论文阅读笔记:Semi-Supervised Semantic Segmentation Using Unreliable Pseudo-Labels
- 1 背景
- 2 创新点
- 3 方法
- 4 模块
- 4.1 伪标签
- 4.2 使用不可靠的伪标签
- 5 效果
- 5.1 与SOTA方法对比
- 5.2 消融实验
- 5.3 定性结果
- 6 结论
论文:https://arxiv.org/pdf/2203.03884v2.pdf
代码:https://github.com/Haochen-Wang409/U2PL
1 背景
一种典型的解决方法是将伪标注赋值给没有标注的像素。为了缓解确认偏差问题,其中模型可能遭受不正确的伪标注,现有的方法提出以其置信度分数过滤预测。换句话说,只有高度自信的预测被用作伪标注,而模糊的预测被丢弃。然而,仅仅使用可靠的预测可能导致的一个潜在问题是某些像素在整个训练过程中可能永远无法学习。如图1中的椅子类,如果模型不能很好的预测这个类别,就很难为该类像素分配准确的伪标签,这可能导致训练不充分和类别不平衡,从这个角度出发,作者认为,为了充分利用未标记的数据,每个像素都应该被适当地利用。

如果将不可靠的预测作为伪标注会导致性能下降。在本文中,作者提出了一个使用不可靠伪标签的替代方法,称为U2PL。首先,作者观察到,一个不可靠的预测通常只在少数及各类而不是所有类之间发生混淆。以图2为例,具有白色十字的像素在摩托车和人身上得到相似的概率,但该模型非常确定该像素不属于汽车和火车。就这样的观察,作者将易混淆的像素重新考虑为那些不太可能的类别的负样本。具体来说,从未标记的图像中获得预测后,作者使用每个像素的熵作为度量,如图2。

2 创新点
提出将不可靠的伪标注作为距离远的类别的负样本。
3 方法

给定一个有标签的数据集
D
l
=
{
(
x
i
l
,
y
i
l
)
}
i
=
1
N
l
D_l=\{(x_i^l,y_i^l)\}_{i=1}^{N_l}
Dl={(xil,yil)}i=1Nl 和一个大很多的无标签数据集
D
u
=
{
(
x
i
u
)
}
i
=
1
N
u
D_u=\{(x_i^u)\}_{i=1}^{N_u}
Du={(xiu)}i=1Nu,目标是利用大量的无标签数据和较小的有标签数据来训练一个语义分割模型。
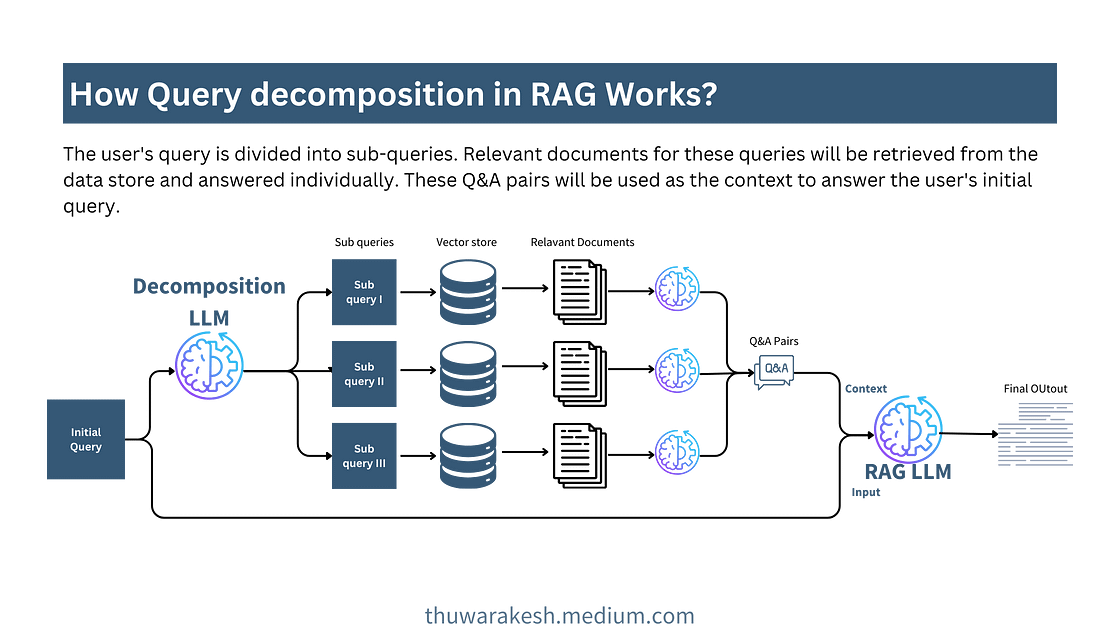
图3展示了
U
2
P
L
U^2PL
U2PL 的总览,它遵循典型的自训练框架,具有相同框架的两个模型,分别命名为教师和学生。两种模型仅在更新权重时存在差异。学生模型的权重
θ
s
\theta_s
θs 是按照通常的做法更新的,而教师模型的权重
θ
t
\theta_t
θt 是根据学生模型权重的指数移动平均更新的。每个模型由一个基于CNN的编码器
h
h
h,一个带有分割头
f
f
f 的解码器和一个表示头
g
g
g 组成的。在每一步训练中,对
B
B
B 张有标签图像
B
l
B_l
Bl 和
B
B
B 张无标签图像
B
u
B_u
Bu 进行等量采样的。对于每个未标记图像,首先将其带入到教师模型并得到预测,然后基于像素级熵,在计算等式中的无监督损失时忽略不可靠的像素级伪标注。最后用对比损失来充分利用无监督损失中排除的不可靠像素。优化目标是最小化总体损失,可以表述为:

式中
L
s
L_s
Ls 和
L
u
L_u
Lu 分别表示应用于有标签图像的监督损失和无标签图像的无监督损失,
L
c
L_c
Lc 为充分利用不可靠伪标签的对比损失。
λ
u
\lambda_u
λu 和
λ
c
\lambda_c
λc 是无监督损失和对比损失的权重。
L
s
L_s
Ls 和
L
u
L_u
Lu 是交叉熵损失:

其中,
y
i
l
y_i^l
yil 表示第
i
i
i 张有标注图像的人工标注掩码标签,
y
^
i
u
\hat{y}_i^u
y^iu 表示第
i
i
i 张无标注图像的伪标签。
f
◦
h
f◦h
f◦h 是
h
h
h 和
f
f
f 的复合函数。即先将图像输入
h
h
h 再输入
f
f
f 得到分割结果。
L
c
L_c
Lc 是像素级 InfoNCE 损失,定义为:

其中
M
M
M 是锚点像素总数,
z
c
i
z_{ci}
zci 表示
c
c
c 类第
i
i
i 个锚点的表示。每个锚点像素后跟一个正样本和N个负样本,其表示分别为
z
c
i
+
z_{ci}^+
zci+ 和
z
c
i
j
−
z_{cij}^-
zcij−。
z
=
g
◦
h
(
x
)
z=g◦h(x)
z=g◦h(x) 为表示头
g
g
g 的输出。
<
⋅
,
⋅
>
<·,·>
<⋅,⋅> 是两个不同像素的特征之间的余弦相似度,其范围限制在[-1,1],因此需要温度因子
τ
\tau
τ。文中
M
=
50
,
N
=
256
,
τ
=
0.5
M=50,N=256,\tau=0.5
M=50,N=256,τ=0.5。
L c L_c Lc 通过增加 e < z c i , z c i + > / τ e^{<z_{ci},z_{ci}^+>/\tau} e<zci,zci+>/τ 从而增加了当前锚点和正样本之间的相似度,通过降低 e < z c i , z c i j − > / τ e^{<z_{ci},z_{cij}^->/\tau} e<zci,zcij−>/τ从而降低了当前锚点和负样本之间的相似度。
4 模块
4.1 伪标签
为了避免过拟合错误的伪标注,我们利用每个像素概率分布的熵来过滤高质量的伪标注以进行进一步的监督。具体来说,将
p
i
j
∈
R
C
p_{ij}∈R^C
pij∈RC 表示教师模型的分割头在第
i
i
i 个未标注图像的第
j
j
j 个像素处生成的softmax概率,其中
C
C
C 为类别数。其熵计算为:

其中
p
i
j
(
c
)
p_{ij}(c)
pij(c) 是
p
i
j
p_{ij}
pij 在第
c
c
c 维的值。
然后,定义在训练的第
t
t
t 个epoch上熵在前
α
t
\alpha_t
αt 上的像素为不可靠的伪标注。这样不可靠的伪标注不具备监督资格。因此,定义第
i
i
i 个未标注图像的第
j
j
j 个像素处的伪标注为:

其中
γ
t
\gamma_t
γt 表示第
t
t
t 个训练step的熵阈值。将 KaTeX parse error: Undefined control sequence: \* at position 40: ….flatten(), 100\̲*̲(1-\alpha_t)),其中
H
H
H 是像素熵图。np.percentile()的作用是取序列
H
.
f
l
t
t
e
n
(
)
H.fltten()
H.fltten() 中的百分之 KaTeX parse error: Undefined control sequence: \* at position 4: 100\̲*̲(1-\alpha_t) 位数。
在训练过程中,未标注逐渐趋于可靠,基于这种直觉,作者每过一个epoch都要用线性策略调整不可靠像素的比例
α
t
\alpha_t
αt:

其中
α
0
\alpha_0
α0 初始比例且为 20%。
在获得可靠的伪标注之后,将它们纳入到无监督损失(3)中。该损失的权重
λ
u
\lambda_u
λu 定义为当前小批量中熵小于
γ
t
\gamma_t
γt 的像素的百分比的倒数乘以一个基础权重
η
\eta
η:

其中
1
(
⋅
)
1(·)
1(⋅) 为指示函数,
η
\eta
η 设置为 1。
4.2 使用不可靠的伪标签
在半监督学习任务重,丢弃不可靠的伪标注或降低其权重可以防止模型性能下降。遵循这一直觉,基于公式(6)过滤掉不可靠的伪标注。
然而,这种不可靠伪标注的忽视可能导致信息丢失,可见,不可靠的伪标注可以为更好的判别提供信息,如图2中白色十字就是典型的不可靠像素,它的分布显示了模型区分人和摩托车的不确定性。然而这种分布也证明了模型确定性,不会将该像素区分乘车,火车,自行车等类。这一特性为提出 U 2 P L U^2PL U2PL 使用不可靠的伪标注提供了主要启示。
U 2 P L U^2PL U2PL 的目标是利用不可靠的伪标注的信息进行更好的辨别,这与最近流行的对比学习范式在辨别表征上不谋而合。但由于半监督语义分割任务中标注图像的缺乏, U 2 P L U^2PL U2PL 建立在更复杂的策略之上。 U 2 P L U^2PL U2PL 有三个分量,分别是锚像素,正候选和负候选。这些分量是以采样的方式从某些集合中获得的,以减轻巨大的计算成本。接下来,将介绍如何选择(a)锚点像素(b)每个锚的正样本(c)每个锚的负样本。
在训练过程中,为当前小批次中出现的每个类采样锚像素,将
c
c
c 类所有已标注的候选像素的特征集合记为
A
c
l
A_c^l
Acl。

其中
y
i
j
y_{ij}
yij 是第
i
i
i 个标注图像的第
j
j
j 个像素的GT,
δ
p
\delta_p
δp 是正样本的阈值,设为0.3。
z
i
j
z_{ij}
zij 标注图像
i
i
i 的第
j
j
j 个像素的表示。对于无标签数据,对
A
c
u
A_c^u
Acu 可以计算为:

与
A
c
l
A_c^l
Acl 不同的是,
A
c
u
A_c^u
Acu 中使用了基于等式(6)的伪标签
y
^
i
j
\hat{y}_{ij}
y^ij。这意味着符合条件的锚点像素是可靠的,即
H
(
p
i
j
)
≤
γ
t
H(p_{ij})≤\gamma_t
H(pij)≤γt。因此,对于
c
c
c 类,所有合格锚点的集合为:

对于来自同一类别的所有锚点,正样本是相同的,是所有可能锚的中心:

同时,作者定义了一个二值化变量
n
i
j
(
c
)
n_{ij}(c)
nij(c) 来识别图像
i
i
i 的第
j
j
j 个像素是否属于
c
c
c 类的负样本。

n
i
j
l
(
c
)
n_{ij}^l(c)
nijl(c) 和
n
i
j
u
(
c
)
n_{ij}^u(c)
niju(c) 分别为标注和未标注图像
i
i
i 的第
j
j
j 个像素是否符合
c
c
c 类负样本的指导。
对于第
i
i
i 张标注图像,一个合格的
c
c
c 类负样本应该是:(a)不属于
c
c
c 类;(b)难以区分
c
c
c 类和它的GT类别。因此,引入像素级类别排序
O
i
j
=
a
r
g
s
o
r
t
(
p
i
j
)
O_{ij}=argsort(p_{ij})
Oij=argsort(pij)。显然有
O
i
j
(
a
r
g
m
a
x
(
p
i
j
)
)
=
0
O_{ij}(argmax(p_{ij}))=0
Oij(argmax(pij))=0 和
O
i
j
(
a
r
g
m
i
n
(
p
i
j
)
)
=
C
−
1
O_{ij}(argmin(p_{ij}))=C-1
Oij(argmin(pij))=C−1 。

其中
r
l
r_l
rl 为低排序阈值,设置为3。两个指标分别反应特征(a)和特征(b)。
这里就是把不是 c c c 类,但模型预测的 c c c 类的置信度在所有类的排名排前 r l r_l rl 的样本作为负样本。
对于第
i
i
i 个未标记图像,一个合格的
c
c
c 类的负样本应该:(a)不可靠;(b)可能不属于
c
c
c 类;(c)不属于最不可能的类。类似的,可以用
O
i
j
O_{ij}
Oij 来定义
n
i
j
u
(
c
)
n_{ij}^u(c)
niju(c):

其中
r
h
r_h
rh 是高排序阈值,设置为20。最终
c
c
c 类的负样本采样如下:

由于数据集的长尾现象,部分类别的负候选在小批量中极少。为了保持稳定的负样本数量,作者采样一个类别内存库
Q
c
Q_c
Qc(FIFO队列)。
算法伪代码如算法1。

5 效果
5.1 与SOTA方法对比



5.2 消融实验
通过像素级预测的熵值计算可信度,并利用不同可信度的像素进行消融实验。“Unrliable”表示从熵值最高的20%的像素中选择负样本,“Reliable”表示从最低的20%中选择,“All”表示不考虑熵的采样。实验证明不可靠伪标注确实有帮助。

低排名和高排名的阈值的消融实验。

各模块的消融实验。
 )
)
不可靠像素的初始比例的消融实验。

5.3 定性结果
通过对分割结果的可视化,发现本文方法在模糊区域(例如,不同对象之间的边界)上取得了更好的效果。

6 结论
类似于在线难负样本挖掘。