一、HashMap插入与删除
通过将key转换为hashCode(int),通过hashCode计算下标,int index = hashCode & (length - 1),从而实现插入与删除。
二、Hash冲突
Java8之前:通过数组+链表的数据结构解决hash冲突,头插法。
Java8之后:数据+链表+红黑树,尾插法,因为单链表如果元素太多,查找效率低。
优化:HashMap的容量必须是2的次幂,减少hash冲突。
三、HashMap线程安全问题
HashMap是线程不安全的。
多线程中可以使用HashTable,它是线程安全的。
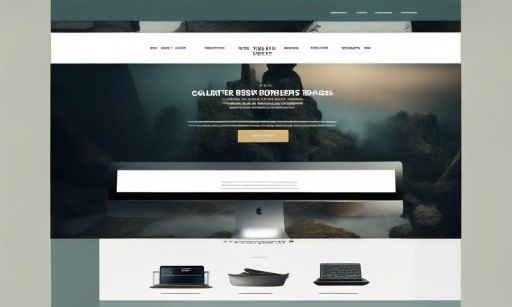
HashTable的问题:
synchronized加在方法上,方法锁,锁住整个数组+链表/红黑树,效率低。synchronized是对象内置锁,由JVM管理开锁&关锁。多个线程同时操作HashTable,只有一个线程能获得锁往下执行。
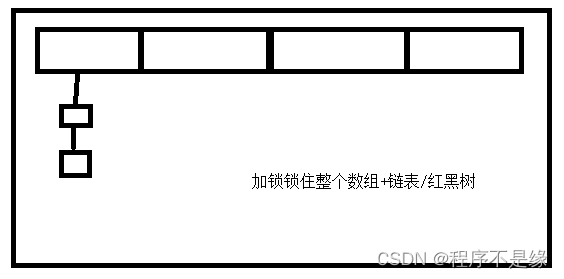
多线程中可以使用ConcurrentHashMap,它也是线程安全的。
synchronized加在代码块上,代码块锁,锁住链表,只有在多个线程同时操作一个链表是才会产生性能问题。
四、HashMap与SparseArray的对比
结论:SparseArray占用内存更小,get/put/remove性能更优。
1.HashMap
1.1.时间
put:
- 根据 key 计算hashCode值(int),hashCode与数组长度相与(&)计算元素的index(下标),如果index相同,就会产生hash冲突。
- 比较hashCode和key是否相等,如果相等,替换旧值,否则插入新的节点,形成链表(耗时)
- 如果数组的容量已经达到阈值,则进行数组的扩容,根据hash值计算元素下标,把旧数组元素复制到新数组中(耗时)。
- 简单来说就是插入比对耗时和扩容耗时(rehash)导致HashMap性能相对较差。
get:
- 计算hash值,用hash值计算index与put相同。
- 如果key相等(==) 或者 hash值相等&&key相等(equals),则返回查到的值,否则返回null。
- 简单来说也是查找比对耗时。
1.2.空间
- key是任意Object类型,比较耗内存。
- HashMap有阈值(0.75F),当HashMap的元素数量达到:容量 * 0.75F,数组就需要扩容,浪费了部分内存空间。
2.SparseArray
两个数组:int[] mKeys 和 Object[] mValues。
2.1.时间
put:
二分查找确定key的index(mKeys数组是有序的):
- 有该key,替换value;
- 没有该key,如果index小于数组长度&&mValues数组对应index位置为DELETE,替换index位置的key和value(删除时mValues数组标记为DELETE);
- 上述条件都不满足,插入新的key和value,其后的元素往后移动。
get:
二分查找得到key的index,根据index获取value。
remove:
删除并不是真正的删除,而是标记为删除(mValues数组标记为DELETE),增删多的情况效率高。
总结:效率较高。
2.2.空间
mKeys数组是int类型的,更加节省内存。