repmgr需要在集群中每个节点上以扩展的形式安装插件,运行在每个节点上的repmgrd可以监控复制以及执行故障转移或切换等操作增强 PostgreSQL 的内置复制功能。
如何可靠快速的监控主节点故障一般是所有数据库高可用程序中都会有的环节,本篇内容主要介绍不同角色的节点如何监控主节点是否存活。
函数入口
通过命令 repmgrd -f repmgr.conf 启动repmgrd后台监控程序时,进入程序的主函数 main(repmgrd.c文件)函数中,
在main 函数主要是处理命令行参数,获取本地节点的信息
/* Retrieve record for this node from the local database */
record_status = get_node_record(local_conn, config_file_options.node_id, &local_node_info);通过SQL查询repmgr数据库中 nodes表 获取本地节点信息 ,查询SQL如下
appendPQExpBuffer(&query,
"SELECT " REPMGR_NODES_COLUMNS
" FROM repmgr.nodes n "
" WHERE n.node_id = %i",
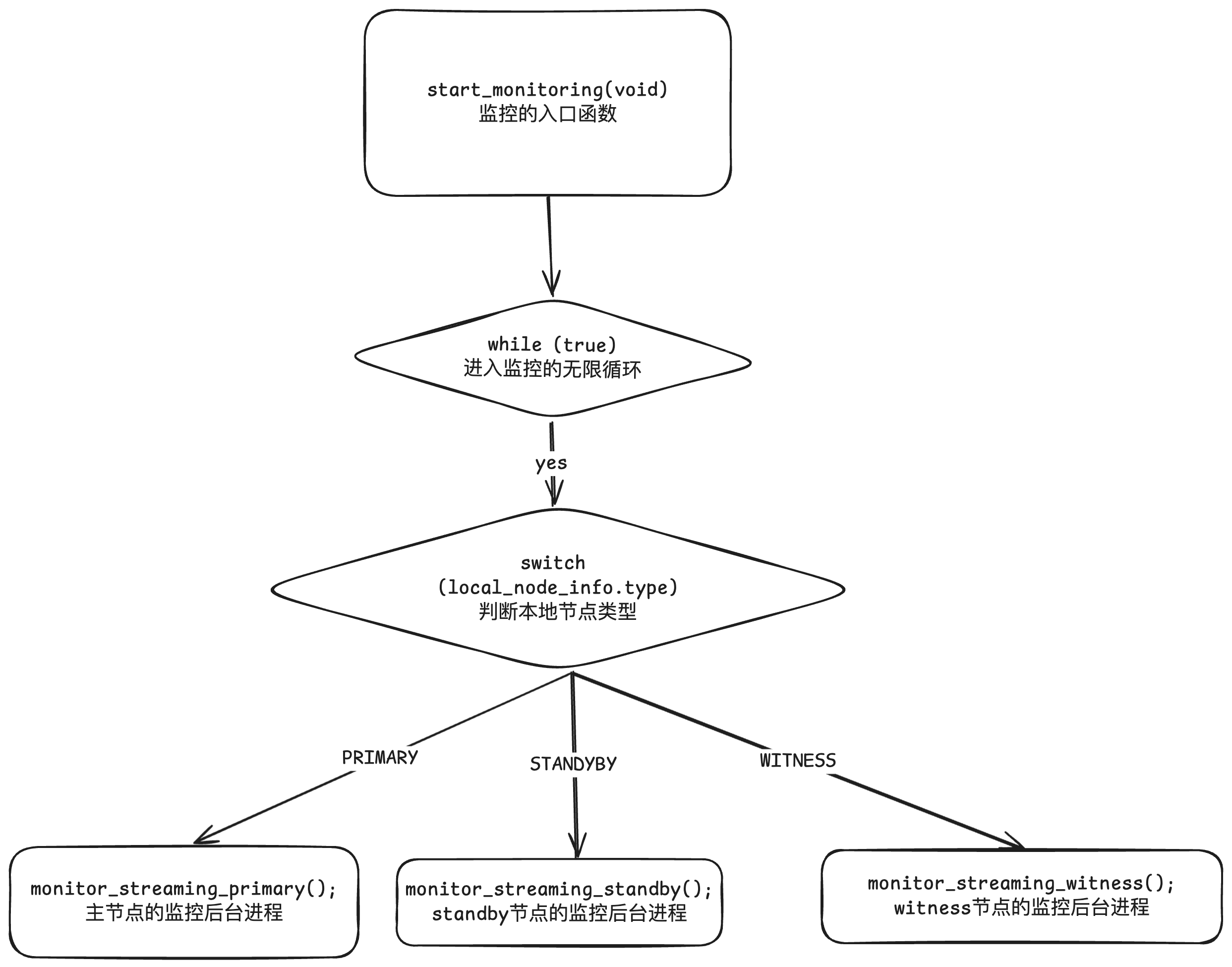
node_id);通过函数 start_monitoring(void) 启动对本地节点的监控,
首先会判断本地节点的角色,根据不同的节点角色进入到不同的监控函数中:
primary节点 对应 monitor_streaming_primary()
standby节点 对应 monitor_streaming_standby()
witness节点 对应 monitor_streaming_witness()
static void
start_monitoring(void)
{
log_notice(_("starting monitoring of node \"%s\" (ID: %i)"),
local_node_info.node_name,
local_node_info.node_id);
log_info(_("\"connection_check_type\" set to \"%s\""), print_connection_check_type(config_file_options.connection_check_type));
// 进入一个无限循环
while (true)
{
// 根据节点的不同角色 ,进入到不同的监控处理分支
switch (local_node_info.type)
{
// 主节点
case PRIMARY:
monitor_streaming_primary();
break;
// 备节点
case STANDBY:
monitor_streaming_standby();
break;
// 见证节点
case WITNESS:
monitor_streaming_witness();
break;
case UNKNOWN:
/* should never happen */
break;
}
}
}
monitor_streaming_primary
如果是节点角色是PRIMARY,会进入到 monitor_streaming_primary 分支进行监控本地的主节点,以下是主要流程
1 重置节点的投票信息,设置节点当前不参与投票 VS_NO_VOTE
执行函数 reset_node_voting_status();
reset_node_voting_status();该函数会调用执行数据库的函数 repmgr.reset_voting_status()
SELECT repmgr.reset_voting_status()在数据库中查看 函数 reset_voting_status 定义,它告诉PostgreSQL查找‘libdir/repmgr动态链接库(DLL 或 so 文件),并在其中查找名为repmgr_reset_voting_status` 的函数。
repmgr=#\sf reset_voting_status
CREATE OR REPLACE FUNCTION repmgr.reset_voting_status()
RETURNS void
LANGUAGE c
STRICT
AS '$libdir/repmgr', $function$repmgr_reset_voting_status$function$
函数解释
-
CREATE OR REPLACE FUNCTION: 如果函数已存在,则替换它;如果不存在,则创建它。
-
repmgr.reset_voting_status(): 函数名,表明这个函数属于
repmgrschema,并且函数名为reset_voting_status。
-
RETURNS void: 函数不返回任何值。
-
LANGUAGE c: 函数是用 C 语言编写的。
-
STRICT: 如果任何输入参数为 NULL,则函数不会执行并立即返回 NULL。
-
**AS 'libdir/repmgr′,functionrepmgrresetvotingstatusfunction∗∗:指定了函数的实现。这里,它告诉PostgreSQL查找‘libdir/repmgr
动态链接库(DLL 或 so 文件),并在其中查找名为repmgr_reset_voting_status` 的函数。
查看 repmgr 源码中的函数 repmgr_reset_voting_status
Datum
repmgr_reset_voting_status(PG_FUNCTION_ARGS)
{ // 如果 shared_state 不为空 ,说明不是第一次启动?
if (!shared_state)
PG_RETURN_NULL();
// 获取共享的锁
LWLockAcquire(shared_state->lock, LW_SHARED);
/* only do something if local_node_id is initialised */
// 如果local_node_id 是初始化的值 ,则做一些操作
if (shared_state->local_node_id != UNKNOWN_NODE_ID)
{ // 释放共享锁
LWLockRelease(shared_state->lock);
// 获取排他锁
LWLockAcquire(shared_state->lock, LW_EXCLUSIVE);
// 将该节点的投票状态设置为 VS_NO_VOTE 不参与投票
shared_state->voting_status = VS_NO_VOTE;
// 将后端节点的node id 设置为UNKNOWN_NODE_ID
shared_state->candidate_node_id = UNKNOWN_NODE_ID;
// follow_new_primary 设置为 不
shared_state->follow_new_primary = false;
}
// 释放锁
LWLockRelease(shared_state->lock);
PG_RETURN_VOID();
}指针类型,共享内存的结构体
static repmgrdSharedState *shared_state = NULL;shared_state 结构体
typedef struct repmgrdSharedState
{
LWLockId lock; /* protects search/modification */
TimestampTz last_updated;
int local_node_id;
int repmgrd_pid;
char repmgrd_pidfile[MAXPGPATH];
bool repmgrd_paused;
/* streaming failover */
int upstream_node_id;
TimestampTz upstream_last_seen;
NodeVotingStatus voting_status;
int current_electoral_term;
int candidate_node_id;
bool follow_new_primary;
} repmgrdSharedState;投票状态是一个枚举类型
typedef enum
{
VS_UNKNOWN = -1,
VS_NO_VOTE,
VS_VOTE_REQUEST_RECEIVED,
VS_VOTE_INITIATED
} NodeVotingStatus;2 重置主节点的上游节点id 为 NO_UPSTREAM_NODE,因为主节点 不需要follow 任何其他节点
repmgrd_set_upstream_node_id(local_conn, NO_UPSTREAM_NODE);3 根据 startup_event_logged 的值,发送一个 repmgrd_start(如果repmgrd未启动) 或 repmgrd_reload (如果repmgred已启动) 的事件通知
4 获取下游子节点的信息
bool success = get_child_nodes(local_conn, config_file_options.node_id, &db_child_node_records);
查询下游节点的SQL语句
appendPQExpBuffer(&query,
" SELECT n.node_id, n.type, n.upstream_node_id, n.node_name, n.conninfo, n.repluser, "
" n.slot_name, n.location, n.priority, n.active, n.config_file, "
" '' AS upstream_node_name, "
" CASE WHEN sr.application_name IS NULL THEN FALSE ELSE TRUE END AS attached "
" FROM repmgr.nodes n "
" LEFT JOIN pg_catalog.pg_stat_replication sr "
" ON sr.application_name = n.node_name "
" WHERE n.upstream_node_id = %i ",
node_id);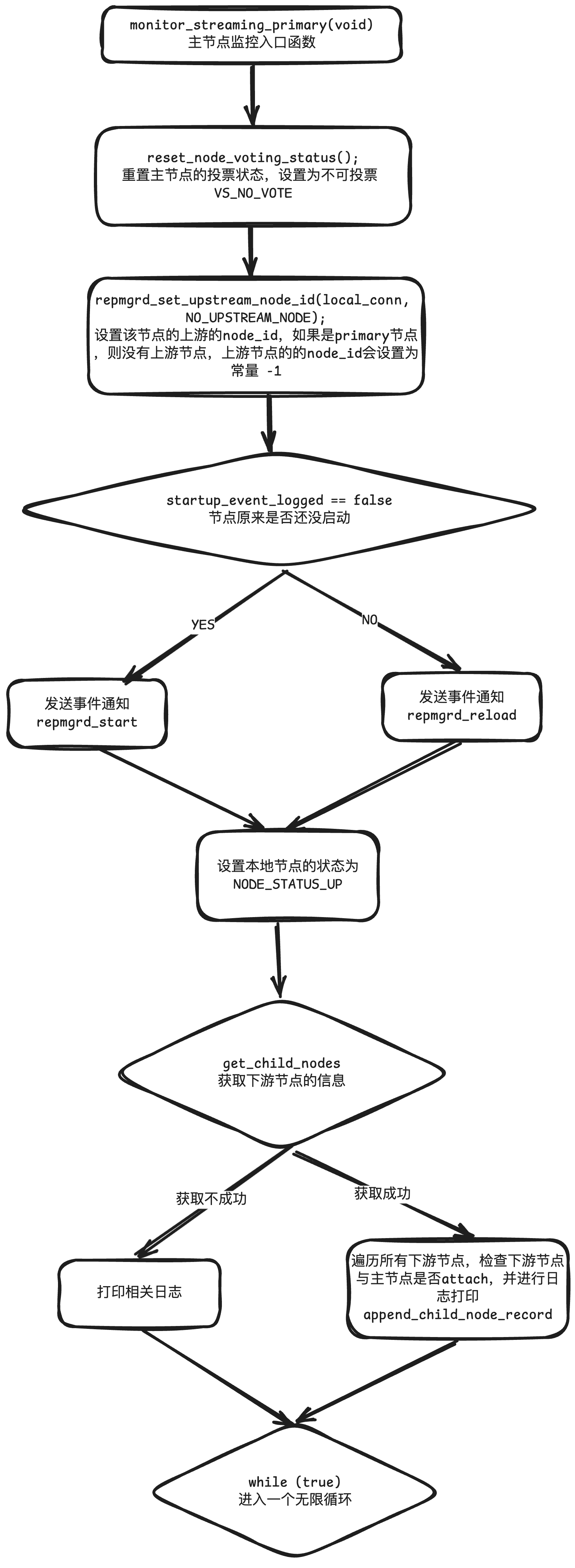
5 进入到while (true) 循环
51 (void) connection_ping(local_conn); 防止数据库连接过期失效 发出SELECT TRUE
5.2 check_connection(&local_node_info, &local_conn); 会对本地节点进行两次检查
5.3 如果节点状态是连接不正常的(PQstatus(local_conn) != CONNECTION_OK),而且原来的状态也被标记为启动的(NODE_STATUS_UP),会初始化一个本地节点不可用开始时间的变量(local_node_unreachable_start),并且把该变量设置为当前时间,然后发送一个 repmgrd_local_disconnect 事件通知,并将节点状态设置为 NODE_STATUS_UNKNOWN 。
5.4 为了防止网络抖动,会进行连接重试,最多重试多少次,每次重试间隔多长时间可以通过配置文件配置
try_reconnect(&local_conn, &local_node_info);5.5 如果在上面重试过程中,节点状态又变为可用了(NODE_STATUS_UP) ,则
-
计算当前节点不可用时间
-
当前节点设置为 UNKNOWN_NODE_ID
-
准备事件通知
-
记录日志
-
发送事件通知 repmgrd_local_reconnect
-
重新设置node_id 和 pid
-
如果不是在主节点,则函数返回,并进入到loop
5.6 如果节点状态还是不可用的,则将节点监控状态设置为降级监控模式 MS_DEGRADED,并初始化降级监控的开始时间为当前时间。
注意
1 主节点不参与投票?
2 主节点上的后台进程不会进行切换操作,可能考虑到 ,主节点服务器宕机,提升命令都需要在本地执行
3 主节点上的repmgrd 会获取下游节点信息,并检查下游节点的状态
4 主节点loop 部分逻辑
-
检查是否还是主节点 ,角色改变则函数返回return,重新判断节点
-
每隔log_status_interval秒记录日志
-
reload repmgr配置
-
监控休眠monitor_interval_secs秒
monitor_streaming_standby
忽略初始化部分 ,进入到 while(true)环节
1 执行检查上游节点连通性的函数 check_upstream_connection ,如果连接正常,更新内存中结构体 shared_state 中最新一次检查的时间
shared_state->upstream_last_seen = GetCurrentTimestamp();
shared_state->upstream_node_id = upstream_node_id;2 如果上游节点连接不正常 ,会尝试 reconnect_attempts 次 重新连接到上游节点
primary_node_id = try_primary_reconnect(&upstream_conn, local_conn, &upstream_node_info);
3 如果主节点的node_id 为 ELECTION_RERUN_NOTIFICATION ,则进行 主库切换 do_primary_failover ,函数返回
4如果主节点的node_id 不是 UNKNOWN_NODE_ID 且 不是 ELECTION_RERUN_NOTIFICATIO,则进行跟随新的主库 ,函数返回












![[RTOS 学习记录] 预备知识:C语言结构体](https://img-blog.csdnimg.cn/img_convert/a28b18c8e2db3f591f4c2ba1c38b10cf.png#pic_center)
![C语言程序设计-[5] 输入输出语句](https://i-blog.csdnimg.cn/direct/63e252177057449c84fb6d4a589a4d01.png)

