手动创建线程的弊端
在前面我们讲了手动创建线程的使用方式:当一个任务过来,创建一个线程,线程执行完了任务马上又销毁,然后下一次任务过来又重新创建线程,执行完任务再销毁,周而复始。
那么会导致这样一个问题:反复创建和销毁线程系统开销比较大,比较极端的情况下,如果任务比较简单,那么创建和销毁线程消耗的资源和时间甚至比线程执行任务本身消耗的资源还要大,这样得不偿失。
此外,如果系统中同时提交了n个任务,且每个任务执行的时间比较长,这样系统中就可能同时存在n个线程在执行任务(一个任务一个线程去执行),如果这个n很大,那么过多的线程会占用过多的内存等资源,还会带来过多的上下文切换,同时还会导致系统不稳定。
针对上面的两点问题,线程池出现了。在开发过程中,合理的使用线程池能够带来3个好处:
-
1.首先是降低资源消耗。通过重复利用已创建的线程降低创建线程和销毁线程所带来的开销。
-
2.提高响应速度。当任务到达时,任务可以不需要等待线程创建就立即执行。
-
3.提高线程的可管理性。线程是稀缺资源,如果无限制的创建,不仅消耗系统资源,同时降低系统的稳定性,使用线程池可以进行统一分配、调优和监控。
手动创建线程池
线程池的创建方式
在 Java 语言中,线程池的创建方式总体来说分为两类:
-
1.通过ThreadPoolExecutor 手动创建线程池。
-
2.通过 Executors 执行器自动创建线程池。
本文我们只介绍通过ThreadPoolExecutor如何手动创建我们需要的线程池。
ThreadPoolExecutor类
ThreadPoolExecutor是java线程池最为核心的一个类,它有四个构造方法,我们只看其中最原始的一个构造方法,其余三个都是由它衍生而来:
public ThreadPoolExecutor(int corePoolSize,
int maximumPoolSize,
long keepAliveTime,
TimeUnit unit,
BlockingQueue<Runnable> workQueue
ThreadFactory threadFactory,
RejectedExecutionHandler handler
)
可以看到这里有6个参数,我们来看下线程池中各个参数的含义,这些参数直接影响到线程池的效果.
-
corePoolSize:核心线程数,线程池初始化时线程数默认为 0,当有新的任务提交后,会创建新线程执行任务(注意不是在初始化 ThreadPoolExecutor 时立即创建),如果不做特殊设置,此后在程序的运行过程中,线程数通常不会再小于 corePoolSize ,因为它们是核心线程,即便未来可能没有可执行的任务也不会被销毁。
-
maximumPoolSize:线程池允许创建的最大线程数,随着任务量的增加,在核心线程已经全部忙碌时并且任务队列满了之后,线程池会进一步创建新线程,最多可以达到 maximumPoolSize 来应对任务多的场景,如果未来线程有空闲,大于 corePoolSize 的线程会被合理回收。
-
workQueue:任务队列,随着任务的不断增加,线程数会逐渐增加并达到核心线程数,此时如果仍有任务被不断提交,就会被放入 workQueue 任务队列中
-
keepAliveTime和unit:当线程池中线程数量多于核心线程数时,而此时又没有任务可做,线程池就会检测线程的 keepAliveTime,如果超过规定的时间,无事可做的线程就会被销毁,以便减少内存的占用和资源消耗。
-
ThreadFactory:线程工厂,它的作用是生产线程以便执行任务。我们可以选择使用默认的线程工厂,创建的线程都会在同一个线程组,并拥有一样的优先级,且都不是守护线程,我们也可以选择自己定制线程工厂,为线程指定名字、优先级、守护线程等属性。
-
handler:拒绝策略,即当线程池和等待队列都达到最大负荷量时,下一个任务来临时采取的策略。
通过上面介绍可知线程池中的线程创建流程图:
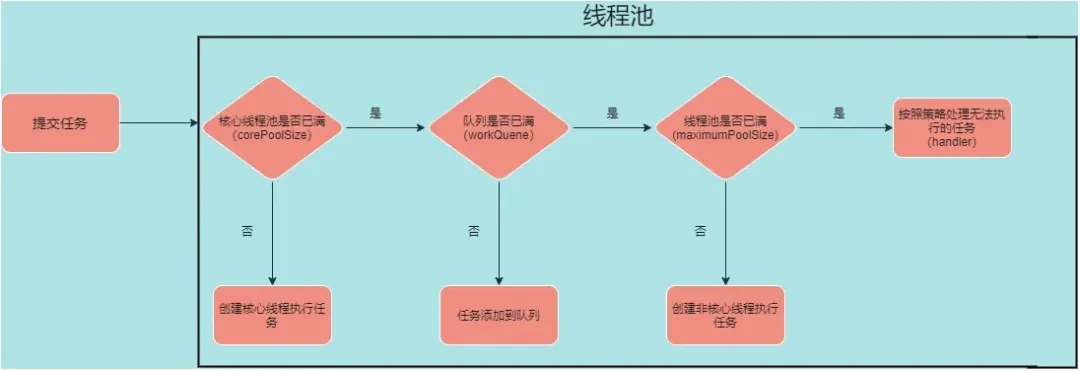
举个栗子:现有一个线程池,corePoolSize=2,maxPoolSize=4,队列长度为2,那么当任务过来会先创建2个核心线程数,接下来进来的任务会进入到队列中直到队列满了,会创建额外的线程来执行任务(最多4个线程),这个时候如果再来任务就会执行拒绝策略。下面看一个例子:
class MyRunnable implements Runnable{
private int i;
MyRunnable(int i){
this.i = i;
}
@Override
public void run() {
SimpleDateFormat simpleDateFormat = new SimpleDateFormat("yy/MM/dd-HH:mm:ss");
String time = simpleDateFormat.format(new Date());
System.out.println(time + " 线程" + Thread.currentThread().getName() + " 执行任务" + i);
try {
Thread.sleep(2000);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
class ThreadPoolExecutorTest{
public void testThreadPoolExecutor(){
ExecutorService executorService = new ThreadPoolExecutor(2, 4, 2, TimeUnit.SECONDS, new ArrayBlockingQueue<>(2));
for (int i=0; i<10; i++){
executorService.submit(new MyRunnable(i));
}
}
}
public class ThreadPoolExecutorExample {
public static void main(String[] args) throws InterruptedException {
ThreadPoolExecutorTest threadPoolExecutorTest = new ThreadPoolExecutorTest();
threadPoolExecutorTest.testThreadPoolExecutor();
}
}
//运行结果
Exception in thread "main" java.util.concurrent.RejectedExecutionException: Task java.util.concurrent.FutureTask@179d3b25[Not completed, task = java.util.concurrent.Executors$RunnableAdapter@1a6c5a9e[Wrapped task = thread.threadpool.MyRunnable@37bba400]] rejected from java.util.concurrent.ThreadPoolExecutor@254989ff[Running, pool size = 4, active threads = 4, queued tasks = 2, completed tasks = 0]
at java.base/java.util.concurrent.ThreadPoolExecutor$AbortPolicy.rejectedExecution(ThreadPoolExecutor.java:2055)
at java.base/java.util.concurrent.ThreadPoolExecutor.reject(ThreadPoolExecutor.java:825)
at java.base/java.util.concurrent.ThreadPoolExecutor.execute(ThreadPoolExecutor.java:1355)
at java.base/java.util.concurrent.AbstractExecutorService.submit(AbstractExecutorService.java:118)
at thread.threadpool.ThreadPoolExecutorTest.testThreadPoolExecutor(ThreadPoolExecutorExample.java:30)
at thread.threadpool.ThreadPoolExecutorExample.main(ThreadPoolExecutorExample.java:64)
22/06/25-10:55:41 线程pool-1-thread-4 执行任务5
22/06/25-10:55:41 线程pool-1-thread-3 执行任务4
22/06/25-10:55:41 线程pool-1-thread-1 执行任务0
22/06/25-10:55:41 线程pool-1-thread-2 执行任务1
22/06/25-10:55:43 线程pool-1-thread-2 执行任务2
22/06/25-10:55:43 线程pool-1-thread-4 执行任务3
在上面的程序中,创建了一个corePoolSize=2,maxPoolSize=4,队列长度为2的线程池,然后向线程池中提交了10个任务,任务中run方法的sleep(2000)模拟任务执行的时间是2s。
通过程序的运行结果可以看出,首先在10:55:41时刻,10个任务先后提交,该时刻马上创建了2个核心线程pool-1-thread-4和pool-1-thread-3立即去执行其中最先提交的两个任务(这里是任务5,4);随后提交的任务2和3则放到任务队列中,暂时不执行;再随后的任务0和1提交的时候,一看2个核心线程还在执行任务而且任务系列已慢,于是马上又创建了2个线程(maxPoolSize-corePoolSize)立即去执行任务0和1;后面还剩4个任务再次提交时,就抛出RejectedExecutionException异常;最后过了2s后也就是在10:55:43 时刻,当有线程已经执行完任务空闲出来于是又从任务队列获取到任务2和3执行。
如何设置线程数
使用线程池,如何合理的给出线程池的大小,是非常重要的。对于线程池的大小不能过大,也不能过小。过大会有大量的线程在相对较少的CPU和内存上竞争,过小又会导致空闲的处理器无法工作,浪费资源,降低吞吐率。对于线程池大小的设定,我们需要考虑的问题有:
-
CPU个数
-
内存大小
-
任务类型,是计算密集型(CPU密集型)还是I/O密集型
CPU 密集型任务
所谓的CPU 密集型任务,是指需要大量耗费 CPU 资源的任务,比如加密、解密、压缩、计算等任务;对于这样的任务最佳的线程数为 CPU 核心数的 1~2 倍。
对于CPU 密集型任务,因为计算任务非常重,会占用大量的 CPU 资源,所以这时 CPU 的每个核心工作基本都是满负荷的,如果设置过多的线程,会造成不必要的上下文切换,此时线程数的增多并没有让性能提升,反而由于线程数量过多会导致性能下降。
IO 密集型任务
IO 密集型任务的特点是并不会特别消耗 CPU 资源,但是会把主要时间耗费在IO操作上,比如数据库、文件的读写,网络通信等任务。
对于IO密集型任务最大线程数一般会大于 CPU 核心数很多倍。对于IO密集型任务,因为 IO 读写速度相比于 CPU 的速度而言是很慢的,如果我们设置线程数过少,就可能导致 CPU 资源得不到充分的利用;反之,如果我们设置线程数过多,当所有的任务都在被执行且在等待IO的时候,就会使一部分线程处于闲置状态。
线程数计算通用估算公式
关于线程数目的计算方法,《Java并发编程实战》的作者 Brain Goetz 给出了一个通用的计算方法:
线程数 = CPU 核心数 *(1+平均等待时间/平均工作时间)
#例如:假设你的电脑有 4 个 CPU 核心,线程平均等待时间是 200 毫秒,平均工作时间是 800 毫秒。套用公式:
线程数 = 4 * (1 + 200/800) = 4 * 1.25 = 5
**平均等待时间:**在并发程序中,线程并不总是在做计算工作。有时候,它们会等待一些资源,例如等待从磁盘读取数据、等待网络请求的响应,或等待其他线程完成工作。这些等待时间就是“平均等待时间”。
平均工作时间: 线程真正忙于执行计算、处理数据、或者执行逻辑操作的时间。这个时间越长,表示线程越多地利用了 CPU 的处理能力。
由公式可得,线程等待时间所占比例越高,那么你需要更多的线程来“掩盖”这些等待时间,确保在任何时候都有足够的线程在工作,以充分利用 CPU 的处理能力。
线程CPU时间所占比例越高,所需的线程数越少,因为每个线程都会充分利用 CPU。
当然,这里介绍的线程数量估算公司只适用于某些理想化的场景:假设机器上只有一个应用在运行,并且只有一个线程池。
现实中,同一台机器上可能会运行多个不同的应用程序,每个应用程序都有自己的线程池。例如,一台服务器上可能同时运行着 Web 服务器、数据库服务器和缓存服务器。
因此在实际部署时,你需要根据以下几个步骤进行验证和调整:
- 性能测试:在实际环境中进行压力测试,观察应用程序的性能表现,包括响应时间、吞吐量和 CPU 利用率等。
- 资源监控:持续监控 CPU、内存、磁盘 I/O 等资源的使用情况,确保线程配置不会导致资源的过度使用或浪费。
- 动态调整:根据监控结果和性能测试的反馈,动态调整线程池的配置,以达到最佳的资源利用和应用性能。



















