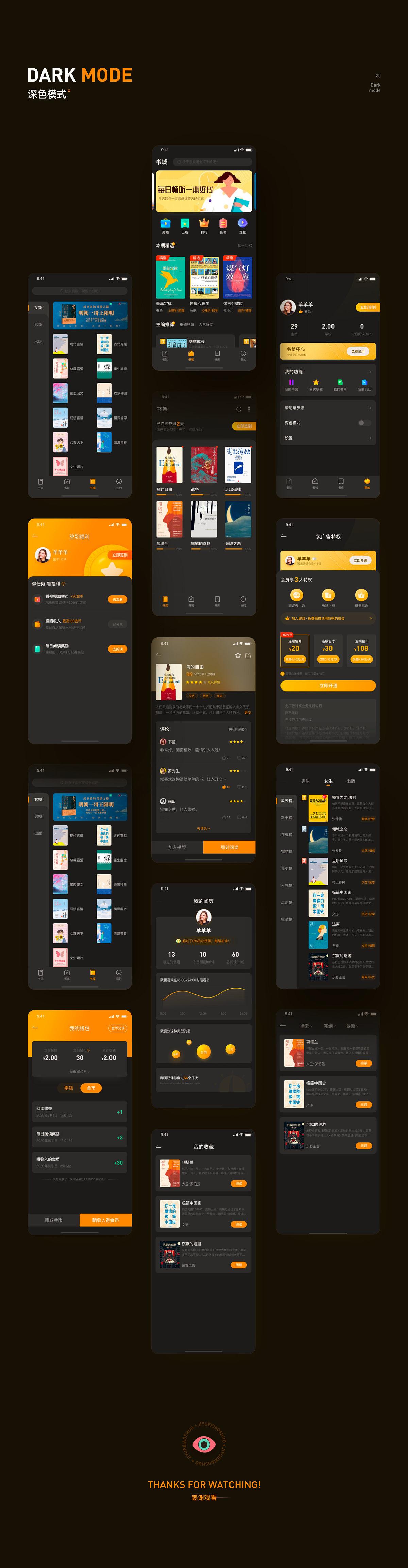
Python大数据分析——DBSCAN聚类模型
- 介绍
- 数学基础
- 模型步骤
- 函数
- 密度聚类对比Kmeans聚类
- 球形簇聚类情况
- 非球形簇的情况
- 示例
介绍
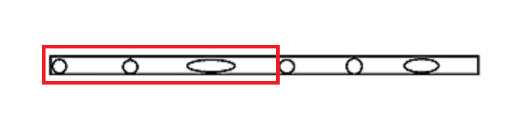
Kmeans聚类存在两个致命缺点,一是聚类效果容易受到异常样本点的影响(因为求的是均值,而异常值对于均值聚类非常容易受到异常点影响);二是该算法无法准确地将非球形样本进行合理的聚类。
基于密度的聚类则可以解决非球形簇的问题,“密度”可以理解为样本点的紧密程度,如果在指定的半径领域内,实际样本量超过给定的最小样本量阈值,则认为是密度高的对象,就可以聚成一个簇。
数学基础
对于几个数学概念我们做下讲解:

直接密度可达:是在领域内的点到中心点;
密度可达:是各个领域的中心点,也就是核心点直接的距离;
举例说明:

除此之外还有四点数学概念:

举例说明:


模型步骤
- 为密度聚类算法设置一个合理的半径c以及ε领域内所包含的最少样本量MinPts。
- 从数据集中随机挑选一个样本点p,检验其在ε领域内是否包含指定的最少样本量,如果包含就将其定性为核心对象,并构成一个簇C;否则,重新挑选一个样本点。
- 对于核心对象p所覆盖的其他样本点q,如果点q对应的ε领域内仍然包含最少样本量MinPts,就将其覆盖的样本点统统归于簇C。
- 重复步骤(3),将最大的密度相连所包含的样本点聚为一类,形成一个大簇。
- 完成步骤(4)后,重新回到步骤(2),并重复步骤(3)和(4),直到没有新的样本点可以生成新簇时算法结束。
这个模型的缺点就是我们需要靠经验得到合理半径c,而无其他办法。
函数
cluster.DBSCAN(eps=0.5, min_samples=5, metric=‘euclidean’, p=None)
eps:用于设置密度聚类中的e领域,即半径,默认为0.5
min_samples:用于设置e领域内最少的样本量,默认为5
metric:用于指定计算点之间距离的方法,默认为欧氏距离
p:当参数metric为闵可夫斯基(‘minkowski’)距离时,p=1,表示计算点之间的曼哈顿距离;p=2,表示计算点之间的欧氏距离;该参数的默认值为2
密度聚类对比Kmeans聚类
球形簇聚类情况
Kmeans聚类效果:

密度聚类效果:

我们发现密度聚类能排除这个异常值点,说明效果更好。
非球形簇的情况
Kmeans聚类效果:

密度聚类效果:

发现非球形要用密度聚类
示例
- 导入功能包
# 导入第三方模块
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn import cluster
注:
在最新的sklearn版本中导入模块from sklearn.datasets.samples_generator import make_blobs时报错:ModuleNotFoundError: No module named ‘sklearn.datasets.samples_generator’,因为已经删除samples_generator了,我们需要改为from sklearn.datasets import make_blobs
- 读取数据,查看分布
# 读取外部数据
Province = pd.read_excel(r'D:\pythonProject\data\Province.xlsx')
Province.head()
# 绘制出生率与死亡率散点图
plt.scatter(Province.Birth_Rate, Province.Death_Rate, c = 'steelblue')
# 添加轴标签
plt.xlabel('Birth_Rate')
plt.ylabel('Death_Rate')
# 显示图形
plt.show()

- 数据处理
首先进行标准化处理(对于量纲不一致的必须需要进行标准化处理,但这里都是百分比其实可以不做的):
# 读入第三方包
from sklearn import preprocessing
# 选取建模的变量
predictors = ['Birth_Rate','Death_Rate']
# 变量的标准化处理
X = preprocessing.scale(Province[predictors])
X = pd.DataFrame(X)
再循环迭代ε,也就是eps,对每一次组合进行一次聚类,从而寻找最佳组合:
# 构建空列表,用于保存不同参数组合下的结果
res = []
# 迭代不同的eps值
for eps in np.arange(0.001,1,0.05):
# 迭代不同的min_samples值
for min_samples in range(2,10):
dbscan = cluster.DBSCAN(eps = eps, min_samples = min_samples)
# 模型拟合
dbscan.fit(X)
# 统计各参数组合下的聚类个数(-1表示异常点)
n_clusters = len([i for i in set(dbscan.labels_) if i != -1])
# 异常点的个数
outliners = np.sum(np.where(dbscan.labels_ == -1, 1,0))
# 统计每个簇的样本个数
stats = str(pd.Series([i for i in dbscan.labels_ if i != -1]).value_counts().values)
res.append({'eps':eps,'min_samples':min_samples,'n_clusters':n_clusters,'outliners':outliners,'stats':stats})
# 将迭代后的结果存储到数据框中
df = pd.DataFrame(res)
df

其中eps是ε也就是范围;min_simples指定的最小样本量;n_clusters形成的簇的数量;outliners形成的异常点的个数;stats一个簇的里面的样本个数
我们根据经验:簇类均匀,不要让异常点过多,也就是综合平均选择参数。我们挑选到3可能是适合的
# 根据条件筛选合理的参数组合
df.loc[df.n_clusters == 3, :]

通过发现每个簇的样本数量不要差异太大,发现0.801是合适的,也就是[17 7 3]
- 结果分类
通过上面分析的数据得到的我们认为可靠的参数值,来拟合分析分类
# 中文乱码和坐标轴负号的处理
plt.rcParams['font.sans-serif'] = ['Microsoft YaHei']
plt.rcParams['axes.unicode_minus'] = False
# 利用上述的参数组合值,重建密度聚类算法
dbscan = cluster.DBSCAN(eps = 0.801, min_samples = 3)
# 模型拟合
dbscan.fit(X)
Province['dbscan_label'] = dbscan.labels_
# 绘制聚类聚类的效果散点图
sns.lmplot(x = 'Birth_Rate', y = 'Death_Rate', hue = 'dbscan_label', data = Province,
markers = ['*','d','^','o'], fit_reg = False, legend = False)
# 添加省份标签
for x,y,text in zip(Province.Birth_Rate,Province.Death_Rate, Province.Province):
plt.text(x+0.1,y-0.1,text, size = 8)
# 添加参考线
plt.hlines(y = 5.8, xmin = Province.Birth_Rate.min(), xmax = Province.Birth_Rate.max(),
linestyles = '--', colors = 'red')
plt.vlines(x = 10, ymin = Province.Death_Rate.min(), ymax = Province.Death_Rate.max(),
linestyles = '--', colors = 'red')
# 添加轴标签
plt.xlabel('Birth_Rate')
plt.ylabel('Death_Rate')
# 显示图形
plt.show()

五角星代表的是四个异常值,其余的分布为类别
我们可以对比下Kmeans聚类来分析下(这里面采用的是轮廓系数法):
- 首先轮廓系数法分析
# 导入第三方模块
from sklearn import metrics
# 构造自定义函数,用于绘制不同k值和对应轮廓系数的折线图
def k_silhouette(X, clusters):
K = range(2,clusters+1)
# 构建空列表,用于存储个中簇数下的轮廓系数
S = []
for k in K:
kmeans = cluster.KMeans(n_clusters=k)
kmeans.fit(X)
labels = kmeans.labels_
# 调用字模块metrics中的silhouette_score函数,计算轮廓系数
S.append(metrics.silhouette_score(X, labels, metric='euclidean'))
# 中文和负号的正常显示
plt.rcParams['font.sans-serif'] = ['Microsoft YaHei']
plt.rcParams['axes.unicode_minus'] = False
# 设置绘图风格
plt.style.use('ggplot')
# 绘制K的个数与轮廓系数的关系
plt.plot(K, S, 'b*-')
plt.xlabel('簇的个数')
plt.ylabel('轮廓系数')
# 显示图形
plt.show()
# 聚类个数的探索
k_silhouette(X, clusters = 10)

发现类别数为3是合适的
- 利用Kmeans聚类分析
通过得到的K值,来拟合分析,查看聚类效果:
# 利用Kmeans聚类
kmeans = cluster.KMeans(n_clusters = 3)
# 模型拟合
kmeans.fit(X)
Province['kmeans_label'] = kmeans.labels_
# 绘制Kmeans聚类的效果散点图
sns.lmplot(x = 'Birth_Rate', y = 'Death_Rate', hue = 'kmeans_label', data = Province,
markers = ['d','^','o'], fit_reg = False, legend = False)
# 添加轴标签
plt.xlabel('Birth_Rate')
plt.ylabel('Death_Rate')
plt.show()

所不同的是,有无异常点和这些点的归属问题