AI视频生成赛道风起云涌,国内外新颖的文生、图生视频产品层出不穷。在各大厂商的“内卷”之下,当下的视频生成模型各方面已经接近“以假乱真”的效果。例如,OpenAI 的 Sora 和国内的 Vidu、可灵等模型,通过利用 Diffusion Transformer 的扩展特性,不仅能够满足各种分辨率、尺寸和时长的预测要求,同时生成的视频更符合物理世界的表现。
但与此同时,大部分视频生成模型的准确程度、遵循指令的能力还有待提升,生成视频仍然是一个“抽卡”的过程,往往需要用户生成许多次,才能获得符合需求的结果。这也造成算力成本过高、资源浪费等问题。
为了解决这些问题,阿里云提出了一种基于 DiT 架构的轨迹可控视频生成模型 Tora。Tora能够根据任意数量的物体轨迹,图像和文本条件生成不同分辨率和时长的视频,在 720p分辨率下能够生成长达204 帧的稳定运动视频。值得注意的是,Tora继承了DiT的scaling特性,生成的运动模式更流畅,更符合物理世界。

三种模态组合输入,精准控制运动轨迹
Tora支持轨迹、文本、图像三种模态,或它们的组合输入,可对不同时长、宽高比和分辨率的视频内容进行动态精确控制。
轨迹输入可以是各种各样的直线、曲线,其具有方向,不同方向的多个轨迹也可以进行组合。
例如,你可以用一条S型曲线控制漂浮物的运动轨迹,同时用文字描述来控制它的运动速度。下面这个视频中,所使用的提示词用到了“缓慢”、“优雅”、“轻轻”等副词。

与目前常见的运动笔刷功能有所不同的是,即使没有输入图像,Tora也可以基于轨迹和文本的组合,生成对应的视频。
例如下面这个视频中的1、3两个视频,就是在没有初始帧,只有轨迹和文字的情况下生成的。

Tora也支持首尾帧控制,不过这个案例只以图片形式出现在官方给出的论文里,并没有提供视频演示。

方法介绍
基于OpenSora框架,创新两种运动处理模块
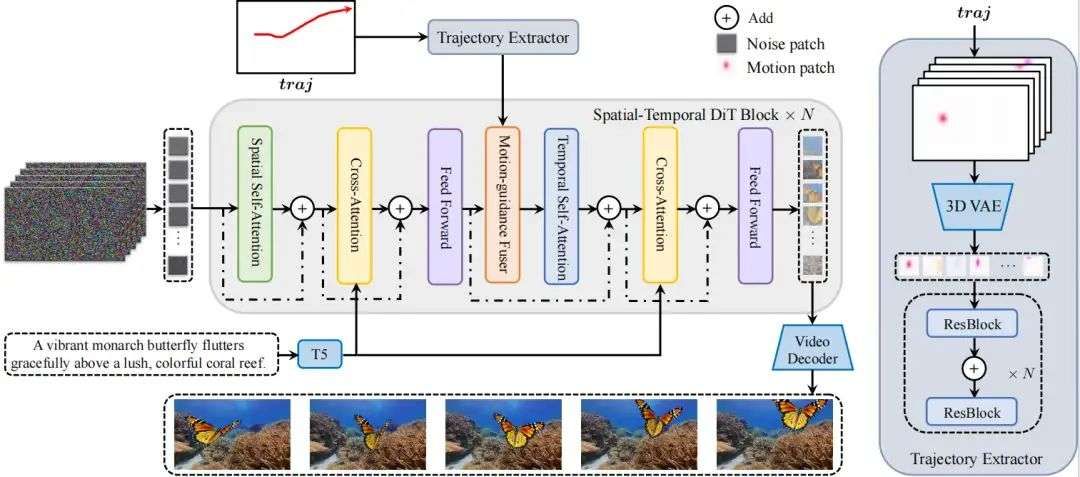
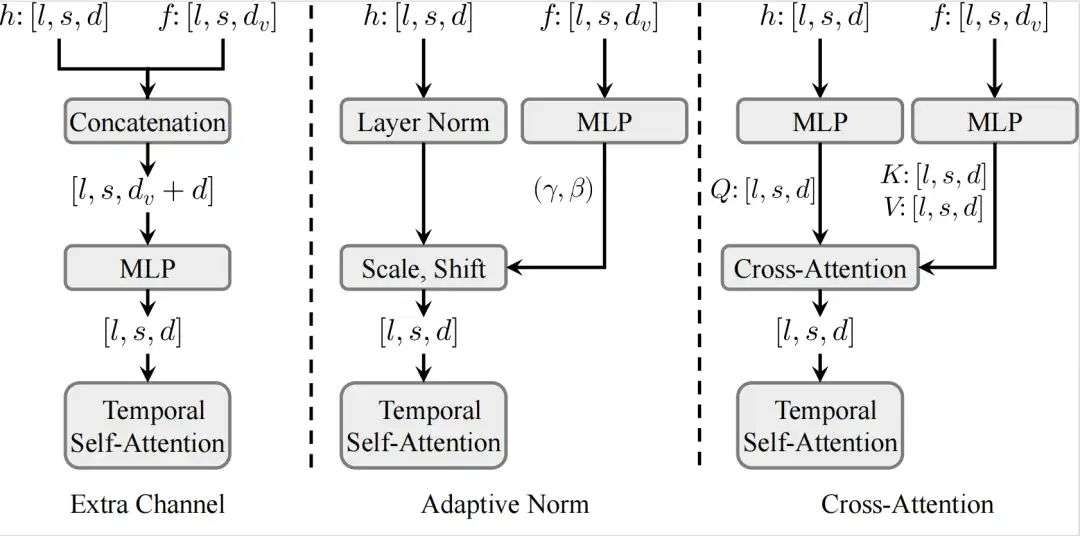
如下图所示,Tora包括一个Spatial-Temporal Denoising Diffusion Transformer,(ST-DiT,时空去噪扩散变换器)、一个Trajectory Extractor(TE,轨迹提取器)和一个Motion-guidance Fuser(MGF,运动引导融合器)。
Tora 的 ST-DiT 继承了 OpenSora v1.2 的设计,将输入视频在时空维度上压缩成Spacetime visual patches(时空视觉补丁),再通过交替的spatial transformer block(空域变换器块) 和temporal transformer block(时域变换器块)进行噪声预测。
为了实现用户友好的轨迹控制,TE 和 MGF 将用户提供的轨迹编码为多层次的Spacetime motion patches(时空运动补丁),再通过自适应归一化层将这些patches无缝整合到每个DiT block中,以确保生成视频的运动与预定义的轨迹一致。
Motion-guidance Fuser:运动引导融合器
有了与visual patches共享特征空间的运动特征后,下一步需要将多层次的运动特征引入到相应的 DiT 块中,使生成的运动能够遵循预定义的轨迹,同时不影响原有的视觉效果。
Tora 参考了transformer的多种特征注入结构,如上图所示,Motion-guidance Fuser实验了包括额外通道连接、自适应归一化和交叉注意力三种架构。
实验结果显示,自适应归一化在视觉质量和轨迹跟随程度方面表现最佳,同时计算效率最高。自适应归一化层能够根据多样化的条件(文本&轨迹&图像)动态调整特征,确保视频生成的时间一致性。这在注入运动线索时尤为重要,能够有效维持视频运动的连续性和自然性。
实验结果
实现细节与测试数据
Tora 基于 OpenSora v1.2 权重,使用分辨率从 144p 到 720p、帧数从 51 帧到 204 帧不等的视频进行训练。为平衡不同分辨率和帧数的训练 FLOP和所需内存,批次大小调整为 1 到 25。
训练过程分为两个阶段,首先使用密集光流进行 2 个 epoch 的训练,然后使用稀疏光流进行 1 个 epoch 的微调。
在推理过程中,精选了 185 个包含多样化运动轨迹和场景的长视频片段,作为评估运动可控性的新基准。
结语:AI视频生成可控性再上一层
在AI视频生成时长、质量已经达到一定程度之际,如何让生成的视频更可控、更符合需求,是当下的重要命题。
在精准度、可控性和资源利用效率等方面的持续优化下,AI视频生成产品的使用体验将迎来新的阶段,价格也会更加亲民,让更多创作者参与进来。
高性价比GPU算力:
https://www.ucloud.cn/site/active/gpu.html?ytag=gpu_wenzhang_0805_shemei







![无缝融入,即刻智能[4]:MaxKB知识库问答系统[进一步深度开发调试,完成基于API对话,基于ollama大模型本地部署等]](https://img-blog.csdnimg.cn/img_convert/d6ef99abe1d0390259fd1c2ae2eef82a.jpeg)