Redis 高可用方式
Redis 提供了多种高可用性方案,主要包括以下几种方式:
主从复制(Replication)
主从复制是最基本的高可用性方案,通过将数据从一个主节点复制到多个从节点来实现数据的冗余和读写分离。主节点负责所有的写操作,而读操作可以在主节点和从节点上进行。
优点是架构简单、部署方便,并且具有高性价比。
缺点是不保证数据的可靠性,故障恢复复杂,且主节点的写能力受到单机的限制。
哨兵模式(Sentinel)
哨兵模式在主从复制的基础上增加了故障转移的功能,通过自动故障转移机制来应对主节点的故障,确保服务的持续可用。哨兵系统持续监控Redis实例的状态,提供更全面的监控信息。
缺点 哨兵模式需要部署和配置额外的哨兵节点,增加了系统的复杂性,并且主节点发生故障后,新的主节点可能会有一段时间的数据不一致,影响数据的准确性。
集群模式(Cluster)
Redis集群通过数据分片(sharding)实现数据的分布式存储,每个节点负责存储一部分数据,同时提供复制和高可用性。
优点 集群模式可以实现数据的水平扩展,提高了系统的性能和存储容量;
同时,集群模式也可以实现高可用性,即使某个节点发生故障,系统仍然可以继续提供服务。
缺点 集群模式的配置和维护相对复杂,需要管理多个节点 。
在选择Redis的高可用性方案时,需要综合考虑业务需求、系统复杂性、性能要求和故障转移需求。
例如,如果业务主要是读取数据,数据量不大,对数据的一致性要求不高,可以选择主从复制模式。
如果业务需要高可用性,即使在主节点发生故障的情况下也需要保证服务的正常运行,可以选择哨兵模式。如果业务数据量大,需要高性能和高可用性,集群模式可能是最佳选择
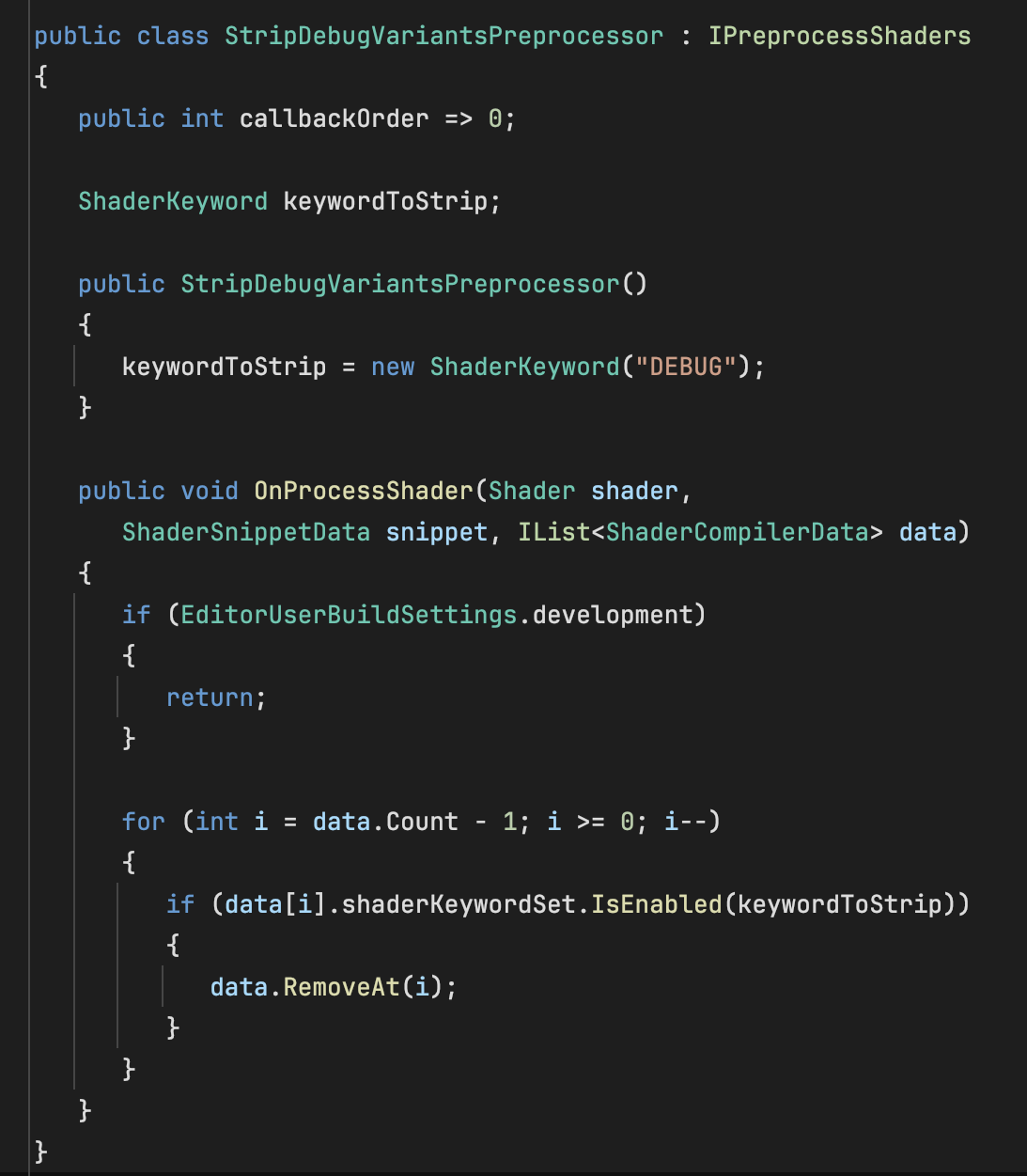
Redis Cluster 详解
为什么使用
扩展性:Redis Cluster通过数据分片,突破单机限制,提供更大的存储容量和处理能力。
高可用性:集群能够在部分节点故障时继续提供服务,实现自动故障转移。
读写分离:通过主从复制模型,提高读取性能,并在主节点故障时自动进行故障转移 。
原理
Redis Cluster采用无中心结构,数据自动在多个Redis节点间分片。集群中的每个节点都保存数据,并且节点之间相互连接,共享整个集群的状态信息。它使用数据分片(Sharding),通过16384个哈希槽来分配数据,每个键通过CRC16算法(哈希函数(CRC16[key]&16383))映射到0-16383槽内,然后这个槽再分配给集群中的节点 。每个节点维护部分槽及槽所映射的键值数据。哈希函数: Hash()=CRC16[key]&16383 按位与槽与节点的关系如下:

用 hash 函数将键映射到槽,再由槽指向数据

节点角色
主节点(Master):处理读写请求,维护数据副本,并同步给从节点。
从节点(Slave):复制主节点数据,提供读服务,在主节点故障时可晋升为主节点 。
节点间通信
使用Gossip协议交换集群状态信息,包括节点新增、删除、故障、槽信息变更等。客户端与任意节点建立连接,节点负责将请求转发至正确的主节点 。
redis集群架构图

- 所有的redis节点彼此互联(PING-PONG机制),内部使用二进制协议优化传输速度和带宽。
- 节点的fail是通过集群中超过半数的节点检测失效时才生效。
- 客户端与redis节点直连,不需要中间proxy层.客户端不需要连接集群所有节点,连接集群中任何一个可用节点即可。
- redis-cluster把所有的物理节点映射到[0-16383]slot上,cluster 负责维护node<->slot<->value
redis集群投票:容错

投票过程是集群中所有master参与,如果半数以上master节点与master节点通信超时(cluster-node-timeout),认为当前master节点挂掉.
什么时候整个集群不可用(cluster_state:fail)?
如果集群任意master挂掉,且当前master没有slave.集群进入fail状态,也可以理解成集群的slot映射[0-16383]不完整时进入fail状态.
redis-3.0.0.rc1加入cluster-require-full-coverage参数,默认关闭,打开集群兼容部分失败.
如果集群超过半数以上master挂掉,无论是否有slave,集群进入fail状态.
故障检测与自动故障转移:节点间定期发送PING/PONG消息,检测对方是否存活。故障节点的从节点竞选成为新主节点,其他节点更新槽映射与配置,客户端自动重定向 。
数据同步与增量复制:新节点加入或从节点晋升为主节点时,通过RDB快照进行全量同步。主从节点间通过PSYNC命令进行增量数据同步,减少网络开销 。
集群的端口:每个Redis集群节点需要打开两个TCP连接,一个用于客户端连接,另一个用于集群节点间通信,后者使用的是二进制协议 。
Redis Cluster缺陷以及相应解决方法
数据迁移和重新分片的复杂性:
当集群需要扩容或缩容时,数据迁移和重新分片可能是一个复杂的过程。这可能涉及到大量的数据在节点之间移动,对于大型集群来说可能是一个挑战。
解决方法:
使用redis-cli提供的–cluster reshard选项来进行数据迁移,同时监控整个过程以确保数据一致性。
不支持多键操作:
Redis Cluster不支持跨多个节点的多键操作,如MGET或MSET,因为这些操作可能涉及到多个节点的数据。
解决方法:
将相关联的数据分布在同一个槽中,或者在应用层实现数据聚合逻辑。
写操作热点问题:
如果某些键访问非常频繁,可能导致成为写操作的热点,影响性能。
解决方法:
通过合适的数据分布和缓存策略,例如二级缓存或热点数据的预热机制,来避免热点问题。
故障转移和自动故障恢复:
虽然Redis Cluster支持故障转移,但如果主节点和其所有从节点同时宕机,那么该节点的数据将会丢失,集群将不可用。
解决方法:
采用三主三从的架构,实现交叉复制,即使一台主机宕机,其他主机仍然可以继续提供服务。
运维监控挑战:
Redis Cluster的分布式特性使得监控和故障排查更为复杂。
解决方法:
使用专业的监控工具来监控集群状态,如Redis自带的监控命令CLUSTER INFO,以及第三方监控系统。
数据一致性问题:
在网络分区或其他异常情况下,可能会导致数据一致性问题。
解决方法:
通过适当的集群配置和网络优化来减少这些问题的发生,同时在发现问题时使用CLUSTER REPLICATE命令来同步数据。
集群状态同步:
在主节点故障后,新的主节点可能需要一段时间来同步数据,这期间集群可能无法提供服务。
解决方法:
合理配置从节点的数量和分布,确保故障转移时数据同步能够快速完成。
不支持在线扩容:
Redis Cluster不支持在线平滑扩容,扩容时可能需要停机。
解决方法:
通过预先规划容量和使用redis-cli工具进行节点添加和数据迁移来最小化停机时间。
资源利用率问题:
在Redis Cluster中,只有主节点对外提供服务,从节点仅作为备份,这可能导致资源浪费。
解决方法:
合理规划主从节点数量,并通过负载均衡策略来提高资源利用率。