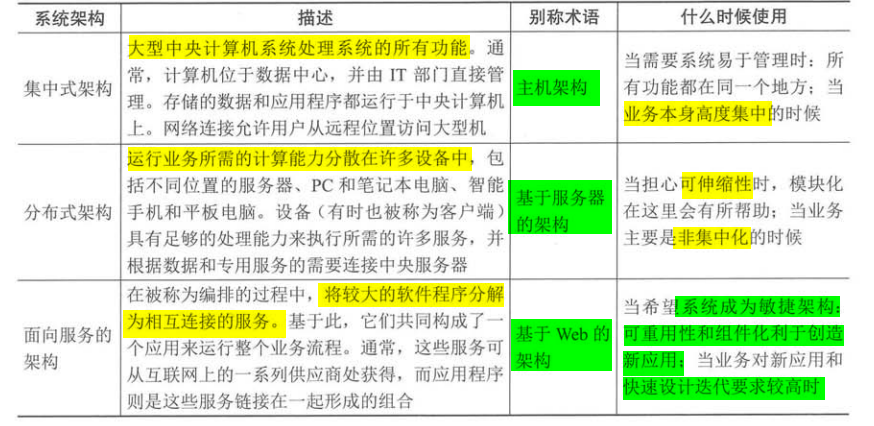
在过去的几篇文章中,我们深入探讨了数据埋点、数据质量保证、数据分析和可视化等主题。现在,让我们站在更高的视角,讨论如何将这些技术和方法整合到实际的业务决策中,以及如何在组织中建立真正的数据驱动文化。

目录
- 1. 回顾:数据驱动决策的基础
- 2. 建立数据驱动文化
- 2.1 领导层的支持
- 2.2 数据素养培训
- 2.3 建立数据驱动的决策流程
- 3. 数据伦理与隐私
- 3.1 数据伦理框架
- 3.2 隐私保护技术
- 4. 高级数据驱动技术
- 4.1 机器学习辅助决策
- 4.2 A/B测试和实验设计
- 5. 案例研究:Netflix的数据驱动决策
- 6. 未来趋势
- 7. 构建数据驱动组织的路线图
- 8. 挑战与解决策略
- 9. 结语
1. 回顾:数据驱动决策的基础
首先,让我们快速回顾一下我们已经讨论过的关键点:
- 数据埋点:精确捕获用户行为和系统事件
- 数据质量保证:确保数据的准确性和可靠性
- 数据分析:从原始数据中提取有价值的洞察
- 数据可视化:有效地传达数据洞察

这些元素共同构成了数据驱动决策的基础。但是,仅有这些技术还不够,我们还需要一个支持数据驱动的组织文化和决策框架。
2. 建立数据驱动文化
建立数据驱动文化是一个长期的过程,需要从上至下的支持和commitment。以下是一些关键步骤:
2.1 领导层的支持

数据驱动文化必须从公司最高层开始。领导者应该:
- 公开支持和倡导基于数据的决策
- 投资数据基础设施和人才
- 在决策过程中以身作则,要求并使用数据支持
# 模拟领导仪表板
import pandas as pd
import matplotlib.pyplot as plt
def executive_dashboard(data):
# KPI计算
revenue = data['sales'].sum()
customers = data['customer_id'].nunique()
avg_order_value = revenue / data['order_id'].nunique()
# 创建仪表板
fig, (ax1, ax2, ax3) = plt.subplots(1, 3, figsize=(15, 5))
ax1.bar(['Revenue'], [revenue])
ax1.set_title('Total Revenue')
ax2.bar(['Customers'], [customers])
ax2.set_title('Unique Customers')
ax3.bar(['AOV'], [avg_order_value])
ax3.set_title('Average Order Value')
plt.tight_layout()
plt.show()
# 使用示例
sales_data = pd.read_csv('sales_data.csv')
executive_dashboard(sales_data)
2.2 数据素养培训

提高整个组织的数据素养是建立数据文化的关键。
def data_literacy_program():
modules = [
{
"title": "数据基础",
"content": [
"什么是数据?",
"数据类型和结构",
"数据收集方法"
]
},
{
"title": "数据分析入门",
"content": [
"描述性统计",
"数据可视化基础",
"简单的假设检验"
]
},
{
"title": "数据驱动决策",
"content": [
"从数据到洞察",
"常见的决策陷阱",
"数据伦理"
]
}
]
for module in modules:
print(f"Module: {module['title']}")
for topic in module['content']:
print(f" - {topic}")
print()
data_literacy_program()
2.3 建立数据驱动的决策流程

将数据分析纳入正式的决策流程中。
def data_driven_decision_process(hypothesis, data, analysis_function, decision_threshold):
# 进行数据分析
result = analysis_function(data)
# 基于结果和阈值做出决策
if result > decision_threshold:
decision = "Accept hypothesis"
else:
decision = "Reject hypothesis"
return {
"hypothesis": hypothesis,
"result": result,
"decision": decision,
"explanation": f"Based on our analysis, the result ({result}) {'exceeds' if result > decision_threshold else 'does not exceed'} our decision threshold ({decision_threshold})."
}
# 使用示例
def analysis_function(data):
# 这里是实际的分析逻辑
return data.mean()
hypothesis = "新的营销活动将提高转化率"
data = pd.Series([0.05, 0.06, 0.055, 0.07, 0.065]) # 假设这是转化率数据
decision = data_driven_decision_process(hypothesis, data, analysis_function, 0.06)
print(decision)
3. 数据伦理与隐私
随着数据在决策中的作用越来越重要,数据伦理和隐私保护也变得至关重要。
3.1 数据伦理框架

建立一个数据伦理框架来指导数据的收集、使用和共享。
class DataEthicsFramework:
def __init__(self):
self.principles = [
"尊重用户隐私",
"确保数据安全",
"公平和无歧视",
"透明度",
"问责制"
]
def evaluate_data_practice(self, practice):
compliance = {}
for principle in self.principles:
compliance[principle] = input(f"Does the practice '{practice}' comply with the principle of {principle}? (yes/no): ")
return compliance
# 使用示例
framework = DataEthicsFramework()
evaluation = framework.evaluate_data_practice("使用机器学习算法进行信用评分")
print(evaluation)
3.2 隐私保护技术

实施技术措施来保护用户隐私。
import hashlib
def anonymize_data(df, columns_to_anonymize):
for column in columns_to_anonymize:
df[column] = df[column].apply(lambda x: hashlib.sha256(str(x).encode()).hexdigest())
return df
# 使用示例
df = pd.DataFrame({
'user_id': [1, 2, 3],
'name': ['Alice', 'Bob', 'Charlie'],
'email': ['alice@example.com', 'bob@example.com', 'charlie@example.com']
})
anonymized_df = anonymize_data(df, ['name', 'email'])
print(anonymized_df)
4. 高级数据驱动技术
随着技术的发展,更多高级的数据驱动技术正在被应用到决策中。
4.1 机器学习辅助决策

使用机器学习模型来辅助决策过程。
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
def ml_assisted_decision(X, y):
# 分割数据
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 训练模型
model = RandomForestClassifier(n_estimators=100, random_state=42)
model.fit(X_train, y_train)
# 评估模型
y_pred = model.predict(X_test)
accuracy = accuracy_score(y_test, y_pred)
print(f"Model Accuracy: {accuracy}")
# 使用模型进行预测
new_data = X_test.iloc[0].values.reshape(1, -1) # 使用测试集的第一个样本作为新数据
prediction = model.predict(new_data)
return f"For the given input, the model recommends: {'Approve' if prediction[0] == 1 else 'Reject'}"
# 使用示例(假设我们有一个贷款申请的数据集)
X = pd.DataFrame({
'income': [50000, 60000, 75000, 45000, 80000],
'credit_score': [700, 750, 800, 650, 780],
'debt_to_income_ratio': [0.3, 0.25, 0.2, 0.35, 0.22]
})
y = pd.Series([1, 1, 1, 0, 1]) # 1表示批准,0表示拒绝
result = ml_assisted_decision(X, y)
print(result)
4.2 A/B测试和实验设计
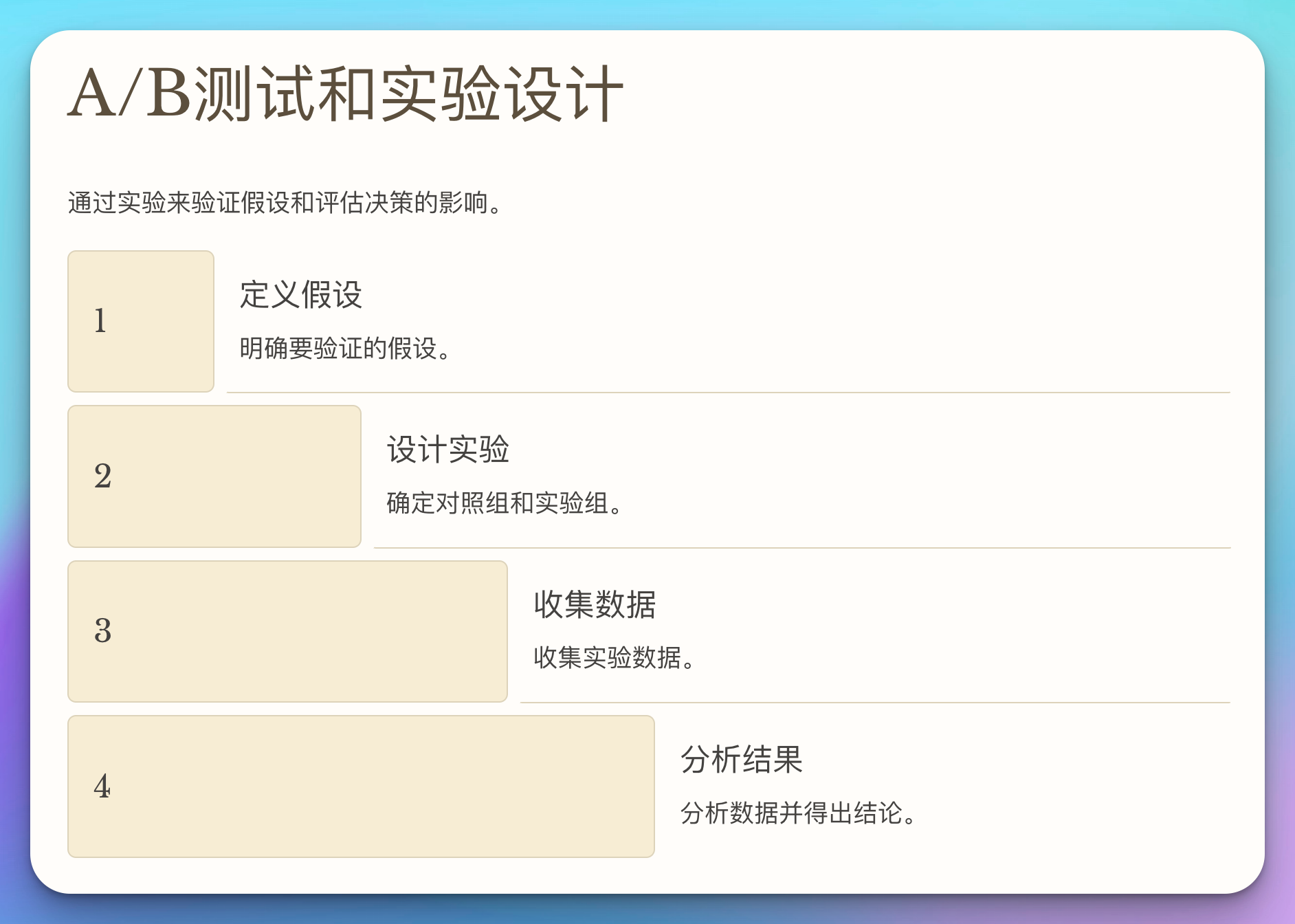
通过实验来验证假设和评估决策的影响。
import numpy as np
from scipy import stats
def ab_test(control_data, experiment_data, confidence_level=0.95):
# 计算t统计量和p值
t_stat, p_value = stats.ttest_ind(control_data, experiment_data)
# 计算效应量 (Cohen's d)
cohens_d = (np.mean(experiment_data) - np.mean(control_data)) / np.sqrt((np.std(control_data, ddof=1) ** 2 + np.std(experiment_data, ddof=1) ** 2) / 2)
# 确定结果
if p_value < (1 - confidence_level):
result = "实验组显著优于对照组" if cohens_d > 0 else "对照组显著优于实验组"
else:
result = "没有发现显著差异"
return {
"t_statistic": t_stat,
"p_value": p_value,
"effect_size": cohens_d,
"result": result
}
# 使用示例
control_data = np.random.normal(10, 2, 1000) # 对照组数据
experiment_data = np.random.normal(10.5, 2, 1000) # 实验组数据
test_result = ab_test(control_data, experiment_data)
print(test_result)
5. 案例研究:Netflix的数据驱动决策

让我们通过一个真实的案例来看看数据驱动决策如何在实践中应用。
Netflix是数据驱动决策的典范之一。他们在多个方面使用数据来指导决策:
- 内容制作:使用数据来决定制作什么样的内容
- 个性化推荐:基于用户行为数据提供个性化的内容推荐
- 用户界面优化:通过A/B测试不断优化用户界面
以下是一个简化的示例,展示Netflix如何使用数据来决定是否为某个系列制作新一季:
import pandas as pd
import matplotlib.pyplot as plt
def analyze_show_performance(show_data):
# 计算关键指标
total_views = show_data['views'].sum()
completion_rate = show_data['completed'].mean()
viewer_rating = show_data['rating'].mean()
# 可视化观看趋势
plt.figure(figsize=(10, 6))
plt.plot(show_data['episode'], show_data['views'])
plt.title('Views per Episode')
plt.xlabel('Episode')
plt.ylabel('Views')
plt.show()
# 决策逻辑
if total_views > 1000000 and completion_rate > 0.7 and viewer_rating > 4:
decision = "Renew for another season"
elif total_views > 500000 and completion_rate > 0.5 and viewer_rating > 3.5:
decision = "Consider renewal, need further analysis"
else:
decision = "Do not renew"
return {
"total_views": total_views,
"completion_rate": completion_rate,
"viewer_rating": viewer_rating,
"decision": decision
}
# 模拟数据
show_data = pd.DataFrame({
'episode': range(1, 11),
'views': [900000, 850000, 800000, 750000, 700000, 720000, 680000, 660000, 640000, 620000],
'completed': [0.95, 0.9, 0.85, 0.8, 0.75, 0.78, 0.72, 0.7, 0.68, 0.65],
'rating': [4.5, 4.4, 4.3, 4.2, 4.1, 4.2, 4.0, 3.9, 3.8, 3.7]
})
result = analyze_show_performance(show_data)
print(result)
这个简化的例子展示了Netflix如何利用多个数据点(总观看量、完成率、观众评分)来做出续订决定。在实际情况中,他们会考虑更多的因素,如成本、同类节目的表现、市场趋势等。
6. 未来趋势

随着技术的不断发展,数据驱动决策的未来充满了可能性。以下是一些值得关注的趋势:
- 自动化决策:利用AI技术实现某些决策的自动化
- 增强分析:结合人工智能和人类智慧,提供更深入的洞察
- 实时决策:利用流处理技术实现实时的数据分析和决策
- 边缘计算:在数据源头进行处理和分析,实现更快的响应
- 可解释的AI:开发能够解释其决策过程的AI模型,增加透明度
def future_trends_impact(trend, current_practices):
impact_areas = {
"自动化决策": ["效率提升", "人为错误减少", "决策一致性提高"],
"增强分析": ["洞察深度增加", "决策质量提升", "创新能力增强"],
"实时决策": ["反应速度提高", "机会把握能力增强", "风险管理改善"],
"边缘计算": ["数据处理速度提高", "隐私保护增强", "网络带宽压力减少"],
"可解释的AI": ["决策透明度提高", "合规性增强", "用户信任度提升"]
}
if trend in impact_areas:
print(f"{trend}对当前实践的潜在影响:")
for impact in impact_areas[trend]:
print(f"- {impact}")
print("\n需要采取的行动:")
for practice in current_practices:
print(f"- 评估{trend}对'{practice}'的影响并制定相应策略")
else:
print(f"未找到'{trend}'的影响信息")
# 使用示例
current_practices = ["每周销售预测", "客户流失预警", "产品推荐系统"]
future_trends_impact("实时决策", current_practices)
7. 构建数据驱动组织的路线图

将组织转变为真正的数据驱动型企业是一个渐进的过程。以下是一个可能的路线图:
- 评估当前状态
- 建立数据基础设施
- 培养数据文化
- 实施数据驱动项目
- 持续优化和创新
class DataDrivenTransformation:
def __init__(self, organization_name):
self.organization = organization_name
self.stages = [
"评估当前状态",
"建立数据基础设施",
"培养数据文化",
"实施数据驱动项目",
"持续优化和创新"
]
self.current_stage = 0
def assess_readiness(self):
questions = [
"我们是否有清晰的数据战略?",
"我们的数据基础设施是否足够支持数据驱动决策?",
"我们的员工是否具备必要的数据素养?",
"我们的决策过程中是否常规性地使用数据?",
"我们是否有机制来评估和改进我们的数据实践?"
]
score = 0
for question in questions:
response = input(f"{question} (是/否): ")
if response.lower() == '是':
score += 1
readiness = (score / len(questions)) * 100
print(f"{self.organization}的数据驱动就绪度: {readiness}%")
return readiness
def next_step(self):
if self.current_stage < len(self.stages):
next_stage = self.stages[self.current_stage]
print(f"{self.organization}的下一步是: {next_stage}")
self.current_stage += 1
else:
print(f"{self.organization}已经完成了转型路线图。下一步是持续优化和创新。")
# 使用示例
transformation = DataDrivenTransformation("科技创新有限公司")
readiness = transformation.assess_readiness()
if readiness < 60:
print("建议先focus on提高数据驱动就绪度")
else:
transformation.next_step()
8. 挑战与解决策略

在实施数据驱动决策的过程中,组织可能会面临各种挑战。以下是一些常见的挑战及可能的解决策略:
-
数据质量问题
- 策略:实施严格的数据治理政策,使用自动化工具进行数据验证
-
技能缺口
- 策略:投资员工培训,建立数据科学团队,考虑外部合作
-
文化阻力
- 策略:从高层开始推动变革,展示早期成功案例,逐步改变决策流程
-
技术限制
- 策略:评估并升级技术基础设施,考虑云计算解决方案
-
隐私和合规问题
- 策略:建立强大的数据伦理框架,遵守相关法规,增强数据安全措施
def challenge_solution_matcher(challenge):
solutions = {
"数据质量问题": [
"实施数据质量监控系统",
"建立数据清洗流程",
"定期进行数据审计"
],
"技能缺口": [
"制定数据素养培训计划",
"招聘数据专家",
"与大学或培训机构合作"
],
"文化阻力": [
"高管进行数据驱动决策背书",
"建立数据驱动决策的激励机制",
"展示数据驱动成功案例"
],
"技术限制": [
"评估并升级数据基础设施",
"采用云计算解决方案",
"实施数据集成平台"
],
"隐私和合规问题": [
"制定全面的数据隐私政策",
"进行定期的合规审计",
"实施数据加密和访问控制"
]
}
if challenge in solutions:
print(f"针对'{challenge}'的可能解决策略:")
for solution in solutions[challenge]:
print(f"- {solution}")
else:
print(f"未找到针对'{challenge}'的具体解决策略。建议进行深入分析并制定定制化方案。")
# 使用示例
challenge_solution_matcher("文化阻力")
9. 结语

数据驱动决策不仅仅是一种技术实践,更是一种思维方式和组织文化。它要求我们不断质疑、学习和适应。在这个数据爆炸的时代,成功的组织将是那些能够有效利用数据,并在此基础上做出明智决策的组织。
然而,我们也要记住,数据驱动并不意味着完全依赖数据。人类的直觉、经验和创造力仍然是决策过程中不可或缺的元素。真正的智慧在于知道何时依赖数据,何时信任直觉,以及如何将两者结合以做出最佳决策。
正如作家亚瑟·柯南·道尔在他的夏洛克·福尔摩斯系列中所写:"比简单地拥有信息更重要的,是拥有从中得出正确结论的能力。"在数据时代,这句话依然适用。我们的挑战不仅在于收集和分析数据,更在于如何明智地使用这些数据来推动我们的组织和社会向前发展。
让我们继续探索、学习和创新,用数据的力量来照亮决策的道路,同时不忘保持对人性的理解和尊重。在数据与直觉、科学与艺术之间找到平衡,这将是未来领导者们面临的最大挑战和最大机遇。