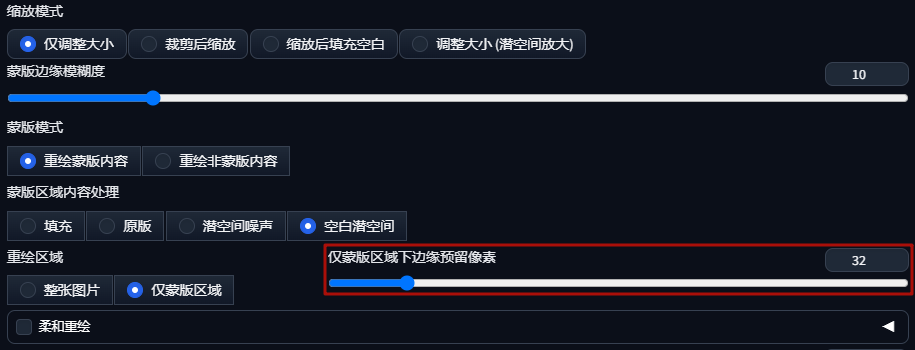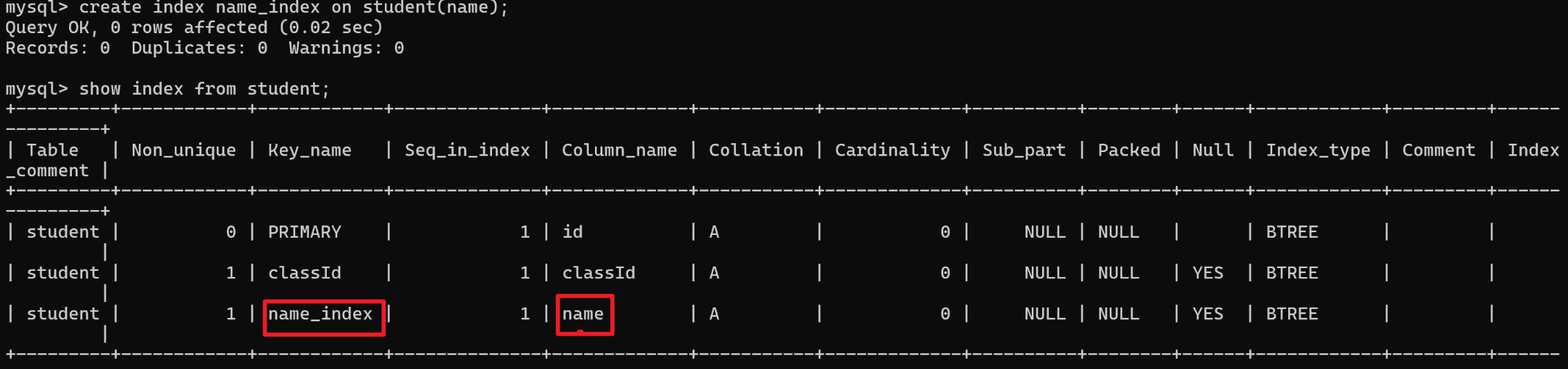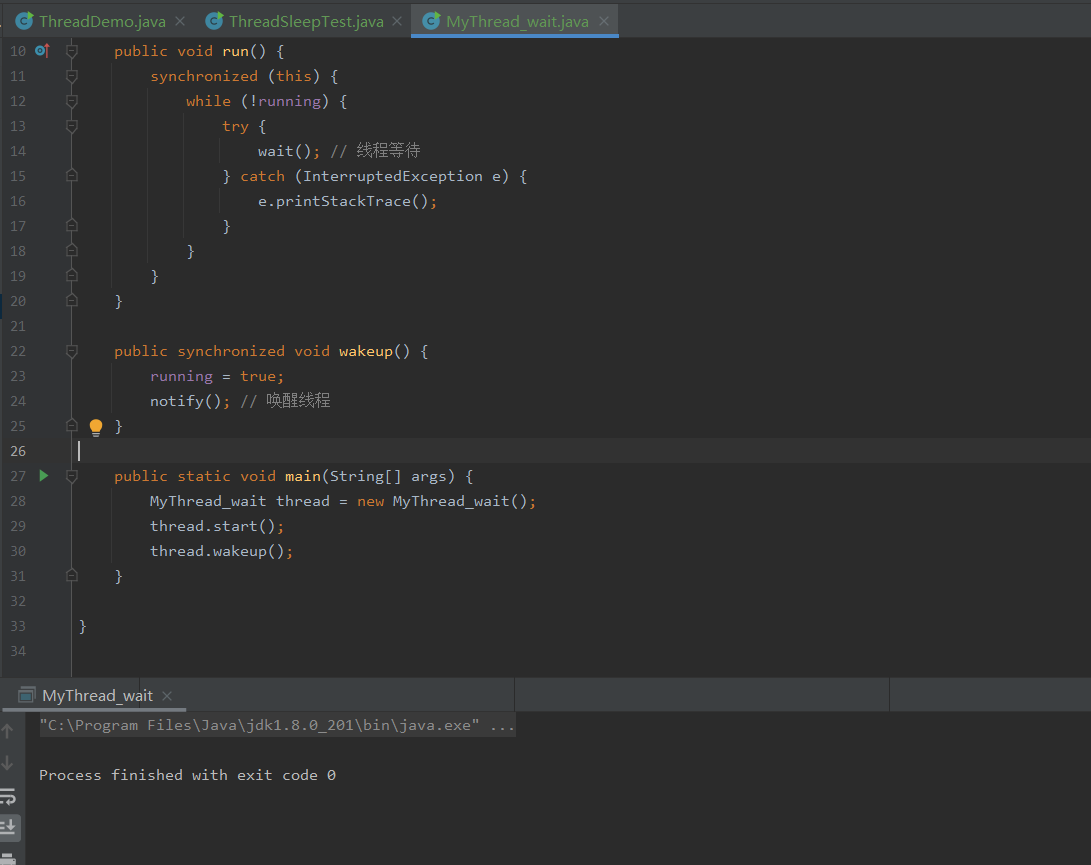
最近,OpenAI宣布推出Search GPT,这基本上是Perplexity的改版,但直接由OpenAI开发。这让我非常高兴,因为与其让第三方使用他们的模型并提供封装服务,不如他们自己来做。我一直不喜欢Perplexity,因为他们声称他们做了很多事情来生成结果,因此向用户收费20美元,但实际上他们只是将GPT-4与Google搜索结果结合起来。每当我制作关于本地替代品的视频时,总有一些被洗脑的人会说“没有什么能打败Perplexity”,但现在OpenAI自己做了这件事,我至少感到很开心,但我打赌Perplexity的投资者现在不会高兴。
今天的视频不是关于这个的。今天我要告诉你如何在你的电脑上本地设置一个Perplexity克隆,使用的是Llama 3.1。这非常类似于Perplexity,而且完全免费和本地化。那么我会用什么来制作它呢?我会使用# Perplexica来实现这一点,设置起来超级简单,我们可以将其与ollama和Groq集成起来。我将向你展示如何使用Llama 3.1 8B模型和Gro的70B模型进行配置。最后我还会告诉你如何使用405B模型。
第一步:安装ollama
首先,打开ollama,点击下载按钮,选择你的操作系统并进行安装。安装完成后,前往模型页面,选择Llama 3.1并复制安装命令,将其粘贴到你的终端,模型将开始安装。安装完成后,你会在终端中看到这个聊天界面,发送一条消息并检查是否有效。
第二步:安装embedding model
我们还需要在ollama中安装一个embedding model。。这将把嵌入模型安装到你的电脑上。完成后,前往Docker,下载Docker并按照屏幕上的说明进行安装。我们需要Docker来安装Perplexica。
第三步:克隆Perplex仓库
完成Docker安装后,克隆 Perplexica 并按照readme文档进行配置。,向下滚动并复制这个命令。现在打开你的终端并将其粘贴进去,这将把仓库克隆到你的电脑上。现在在VS Code中打开克隆的文件夹,将sample.config.toml文件重命名为config.toml
git clone https://github.com/ItzCrazyKns/Perplexica.git
Rename the sample.config.toml file to config.toml
docker compose up -d
第四步:创建Docker容器
完成重命名后,回到终端,现在CD进入克隆的文件夹并运行这个命令,这将为你创建一个Docker容器并启动它。完成后,你可以在浏览器中打开端口3000,你会看到这个页面。你会看到一个错误,不用担心,只需进入设置选项并将这个URL添加到Al API基URL中。完成后保存,现在你会看到这个页面正常打开了。
第五步:配置Perplex
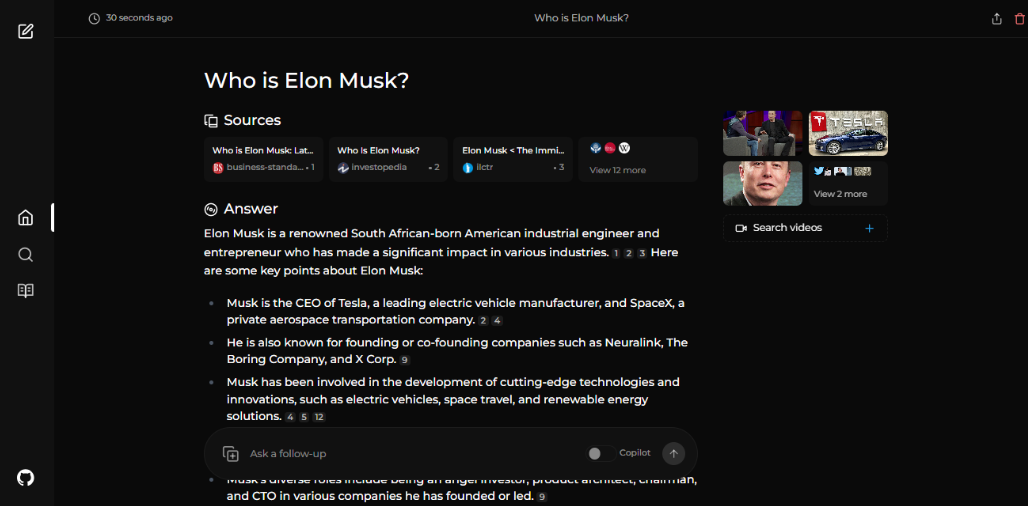
但我们仍然不能使用它,所以进入设置选项,在模型中选择Llama 3.1,在嵌入提供商中选择Ollama,然后选择刚刚安装的embedding模型。一旦完成,我们现在可以使用它了。现在发送一条消息,你会看到它正常工作。你会得到文章、图片、视频等,这非常酷。你还可以在这里询问后续问题,这也非常酷。
使用Groq进行配置
如果你不想本地运行LLM但仍想使用Perplex,你可以使用Groq。Groq添加了Llama 3.1 8B和70B模型,你可以通过API免费使用它,但会有一点速率限制。要与Gro进行配置,只需打开Groq Cloud,注册一个帐户,在API密钥选项中创建一个API密钥并复制它。现在回到Perplex,打开设置并输入API密钥,保存它,重新打开设置并将提供商更改为Groq,现在在这里选择Llama 3.1模型,保存它,现在你可以开始使用Groq了,你会看到与Perplexity相同的速度,但质量极高且免费。
使用Together AI进行配置
接下来是如何使用405B模型来设置它。我将使用Together AI,因为他们提供一些免费积分,之前是25美元的积分,但现在他们减少到了5美元,我觉得这还可以,因为你仍然可以进行大约100次请求。搜索Together AI,注册并前往设置选项,复制你的API密钥。现在回到Perplex,点击设置并将提供商更改为自定义OpenAI,现在输入这个URL作为基本URL和这个模型名称,并在这里输入你的API密钥。完成后保存,现在你可以开始使用Llama 3.1 405B,这显然也很酷。
总结
以上就是如何使用Llama 3.1完全免费和本地化地设置你自己的Perplexity克隆的步骤。因为最终它只是一个LLM和Google搜索API。此外,它使用CRX NG作为搜索引擎,这也是开源的并在你安装时直接安装,所以你不需要任何API来进行搜索,这也非常酷。