论文:INF-LLaVA: Dual-perspective Perception for High-Resolution Multimodal
代码:https://github.com/WeihuangLin/INF-LLaVA
出处:厦大
时间:2024.07.23
贡献:
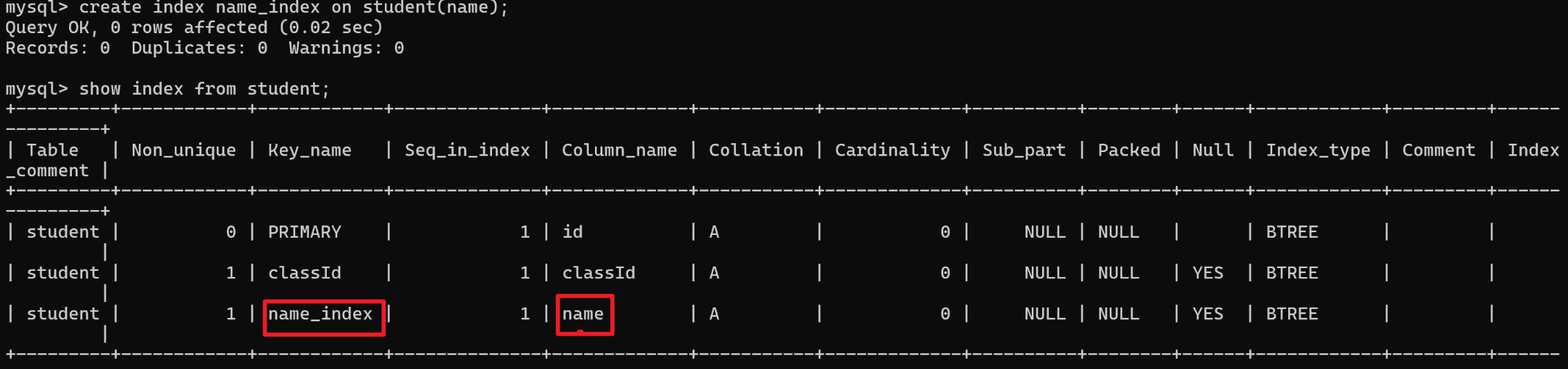
- 提出了双视角裁剪模块(Dual-perspective Cropping Module),在进行大分辨率图像切分的时候同时考虑全局和局部切分,能够保留细节信息的同时保留纹理信息
- 提出了双视角增强模块(Dual-perspective Enhancement Module),能够又快又好的融合全局和局部的特征,提升模型效果
一、背景
大分辨率的图像能够更好的保持图像细节,减少模型幻觉,对细粒度感知任务很重要,但大分辨率图像意味着更多的图像 token,增加处理时间和复杂度,所以,如何实现对分辨率和资源限制的平衡对多模态模型是很重要的。
为了解决上述矛盾,现有的方法一般使用两种方式:
- cropping-based 方式:由于预训练的 ViT 模型都是低分辨率的,且计算量和分辨率呈平方关系,所以 Internlmxcomposer2-4khd、Monkey、Sphinx、 Llava-uhd 都将大分辨率图像切分成小图,然后使用 ViT 对小图进行编码。
- dual-encoder 方式:上面切割的方式会丢失不同小图之间的关联,但是理解不同目标之间的关系对模型来说是很重要的,LLava-HR、 Mini-gemini 提出了 dual-encoder 的方法,使用预训练的 ConvNeXt 来编码高分辨率的图,如图 1b。但这种方法需要额外的预训练模型和编码,会提升耗时。

本文提出的 INF-LLaVA 是一个又好又快的模型,如图 1c 所示:
- 作者引入了Dualperspective Cropping Module (DCM),能够同时从 local 和 global 两个角度来进行高分辨率图像的切分
- local 切分:直接将大图切分成小图,保持细节和内容连续性不变
- global 切分:将相邻的像素分配到不同的子图中,每个子图都包含全局信息,但会丢失部分细节信息
- 这种双切分方式能够在 cropping 阶段同时保留细节和全局信息
- 作者引入了Dual-perspective Enhancement Module (DEM) ,能够促进 local 和 global 信息的交互
- 一般的通用方法是使用 cross-attention 来直接融合两种特征,但高分辨率的特征在进行平方次的计算的话容易导致 out-of-memory 问题。因此,本文使用了一个资源高效的策略,即将这些子图像特征基于二维先验(例如空间位置)重新拼接回原始图像的形状,然后从局部视角重新裁剪成多个子图像,这些新生成的子图像与对应的原始局部视角子图像进行匹配
高分辨率多模态模型的现状:
-
高分辨率图像为多模态大语言模型(MLLMs)提供了显著的优势,因为它们能够捕捉图像中详细的物体信息和复杂的物体间关系。然而,直接将高分辨率图像输入到视觉编码器中会导致难以承受的计算开销,这主要是由于Transformer架构[92]所涉及的二次复杂性以及视觉标记数量的大幅增加。为了缓解这一问题,现有的高分辨率MLLMs可以分为两种主要类型:基于裁剪的方法和双编码器方法,如图1(a)和图1(b)所示。
-
基于裁剪的方法[24, 51, 53, 99] 将图像划分为多个不重叠的块,并分别将每个块输入到视觉编码器,从而获取局部区域的视觉特征。为了确保每个块保持接近1:1的纵横比,LLaVA-UHD [96] 在裁剪操作期间引入了各种块策略。此外,为了单独建模每个块的信息,Monkey [49] 使用LoRA [35] 对视觉编码器进行微调,以适应每个特定块。尽管这些方法有其优点,但通过将完整图像分割成独立子图像,会破坏图像信息的全局连贯性。因此,一些研究人员提出了双编码器方法来保持全局信息的完整性。
-
双编码器方法 利用辅助视觉编码器来增强高分辨率图像理解,而不会显著增加视觉标记数量。例如,Vary [94] 和 Deepseek-VL [60] 在高分辨率视觉编码器中使用Segment Anything Model (SAM) [40] 来更好地捕捉高分辨率信息。同时,MiniGemini [47] 和 LLaVA-HR [64] 使用在大规模LAION-2B数据集[80]上预训练的ConvNeXt [57] 来增强Vision Transformer (ViT) 提取的视觉特征。然而,双编码器方法需要额外预训练的视觉编码器来处理高分辨率图像。无论是SAM,在SA-1B数据集上预训练,还是ConvNeXt,在LAION-2B数据集上预训练,都需要大量计算资源,总计数万GPU小时,这可能会成本过高。
-
本文INF-LLaVA,是一个通过整合创新的双视角裁剪模块和新的双视角增强模块来解决这些挑战的新框架。我们的方法不仅确保了计算资源的效率,还全面捕捉了局部和全局图像细节,从而提升了高分辨率MLLMs 的能力。
二、方法
INF-LLaVA 的框架如图 2 所示

第一步:双视角切分模块 DCM,其中 loc 和 global 分别表示局部和全局子图,N 是每个视角切分的子图数量

第二步:将每个 local 和 global 子图都分别送入 vision encoder

第三步:使用 2D 位置先验再将 local 和 global 子图特征重新组合到高分辨率图像特征,即 high resolution visual features F l o c F^{loc} Floc 和 F g l o F^{glo} Fglo 如下

第四步:为了对 local 和 global 特征进行高效的交互,作者使用多视角增强模块 来让 loca 和 global 的特征进行融合,得到 dual-enhanced 后的特征,其中 F p o o l F_{pool} Fpool 是平均池化,用于降低 visual token 的数量,加速训练和推理的同时降低计算量。

第五步:使用 connector 将 dual-enhanced visual features 进行映射,映射的目标是将视觉特征和文本特征进行对齐。然后将指令 T i n s T_{ins} Tins 进行 tokenizer 后的文本 token 和 visual token 进行 concat,送入 LLM ,得到最终的响应如下:

2.1 Dual-perspective Cropping Module
DCM 提出的目标是实现对高分辨率图像的有效切分,即将大图 I ∈ R W h × H h × 3 I \in R^{W_h \times H_h \times 3} I∈RWh×Hh×3 切分成子图 I i ∈ R W l × H l × 3 I_i \in R^{W_l \times H_l \times 3} Ii∈RWl×Hl×3,切分后的子图大小就是使用的 vision encoder 预训练时使用的图像大小,如 CLIP-ViT-large-patch14-336 的 W l = H l = 336 W_l = H_l = 336 Wl=Hl=336
1、Local-perspective Cropping
给定大分辨率图像 I ∈ R W h × H h × 3 I \in R^{W_h \times H_h \times 3} I∈RWh×Hh×3:
确定大图尺寸和子图尺寸的关系,下面的符号是向下取整,
n
W
n_W
nW 和
n
H
n_H
nH 是 width 和 height 方向上子图的个数

大图会被切分为 n W × n H n_W \times n_H nW×nH 个子图,令 i ∈ [ 0 , n W × n H − 1 ] i \in [0, n_W \times n_H-1] i∈[0,nW×nH−1],则行和列如下:

则每个子图的 bbox 如下:

2、Global-perspective Cropping
全局视角的切分是为了捕捉粗糙的纹理信息,即保留不同目标的空间关系,能够帮助模型理解宏观信息
给定大分辨率图像的大小和 vision encoder 预训练图像的大小,切分数量计算和局部子图一样:

对于子图的第 i 行和第 j 列, pixel indices 如下,其中 (x,y) 对应的是大分辨率图中的 pixel indices

因此,子图 I i j g l o I_{ij}^{glo} Iijglo 中的每个像素 (u, v) 和大图的映射关系如下:

2.2 Dual-perspective Enhancement Module
上面对每个子图使用 DCM 提取了特征之后,需要对局部和全局子图特征分别进行组合,如图 3 所示,分别会按原图中切割出来的顺序进行重组:



1、Global-Perspective Enhancement
组合成大图特征后,需要对全局和局部的两组特征进行交互,如果直接使用 cross-attention 的话,高分辨率的特征图会导致计算溢出,所以本文提出了一个高效的交互方式。
对于 global 视角的特征图的增强,如图 4 所示,先从 global 视角特征图中 crop 出 local 和 global 视角特征如下:

为了将局部特征注入全图特征子图,作者将对应的 local 和 global 子图特征进行 cross-attention

然后再将 V 1 g l o , . . . , V N g l o V_1^{glo}, ..., V_N^{glo} V1glo,...,VNglo 进行结合,得到 globallyenhanced feature:

2、 Local-Perspective Enhancement
Local-Perspective Enhancement 是为了将全局特征注入局部特征中,同上,先对 local 特征图进行全局和局部的切分如下:

之后,使用 cross-attention 来对切分后的 local 和 global 子图特征进行交互融合:

然后再将
V
1
l
o
c
,
.
.
.
,
V
N
l
o
c
V_1^{loc}, ..., V_N^{loc}
V1loc,...,VNloc 进行结合,得到 local-enhanced feature:

3、Dual-perspective Fusion
在得到了 global-enhanced feature V g l o V_{glo} Vglo 和 local-enhanced feature V l o c V_{loc} Vloc 后,需要对这两组特征进行融合,作者使用 concat 的方式进行特征组合
作者使用了两个独立的 embedding layers 来降低特征的维度,这步对降低计算量很关键,且能够找出重要的特征,embedding 过程如下:

然后,将编码后的 global 和 local 特征在 channel 维度上进行 concat:

三、效果
3.1 训练细节
- vision encoder:CLIP-ViT-L/14
- LLM:LLaMA3-8b
- 训练方式:
- pretrain:为了对齐 vision encoder 和 LLM,本阶段会冻结 vision encoder 和 LLM,主要是训练 DEM 和 projector,训练数据为 CC-595K,训练 1 epoch,AdamW,1x10-3 学习率,cosine 学习率下降,global batch=256
- SFT:为了精细化调整模型在下游任务上的指令跟随能力,本阶段会冻结 vision encoder,训练 DEM、projector、LLM。训练数据为 e LLaVA-656K,学习率为 2x10-5,batch size=128

3.2 定量对比

3.3 定性对比
1、不同分辨率的对比

2、和 LLaVA-1.5 对比


3、消融实验
不同分辨率的对比:


DEM 只使用 global、local,和 global、local 都使用的对比:

DEM 不同融合方式的对比: