缓存系列文章链接如下:
高并发下的分布式缓存 | 缓存系统稳定性设计
高并发下的分布式缓存 | 设计和实现LRU缓存
高并发下的分布式缓存 | 设计和实现LFU缓存
高并发下的分布式缓存 | Cache-Aside缓存模式
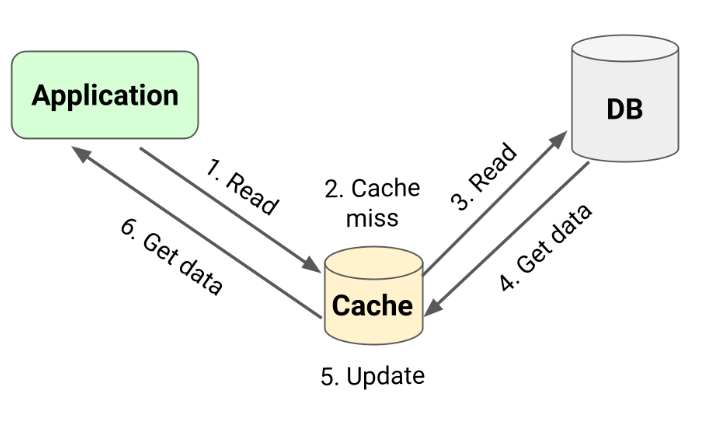
Read-Through 模式的缓存操作
Read-Through模式的一个关键优势是简化了应用程序的代码。它将缓存未命中时数据获取责任转移到了缓存层。应用层只与缓存交互。
缓存系统在这里起到了“中介”的作用:当应用程序请求数据时,首先去缓存中查找;如果缓存中有数据,就直接返回给应用程序。如果缓存中没有数据(即缓存未命中),缓存系统会自动从数据库中取出数据,然后将数据存储在自身,并返回给应用程序。下次再有相同的数据请求时,就可以直接从缓存中获取,而不需要再次访问数据库。
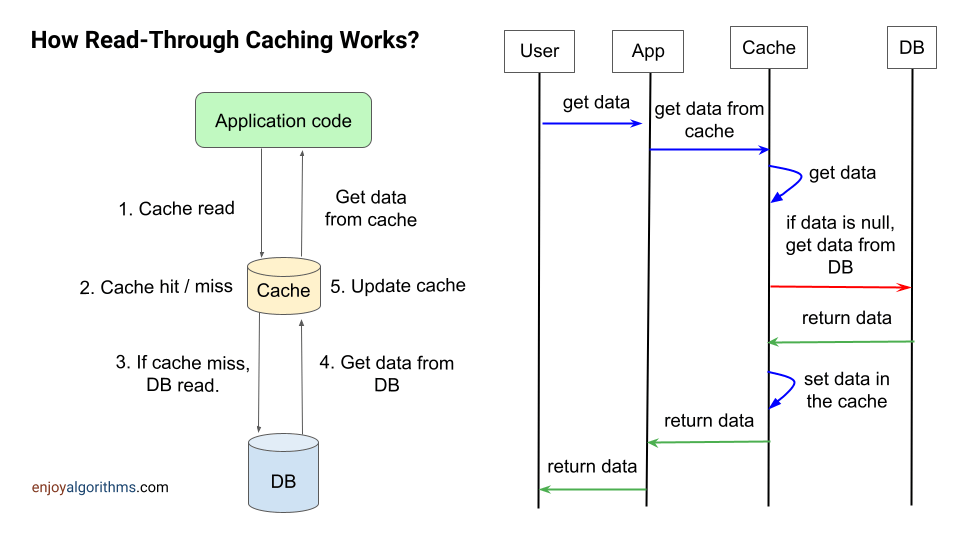
Read-Through模式的特点
Read-Through模式的优点
1. 降低读取延迟
这个模式的最大优势是提高了系统的响应速度。因为很多时候数据已经在缓存中了,所以应用程序不需要每次都去数据库找数据。尤其是当数据库在远程服务器上时,直接从缓存中读取数据可以节省大量时间。
2. 简化应用程序代码
使用 Read-Through 模式,应用程序不用自己管理什么时候从数据库获取数据,什么时候更新缓存。这些事情都由缓存系统自动处理,开发人员只需要专注于业务逻辑,不用操心缓存的一些细节。
3. 减少数据库负载
因为大部分的数据请求都能直接在缓存中找到,不用总是访问数据库,这样数据库的工作量就会减少,减轻了它的压力。
4. 自动数据刷新
在这个模式下,缓存可以设置成自动更新的。当缓存里的数据过期或者数据库里的数据发生了变化,缓存会自动从数据库里获取最新的数据,减少出现过期数据的可能性。
Read-Through模式的缺点:
1. 首次请求延迟较高
在 Read-Through 模式下,当某个数据首次被请求或缓存中的数据过期时,缓存系统会自动从数据库中获取最新数据并将其存入缓存中。由于需要访问数据库,这个过程相对较慢,可能会导致初次请求时的延迟增大。
2. 可能缓存不必要的数据
在 Read-Through 模式中,缓存系统会自动将从数据库中读取的数据存入缓存。然而,有时这些数据可能是一次性访问的数据,之后不会再被频繁访问,这会导致缓存中存放了很多不常用的数据,占用了宝贵的缓存空间。
例如你平时不太吃零食,但某天突然想尝试一下某种零食。你去买了一大包放在冰箱里。结果,你吃了一次后就不太想吃了,但它们仍然占据了冰箱的大部分空间,让你常吃的食物没有足够的地方放。
3. 数据不一致
在 Read-Through 模式中,数据的一致性问题是指缓存中的数据在某些情况下可能与数据库中的数据不一致。比如,数据在数据库中更新了,但由于缓存中的数据尚未过期,因此你访问到的还是旧数据。这种情况可能会影响到系统的正确性。
Read-Through和Cache-Aside的区别
Read-Through和Cache-Aside两种缓存策略虽然看起来非常相似,但是仍然存在一些主要的差别,下面通过一个例子说明。
想象你有两个咖啡店,一个是“Read-Through 咖啡店”,另一个是“Cache-Aside 咖啡店”。
-
在 Read-Through 咖啡店,你(客户)只需要告诉店员你要喝什么,店员会自动去厨房(数据库)准备你要的咖啡,如果厨房已经准备好了(缓存命中),直接给你,如果没有准备好(缓存未命中),店员会去厨房准备好再给你。
-
在 Cache-Aside 咖啡店,你需要自己去厨房查看咖啡有没有准备好(检查缓存),如果没有准备好,你需要自己去煮咖啡(加载数据),然后再将咖啡放到前台(缓存)供以后使用。







![[Qt][QWidget]详细讲解](https://i-blog.csdnimg.cn/direct/54743ff13141411db5633e76ab0876a4.png)