AI应用。 其他技术如 HayStack、Meltano11 和 Cohere Coral12 也因其在该领域的独特贡献而受到关注。
除了专注于 AI 的提供者之外,传统软件和云服务提供商也在扩大其服务范围,包括以 RAG 为中心的服务。 如向量数据库公司Weaviate推出的Verba7专注于个人助理应用,而亚马逊的Kendra提供智能企业搜索服务,允许用户使用内置连接器在各种内容存储库中导航。
最后的最后
感谢你们的阅读和喜欢,我收藏了很多技术干货,可以共享给喜欢我文章的朋友们,如果你肯花时间沉下心去学习,它们一定能帮到你。
因为这个行业不同于其他行业,知识体系实在是过于庞大,知识更新也非常快。作为一个普通人,无法全部学完,所以我们在提升技术的时候,首先需要明确一个目标,然后制定好完整的计划,同时找到好的学习方法,这样才能更快的提升自己。
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

大模型知识脑图
为了成为更好的 AI大模型 开发者,这里为大家提供了总的路线图。它的用处就在于,你可以按照上面的知识点去找对应的学习资源,保证自己学得较为全面。

经典书籍阅读
阅读AI大模型经典书籍可以帮助读者提高技术水平,开拓视野,掌握核心技术,提高解决问题的能力,同时也可以借鉴他人的经验。对于想要深入学习AI大模型开发的读者来说,阅读经典书籍是非常有必要的。

实战案例
光学理论是没用的,要学会跟着一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。

面试资料
我们学习AI大模型必然是想找到高薪的工作,下面这些面试题都是总结当前最新、最热、最高频的面试题,并且每道题都有详细的答案,面试前刷完这套面试题资料,小小offer,不在话下

640套AI大模型报告合集
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。

这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】