一、Ceph概述
如何选择存储
- 底层协议
- 兼容性
- 产品要有定位,功能有所取舍
- 针对特定市场的应用存储
- 被市场认可的存储系统
- 稳定性是第一位的
- 性能第二
- 数据功能要够用
一)存储分类
1、本地存储
本地的文件系统,不能在网络上用。
如:ext3、ext4、xfs、ntfs
2、网络存储
网络文件系统,共享的是文件系统
nfs:网络文件系统
hdfs、glusterfs:分布式网络文件系统
共享的是裸设备:块存储 cinder,ceph(块存储、对象存储、网络文件系统-分布式)、SAN(存储区域网)
二)分布式存储分类
1、Hadoop HDFS(大数据分布式文件系统)
HDFS(Hadoop Distributed File System)是一个分布式文件系统,是Hadoop生态系统的一个重要组成部分,是Hadoop中的存储组件。HDFS是一个高吞吐量的数据访问,非常适合大规模数据集上的应用。
1)HDFS的优点
- 高容错性
- 数据自动保存多个副本
- 副本丢失后,自动恢复
- 良好的数据访问机制
- 一次写入、多次读取,保证数据一致性
- 适合大数据文件的存储
- TB、甚至PB级数据
- 扩展能力很强
2)HDFS的缺点
- 低延迟数据访问
- 难以应付毫秒级以下的应用
- 海量小文件存储
- 占用NameNode大量内存
- 一个文件只能一个写入者
- 仅支持append(追加)
2、OpenStack object storage(Swift)
Swift是OpenStack开源云计算项目的子项目之一。Swift的目的是使用普通硬件来构建冗余的、可扩展的分布式对象存储集群,存储容量可达PB级。Swift的是Python开发
1)Swift的主要特点
- 各个存储的节点完全对等,是对称的系统架构
- 开发者通过一个restful http api与对象存储系统相互作用
- 无单点故障:Swift的元数据存储是完全均匀随机分布的,并且与对象文件存储一样,元数据也会存储多份。整个Swift集群中,也没有一个角色是单点的
- 在不影响性能的情况下,集群通过增加外部节点进行扩展
- 无限的可扩展性:这里的扩展性分两方面:一是数据存储容量无限可扩展了;二是Swift性能(如QPS、吞吐量等)可线性提升,扩容只需简单地新增机器,系统会自动完成数据迁移等工作,使各存储及诶点重新达到平衡状态
- 极高的数据持久性
2)Swift可以用一下用途
- 图片、文档存储
- 长期保存的日志文件
- 存储媒体库(图片、音乐、视频等)
- 视频监控文件的存档
总结:Swift适合用来存储大量的、长期的、需要备份的对象
3、公有云对象存储
公有云大都只有对象存储。例如,谷歌云存储是一个快速,具有可扩展性和高可用性的对象存储。
AWS的s3,阿里云的对象存储oss等等
4、GlusterFS
GlusterFS是一种全对称的开源分布式文件系统,所谓全对称是指GlusterFS采用弹性哈希算法,没有中心节点,所有节点全部平等。GlusterFS配置方便,稳定性好,可轻松达到PB级容量,数千个节点。
PB级容量 高可用性 基于文件系统级别共享 分布式 去中心化
基本类型:条带、复制、哈希
复合卷:就是分布式复制、分布式条带、分布式条带复制卷,像分布式复制,分布式条带这两个是比较常用的,像分布式条带复制卷三种揉一块的用的都比较少。
各种卷的整理:
- 分布卷:存储数据时,将文件随机存储到各台glusterfs机器上
- 优点:存储数据时,读取速度快
- 缺点:一个birck坏掉,文件就会丢失
- 复制卷:存储数据时,所有文件分别存储到每台flusterfs机器上
- 优点:对文件进行的多次备份,一个brick坏掉,文件不会丢失,其他机器的brick上面有备份
- 缺点:占用资源
- 条带卷:存储数据时,换一个文件分开存到每台glusterfs机器上
- 优点:对大文件,读写速度快
- 缺点:一个brick坏掉,文件就会坏掉
5、ceph
三)分布式存储系统的特性
1、可扩展
分布式存储系统可以扩展到几百台甚至几千台的集群规模,而且随着集群规模的增长,系统整体性能表现为线性增长。分布式存储的水平扩展有以下特性:
- 节点扩展后,旧数据会自动迁移到新节点,实现负载均衡,避免单点过热的情况出现
- 水平扩展只需将新节点和原有集群连接到同一网络,整个过程不会对业务造成影响
- 当节点被添加到集群,集群系统的整体容量和性能也随之线性扩展,伺候新节点的资源就会被平台管理,被用于分配或者回收
2、低成本
分布式存储系统的自动容错、自动负载均衡机制使其可以构建在普通的PC机之上。另外,线性扩展能力也使得增加、减少机器非常方便,可以实现自动运维。
3、高性能
无论是针对整个集群还是单台服务器,都要求分布式存储系统具备高性能。
4、易用
分布式存储系统需要能够提供易用的对外接口,另外,也要求具备完善的监控、运维工具,并能够与其他系统集成。
5、易管理
可通过一个简单的WEB界面就可以对整个系统进行配置管理,运维简便,极低的管理成本。
分布式存储系统的挑战主要在于数据、状态信息和持久化,要求在自动迁移、自动容错、并发读写的过程中保证数据的一致性。分布式存储涉及的技术主要来自两个领域:分布式系统以及数据库。
四)Ceph介绍
软件定义存储 (SDS) 利用基于软件的方法管理数据存储,并提供基于策略的数据层控制,独立于底层的存储硬件。
S3 Client:S3cmd Amazon S3 Tools: Download S3cmd
用于监控的ceph-dash管理控制台:https://github.com/Crapworks/ceph-dash
OpenStack RDO:http://rdo.fedorapeople.org/rdo-release.rpm
1、Ceph概要
Ceph是一个开源项目,他提供软件定义的、统一的存储解决方案。Ceph是一个可大规模扩展、高性能并且无单点故障的分布式存储系统。从一开始他就运行在通用商用硬件上,具有高度可伸缩性,容量可扩展至EB级别,甚至高大。
Ceph正变成一个流行的云存储解决方案。云依赖于商用硬件,而Ceph能和否充分利用商用硬件为你提供一个企业级、稳定、高度可伸缩性.
Ceph为企业提供了杰出的性能,无线的扩展性,强大并且灵活的存储产品,从而帮助他们摆脱了昂贵的专用存储。Ceph是一个运行与商用硬件之上的企业级、软件定义、统一存储解决方案,这也使得它成为最具性价比而且功能多样的存储系统。
Ceph存储系统在同一个底层架构上提供了块、文件和对象存储,使得用户可以自主选择需要的存储方式。
我们无法停止数据的生成,但需要缩小数据生成和数据存储之间的差距
2、Ceph的架构在设计之初就包含下面的特性:
- 所有的组件必须可扩展
- 不能存在单点故障
- 解决方案必须是软件定义的、开源的的并且可适用
- Ceph软件应该运行在通用商用硬件上。
- Ceph所有组件必须尽可能自我管理
3、ceph的好处
对象是Ceph的基础,也就是它的基本存储单元。任何格式的数据,不管是块、对象还是文件,都是以对象的形式保存在Ceph集群的归置组(Placement Group,PG)中。
- 满足现在和将来对于非结构化数据存储的需求
- 可以将平台和硬件独立分开
- 智能地处理对象,可以为每个对象都创建集群副本以提高其高可靠性
- 由于没有物理存储路径绑定,使得对象非常灵活并且与为之无关:使得数据的量级能够近线性地从PB级别扩展到EB级别
4、ceph核心组件及概念介绍
Ceph支持对象存储(RADOSGW)、块存储(RBD)和文件存储(CephFS)。一个Ceph存储集群至少包含一个Ceph monitor、Ceph manager及Ceph OSD(Object Store Daemon)。若要运行CephFS client,还需要Ceph metadata server。以下是Ceph的整体架构图:
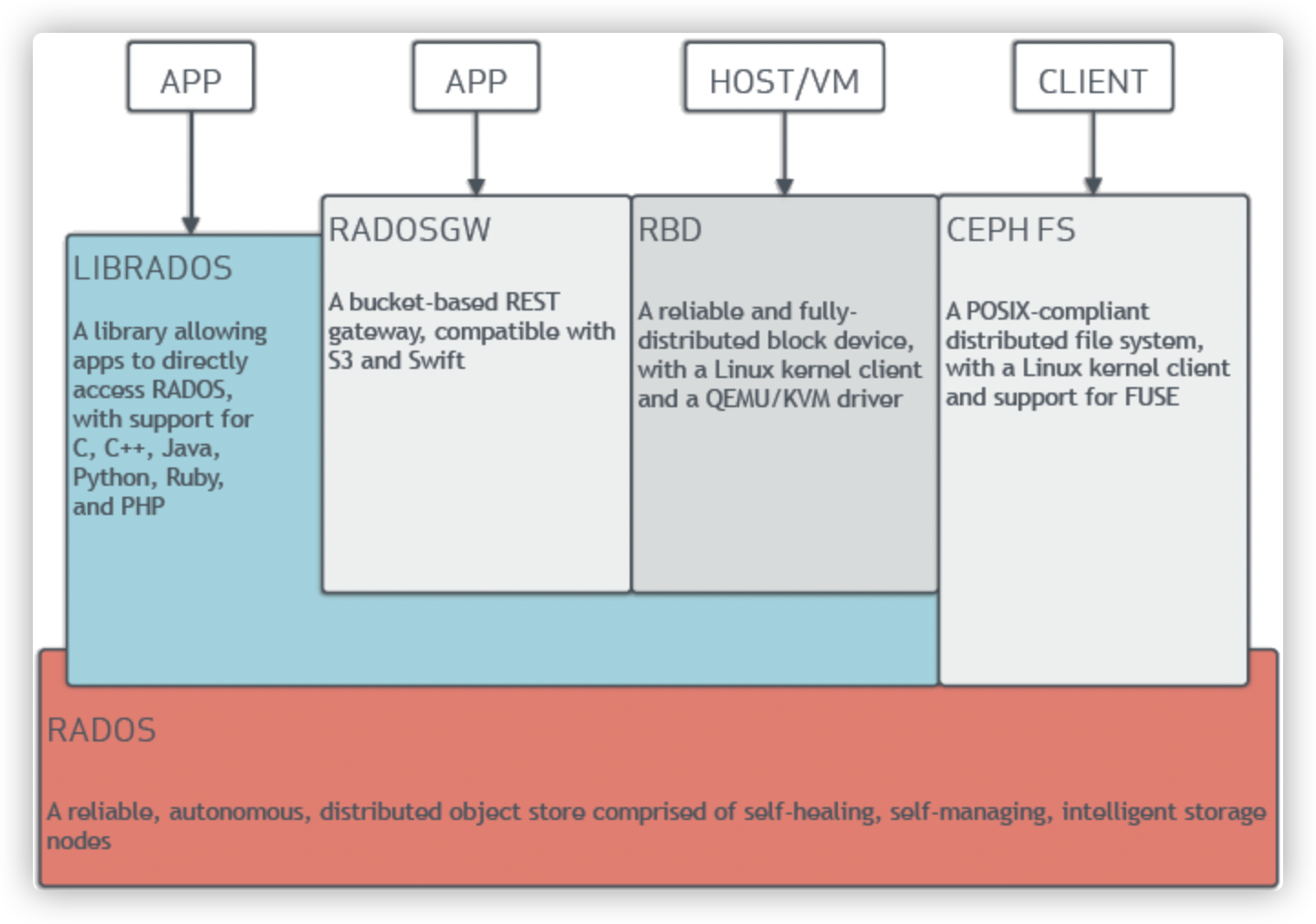
1)OSD:ceph OSD 存储
Ceph OSD:OSD的英文全称是Object Storage Device,它的主要功能是存储数据、复制数据、平衡数据、恢复数据等,与其它OSD间进行心跳检查等,并将一些变化情况上报给Ceph Monitor。一般情况下一块硬盘对应一个OSD,由OSD来对硬盘存储进行管理,当然一个分区也可以成为一个OSD。
Ceph OSD的架构实现由物理磁盘驱动器、Linux文件系统和Ceph OSD服务组成,对于Ceph OSD Deamon而言,Linux文件系统显性的支持了其拓展性,一般Linux文件系统有好几种,比如有BTRFS、XFS、Ext4等,BTRFS虽然有很多优点特性,但现在还没达到生产环境所需的稳定性,一般比较推荐使用XFS。
伴随OSD的还有一个概念叫做Journal盘,一般写数据到Ceph集群时,都是先将数据写入到Journal盘中,然后每隔一段时间比如5秒再将Journal盘中的数据刷新到文件系统中。一般为了使读写时延更小,Journal盘都是采用SSD,一般分配10G以上,当然分配多点那是更好,Ceph中引入Journal盘的概念是因为Journal允许Ceph OSD功能很快做小的写操作;一个随机写入首先写入在上一个连续类型的journal,然后刷新到文件系统,这给了文件系统足够的时间来合并写入磁盘,一般情况下使用SSD作为OSD的journal可以有效缓冲突发负载。
2)MON:Ceph Monitor 监控集群
Ceph Monitor:由该英文名字我们可以知道它是一个监视器,负责监视Ceph集群,维护Ceph集群的健康状态,同时维护着Ceph集群中的各种Map图,比如OSD Map、Monitor Map、PG Map和CRUSH Map,这些Map统称为Cluster Map,Cluster Map是RADOS的关键数据结构,管理集群中的所有成员、关系、属性等信息以及数据的分发,比如当用户需要存储数据到Ceph集群时,OSD需要先通过Monitor获取最新的Map图,然后根据Map图和object id等计算出数据最终存储的位置。
3)MDS:源数据管理
Ceph MDS:全称是Ceph MetaData Server,主要保存的文件系统服务的元数据,但对象存储和块存储设备是不需要使用该服务的。
4)MGR:manger 管理集群
用于收集ceph集群状态、运行指标,比如存储利用率、当前性能指标和系统负载。对外提供ceph dashboard(ceph ui)和restful api。manager组件开启高可用时,至少2个。
5)RGW:RADOS网关

rgw运行于librados之上,事实上就是一个称之为Civetweb的web服务器来响应api请求
客户端使用标准api与rgw通信,而rgw则使用librados与ceph集群通信
rgw客户端通过s3或者swift api使用rgw用户进行身份验证。然后rgw网关代表用户利用cephx与ceph存储进行身份验证
6)object
ceph最底层的存储单元是object对象,每个object包含元数据和原始数据。
7)PG
PG全称Placement Groups,是一个逻辑的概念,一个PG包含多个OSD。引入PG这一层其实是为了更好的分配数据和定位数据。
8)RADOS
RADOS全称Reliable Autonomic Distributed Object Store 是ceph集群的精华,永华实现数据分配、Failover等集群操作
9)CephFS
CephFS全称Ceph File System是ceph对外提供的文件系统服务。它使用ceph存储集群来存储数据。ceph文件系统与ceph块设备、同时提供s3和Swift api的ceph对象存储、或者原生库(librados)一样,都使用着相同的ceph存储集群系统。
5、CRUSH算法
- 在后台计算存储和读取的位置,而不是为每个客户端请求执行元数据表的查找
- 通过动态计算元数据,也就是不需要管理一个集中式的元数据表
- 利用分布式存储的功能可以将一个大的计算负载分布到集群中的多个节点,crush清晰的元数据管理方法比传统存储的更好
- 独特的基础感知能力。用户在ceph的crush map中可以自由地为他的基础设施定义故障区域(可以在自己的环境中高效地管理他们的数据)
- crush使得ceph能够自我管理和自我治愈(为因故障而丢失的数据执行恢复操作)
五)企业里的典型场景
1、高性能场景
亮点在于它在低TCO下每秒拥有最高的IOPS。
典型的做法是使用包含了更快的SSD硬盘、PCIe SSD、NVMe做数据存储的高性能节点。
通常用于块存储,也可以用在高IOPS的工作负载上。
2、通用场景
亮点在于高吞吐量和每吞吐量的低功耗。
通常的做法是拥有一个高带宽、物理隔离的双重网络,使用SSD和PCIe SSD做OSD日志盘。
这种方法常用于块存储,若你的应用场景需要高性能的对象存储和文件存储,也可以考虑使用。
3、大容量场景
亮点在于数据中心每TB存储的低成本,以及机架单元物理空间的低成本。也被成为经济存储、廉价存储、存储/长期存储。
通用的做法是使用插满机械硬盘的密集服务器,一般是8-14台服务器,每台服务器24-72TB的物理硬盘空间,
通常用于低功耗、大存储容量的对象存储和文件存储。
二、Ceph部署
一)ceph-deploy部署ceph
使用ceph-deploy安装Ceph 12.x:使用ceph-deploy安装Ceph 12.x_ceph-deploy install ceph-CSDN博客
二)cephadm部署ceph
https://www.cnblogs.com/st2021/p/14970266.html
三)rook部署ceph到kubernetes中
Ceph Docs
1、架构
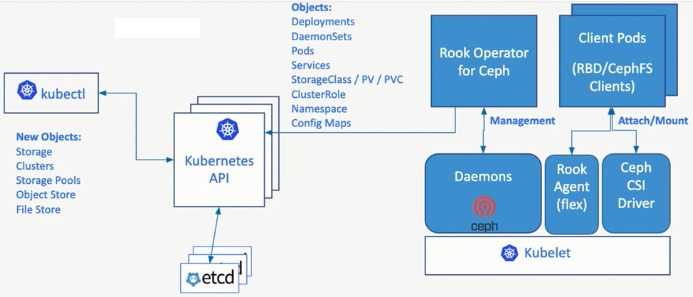
- rook负责初始化和管理ceph集群
- monitor集群
- mgr集群
- osd集群
- pool管理
- 对象存储
- 文件存储
- 监视和维护集群状态
- rook负责提供访问存储所需的驱动
- Flex驱动(旧驱动,不建议使用)
- CSI驱动
- RBD块存储
- CephFS文件存储
- S3/Swift风格对象存储

- 所有对象依托于kubernetes集群
- mon
- rgw
- mds
- osd
- agent
- csi-rdbplugin
- csi-cephfsplugin
- 抽象化管理,隐藏细节
- pool
- volumes
- filesystems
- buckets
三、ceph性能调优介绍和硬件选型
一)硬件选型
- 把握一个原则:ceph的硬件选型需要根据存储需求和企业的使用场景来制定
- 企业渴望什么需要什么:TCO低、高性能、高可靠
- 一般企业使用ceph的历程:硬件选型——部署调优——性能测试——架构灾备涉及——部分业务上限测试——运行维护(故障处理、预案演练等)
Hardware Recommendations — Ceph Documentation
Ceph OSD运行RADOS服务,需要通过CRUSH来计算数据的存放位置,复制数据,以及Cluster Map的拷贝。
通常建议每个OSD进程至少有一个CPU核。
- 硬件规划:CPU、内存、网络
- SSD选择:在预算足够的情况下,推荐使用PCIE SSD,这样性能会得到进一步提升,延迟有很大的改善。
- BIOS设置:超线程,关闭节能
- NUMA设置:建议关闭。若要用可以通过cgroup将ceph-osd进行与某一个CPU Core以及同一个Node下的内存进行绑定。
二)系统层面
1、Linux Kernel
IO调度:使用Noop调度器替代内核默认的CFQ
btrfs cfq, noop, deadline三种IO调度策略
预读:read_ahead_kb建议设最大值
进程:pid_max设最大值;调整CPU频率,使其运行在最大性能下
2、内存
SMP和NUMA
SWAP:vm_swappiness=0
全闪存支持:增加TCmalloc的Cache大小或者使用jemalloc替代TCmalloc
3、Cgroup
- 在对程序做CPU绑定或者使用Cgroup进行隔离时,注意不要跨CPU,以便更好地命中内存和缓存
- ceph进程和其他进程会互相抢占资源,使用Cgroup做好隔离措施
- 为Ceph进程预留足够多的CPU和内存资源,防止影响性能
三)网络层面
1、巨型帧
以太网的MTU是1500字节,默认情况下以太网帧是1522字节 = 1500(payload)+14(Ethernet header)+4(CRC)+4(VLAN tag)
巨型帧是将MTU调整到9000,从而通过减少网络中数据包的个数来减轻网络设备处理包头的额外开销,可以极大地提高性能。
设置MTU,需要本地设备和对端设备同时开启,可以极大提高性能。
为什么巨型帧会影响延迟?https://www.cnblogs.com/bandaoyu/p/14861151.html
2、中断亲和
进行网络IO时,会出发系统中断。默认情况下,所有的网卡中断都交由CPU0处理。
当大量网络IO出现时,处理大量网络IO会导致CPU0长时间处于满负载状态,以致无法处理更多的IO导致网络丢包等并发问题,产生系统瓶颈。Linux2.4内核之后,引入了将中断绑定到指定的CPU的技术,称为中断亲和(SMP IRQ affinity)。Linux中所有的中断情况在文件 /proc/interrupts 中记录。
可以通过 echo "$bitmask" > /proc/irq/$num/smp_affinity
bitmask代表CPU的掩码,以十六进制表示,每一位代表一个CPU核。 这里的$num代表中断号。
但是,这样手动设置CPU太过麻烦。实际中有 irqbalance 服务会定期(10秒)统计CPU的负载和系统的中断量,自动迁移中断,保持负载均衡。
irqbalance 在部分情况下确实能极大减少工作量,但由于它的检测无法保证实时性,部分情况下会加剧系统负载。
所以,还是建议根据系统规划,通过手动设置中断亲和,隔离部分CPU处理网卡中断。
3、硬件加速
主要采取TOE网卡(TCP offload Engine),它主要处理以下工作:
1) 协议处理:对TCP/IP协议的处理,如IP数据包的校验、TCP数据流的可靠性和一致性处理。
2) 中断处理:普通网卡上每个数据包都要触发一次中断,TOW网卡让每个应用程序完成一次完整的数据处理后才触发一次中断。
3) 减少内存拷贝:因为在网卡内进行协议处理,所以不必将数据复制到内核缓冲区,而是直接复制到应用程序的缓冲区。
4、RDMA (Remote Direct Memory Access)
RDMA可以在不需要操作系统的干预下,完成2个主机之间内存数据的传输。
RDMA工作过程中,应用程序与网卡直接互传数据,中间不经过内核缓冲区。
RDMA在Ceph中主要由Mellanox维护,使用accelio实现了类似SampleMessager的xio消息处理机制。
5、DPDK (Data Plane Development Kit)
DPDK采用轮询方式处理数据包处理过程,而不是使用CPU中断处理数据包的方式。
DPDK重载了网卡驱动,驱动在收到数据包后,不使用中断通知CPU,而是直接存入用户态内存中,使得应用程序可以通过DPDK提供的接口从内存中直接读取数据包。
使用DPDK类似于RDMA,避免了内存拷贝和上下文切换的时间。
四)Ceph层面优化
1、各种参数的配置
大致有:global参数、journal相关参数、osd config tuning参数、recovery tuning参数、client tuning参数
2、PG数量优化
Total PGs = (osd number * [100-200]) / replica_number
即,osd的数量乘以100到200之间的一个数值(如果pool比较多,则乘以200),再除以副本数。
五)ceph优化之其他杂项
- osd_enable_op_tracker=false #默认开启,可以跟踪op执行时间
- throttler_perf_counter=false #默认开启,可以观察阈值是否是瓶颈
- 当在特定环境调整到最佳性能后,建议关闭,tracker对性能影响较大
- cephx_sign_messages=false #默认开启,若对安全要求不高,建议关闭
- filestore_fd_cache_size=4096 #默认256
- filestore_fd_cache_shards=256 #默认16,修改后,略有提升
四、ceph运维
一)ceph运维内容概述
1、手册
- ceph运维手册
- ceph预案手册等
2、实操
- 部署ceph
- 进行预案演练
- 故障处理
- 集群扩容
- 来保证ceph整个集群的高可用性,确保数据不丢失,同时进行常规故障演练,保证出现故障后能够有序的进行故障修复
二)双活与容灾
1、双活场景
已经没有主和备的角色分别了,是对称式的,也就是两边会相互影响。这种影响,很有可能导致两边一损俱损。
双活只会增加运维难度,而不会降低。双活就得预防脑裂,而“预防脑裂”本身就可能会出各种问题,一旦软件做的问题不够健壮,反而会导致更大的问题甚至脑裂。
2、异地容灾
通过互联网TCP/IP协议,将本地的数据实时备份到异地服务器中,可以通过异地备份的数据进行远程恢复,也可以在异地进行数据回退。
3、传统存储的双活
利用虚拟化网关的实现起来,多一层运维比较复杂,现在的趋势偏向存储阵列的双活。
三)ceph日常运维
1、集群监控管理
1)集群整体运行状态
[root@cephnode01 ~]# ceph -s
cluster:
id: 8230a918-a0de-4784-9ab8-cd2a2b8671d0
health: HEALTH_WARN
application not enabled on 1 pool(s)
services:
mon: 3 daemons, quorum cephnode01,cephnode02,cephnode03 (age 27h)
mgr: cephnode01(active, since 53m), standbys: cephnode03, cephnode02
osd: 4 osds: 4 up (since 27h), 4 in (since 19h)
rgw: 1 daemon active (cephnode01)
data:
pools: 6 pools, 96 pgs
objects: 235 objects, 3.6 KiB
usage: 4.0 GiB used, 56 GiB / 60 GiB avail
pgs: 96 active+clean
# id:集群ID # health:集群运行状态,这里有一个警告,说明是有问题,意思是pg数大于pgp数,通常此数值相等。 # mon:Monitors运行状态。 # osd:OSDs运行状态。 # mgr:Managers运行状态。 # mds:Metadatas运行状态。 # pools:存储池与PGs的数量。 # objects:存储对象的数量。 # usage:存储的理论用量。 # pgs:PGs的运行状态
2)常用查询状态指令
集群状态: HEALTH_OK,HEALTH_WARN,HEALTH_ERR
# 仅仅显示集群是否正常
[root@ceph2 ~]#ceph health detail
HEALTH_OK
# 显示集群状态/
[root@ceph2 ~]# ceph -s
cluster:
id: 35a91e48-8244-4e96-a7ee-980ab989d20d
health: HEALTH_OK
services:
mon: 3 daemons, quorum ceph2,ceph3,ceph4
mgr: ceph4(active), standbys: ceph2, ceph3
mds: cephfs-1/1/1 up {0=ceph2=up:active}, 1 up:standby
osd: 9 osds: 9 up, 9 in; 32 remapped pgs
rbd-mirror: 1 daemon active
data:
pools: 14 pools, 536 pgs
objects: 220 objects, 240 MB
usage: 1764 MB used, 133 GB / 134 GB avail
pgs: 508 active+clean
28 active+clean+remapped
# 动态观察ceph集群
[root@ceph2 ~]# ceph -w
3)集群标志
noup:OSD启动时,会将自己在MON上标识为UP状态,设置该标志位,则OSD不会被自动标识为up状态 nodown:OSD停止时,MON会将OSD标识为down状态,设置该标志位,则MON不会将停止的OSD标识为down状态,设置noup和nodown可以防止网络抖动 noout:设置该标志位,则mon不会从crush映射中删除任何OSD。对OSD作维护时,可设置该标志位,以防止CRUSH在OSD停止时自动重平衡数据。OSD重新启动时,需要清除该flag noin:设置该标志位,可以防止数据被自动分配到OSD上 norecover:设置该flag,禁止任何集群恢复操作。在执行维护和停机时,可设置该flag nobackfill:禁止数据回填 noscrub:禁止清理操作。清理PG会在短期内影响OSD的操作。在低带宽集群中,清理期间如果OSD的速度过慢,则会被标记为down。可以该标记来防止这种情况发生 nodeep-scrub:禁止深度清理 norebalance:禁止重平衡数据。在执行集群维护或者停机时,可以使用该flag pause:设置该标志位,则集群停止读写,但不影响osd自检 full:标记集群已满,将拒绝任何数据写入,但可读
4)集群标志操作
a) 设置noout状态
[root@ceph2 ~]# ceph osd set noout noout is set
b) 取消noout状态
[root@ceph2 ~]# ceph osd unset noout noout is unset
c) 将指定文件作为对象写入到资源池中 put
[root@ceph2 ~]# rados -p ssdpool put testfull /etc/ceph/ceph.conf 2019-03-27 21:59:14.250208 7f6500913e40 0 client.65175.objecter FULL, paused modify 0x55d690a412b0 tid 0 [root@ceph2 ~]# rados -p ssdpool ls testfull test
5)PG操作
a) pg状态
Creating:PG正在被创建。通常当存储池被创建或者PG的数目被修改时,会出现这种状态 Active:PG处于活跃状态。可被正常读写 Clean:PG中的所有对象都被复制了规定的副本数 Down:PG离线 Replay:当某个OSD异常后,PG正在等待客户端重新发起操作 Splitting:PG正在初分割,通常在一个存储池的PG数增加后出现,现有的PG会被分割,部分对象被移动到新的PG Scrubbing:PG正在做不一致校验 Degraded:PG中部分对象的副本数未达到规定数目 Inconsistent:PG的副本出现了不一致。如果出现副本不一致,可使用ceph pg repair来修复不一致情况 Peering:Perring是由主OSD发起的使用存放PG副本的所有OSD就PG的所有对象和元数据的状态达成一致的过程。Peering完成后,主OSD才会接受客户端写请求 Repair:PG正在被检查,并尝试修改被发现的不一致情况 Recovering:PG正在迁移或同步对象及副本。通常是一个OSD down掉之后的重平衡过程 Backfill:一个新OSD加入集群后,CRUSH会把集群现有的一部分PG分配给它,被称之为数据回填 Backfill-wait:PG正在等待开始数据回填操作 Incomplete:PG日志中缺失了一关键时间段的数据。当包含PG所需信息的某OSD不可用时,会出现这种情况 Stale:PG处理未知状态。monitors在PG map改变后还没收到过PG的更新。集群刚启动时,在Peering结束前会出现该状态 Remapped:当PG的acting set变化后,数据将会从旧acting set迁移到新acting set。新主OSD需要一段时间后才能提供服务。因此这会让老的OSD继续提供服务,直到PG迁移完成。在这段时间,PG状态就会出现Remapped
b) stuck(卡住)状态的PG
# 如果PG长时间(mon_pg_stuck_threshold,默认为300s)出现如下状态时,MON会将该PG标记为stuck:
inactive:pg有peering问题
unclean:pg在故障恢复时遇到问题
stale:pg没有任何OSD报告,可能其所有的OSD都是down和out
undersized:pg没有充足的osd来存储它应具有的副本数
默认情况下,Ceph会自动执行恢复,但如果未成自动恢复,则集群状态会一直处于HEALTH_WARN或者HEALTH_ERR
如果特定PG的所有osd都是down和out状态,则PG会被标记为stale。要解决这一情况,其中一个OSD必须要重生,且具有可用的PG副本,否则PG不可用
Ceph可以声明osd或PG已丢失,这也就意味着数据丢失。
需要说明的是,osd的运行离不开journal,如果journal丢失,则osd停止
c) 管理stuck状态的PG
# 检查处于stuck状态的pg [root@ceph2 ceph]# ceph pg dump_stuck ok PG_STAT STATE UP UP_PRIMARY ACTING ACTING_PRIMARY 17.5 stale+peering [0,2] 0 [0,2] 0 17.4 stale+peering [2,0] 2 [2,0] 2 17.3 stale+peering [2,0] 2 [2,0] 2 17.2 stale+peering [2,0] 2 [2,0] 2 17.1 stale+peering [0,2] 0 [0,2] 0 17.0 stale+peering [2,0] 2 [2,0] 2 17.1f stale+peering [2,0] 2 [2,0] 2 17.1e stale+peering [0,2] 0 [0,2] 0 17.1d stale+peering [2,0] 2 [2,0] 2 17.1c stale+peering [0,2] 0 [0,2] 0 [root@ceph2 ceph]# ceph osd blocked-by osd num_blocked 0 19 2 13 # 检查导致pg一直阻塞在peering 状态的osd ceph osd blocked-by # 检查某个pg的状态 ceph pg dump |grep pgid # 声明pg丢失 ceph pg pgid mark_unfound_lost revert|delete # 声明osd丢失(需要osd状态为down 且out) ceph osd lost osdid --yes-i-really-mean-it
6)pool管理
a) 查看pool状态
ceph osd pool stats ceph osd lspools
b)限制pool配置更改
# 禁止pool被删除 ceph tell osd.* injectargs --osd_pool_default_flag_nodelete true # 禁止修改pool的pg_num和pgp_num ceph tell osd.* injectargs --osd_pool_default_flag_nopgchange true # 禁止修改pool的size和min_size ceph tell osd.* injectargs --osd_pool_default_flag_nosizechang true
7)查看osd状态
ceph osd stat ceph osd status ceph osd dump ceph osd tree ceph osd df
8)Monitor 状态和查看仲裁状态
ceph mon stat ceph mon dump ceph quorum_status
9)集群空间用量
ceph df ceph df detail
2、集群配置管理
1)查看运行配置
ceph daemon {daemon-type}.{id} config show
# ceph daemon osd.0 config show
2)tell子命令格式
# 使用 tell 的方式适合对整个集群进行设置,使用 * 号进行匹配,就可以对整个集群的角色进行设置。而出现节点异常无法设置时候,只会在命令行当中进行报错,不太便于查找。
命令格式:
# ceph tell {daemon-type}.{daemon id or *} injectargs --{name}={value} [--{name}={value}]
命令举例:
# ceph tell osd.0 injectargs --debug-osd 20 --debug-ms 1
# daemon-type:为要操作的对象类型如osd、mon、mds等。
# daemon id:该对象的名称,osd通常为0、1等,mon为ceph -s显示的名称,这里可以输入*表示全部
# injectargs:表示参数注入,后面必须跟一个参数,也可以跟多个
3)daemon 子命令
# 使用 daemon 进行设置的方式就是一个个的去设置,这样可以比较好的反馈,此方法是需要在设置的角色所在的主机上进行设置。
命令格式:
# ceph daemon {daemon-type}.{id} config set {name}={value}
命令举例:
# ceph daemon mon.ceph-monitor-1 config set mon_allow_pool_delete false
3、集群操作
1)操作守护进程
1、启动所有守护进程 # systemctl start ceph.target 2、按类型启动守护进程 # systemctl start ceph-mgr.target # systemctl start ceph-osd@id # systemctl start ceph-mon.target # systemctl start ceph-mds.target # systemctl start ceph-radosgw.target
2)添加和删除OSD
a) 添加 osd
# 格式化磁盘 ceph-volume lvm zap /dev/sd<id> # 进入到ceph-deploy执行目录/my-cluster,添加OSD ceph-deploy osd create --data /dev/sd<id> $hostname
b) 删除osd
# 调整osd的crush weight为 0 ceph osd crush reweight osd.<ID> 0.0 # 将osd进程stop systemctl stop ceph-osd@<ID> # 将osd设置out ceph osd out <ID> # 立即执行删除OSD中数据 ceph osd purge osd.<ID> --yes-i-really-mean-it # 卸载磁盘 umount /var/lib/ceph/osd/ceph-?
3)扩容pg
ceph osd pool set {pool-name} pg_num 128
ceph osd pool set {pool-name} pgp_num 128
# 在更改pool的PG数量时,需同时更改PGP的数量。PGP是为了管理placement而存在的专门的PG,它和PG的数量应该保持一致。如果你增加pool的pg_num,就需要同时增加pgp_num,保持它们大小一致,这样集群才能正常rebalancing。
4)pool操作
a) 列出存储池
ceph OSD lspools
b) 创建存储池
# 命令格式:
ceph osd pool create {pool-name} {pg-num} [{pgp-num}]
# 命令举例:
ceph osd pool create rbd 32 32
c) 设置存储池配置
命令格式:
# ceph osd pool set-quota {pool-name} [max_objects {obj-count}] [max_bytes {bytes}]
命令举例:
# ceph osd pool set-quota rbd max_objects 10000
d) 删除存储池
ceph osd pool delete {pool-name} [{pool-name} --yes-i-really-really-mean-it]
e) 重命名存储池
ceph osd pool rename {current-pool-name} {new-pool-name}
f) 查看存储池统计信息
rados df
g) 给存储池做快照
ceph osd pool mksnap {pool-name} {snap-name}
h) 删除存储池的快照
ceph osd pool rmsnap {pool-name} {snap-name}
i) 获取存储池选项值
ceph osd pool get {pool-name} {key}
j) 调整存储池选项值
ceph osd pool set {pool-name} {key} {value}
# size:设置存储池中的对象副本数,详情参见设置对象副本数。仅适用于副本存储池。
# min_size:设置 I/O 需要的最小副本数,详情参见设置对象副本数。仅适用于副本存储池。
# pg_num:计算数据分布时的有效 PG 数。只能大于当前 PG 数。
# pgp_num:计算数据分布时使用的有效 PGP 数量。小于等于存储池的 PG 数。
# hashpspool:给指定存储池设置/取消 HASHPSPOOL 标志。
# target_max_bytes:达到 max_bytes 阀值时会触发 Ceph 冲洗或驱逐对象。
# target_max_objects:达到 max_objects 阀值时会触发 Ceph 冲洗或驱逐对象。
# scrub_min_interval:在负载低时,洗刷存储池的最小间隔秒数。如果是 0 ,就按照配置文件里的
# osd_scrub_min_interval 。
# scrub_max_interval:不管集群负载如何,都要洗刷存储池的最大间隔秒数。如果是 0 ,就按照配置文件里的
# osd_scrub_max_interval 。
# deep_scrub_interval:“深度”洗刷存储池的间隔秒数。如果是 0 ,就按照配置文件里的
# osd_deep_scrub_interval 。
k) 获取对象副本数
ceph osd dump | grep 'replicated size'
l)调整pool的副本
# 设置pool的副本数 ceph osd pool set <poolname> size <num> # 获取pool的副本数 ceph osd pool get <poolname> size
5)用户管理
Ceph 把数据以对象的形式存于各存储池中。Ceph 用户必须具有访问存储池的权限才能够读写数据。另外,Ceph 用户必须具有执行权限才能够使用 Ceph 的管理命令。
a) 查看用户信息
# 查看所有用户信息 ceph auth list # 获取所有用户的key与权限相关信息 ceph auth get client.admin # 如果只需要某个用户的key信息,可以使用pring-key子命令 ceph auth print-key client.admin
b) 添加用户
ceph auth add client.john mon 'allow r' osd 'allow rw pool=liverpool' ceph auth get-or-create client.paul mon 'allow r' osd 'allow rw pool=liverpool' ceph auth get-or-create client.george mon 'allow r' osd 'allow rw pool=liverpool' -o george.keyring ceph auth get-or-create-key client.ringo mon 'allow r' osd 'allow rw pool=liverpool' -o ringo.key
c) 修改用户权限
# ceph auth caps client.john mon 'allow r' osd 'allow rw pool=liverpool' # ceph auth caps client.paul mon 'allow rw' osd 'allow rwx pool=liverpool' # ceph auth caps client.brian-manager mon 'allow *' osd 'allow *' # ceph auth caps client.ringo mon ' ' osd ' '
e) 删除用户
# ceph auth del {TYPE}.{ID}
其中, {TYPE} 是 client,osd,mon 或 mds 的其中一种。{ID} 是用户的名字或守护进程的 ID 。
6)增加和删除Monitor
一个集群可以只有一个 monitor,推荐生产环境至少部署 3 个。 Ceph 使用 Paxos 算法的一个变种对各种 map 、以及其它对集群来说至关重要的信息达成共识。建议(但不是强制)部署奇数个 monitor 。Ceph 需要 mon 中的大多数在运行并能够互相通信,比如单个 mon,或 2 个中的 2 个,3 个中的 2 个,4 个中的 3 个等。初始部署时,建议部署 3 个 monitor。后续如果要增加,请一次增加 2 个。
a) 增加一个monnitor
# ceph-deploy mon create $hostname 注意:执行ceph-deploy之前要进入之前安装时候配置的目录。/my-cluster
b) 删除monitor
# ceph-deploy mon destroy $hostname 注意: 确保你删除某个 Mon 后,其余 Mon 仍能达成一致。如果不可能,删除它之前可能需要先增加一个。
7)ceph故障排除
此时说明部分osd的存储已经超过阈值,mon会监控ceph集群中OSD空间使用情况。如果要消除WARN,可以修改这两个参数,提高阈值,但是通过实践发现并不能解决问题,可以通过观察osd的数据分布情况来分析原因。
nearfull osds or pools nearfull
a) 配置文件设置阙值
"mon_osd_full_ratio": "0.95", "mon_osd_nearfull_ratio": "0.85"
b) 自动处理
ceph osd reweight-by-utilization ceph osd reweight-by-pg 105 cephfs_data(pool_name)
c) 手动处理
ceph osd reweight osd.2 0.8
d) 全局处理
ceph mgr module ls ceph mgr module enable balancer ceph balancer on ceph balancer mode crush-compat ceph config-key set "mgr/balancer/max_misplaced": "0.01"
4、pg状态和osd 状态
1)PG状态概述
一个PG在它的生命周期的不同时刻可能会处于以下几种状态中:
Creating(创建中) 在创建POOL时,需要指定PG的数量,此时PG的状态便处于creating,意思是Ceph正在创建PG。 Peering(互联中) peering的作用主要是在PG及其副本所在的OSD之间建立互联,并使得OSD之间就这些PG中的object及其元数据达成一致。 Active(活跃的) 处于该状态意味着数据已经完好的保存到了主PG及副本PG中,并且Ceph已经完成了peering工作。 Clean(整洁的) 当某个PG处于clean状态时,则说明对应的主OSD及副本OSD已经成功互联,并且没有偏离的PG。也意味着Ceph已经将该PG中的对象按照规定的副本数进行了复制操作。 Degraded(降级的) 当某个PG的副本数未达到规定个数时,该PG便处于degraded状态,例如: 在客户端向主OSD写入object的过程,object的副本是由主OSD负责向副本OSD写入的,直到副本OSD在创建object副本完成,并向主OSD发出完成信息前,该PG的状态都会一直处于degraded状态。又或者是某个OSD的状态变成了down,那么该OSD上的所有PG都会被标记为degraded。 当Ceph因为某些原因无法找到某个PG内的一个或多个object时,该PG也会被标记为degraded状态。此时客户端不能读写找不到的对象,但是仍然能访问位于该PG内的其他object。 Recovering(恢复中) 当某个OSD因为某些原因down了,该OSD内PG的object会落后于它所对应的PG副本。而在该OSD重新up之后,该OSD中的内容必须更新到当前状态,处于此过程中的PG状态便是recovering。 Backfilling(回填) 当有新的OSD加入集群时,CRUSH会把现有集群内的部分PG分配给它。这些被重新分配到新OSD的PG状态便处于backfilling。 Remapped(重映射) 当负责维护某个PG的acting set变更时,PG需要从原来的acting set迁移至新的acting set。这个过程需要一段时间,所以在此期间,相关PG的状态便会标记为remapped。 Stale(陈旧的) 默认情况下,OSD守护进程每半秒钟便会向Monitor报告其PG等相关状态,如果某个PG的主OSD所在acting set没能向Monitor发送报告,或者其他的Monitor已经报告该OSD为down时,该PG便会被标记为stale。
2)OSD状态
单个OSD有两组状态需要关注,其中一组使用in/out标记该OSD是否在集群内,另一组使用up/down标记该OSD是否处于运行中状态。两组状态之间并不互斥,换句话说,当一个OSD处于“in”状态时,它仍然可以处于up或down的状态。
OSD状态为in且up 这是一个OSD正常的状态,说明该OSD处于集群内,并且运行正常。 OSD状态为in且down 此时该OSD尚处于集群中,但是守护进程状态已经不正常,默认在300秒后会被踢出集群,状态进而变为out且down,之后处于该OSD上的PG会迁移至其它OSD。 OSD状态为out且up 这种状态一般会出现在新增OSD时,意味着该OSD守护进程正常,但是尚未加入集群。 OSD状态为out且down 在该状态下的OSD不在集群内,并且守护进程运行不正常,CRUSH不会再分配PG到该OSD
五、ceph MDS 性能测试分析
ceph MDS在主处理流程中使用了单线程,这导致了其单个MDS的性能受到了限制,最大单个MDS可达8k ops/s,CPU利用率达到的 140%左右。但这可能也是ceph MDS的优势:
- 单线程使内部不用考虑太复杂的锁机制,能发挥最大的单MDS性能优势。
- 由于MDS是无状态的,在单个物理节点可以部署多个MDS来提供并发,从而提高性能。通过上述手动设置负载均衡测试可知:如果负载均衡,性能可以随MDS线性增加。
- 目前MDS的负载均衡实现的不是很好,后续有待提供和改善。目前可以针对具体的应用,手动实现负载均衡,这在某些特定应用场景是可行的。
目前生产环境中,做了大量的长时间测试,Ceph内核客户端确实可以提供3倍性能,但是还是推荐使用fuse客户端。在长稳测试中,内核客户端偶然会有宕机的情况,fuse客户端还比较稳定。
- 测试对象:要区分硬:SSD、RAID、SAN和云硬盘等,因为他们有不同的特点
- 测试指标:IOPS和MBPS(吞吐率),下面会具体阐述
- 测试工具:Linux下常用Fio、dd工具,rados bench,Windows iometer
- 测试参数:IO大小、寻址空间、队列深度、读写模式和随机/顺序模式
- 测试方法:科学合理的测试步骤
















![PostgreSQL的学习心得和知识总结(一百五十)|[performance]更好地处理冗余 IS [NOT] NULL 限定符](https://i-blog.csdnimg.cn/direct/0429c52cc29e4daf8b54d936a535c2fe.png)
