FunAudioLLM
FunAudioLLM 是阿里开源的语音处理模型,包含 SenseVoice 和 CosyVoice 两个模型。可以实现 5 种语言生成,以及 50 种语言无缝翻译,还能识别语音情绪。
-
FunAudioLLM:https://github.com/FunAudioLLM
-
CosyVoice开源仓库:https://github.com/FunAudioLLM/CosyVoice
-
CosyVoice在线体验:https://www.modelscope.cn/studios/iic/CosyVoice-300M
-
SenseVoice开源仓库:https://github.com/FunAudioLLM/SenseVoice
-
SenseVoice在线体验:https://www.modelscope.cn/studios/iic/SenseVoice
FunAudioLLM 模型已经在趋动云『社区项目』上线,欢迎感兴趣的码友们前来实操体验,一同领略 AI 播客带来的非凡魅力与强劲实力!
-
项目入口:https://open.virtaicloud.com/web/project/detail/470526582805655552
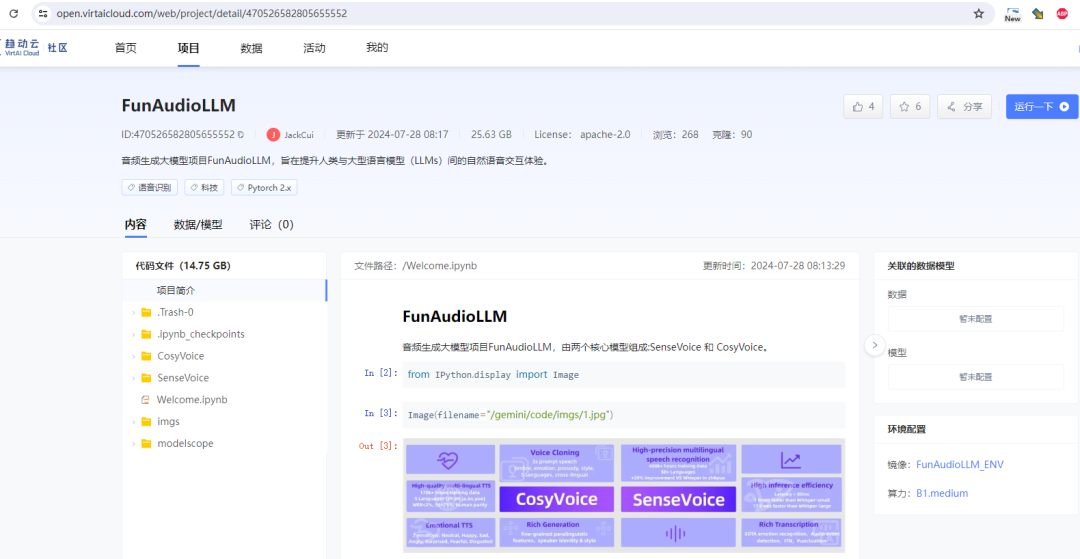
一键部署,极速体验 AI 语音天花板
进入FunAudioLLM项目主页中,下滑可以浏览该项目的详细介绍。

点击运行一下,即刻将项目一键克隆到工作空间,不需要自己动手收集下载数据集、模型等。另外,『社区项目』推荐适用的算力规格,可以直接立即运行。
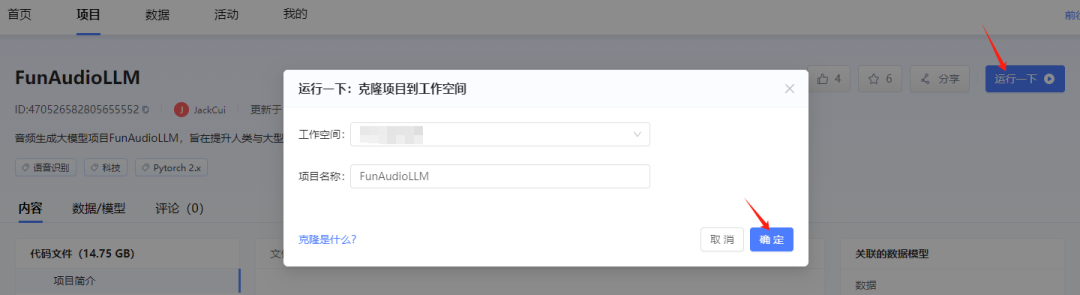
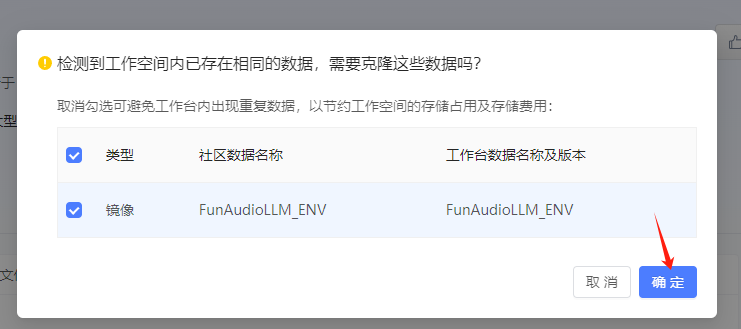
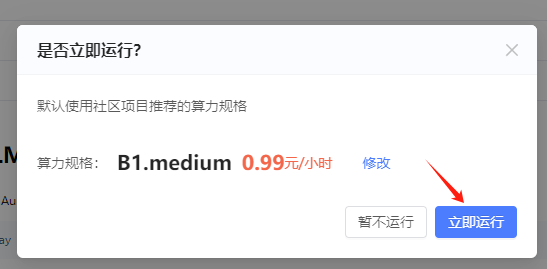
配置完成,点击进入开发环境,根据项目主页介绍进行部署。
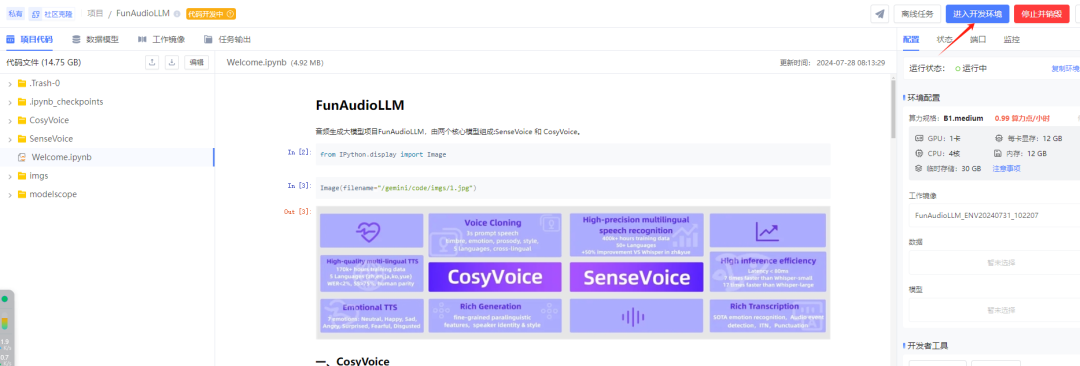
根据『社区项目』中该项目的介绍,执行以下操作,依次部署:CosyVoice 和 SenseVoice 两个模型。
CosyVoice
1.运行方法
进入CosyVoice文件夹,找到run.ipynb文件。
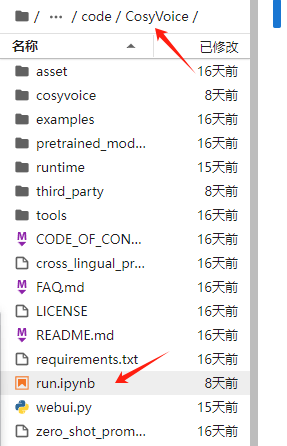
2.运行代码
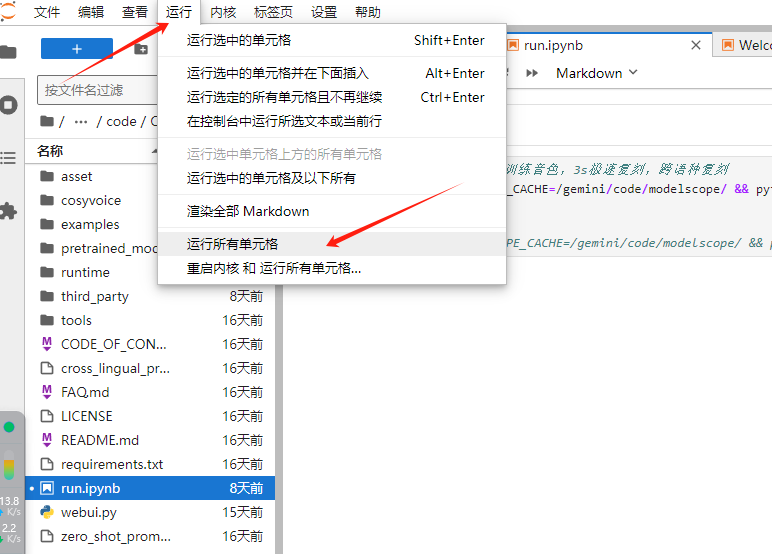
或者点进去run.ipynb,直接enter+shift运行代码即可。
3.当看到 local url 表明服务开启完成
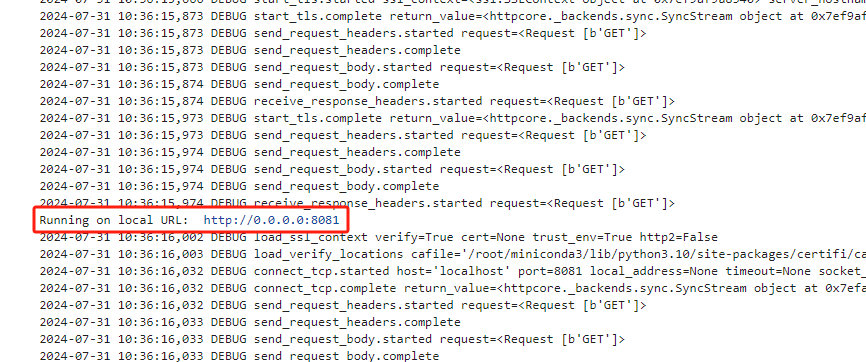
4.添加端口,获得外部访问链接
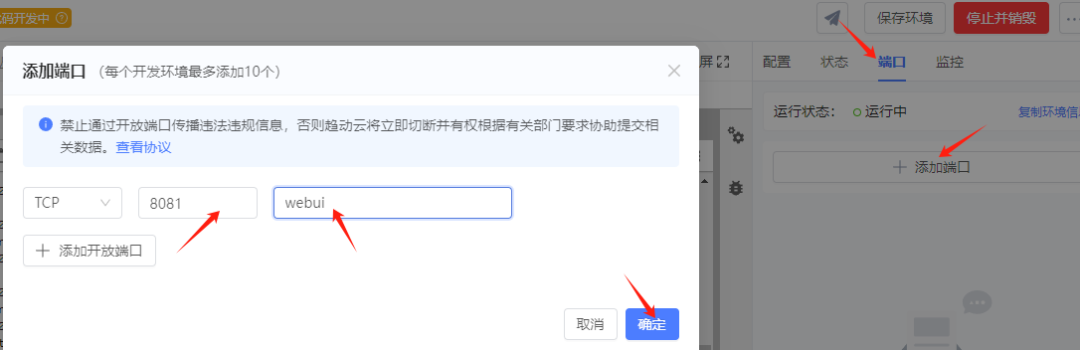
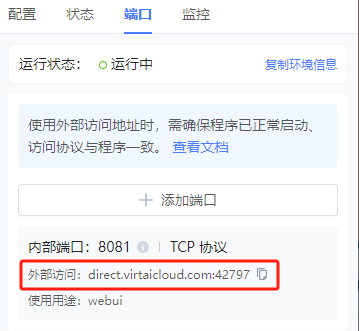
5.复制到浏览器即可访问

使用自然语言控制时,需要更换模型,在run.ipynb文件中,在代码!export MODELSCOPE_CACHE=/gemini/code/modelscope/ && python webui.py --port 8081 --model_dir pretrained_models/CosyVoice-300M前加#号注释掉,然后将#!export MODELSCOPE_CACHE=/gemini/code/modelscope/ && python webui.py --port 8081 --model_dir pretrained_models/CosyVoice-300M-Instruct前的#号去掉,运行代码即可。
SenseVoice
操作和 CosyVoice 一样。
-
打开 SenseVoice 目录下的 run.ipynb 文件;
-
运行所有单元格,运行代码;
-
当看到 local url 的时候表明服务开启;
-
添加 8082 端口;
-
通过外部访问链接即可访问服务。
直接上传音频,即可识别出对应的文字,或者可以直接使用在 CosyVoice 上生成的音频。
识别文字如下,正确率非常的高,除了粤语的不太好评定,中英日韩的识别正确率百分百!
中文
英语
粤语歌

日语

韩语
➫温馨提示: 完成项目后,记得及时关闭开发环境,以免继续产生费用!
智汇全球,趋动未来
『社区项目』汇聚全球智慧,促进技术交流的宝贵平台。热切盼望每一位码友加入,分享您的杰作,共筑这个充满活力与创新的技术乐园。让我们并肩同行,在技术的浩瀚宇宙中持续探索,共同成长!
教程系列1 | 趋动云『社区项目』极速部署 SD WebUI
教程系列2 | 趋动云『社区项目』一步实现与 AI 对话
教程系列3 | 趋动云『社区项目』一键极速部署 PhotoMaker,解锁 AI 绘画奇妙之旅
教程系列4 | 趋动云『社区项目』极速体验 LivePortrait 人脸表情“移花接木”大法
趋动云



















