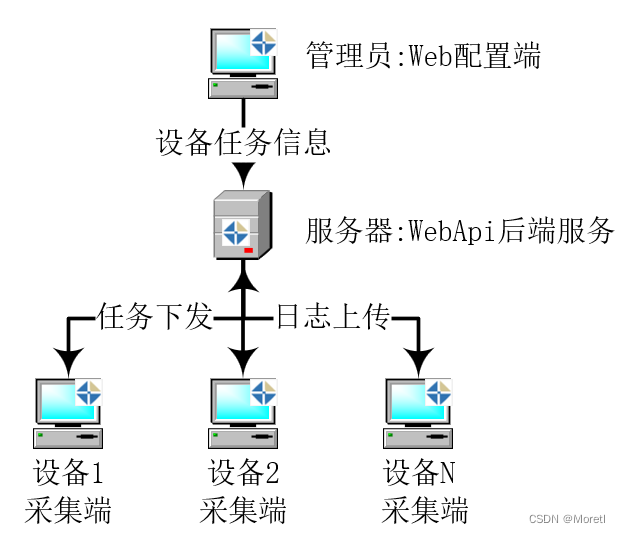
Lambda架构

- nginx (b) Hbase (c)Spark Streaming (d)Spark (e)MapReduce
(f)ETL (g)MemSQL (h)HDFS (i)Flume (k)数据存储层
(l)kafka数据采集层 (m)业务逻辑层
将上面分别填入其中(9分)
1 d spark
2 e MapReduce
3 k 数据存储层
4 g MemSQL
5 h HDFS
6 I kafka
7 flume
8 ETL
解析:
ETL采用Sqoop/Datax来数据迁移到分布式存储文件HDFS,之后通过Spark和MapReduce工具离线计算处理,将结果视图发送到hive数据仓库,将结果存储到HDFS。
Nginx则是用flume采集信息,通过kafka实时数据集成,Spark Steaming计算处理分析,把结果存储到MemSQL/Doris。
合并计算则是用Spark来将批处理和实时处理的数据合并存储到HBase。


数据源:HDFS
批处理层:Offline Hive/MR/Spark
加速层:Flink/Storm
数据迁移:Collector/DataX/Sqoop
服务层:MongoDB/HBase/Redis OneDataAPI
Kappa架构
Kappa则是去掉了批处理层,所以处理历史数据的能力比Lambda架构差点。
业务和技术需求方面:
Lambda架构依赖Hadoop,Spark,Storm技术。
Kappa依赖Flink计算引擎,偏流式计算。
Hadoop里的HDFS是用于海量存储,而MapReduce则是用于海量计算。












![[论文阅读笔记34] LISA (LISA: Reasoning Segmentation via Large Language Model) 代码精读](https://i-blog.csdnimg.cn/direct/5279bced92d84a04a2b4f732146eeaa7.png)


