专注于计算机图形学的全球学术顶会 SIGGRAPH,正在出现新的趋势。
点击访问我的技术博客https://ai.weoknow.com![]() https://ai.weoknow.com
https://ai.weoknow.com
在上周举行的 SIGGRAPH 2024 大会上,最佳论文等奖项中,来自上海科技大学 MARS 实验室的团队同时拿到两篇最佳论文荣誉提名,其研究成果亦在快速走向产业化。
作者使用生成模型的方法,开启了将想象力直接转化为复杂 3D 模型的新路。

拿到最佳论文提名的两篇论文——CLAY 和 DressCode,二者的主题分别是 3D 生成和 3D 服装生成。
在 SIGGARPH 的 Real-Time Live 环节,上科大这一团队更实时展示了基于这两项工作的一系列应用场景。
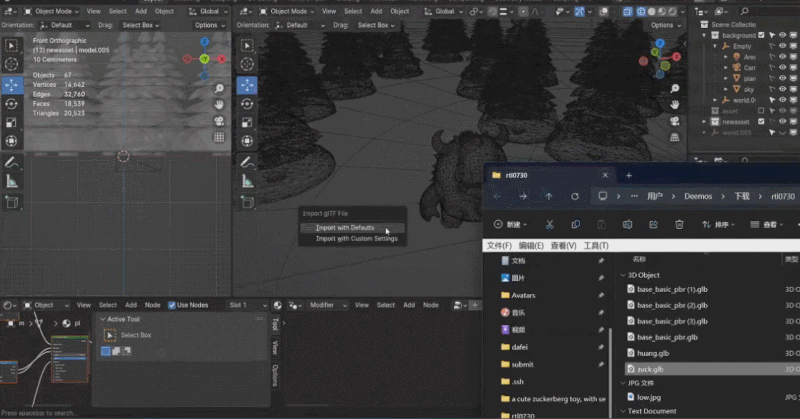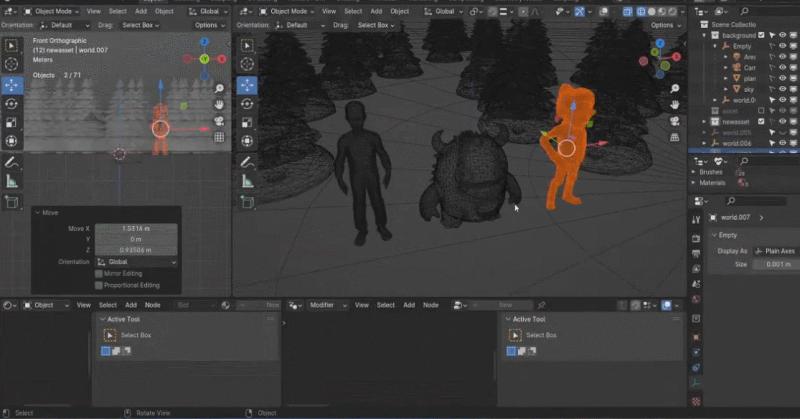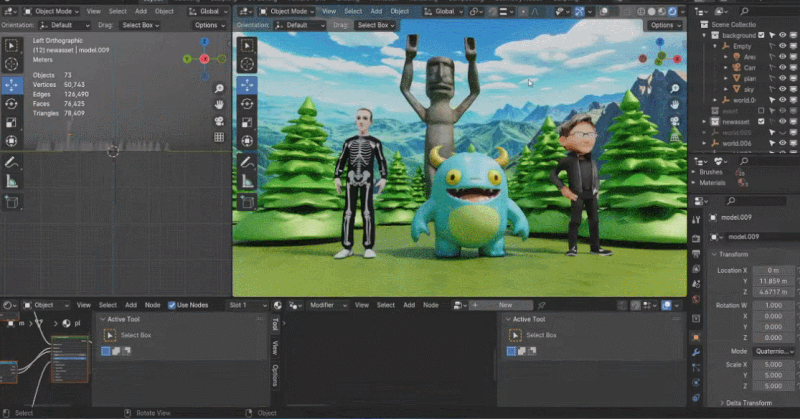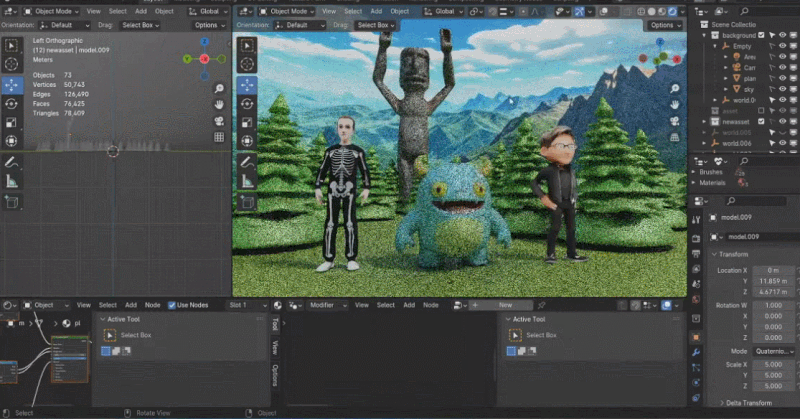
论文作者,研究生二年级学生,同时也是初创公司影眸科技的 CTO 张启煊首先演示了基于 CLAY 的 3D 生成解决方案。影眸团队去年用简单的文字提示词(Prompt)给扎克伯格和黄仁勋构建了真实风格的 3D 模型,成为第一个登上 SIGGRAPH Real-Time Live 的中国团队。今年他们的 3D 生成方案,通过单张图片作为输入,可以生成出小扎和老黄不同风格的卡通形象。
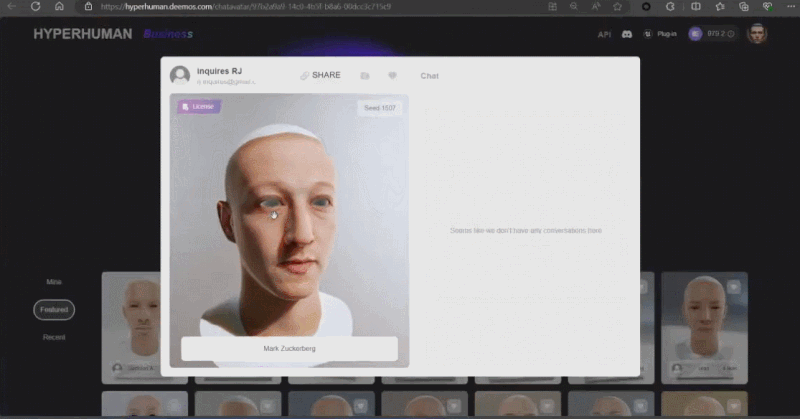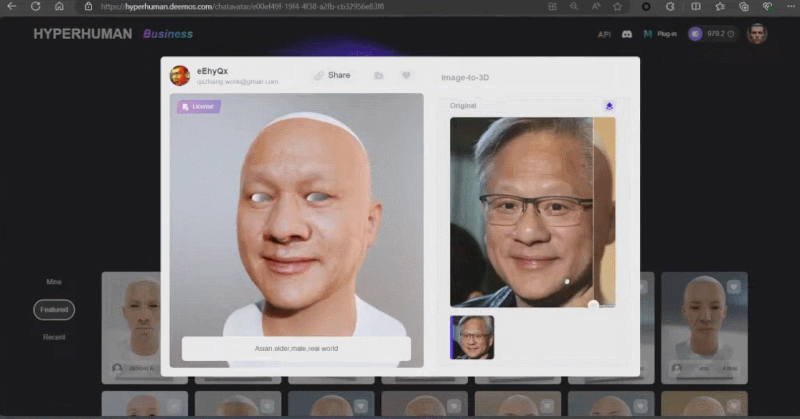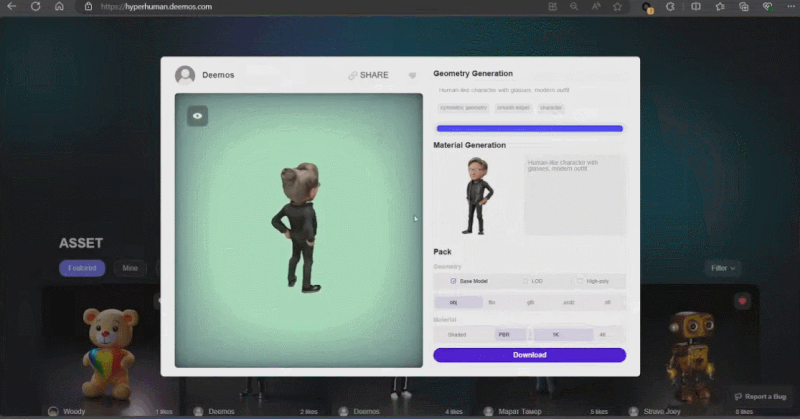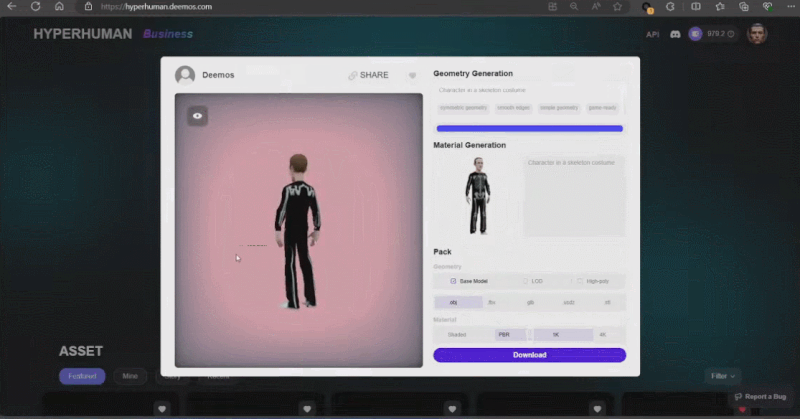
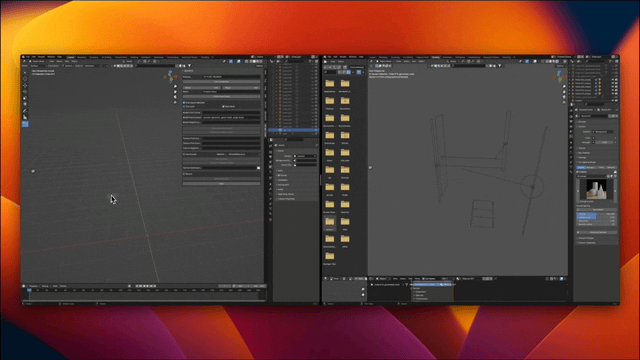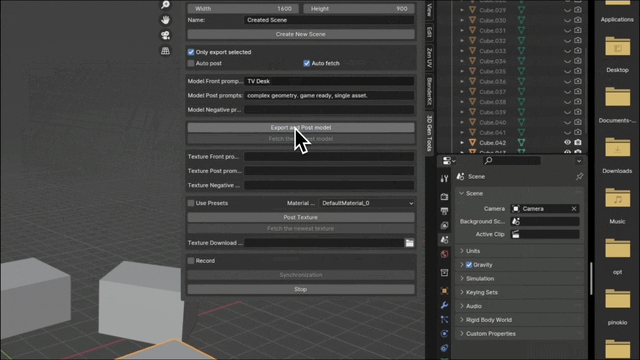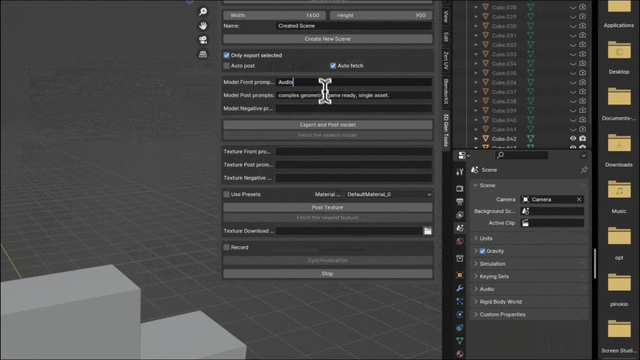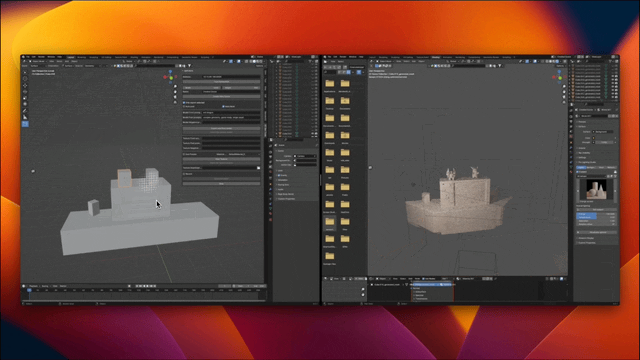
这些生成内容的背后是新一代 3D AI 引擎 Rodin,致敬著名雕塑家罗丹。现场展示的 3D 内容都是由用户上传的单张图片直接生成的,Rodin 可以进一步生成 PBR 纹理和四角面,以方便艺术家进一步修改和使用。
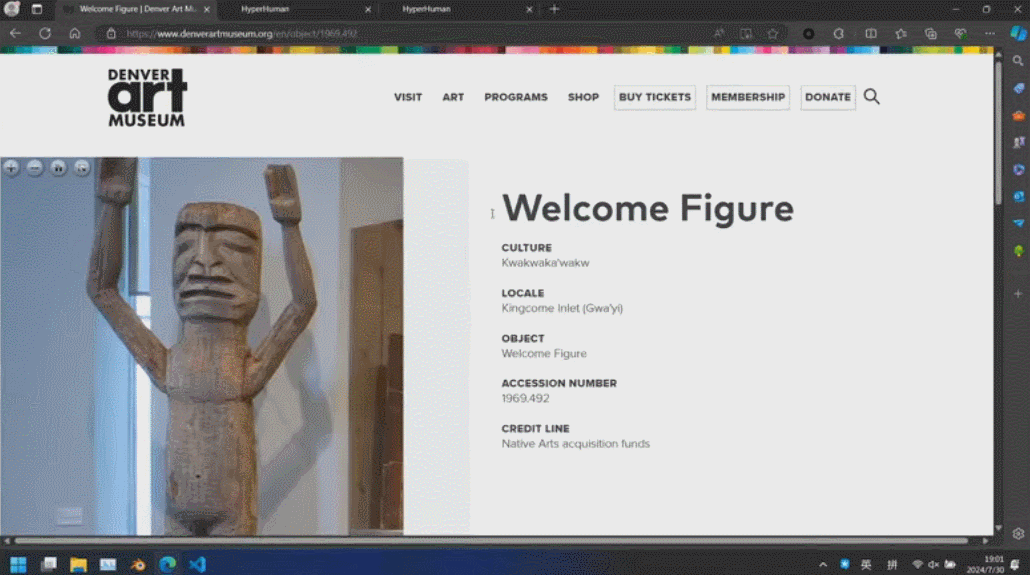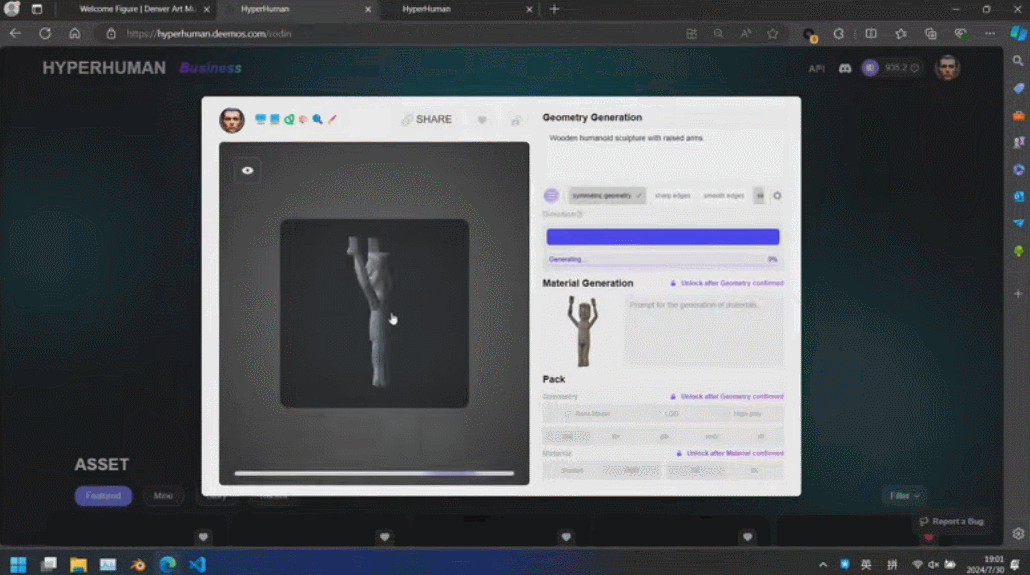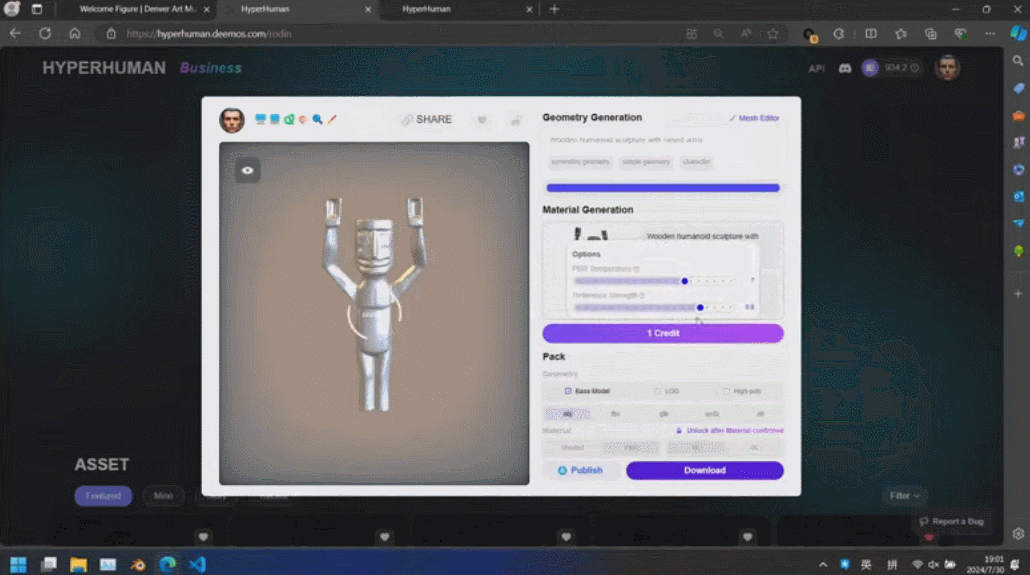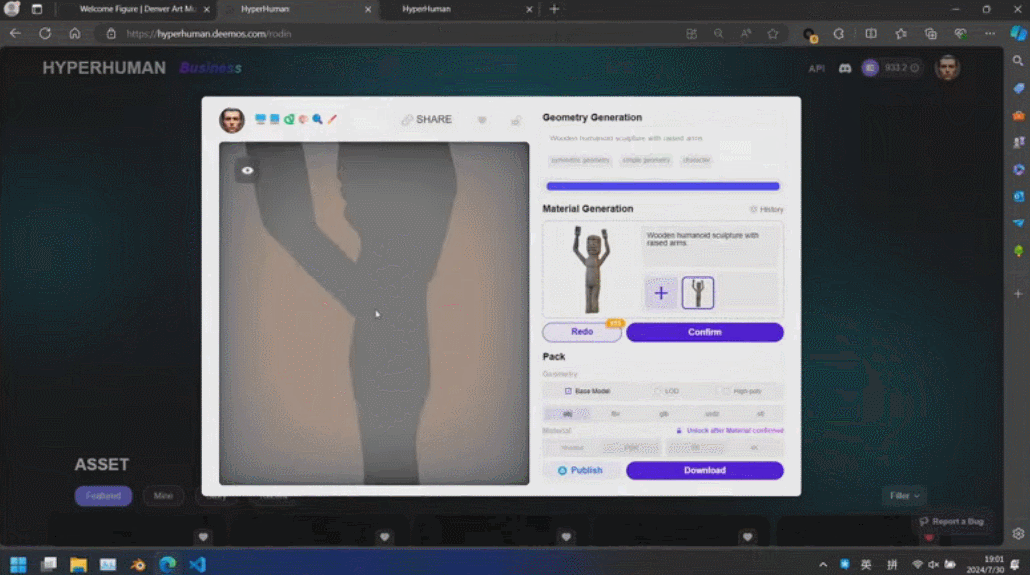
通过 3D ControlNet,Rodin 可以控制 AI 生成的形状。仅需提供简单的几何元素作为指导,就可以将其转换为体素,并根据参考图片的语义信息将其转换为所需要的 3D 资产。
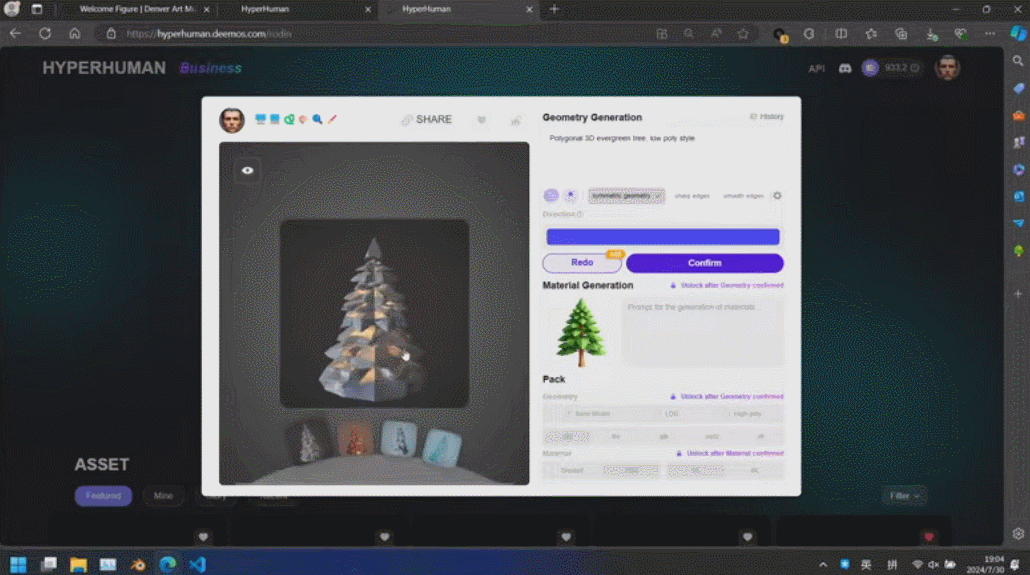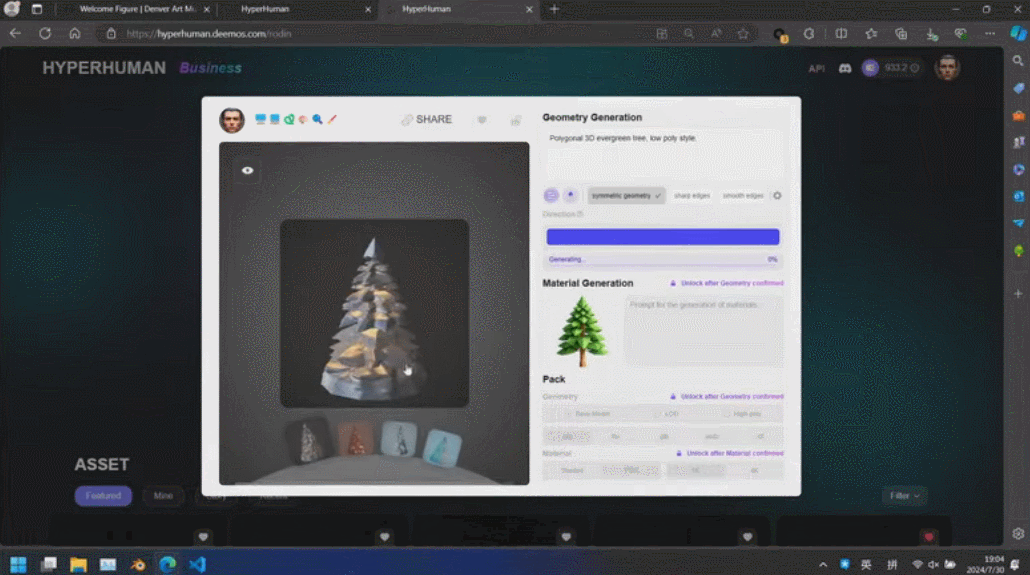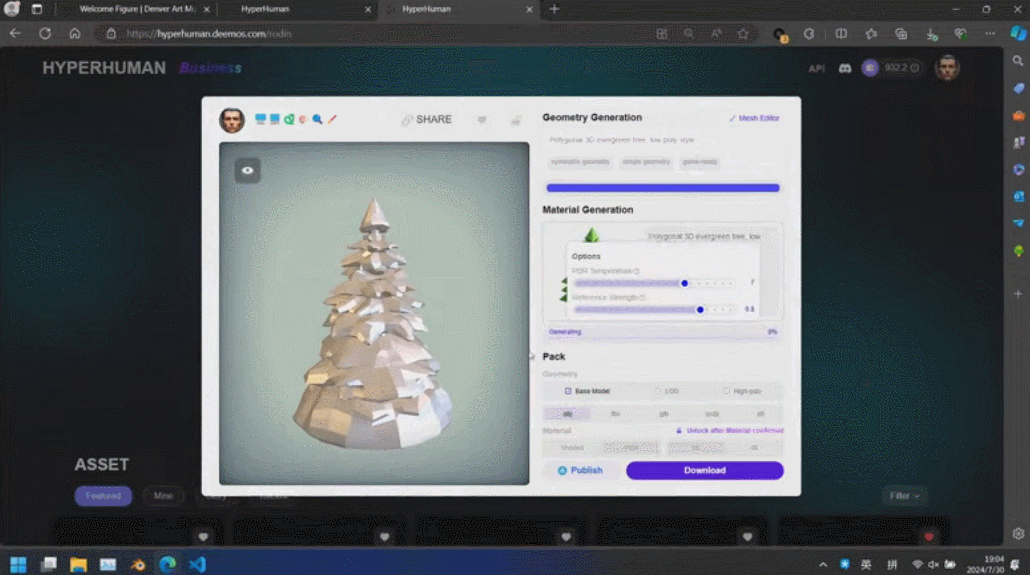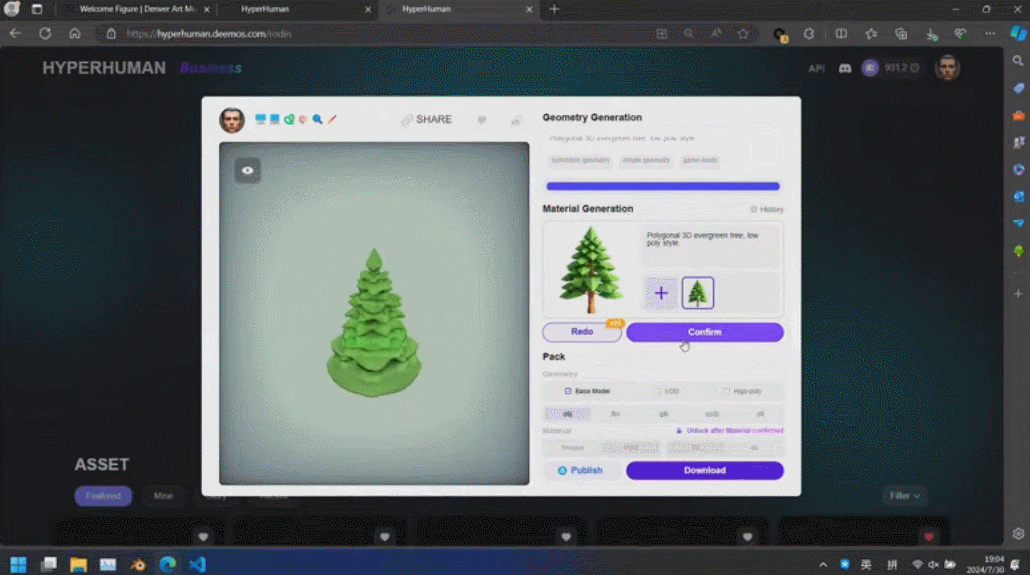
Rodin 也支持直接手绘的图片,甚至是简单涂鸦。几张照片生成 3D 人物,儿童涂鸦生成树木作为背景,开发人员现场实时操作,一分钟内便搭建了一个完整的 3D 建模的场景。当主持人问到中间的小怪物是谁时,张启煊风趣的说,这就是 AI。
说起来,3D 模型生成的上一次出圈其实也是在 SIGGRAPH 上:在 2021 年,英伟达在这个舞台上介绍了给黄仁勋制作 3D 模型的方法,以假乱真的效果震撼了世界。
彼时的 3D 模型生成被认为对于数字人、虚拟现实等技术而言至关重要。但毫无疑问,高精度人体扫描 + 深度学习重建方式的高成本,决定了它注定不会成为投入大规模生产的方式。
使用 AI 生成或许才是更好的路径。然而此前在这个方向上,人们提出的技术一直「叫好不叫座」。
对实际应用而言,这些方法存在一些挑战:3D 是一个工业问题,模型仅仅在视觉上表现好是不够的,还需要符合特定的工业标准,比如材质如何表现,面片规划、结构如何合理。如果不能和人类工业标准对齐,那生成结果就需要大量调整,难以应用于生产端。
就像大语言模型(LLM)需要对齐人类的价值观,3D 生成的 AI 模型需要对齐复杂的 3D 工业标准。
更实用的方案已经出现:3D 原生
上科大 MARS 实验室获得最佳论文提名的工作之一——CLAY 让行业看到了上述问题的一个可行的解决思路,即 3D 原生。
我们知道,最近两年,3D 生成的技术路线大致可以分为两类:2D 升维和原生 3D。
2D 升维是通过 2D 扩散模型,结合 NeRF 等方法实现三维重建的过程。由于可以利用大量的 2D 图像数据进行训练,这类模型往往能够生成多样化的结果。但又因为 2D 扩散模型的 3D 先验能力不足,这类模型对 3D 世界的理解能力有限,容易生成几何结构不合理的结果(比如有多个头的人或动物)。

近期的一系列多视角重建工作通过把 3D 资产的多视角 2D 图像加入 2D 扩散模型的训练数据,在一定程度上缓解了这一问题。但局限性在于,这类方法的起点是 2D 图像,因此它们关注的都是生成图像的质量,而不是试图保持几何保真度,所以生成的几何图形经常存在不完整和缺乏细节的问题。
换句话说,2D 数据终究只记录了真实世界的一个侧面,或者说投影,再多角度的图像也无法完整描述一个三维内容,因此模型学到的东西依旧存在很多信息缺失,生成结果还是需要大量修正,难以满足工业标准。
考虑到这些局限,CLAY 的研究团队选择了另一条路 ——3D 原生。
这一路线直接从 3D 数据集训练生成模型,从各种 3D 几何形状中提取丰富的 3D 先验。因此,模型可以更好地「理解」并保留几何特征。
不过,这类模型也要足够大才能「涌现」出强大的生成能力,而更大的模型需要在更大的数据集上进行训练。众所周知,高质量的 3D 数据集是非常稀缺且昂贵的,这是原生 3D 路线首先要解决的问题。
在 CLAY 这篇论文中,研究者采用定制的数据处理流程来挖掘多种 3D 数据集,并提出了有效的技术来扩展(scale up)生成模型。
具体来说,他们的数据处理流程从一个定制的网格重构(remeshing)算法开始,将 3D 数据转换为水密性网格(watertight meshes),细致地保留了诸如硬边和平整表面等重要几何特征。此外,他们还利用 GPT-4V 创建了细致的标注,突出显示重要的几何特性。
众多数据集经过上述处理流程后,汇成了 CLAY 模型训练所使用的超大型 3D 模型数据集。此前,由于格式不同,缺乏一致性,这些数据集从来没有一起用于训练 3D 生成模型。处理后的组合数据集保持了一致的表示和连贯的注释,可以极大地提高生成模型的泛化性。
利用该数据集训练出的 CLAY 包含一个参数量高达 15 亿的 3D 生成模型。为了保证从数据集转化到隐式表达再到输出之间,信息损失尽可能小,他们花了很长时间去筛选、改良,最终探索出了一套全新、高效的 3D 表达方式。具体来说,他们采用了 3DShape2VecSet 中的神经场设计来描述连续完整的表面,并结合了一个特制的多分辨率几何 VAE,用于处理不同分辨率的点云,让它能够自适应隐向量尺寸(latent size)。

为了便于模型的扩展,CLAY 采用了一个极简的潜在扩散 Transformer(DiT)。它由 Transformer 构成,能够自适应隐向量尺寸,具有大模型化能力(scalability)。此外,CLAY 还引入了一种渐进式训练方案,通过逐步增加隐向量尺寸和模型参数来训练。
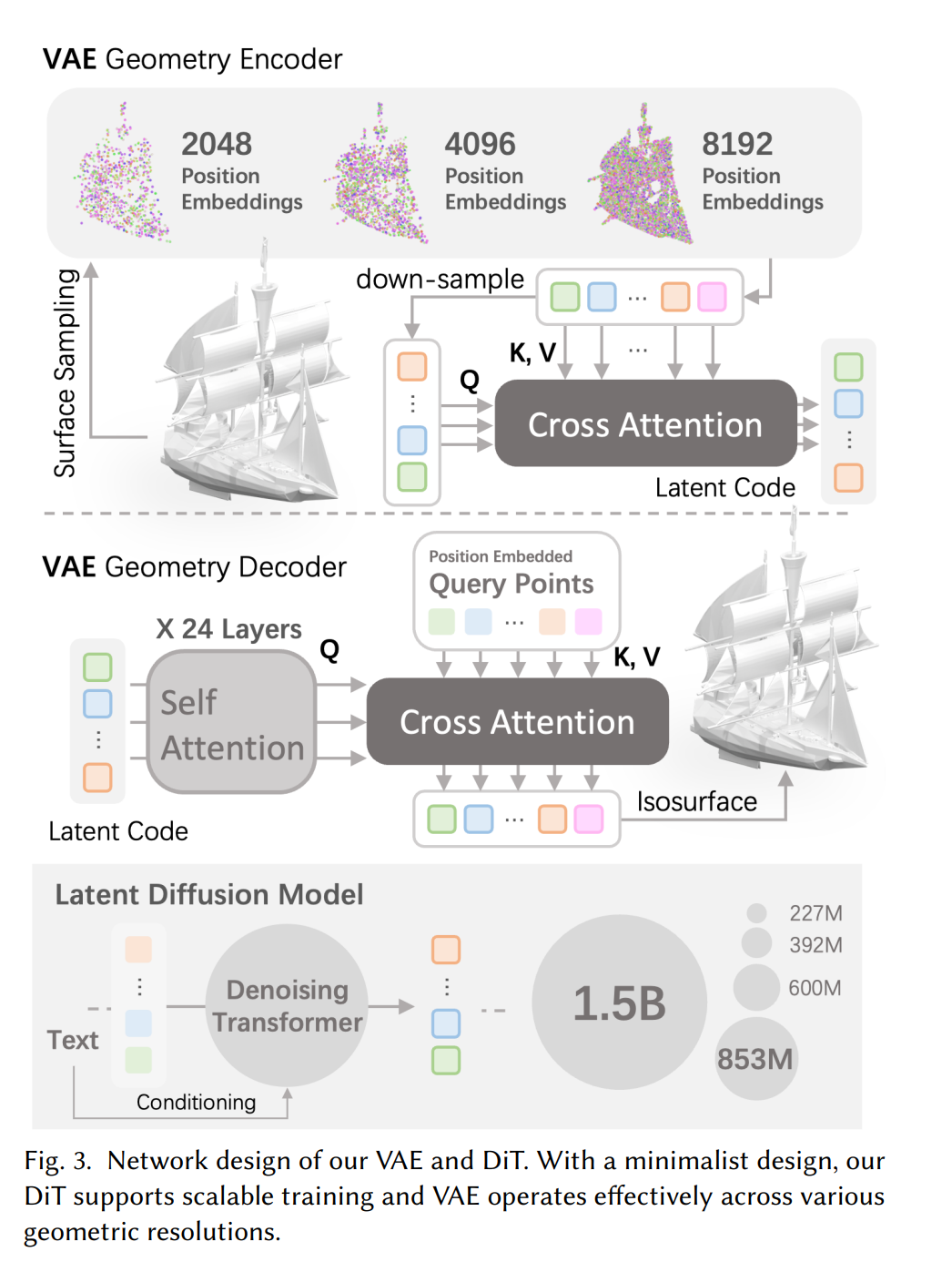
最终,CLAY 实现了对几何的精确控制,使用者可以通过调整提示词控制几何生成的复杂度、风格等(甚至角色)。与以往的方法相比,CLAY 能迅速地生成细致的几何,很好地保证了诸如平整表面和结构完整性等重要几何特征。
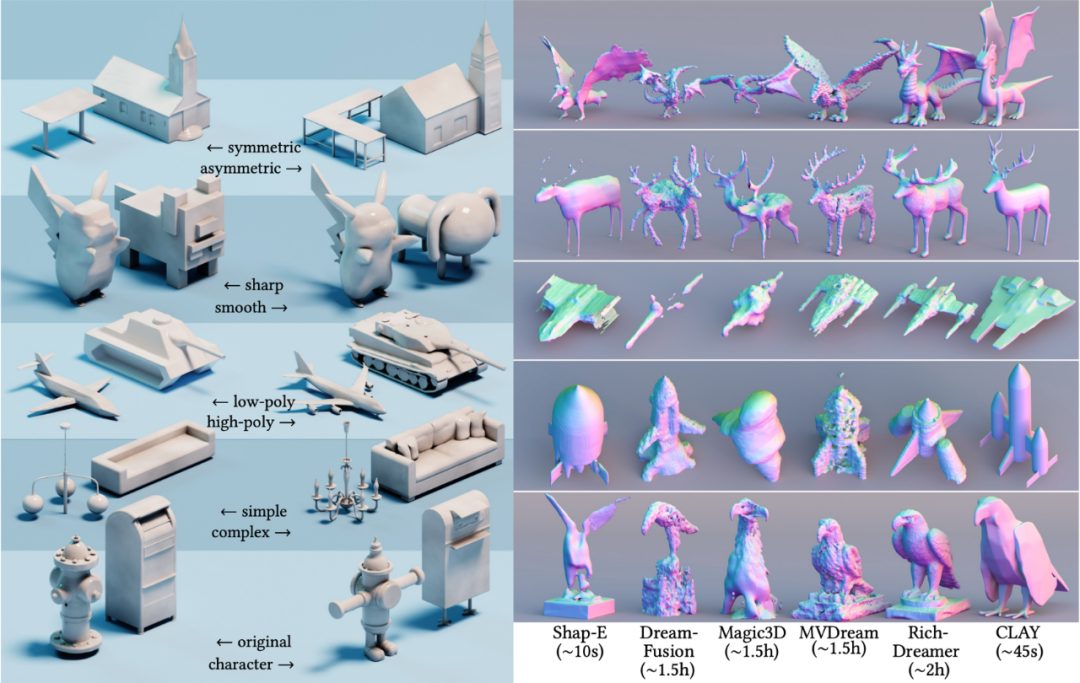
论文中的一些结果充分展示了原生 3D 路径的优势。下图展示了研究者从数据集中检索到的前三个最邻近样本。CLAY 生成的高质量几何体与提示词匹配,但与数据集中的样本有所不同,展现出了足够的丰富度,具备大模型涌现能力的特点。

为了使生成的数字资产能够直接用于现有的 CG 生产管线,研究者进一步采用了一套两阶段方案:
1、几何优化确保结构完整性和兼容性,同时在美观和功能上对模型的形态进行细化,如四边面化、UV 展开等;
2、材质合成通过真实的纹理赋予模型逼真的质感。这些步骤共同将粗糙的网格转变为在数字环境中更可用的资产。
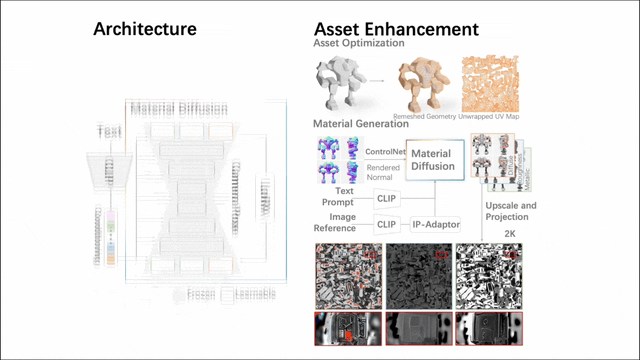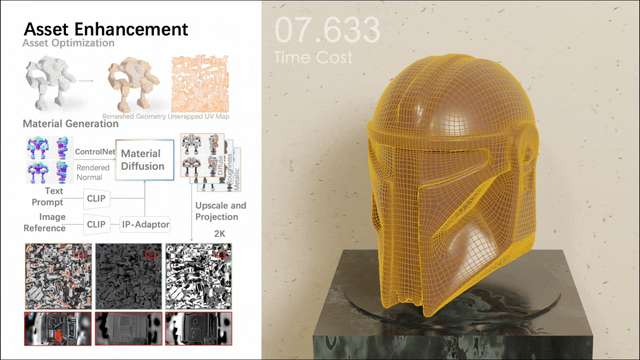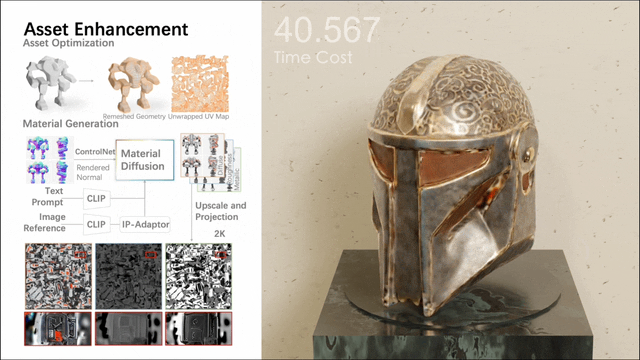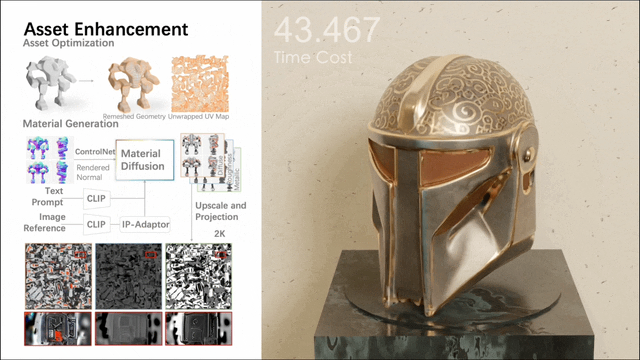
其中,第二个阶段涉及一个近 10 亿参数的多视图材质扩散模型。在进行网格四边面化与 UV 展开之后,它通过多视图方法生成 PBR 材质,随后将其反向投影到 UV maps 上。相比先前的方法,该模型生成的 PBR 材质更加真实,最终实现逼真的渲染效果。

为了让 CLAY 支持更多任务,研究者还设计了 3D 版 ControlNet,极简的架构使它能够高效地支持各种不同模态的条件 (Condition)控制。他们实现了几种用户可以轻松提供的示例条件,包括文本(原生支持),以及图像 / 草图、体素 (Voxel)、多视图图像(Multiview Images)、点云(Point Cloud)、边界框(BoundingBox)和带有边界框的部分点云。这些条件可以单独应用,也可以组合应用,使模型能够基于单一条件忠实生成内容,或结合多种条件创建具有风格和用户控制的 3D 内容,提供广泛的创作可能性。
此外,CLAY 还直接支持在 DiT 的注意力层 (attention layers) 上进行 Low-Rank Adaptation (LoRA)。这允许高效的微调,使生成的 3D 内容能够针对特定风格。

从这些设计不难看出,CLAY 的设计从一开始就瞄准了应用场景,这和一些纯学术研究有很大的不同。
这也让该模型实现了快速落地:目前 Rodin 已经成为很多 3D 开发者的常用 3D 生成器。

可点击阅读原文,访问 Rodin 体验产品(建议 PC 端打开)。
国内外很多行业使用者反馈认为,Rodin 生成的 3D 资产几何科学、布线规则、材质贴图精致,而且可以直接被导入现有的主流渲染引擎,使用起来非常方便,是一款接近 Production-Ready 的 3D 生成应用。
贡献了 CLAY 的上科大 MARS 实验室团队,自 2023 年作为 SIGGRAPH 创立 50 年来首个入选 Real-Time Live 环节的中国团队,已经连续第二年站上这个舞台。

影眸科技在 3D 原生 AI 的道路上探索,构建起了接近 Production-Ready 的 3D 产品,大幅降低了 3D 创造的门槛。
基于 CLAY 的 3D 生成技术不仅指引着业界方向,还将对图像和视频的生成起到积极作用。因为从信息熵的角度来说,你提供的信息越少,模型发挥的空间就越大。而 3D 模型化可以锚定其收敛的方向,提高图像、视频生成的可控性。
不过,3D 领域本身不像图像和视频那么简单,只有补齐完整链条,用户才会真正开始接受 3D + AI 的能力。这部分工作可能通过合作伙伴的 API,或者由其团队自行完成。
期待未来,新技术的进一步落地。
https://ai.weoknow.com









![[Linux] LVM挂载的硬盘重启就掉的问题解决](https://i-blog.csdnimg.cn/direct/6dc1283acc374318b007ad52530699ee.png)








