1. Torch 的两种并行化模型封装
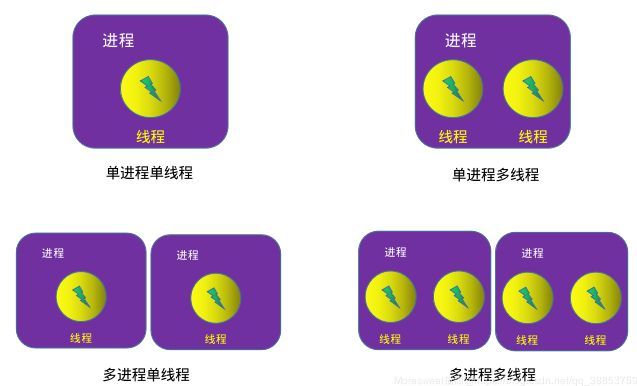
1.1 DataParallel
DataParallel 是 PyTorch 提供的一种数据并行方法,用于在单台机器上的多个 GPU 上进行模型训练。它通过将输入数据划分成多个子部分(mini-batches),并将这些子部分分配给不同的 GPU,以实现并行计算。
在前向传播过程中,输入数据会被划分成多个副本并发送到不同的设备(device)上进行计算。模型(module)会被复制到每个设备上,这意味着输入的批次(batch)会被平均分配到每个设备,但模型会在每个设备上有一个副本。每个模型副本只需要处理对应的子部分。需要注意的是,批次大小应大于GPU数量。在反向传播过程中,每个副本的梯度会被累加到原始模型中。总结来说,DataParallel会自动将数据切分并加载到相应的GPU上,将模型复制到每个GPU上,进行正向传播以计算梯度并汇总。
注意:DataParallel是单进程多线程的,仅仅能工作在单机中。
封装示例:
import torchimport torch.nn as nnimport torch.optim as optim# 定义模型class SimpleModel(nn.Module):def __init__(self):super(SimpleModel, self).__init__()self.fc = nn.Linear(10, 1)def forward(self, x):return self.fc(x)# 初始化模型model = SimpleModel()# 使用 DataParallel 将模型分布到多个 GPU 上model = nn.DataParallel(model)
1.2 DistributedDataParallel
DistributedDataParallel (DDP) 是 PyTorch 提供的一个用于分布式数据并行训练的模块,适用于单机多卡和多机多卡的场景。相比于 DataParallel,DDP 更加高效和灵活,能够在多个 GPU 和多个节点上进行并行训练。
DistributedDataParallel是多进程的,可以工作在单机或多机器中。DataParallel通常会慢于DistributedDataParallel。所以目前主流的方法是DistributedDataParallel。
封装示例:
import torchimport torch.nn as nnimport torch.optim as optimimport torch.distributed as distfrom torch.nn.parallel import DistributedDataParallel as DDPdef main(rank, world_size):# 初始化进程组dist.init_process_group("nccl", rank=rank, world_size=world_size)# 创建模型并移动到GPUmodel = SimpleModel().to(rank)# 包装模型为DDP模型ddp_model = DDP(model, device_ids=[rank])if __name__ == "__main__":import osimport torch.multiprocessing as mp# 世界大小:总共的进程数world_size = 4# 使用mp.spawn启动多个进程mp.spawn(main, args=(world_size,), nprocs=world_size, join=True)
2. 多GPU训练的三种架构组织方式
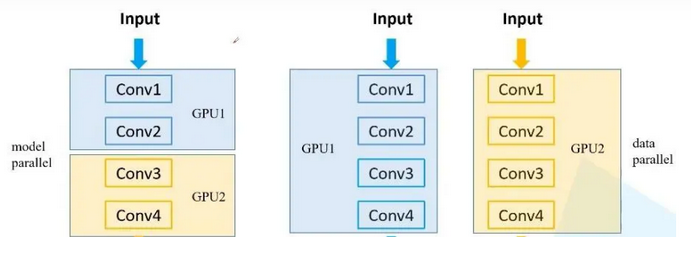
由于上一节的讨论,本节所有源码均由DDP封装实现。
2.1 数据拆分,模型不拆分(Data Parallelism)
数据并行(Data Parallelism)将输入数据拆分成多个子部分(mini-batches),并分配给不同的 GPU 进行计算。每个 GPU 上都有一份完整的模型副本。这种方式适用于模型相对较小,但需要处理大量数据的场景。
由于下面的代码涉及了rank、world_size等概念,这里先做一下简要普及。
Rank
rank 是一个整数,用于标识当前进程在整个分布式训练中的身份。每个进程都有一个唯一的 rank。rank 的范围是 0 到 world_size - 1。
用于区分不同的进程。
可以根据 rank 来分配不同的数据和模型部分。
World Size
world_size 是一个整数,表示参与分布式训练的所有进程的总数。
确定分布式训练中所有进程的数量。
用于初始化通信组,确保所有进程能够正确地进行通信和同步。
Backend
backend 指定了用于进程间通信的后端库。常用的后端有 nccl(适用于 GPU)、gloo(适用于 CPU 和 GPU)和 mpi(适用于多种设备)。
决定了进程间通信的具体实现方式。
影响训练的效率和性能。
Init Method
init_method 指定了初始化分布式环境的方法。常用的初始化方法有 TCP、共享文件系统和环境变量。
用于设置进程间通信的初始化方式,确保所有进程能够正确加入到分布式训练中。
Local Rank
local_rank 是每个进程在其所在节点(机器)上的本地标识。不同节点上的进程可能会有相同的 local_rank。
用于将每个进程绑定到特定的 GPU 或 CPU。

import torchimport torch.nn as nnimport torch.optim as optimimport torch.distributed as distfrom torch.nn.parallel import DistributedDataParallel as DDPimport torch.multiprocessing as mpclass SimpleModel(nn.Module):def __init__(self):super(SimpleModel, self).__init__()self.fc = nn.Linear(10, 1)def forward(self, x):return self.fc(x)def train(rank, world_size):dist.init_process_group(backend='nccl', init_method='tcp://127.0.0.1:29500', rank=rank, world_size=world_size)model = SimpleModel().to(rank)ddp_model = DDP(model, device_ids=[rank])criterion = nn.MSELoss().to(rank)optimizer = optim.SGD(ddp_model.parameters(), lr=0.01)inputs = torch.randn(64, 10).to(rank)targets = torch.randn(64, 1).to(rank)outputs = ddp_model(inputs)loss = criterion(outputs, targets)optimizer.zero_grad()loss.backward()optimizer.step()dist.destroy_process_group()if __name__ == "__main__":world_size = 4mp.spawn(train, args=(world_size,), nprocs=world_size, join=True)
2.2 数据不拆分,模型拆分(Model Parallelism)
模型并行(Model Parallelism)将模型拆分成多个部分,并分配给不同的 GPU。输入数据不拆分,但需要通过不同的 GPU 处理模型的不同部分。这种方式适用于模型非常大,单个 GPU 无法容纳完整模型的场景。
点击pytorch多GPU训练简明教程可查看全文













![【2024最新华为OD-C/D卷试题汇总】[支持在线评测] 最大括号深度(100分) - 三语言AC题解(Python/Java/Cpp)](https://i-blog.csdnimg.cn/direct/4a2868463b994b1eb90a731547c5083d.png)


![[Meachines] [Easy] valentine SSL心脏滴血+SSH-RSA解密+trp00f自动化权限提升+Tmux进程劫持权限提升](https://img-blog.csdnimg.cn/img_convert/c6d8a0e061eec042d3ebf74ec432afca.jpeg)
