本文篇幅有限,很难用短短几语就勾勒出DPDK的完整轮廓,概括来说,DPDK是一个技术栈,主要用于Intel架构的服务器领域,其主要目的就是提升x86标准服务器的转发性能。因此,本文只重点介绍DPDK平台部分技术在电信云中的最佳实践。
NFV网络云为什么需要DPDK?
在IA上,网络数据包处理远早于DPDK而存在。从商业版的Windows到开源的Linux操作系统,所有跨主机通信几乎都会涉及网络协议栈以及底层网卡驱动对于数据包的处理。然而,低速网络数据转发与高速网络数据转发的处理对系统的要求完全不一样。以Linux为例,传统网络设备驱动包处理的动作可以概括如下:
- 数据包到达网卡设备。
- 网卡设备依据配置进行DMA操作。
- 网卡发送中断,唤醒处理器。
- 驱动软件填充读写缓冲区数据结构。
- 数据报文达到内核协议栈,进行高层处理。
- 如果最终应用在用户态,数据从内核搬移到用户态。
- 如果最终应用在内核态,在内核继续进行。
随着网络接口带宽从千兆向万兆迈进,原先每个报文就会触发一个中断,中断带来的开销变得突出,大量数据到来会触发频繁的中断开销,导致系统无法承受。
在网络包高性能转发技术领域,有两个著名的技术框架NAPI和Netmap。NAPI策略用于高吞吐的场景,其策略是系统被中断唤醒后,尽量使用轮询的方式一次处理多个数据包,直到网络再次空闲重新转入中断等待,其目的就是解决数据包在转发过程过程中频繁中断引入的大量系统开销。Netmap就是采用共享数据包池的方式,减少内核到用户空间的包复制,从而解决大多数场景下需要把包从内核的缓冲区复制到用户缓冲区引入大量系统开销问题。
NAPI与Netmap两方面的努力其实已经明显改善了传统Linux系统上的包处理能力,但是,Linux作为分时操作系统,要将CPU的执行时间合理地调度给需要运行的任务。相对于公平分时,不可避免的就是适时调度。早些年CPU核数比较少,为了每个任务都得到响应处理,进行充分分时,用效率换响应,是一个理想的策略。现今CPU核数越来越多,性能越来越强,为了追求极端的高性能高效率,分时就不一定总是上佳的策略。以Netmap为例,即便其减少了内核到用户空间的内存复制,但内核驱动的收发包处理和用户态线程依旧由操作系统调度执行,除去任务切换本身的开销,由切换导致的后续cache替换(不同任务内存热点不同),对性能也会产生负面的影响。为此,Intel针对IA架构的这些问题,就提出了DPDK技术栈的架构,其根本目的就是尽量采用用户态驱动能力来替代内核态驱动,从而减少内核态的开销,提升转发性能。
鸟瞰DPDK
什么是DPDK?在《DPDK深入浅出》一书中,有以下一段描述:
针对不同的对象,其定义并不相同。对于普通用户来说,它可能是一个性能出色的包数据处理加速软件库;对于开发者来说,它可能是一个实践包处理新想法的创新工场;对于性能调优者来说,它可能又是一个绝佳的成果分享平台。当下火热的网络功能虚拟化,则将DPDK放在一个重要的基石位置。
DPDK最初的动机很简单,就是为了证明IA多核处理器能够支撑高性能数据包处理。随着早期目标的达成和更多通用处理器体系的加入,DPDK逐渐成为通用多核处理器高性能数据包处理的业界标杆。
目前,DPDK技术主要应用于计算领域的硬件加速器、通信领域的网络处理器和IT领域的多核处理器。随着软件(例如,DPDK)在I/O性能提升上的不断创新,将多核处理器的竞争力提升到一个前所未有的高度。在SDN/NFV领域,DPDK技术得到了空前应用,产生了不少最佳实践案例。

各类处理器
DPDK提出的目的就是为IA上的高速包处理。下图所示的DPDK主要模块分解展示了以基础软件库的形式,为上层应用的开发提供一个高性能的基础I/O开发包。主要利用了有助于包处理的软硬件特性,如大页、缓存行对齐、线程绑定、预取、NUMA、IA最新指令的利用、Intel DDIO、内存交叉访问等。
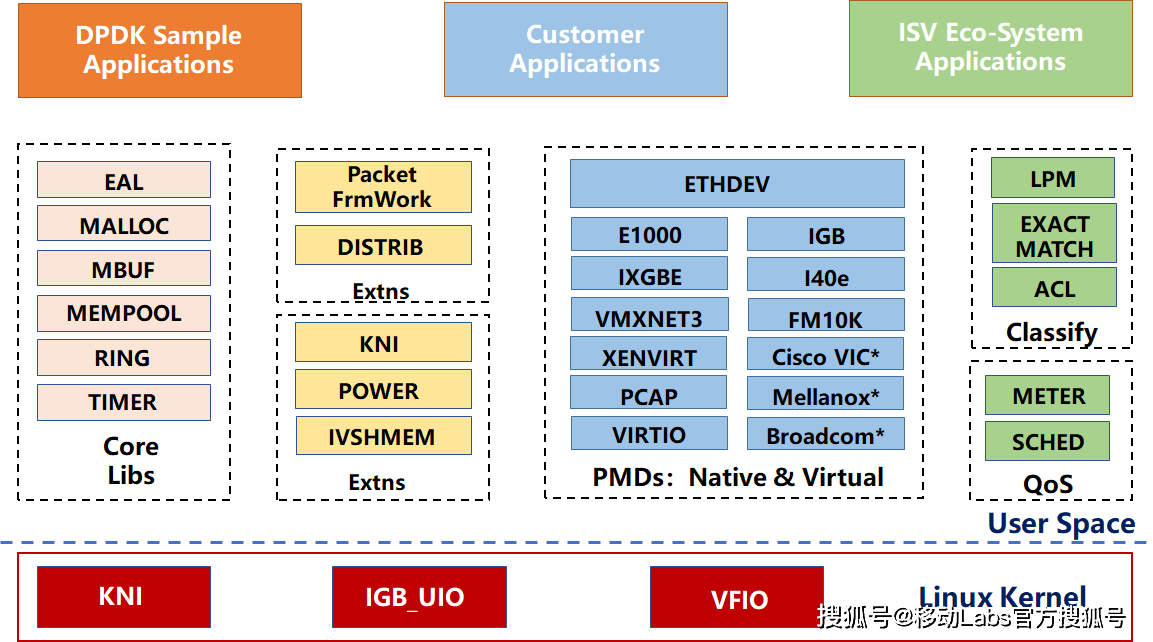
DPDK主要模块
- 核心库Core Libs,提供系统抽象、大页内存、缓存池、定时器及无锁环等基础组件。
- PMD库,提供全用户态的驱动,以便通过轮询和线程绑定得到极高的网络吞吐,支持各种本地和虚拟的网卡。
- Classify库,支持精确匹配(Exact Match)、最长匹配(LPM)和通配符匹配(ACL),提供常用包处理的查表操作。
- QoS库,提供网络服务质量相关组件,如限速(Meter)和调度(Sched)。
除了这些组件,DPDK还提供了几个平台特性,比如节能考虑的运行时频率调整(POWER),与Linux kernel stack建立快速通道的KNI(Kernel Network Interface)。而Packet Framework和DISTRIB为搭建更复杂的多核流水线处理模型提供了基础的组件。
(免费订阅,永久学习)学习地址: Dpdk/网络协议栈/vpp/OvS/DDos/NFV/虚拟化/高性能专家-学习视频教程-腾讯课堂
更多DPDK相关学习资料有需要的可以自行报名学习,免费订阅,永久学习,或点击这里加qun免费
领取,关注我持续更新哦! !
DPDK软件包内有一个最基本的三层转发实例(l3fwd),可用于测试双路服务器整系统的吞吐能力,通过现场实验,可以达到220Gbit/s的数据报文吞吐能力。除了通过硬件或者软件提升性能之外,如今DPDK整系统报文吞吐能力上限已经不再受限于CPU的核数,当前瓶颈在于PCIe(IO总线)的LANE数。换句话说,系统性能的整体I/O天花板不再是CPU,而是系统所提供的所有PCIe LANE的带宽,也就是能插入多少个高速以太网接口卡。
在这样的性能基础上,网络节点的软化(NFV)就成为可能。对于网络节点上运转的不同形态的网络功能,通过软化并适配到一个通用的硬件平台,就是软硬件解耦。解耦正是NFV的一个核心思想,而硬件解耦的多个网络功能在单一通用节点上的隔离共生问题,就是另一个核心思想---虚拟化。
NFV网络云中如何有效利用cache
在当今服务器领域,一个处理器通常包含多个核心(Core),集成Cache子系统,内存子系统通过内部或外部总线与其通信。在经典计算机系统中一般都有两个标准化的部分:北桥(North Bridge)和南桥(SouthBridge)。它们是处理器和内存以及其他外设沟通的渠道。在这类系统中,北桥就是整个架构的瓶颈,一旦北桥处理不过来或故障,整个系统的处理效率就会变低或瘫痪。因此,后来计算机系统中只存在南桥芯片,而北桥部分就被全部移植到CPU的SoC中,其中最重要的部分就是内存控制器,并在此基础上进一步衍生出NUMA和MPP架构,这个放在后面会讲。
我们在本科学习计算机基础课程时,都知道计算机的内存分为SRAM、DRAM、SDRAM和DDR(1/2/3/4)等不同类型。在早期的PC系统中,主要使用DRAM和SDRAM来作为内存,相比SRAM在成本、功耗方面有不小的优势,而且速度也还可以。后来在现今的PC系统中,利用SDRAM在一个时钟周期的上下边沿进行数据读写,整体数据吞吐率带宽翻倍,也就是DDR RAM,DDR根据不同的主频,又分为DDR1/DDR2/DDR3/DDR4。而SRAM,由于其功耗高、成本高,速度很快,一般都作为CPU的cache使用,目前都被封装的CPU的SoC中。
一般来说,Cache由三级组成,之所以对Cache进行分级,也是从成本和生产工艺的角度考虑的。一级(L1)最快,但是容量最小;三级(LLC,Last Level Cache)最慢,但是容量最大。

cache的架构
- 一级Cache:一般分为数据Cache和指令Cache,数据Cache用来存储数据,而指令Cache用于存放指令。这种Cache速度最快,一般处理器只需要3~5个指令周期就能访问到数据,因此成本高,容量小,一般都只有几十KB。
- 二级Cache:和一级Cache分为数据Cache和指令Cache不同,数据和指令都无差别地存放在一起。速度相比一级Cache慢一些,处理器大约需要十几个处理器周期才能访问到数据,容量也相对来说大一些,一般有几百KB到几MB不等。
- 三级Cache:速度更慢,处理器需要几十个处理器周期才能访问到数据,容量更大,一般都有几MB到几十个MB。在多核处理器内部,三级Cache由所有的核心所共有。这样的共享方式,其实也带来一个问题,有的处理器可能会极大地占用三级Cache,导致其他处理器只能占用极小的容量,从而导致Cache不命中,性能下降。因此,Intel公司推出了Intel® CAT技术,确保有一个公平,或者说软件可配置的算法来控制每个核心可以用到的Cache大小,有兴趣的可参考https://software.intel.com/zh-cn/articles/introduction-to-cache-allocation-technology?_ga=2.54835683.913561365.1556263296-1903721401.1556263296。
为了将cache与内存进行关联,需要对cache和内存进行分块,并采用一定的映射算法进行关联。分块就是将Cache和内存以块为单位进行数据交换,块的大小通常以在内存的一个存储周期中能够访问到的数据长度为限。当今主流块的大小都是64字节,因此一个Cache line就是指64个字节大小的数据块。而映射算法是指把内存地址空间映射到Cache地址空间。具体来说,就是把存放在内存中的内容按照一定规则装入到Cache中,并建立内存地址与Cache地址之间的对应关系。当CPU需要访问这个数据块内容时,只需要把内存地址转换成Cache地址,从而在Cache中找到该数据块,最终返回给CPU。
根据Cache和内存之间的映射关系的不同,Cache可以分为三类:第一类是全关联型Cache(full associative cache),第二类是直接关联型Cache(direct mapped cache),第三类是组关联型Cache(N-ways associative cache)。
1)全关联型cache
需要在cache中建立一个目录表,目录表的每一项由内存地址、cache块号和一个有效位组成。当CPU需要访问某个内存地址时,首先查询该目录表判断该内容是否缓存在Cache中,如果在,就直接从cache中读取内容;如果不在,就通过内存地址转换去内存冲读取。具体原理如下:

全联型cache原理图
首先,用内存的块地址A在Cache的目录表中进行查询,如果找到等值的内存块地址,检查有效位是否有效,只有有效的情况下,才能通过Cache块号在Cache中找到缓存的内存,并且加上块内地址B,找到相应数据,这时则称为Cache命中,处理器拿到数据返回;否则称为不命中,CPU则需要在内存中读取相应的数据。使用全关联型Cache,块的冲突最小(没有冲突),Cache的利用率也高,但是需要一个访问速度很快的相联存储器。随着Cache容量的增加,其电路设计变得十分复杂,因此一般只有TLB cache才会设计成全关联型。
2)直接关联型cache
是指将某一块内存映射到Cache的一个特定的块,即Cache line中。假设一个Cache中总共存在N个Cache line,那么内存就被分成N等分,其中每一等分对应一个Cache line。比如:Cache的大小是2K,而一个Cache line的大小是64B,那么就一共有2K/64B=32个Cache line,那么对应我们的内存,第1块(地址0~63),第33块(地址64*32~64*33-1),以及第(N*32+1)块都被映射到Cache第一块中;同理,第2块,第34块,以及第(N*32+2)块都被映射到Cache第二块中;可以依次类推其他内存块。直接关联型Cache的目录表只有两部分组成:区号和有效位。具体原理如下:

直联型cache原理图
首先,内存地址被分成三部分:区号A、块号B和块内地址C。根据区号A在目录表中找到完全相等的区号,并且在有效位有效的情况下,说明该数据在Cache中,然后通过内存地址的块号B获得在Cache中的块地址,加上块内地址C,最终找到数据。如果在目录表中找不到相等的区号,或者有效位无效的情况下,则说明该内容不在Cache中,需要到内存中读取。可以看出,直接关联是一种很“死”的映射方法,当映射到同一个Cache块的多个内存块同时需要缓存在Cache中时,只有一个内存块能够缓存,其他块需要被“淘汰”掉。因此,直接关联型命中率是最低的,但是其实现方式最为简单,匹配速度也最快。
3)组关联型cache
目前Cache中用得比较广泛的一种方式,是前两种Cache的折中形式。在这种方式下,内存被分为很多组,一个组的大小为多个Cache line的大小,一个组映射到对应的多个连续的Cache line,也就是一个Cache组,并且该组内的任意一块可以映射到对应Cache组的任意一个。可以看出,在组外,其采用直接关联型Cache的映射方式,而在组内,则采用全关联型Cache的映射方式。比如:有一个4路组关联型Cache,其大小为1M,一个Cache line的大小为64B,那么总共有16K个Cache line,但是在4路组关联的情况下,就拥有了4K个组,每个组有4个Cache line。一个内存单元可以缓存到它所对应的组中的任意一个Cache line中去。具体原理如下:
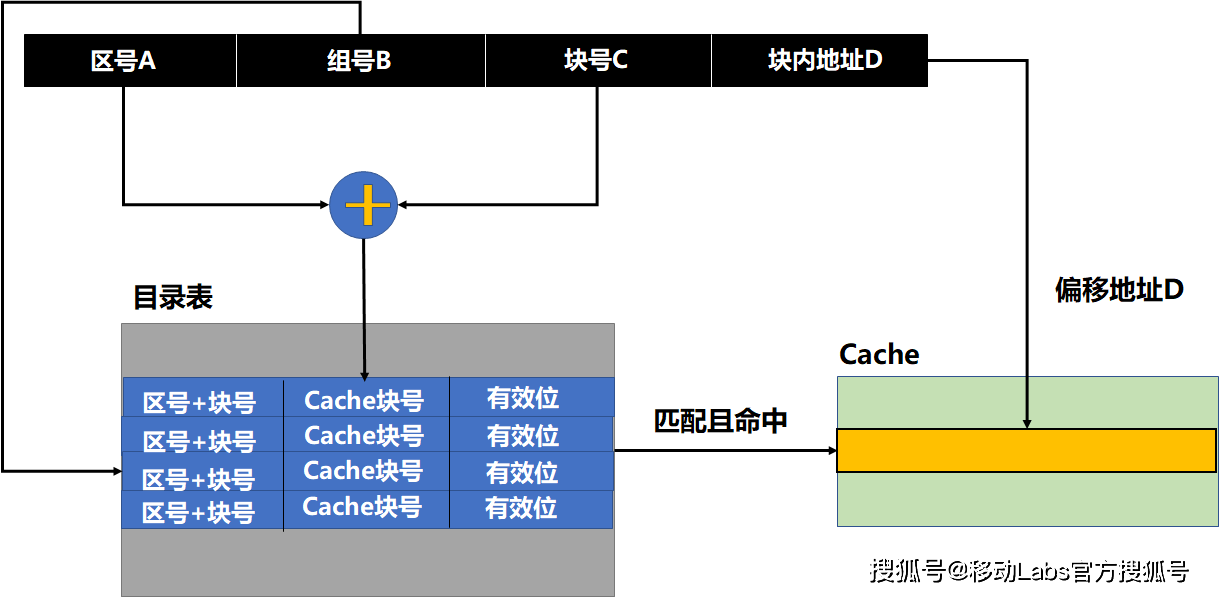
组联型cache原理图
目录表由三部分组成:“区号+块号”、Cache块号和有效位。一个内存地址被分成四部分:区号A、组号B、块号C和块内地址D。首先,根据组号B按地址查找到一组目录表项;然后,根据区号A和块号C在该组中进行关联查找(即并行查找,为了提高效率),如果匹配且有效位有效,则表明该数据块缓存在Cache中,得到Cache块号,加上块内地址D,可以得到该内存地址在Cache中映射的地址,得到数据;如果没有找到匹配项或者有效位无效,则表示该内存块不在Cache中,需要处理器到内存中读取。
内存的数据被加载进cache后,最终还是需要写回到内存中,这个写回的过程存在两种策略:
- 直写(write-through):在CPU对Cache写入的同时,将数据写入到内存中。这种策略保证了在任何时刻,内存的数据和Cache中的数据都是同步的,这种方式简单、可靠。但由于CPU每次对Cache更新时都要对内存进行写操作,总线工作繁忙,内存的带宽被大大占用,因此运行速度会受到影响。
- 回写(write-back):回写相对于直写而言是一种高效的方法。回写系统通过将Cache line的标志位字段添加一个Dirty标志位,当处理器在改写了某个Cache line后,并不是马上把其写回内存,而是将该Cache line的Dirty标志设置为1。当处理器再次修改该Cache line并且写回到Cache中,查表发现该Dirty位已经为1,则先将Cache line内容写回到内存中相应的位置,再将新数据写到Cache中。
除了上述这两种写策略,还有WC(write-combining)和UC(uncacheable)。这两种策略都是针对特殊的地址空间来使用的,这里不做详细讨论,有兴趣的可以参考Intel官方社区。
在采用回写策略的架构中,如果多个CPU同时对一个cache line进行修改后的写回操作,就存在“脏”数据区域的问题,这就是cache一致性问题。其本质原因是存在多个处理器独占的Cache,而不是多个处理器。解决Cache一致性问题的机制有两种:基于目录的协议(Directory-based protocol)和总线窥探协议(Bus snooping protocol)。这里不展开,有兴趣自行参考社区资料。
事实上,Cache对于绝大多数程序员来说都是透明不可见的,cache完成数据缓存的所有操作都是硬件自动完成的。但是,硬件也不是完全智能的。因此,Intel体系架构引入了能够对Cache进行预取的指令,使一些对程序执行效率有很高要求的程序员能够一定程度上控制Cache,加快程序的执行。同时,DPDK在定义数据结构或者数据缓冲区时就申明cache line对齐。
NFV网络云中的大页内存
在前文《x86架构基础》一文中提到了TLB的概念,其主要用来缓存内存地址转换中的页表项,其本质上也是一个cache,称之为TLB cache。TLB和cache的区别是:TLB缓存内存地址转换用的页表项,而cache缓存程序用到的数据和指令。
TLB中保存着程序线性地址前20位[31:12]和页框号的对应关系,如果匹配到线性地址就可以迅速找到页框号,通过页框号与线性地址后12位的偏移组合得到最终的物理地址。TLB使用虚拟地址进行搜索,直接返回对应的物理地址,相对于内存中的多级页表需要多次访问才能得到最终的物理地址,TLB查找大大减少了CPU的开销。如果需要的地址在TLB Cache中,就会迅速返回结果,然后CPU用该物理地址访问内存,这样的查找操作也称为TLB命中;如果需要的地址不在TLB Cache中,也就是不命中,CPU就需要到内存中访问多级页表,才能最终得到物理地址。但是,TLB的大小是有限的,因此TLB不命中的概率很大,为了提高内存地址转换效率,减少CPU的开销,就提出了大页内存的概念。
在x86架构中,一般都分成以下四组TLB:
- 第一组:缓存一般页表(4KB页面)的指令页表缓存(Instruction-TLB)。
- 第二组:缓存一般页表(4KB页面)的数据页表缓存(Data-TLB)。
- 第三组:缓存大尺寸页表(2MB/4MB页面)的指令页表缓存(Instruction-TLB)。
- 第四组:缓存大尺寸页表(2MB/4MB页面)的数据页表缓存(Data-TLB)
如果采用常规页(4KB)并且使TLB总能命中,需要寻址的内容都在该内容页内,那么至少需要在TLB表中存放两个表项。如果一个程序使用了512个内容页也就是2MB大小,那么需要512个页表表项才能保证不会出现TLB不命中的情况。但是,如果采用2MB作为分页的基本单位,那么只需要一个表项就可以保证不出现TLB不命中的情况;对于消耗内存以GB为单位的大型程序,可以采用1GB为单位作为分页的基本单位,减少TLB不命中的情况。需要注意的是:系统能否支持大页,支持大页的大小为多少是由其使用的处理器决定的。
在Linux启动之后,如果想预留大页,则可以使用以下的方法来预留内存。在非NUMA系统中,可以使用以下方法预留2MB大小的大页。
# 预留1024个大小为2MB的大页,也就是预留了2GB内存。
echo 1024 > /sys/kernel/mm/hugepages/hugepages-2048kB/nr_hugepages

系统未开启大页内存的状态

系统开启大页内存后的状态
如果是在NUMA系统中,假设有两个NODE的系统中,则可以用以下的命令:
# 在NODE0和NODE1上各预留1024个大小为2MB的大页,总共预留了4GB大小。
echo 1024 >/sys/devices/system/node/node0/hugepages/hugepages-2048kB/nr_hugepages
echo 1024 >/sys/devices/system/node/node1/hugepages/hugepages-2048kB/nr_hugepages
注意:对于大小为1GB的大页,则必须在Linux的GRUB配置文件中进行修改,并重启系统生效,不能动态预留。
DPDK中也是使用HUGETLBFS来使用大页。首先,它需要把大页mount到某个路径,比如/mnt/huge,以下是命令:
mkdir /mnt/huge
mount -t hugetlbfs nodev /mnt/huge
需要注意的是:在mount之前,要确保之前已经成功预留内存,否则会失败。该命令只是临时的mount了文件系统,如果想每次开机时省略该步骤,可以修改/etc/fstab文件,加上如下一行:
nodev /mnt/huge hugetlbfs defaults 0 0
对于1GB大小的大页,则必须用如下的命令:
nodev /mnt/huge_1GB hugetlbfs pagesize=1GB 0 0
然后,在DPDK运行的时候,会使用mmap()系统调用把大页映射到用户态的虚拟地址空间,然后就可以正常使用了。
原文链接:https://www.sohu.com/a/459604816_121036026







![[MQ] 交换机与队列的介绍](https://img-blog.csdnimg.cn/4023080c6f30409caae46c901368492e.png)
![[Spring Cloud] Open Feign 使用](https://img-blog.csdnimg.cn/af3cb2d4a9f9482296ecc118eca5aba6.png)