在一些特定应用领域,获取大规模且高质量标注的数据十分困难,比如医学图像分析。为了解决这个问题,研究者们提出了小样本目标检测。
小样本目标检测是一种结合了小样本学习和目标检测两者优势的技术,能够在有限的训练数据下,训练出具有更高实用性和泛化能力的模型。目前它在工业界与学术界都与各热门研究方向强相关,因此创新切入点很多,是个很好发论文的方向。
传统且主流的小样本目标检测方法有基于元学习、基于迁移学习、基于数据增强等。不过为了追求更高的性能和检测精度,现在我们更专注于探索新的改进方法,比如引入新的网络架构。
这次我就根据以上思路整理了12篇小样本目标检测最新paper,各位可以用作参考,包含几种主流方法以及最新的改进方法,开源代码已附。
论文原文+开源代码需要的同学看文末
新改进方法
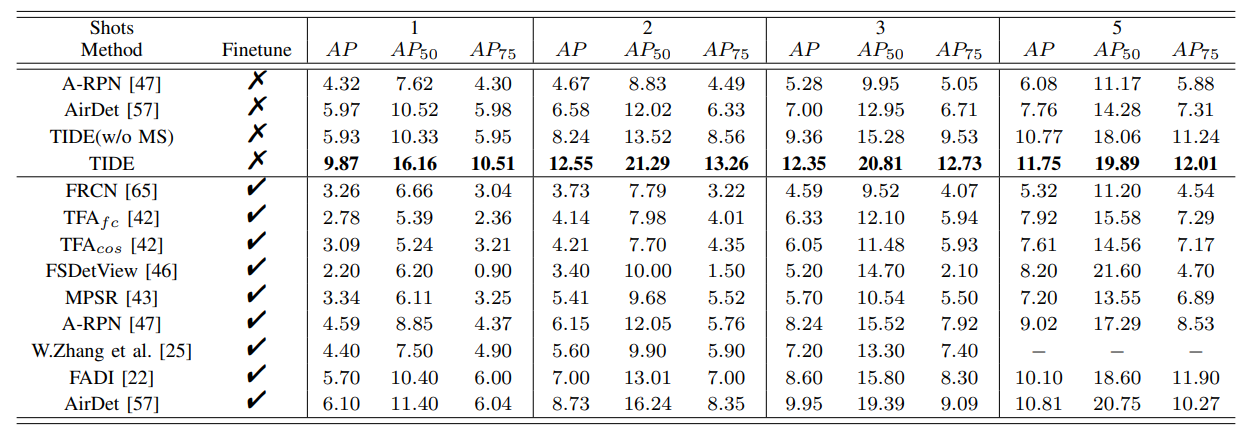
TIDE: Test-Time Few-Shot Object Detection
方法:论文提出了一种新颖的测试时间少样本目标检测(TIDE)方法,TIDE核心是在配置过程中不需要对模型进行微调,而是引入了一个不对称的架构,用于学习支持实例引导的动态类别分类器。此外,还提供了交叉注意力模块和多尺度调整器来增强模型性能。
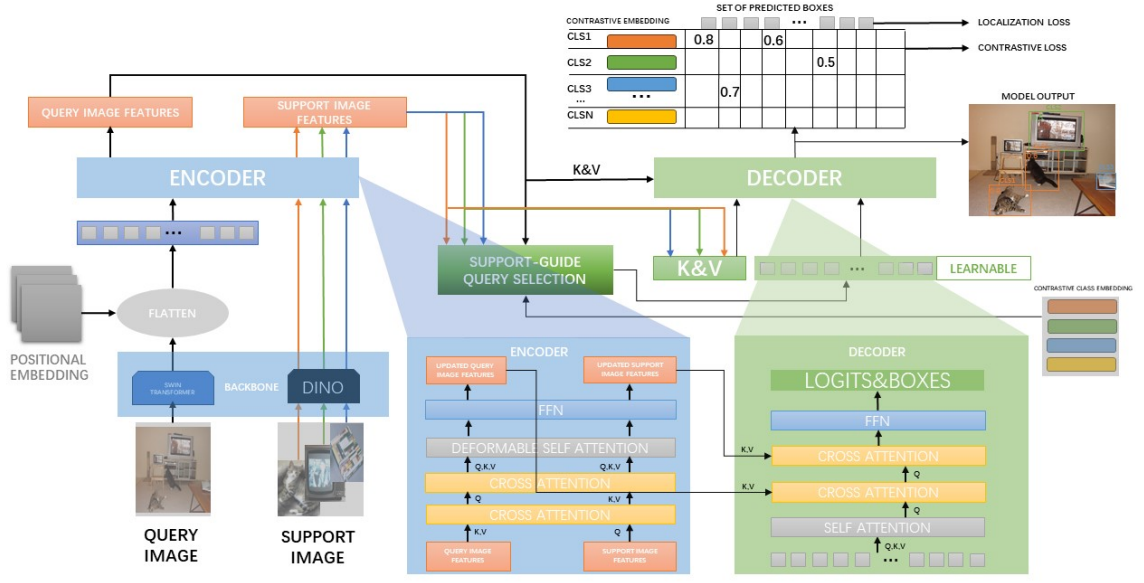
创新点:
-
提出了一种新的FSOD任务,即无需微调的测试时间少样本检测(TIDE),在现实场景中具有更高的适用性。
-
提供了一种基于非对称编码器的有效FSOD方法,首次尝试解决无需模型微调的TIDE问题。
-
实验结果表明,TIDE方法能够有效提升模型的FSOD能力,并且在所有任务中都优于微调方法的结果。
基于元学习
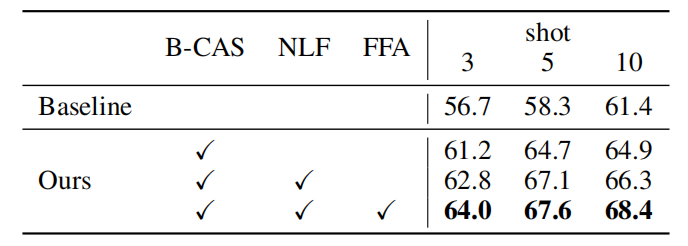
Fine-Grained Prototypes Distillation for Few-Shot Object Detection
方法:论文提出了一种新的小样本目标检测框架,通过细粒度的特征聚合(Fine-Grained Feature Aggregation, FFA)模块来改善特征的融合和表示,以实现更有效的知识转移和新类别的快速学习。
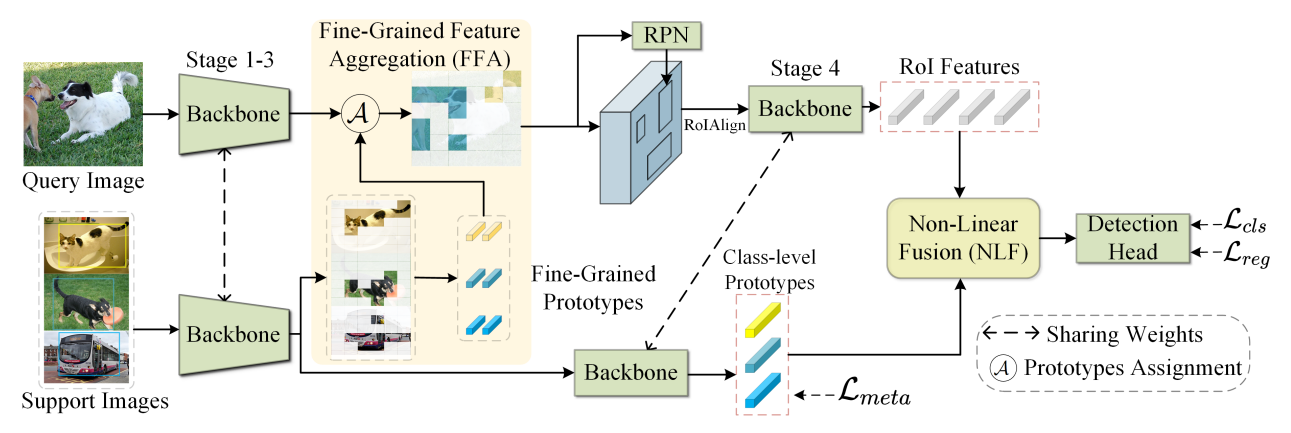
创新点:
-
提出一种新的方法,将支持特征(来自少量样本的类别)蒸馏成更具体和有代表性的细粒度原型。
-
引入一种新的采样策略,控制不同类别特征与查询特征的聚合比例,以保持正负样本的平衡,提高模型的泛化能力。
-
在微调阶段,提出了一种知识迁移方法,将基础类别的特征查询复制并适配到新类别上,解决了数据稀缺情况下的训练挑战。
基于迁移学习
Semantic Enhanced Few-shot Object Detection
方法:论文提出了一个基于迁移学习的小样本目标检测框架,利用语义嵌入来改善对于新类别的偏差表示,特别是在极低样本情况下的表示偏差问题。在Pascal VOC和MS COCO数据集上的实验证明了该方法的优越性,尤其是在低样本场景下。

创新点;
-
提出了一种基于fine-tuning的框架,利用语义嵌入来提高对新类别的泛化能力。该框架在新的fine-tuning阶段使用语义相似度分类器(SSC)代替线性分类器,并通过计算类别名称嵌入和提议区域特征之间的余弦相似度来产生分类结果。
-
设计了三个新的模块,即SSC,MFF和SAM损失,以提供无偏的表示并增加类别间的分离。SSC和MFF在经典的Faster R-CNN损失和SAM损失的端到端优化过程中进行优化。

基于数据增强
SNIDA: Unlocking Few-Shot Object Detection with Non-linear Semantic Decoupling Augmentation
方法:论文提出了一种基于数据增强方法的小样本目标检测技术。具体来说,作者提出了一种语义引导的非线性实例级数据增强方法SNIDA,该方法通过解耦前景和背景来分别增加它们的多样性,并通过语义引导的非线性变换空间来增强训练数据的多样性。
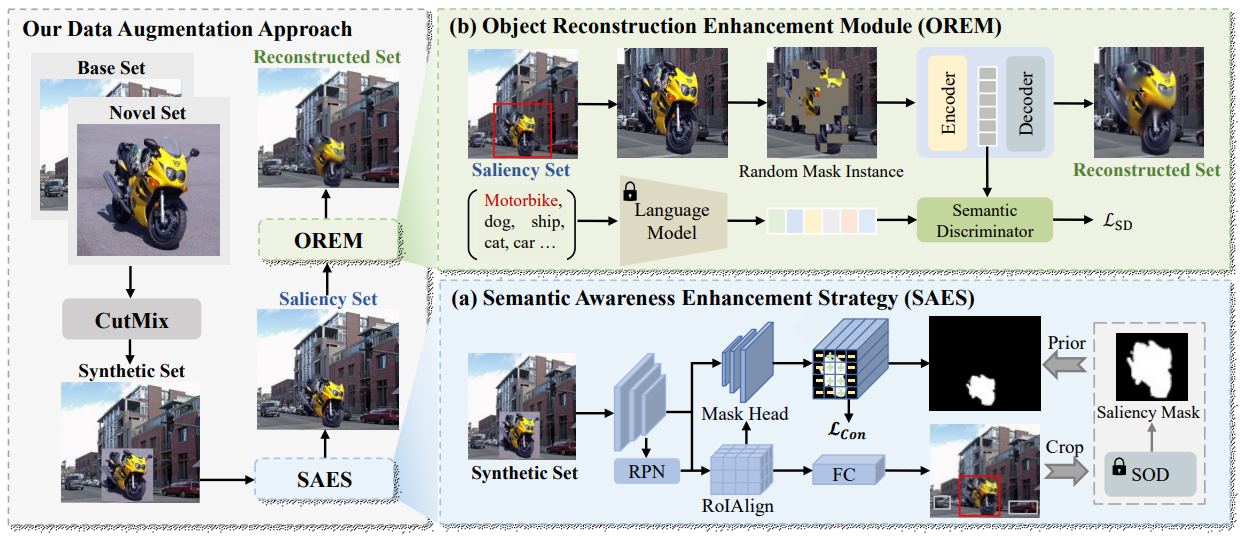
创新点:
-
本文提出了一种新的针对FSOD的数据增强方法,通过语义引导的非线性方式解耦了新类对象的前景和背景,并增加了它们的多样性。
-
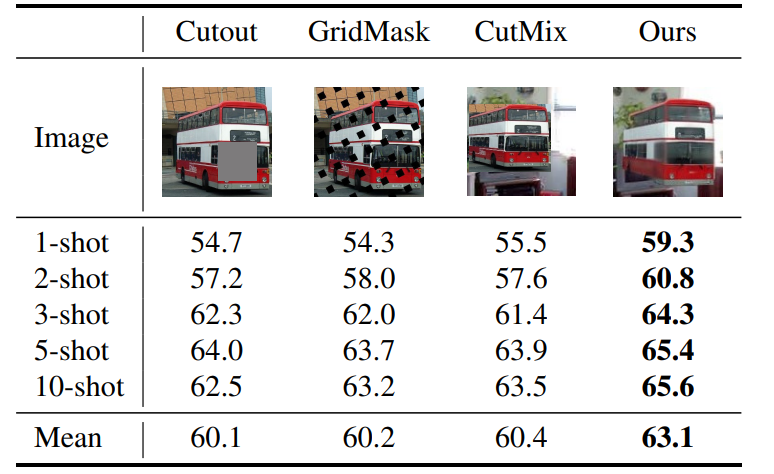
为了增加新类样本的数量,本文采用CutMix方法将基类图像与新类对象结合,将整个对象补丁从新类图像中裁剪出来,并应用简单的随机数据增强,如缩放/翻转/颜色退化。然后将增强的对象补丁粘贴到基类图像上,通过重复这个过程,生成包含来自新类和基类的样本的合成集。
关注下方《学姐带你玩AI》🚀🚀🚀
回复“小样本检测”获取全部论文+开源代码
码字不易,欢迎大家点赞评论收藏










![[RTOS 学习记录] 预备知识:C语言结构体](https://img-blog.csdnimg.cn/img_convert/a28b18c8e2db3f591f4c2ba1c38b10cf.png#pic_center)
![C语言程序设计-[5] 输入输出语句](https://i-blog.csdnimg.cn/direct/63e252177057449c84fb6d4a589a4d01.png)




