最近又有一篇ModularRAG的论文,虽然没有太让人汗毛竖起的惊艳,但我想文中的几张配图冷不丁的也着实让部分密集恐惧症患者又一次炸毛了一下吧;)...ps,图画的还是十分规整和可读的,逻辑也很是清晰,为作者的用心点赞👍特别特的分享一下~
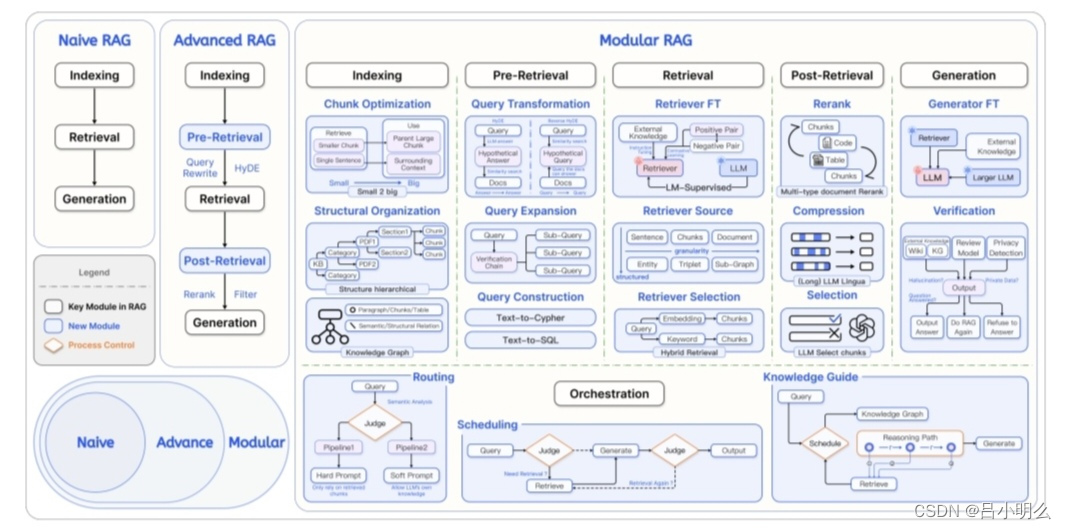
然而,对于RAG原生的数据&知识密集性所进一步衍生出的复杂推理的密集性总有一种感觉哪里不太对似的,直觉上也与llm的推理模式唱反调,即带来了另一种工程复杂度的上升...但一切看似有那么的合乎逻辑..我想问题也许出在rag的认知推理范式天然的复杂性以及在llm训练过程中数据的时空稀缺性,就像在做system2慢思考推理一样,甚至本质上即是System2。
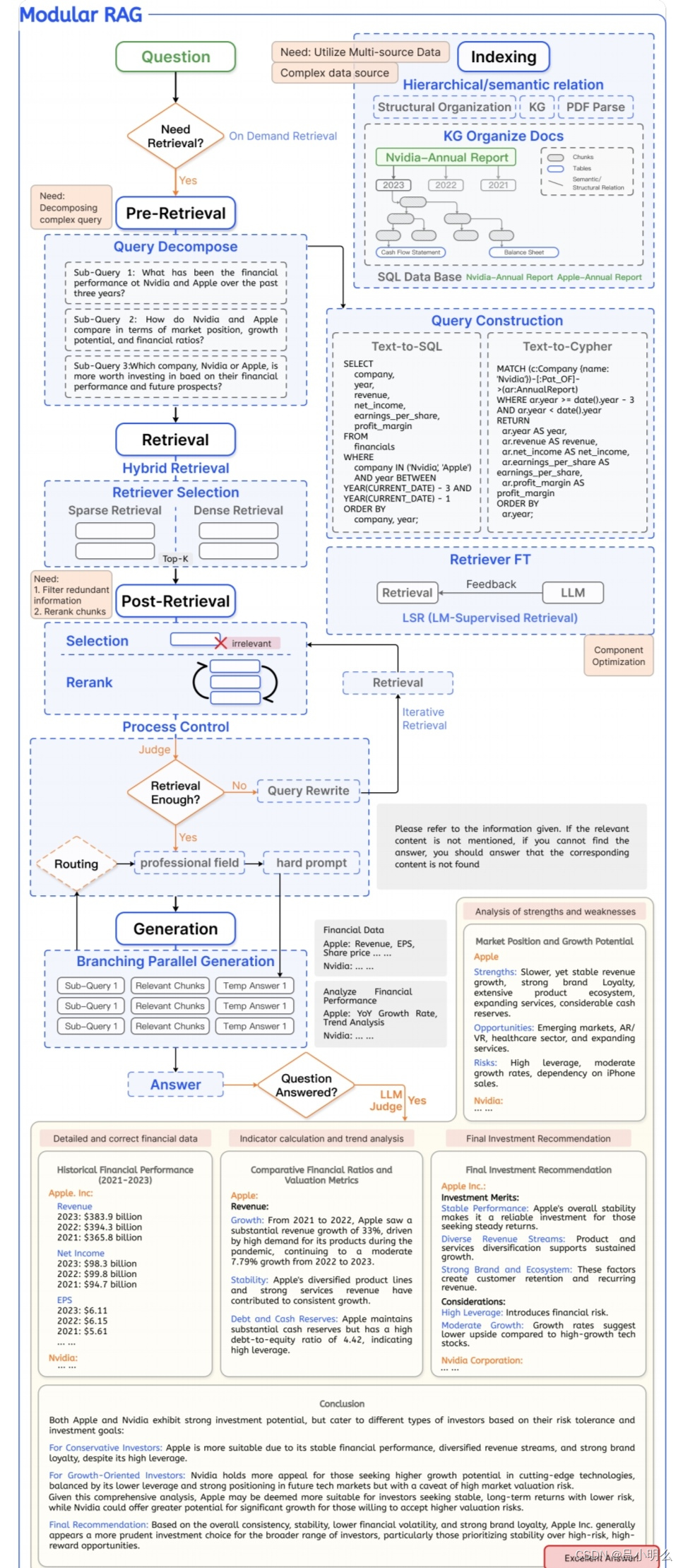
而这又让我不得不联想到一个月前开源的GraphRAG对我的感触,希望我们当前在做的ModularRAG也好,GraphRAG也好,还是agent,能够为今后的复杂推理打下一定的基础,不光是数据,也包含这种范式..
下文是之前分享的针对GraphRAG的一些观点,我想这里把“GraphRAG”替换成“ModularRAG”应该也说得通:
———————
“ 不管面对的是开放Gen任务还是领域Gen任务,对于LLM之下所采用的各种泛RAG增强技术来说,其本质貌似亦可以看作是LLM生成推理过程在某种指引下的step by step结构性符号化扩散提示或约束(对于领域任务更多体现为约束)。
如无论是GraphRAG中分步骤的图谱化实体要素提取或实体社区摘要生成的索引过程,还是大多数泛RAG中检索增强机制的中间索引构建过程,均可以看作某种具象化结构性提示,甚至可以看成为某种复杂推理模式进行的预符号化提示建模。
而GraphRAG所呈现出的在知识结构粒度和层级符号化索引与增强方面方面也许要比传统的RAG在增强LLM应用于复杂推理层面会更精细或准确,同时也能如论文中所说亦能进行局部或全局的整体内容理解和生成。然而,严重的成本开销也是不可避免的,我想也许这也是GraphRAG选择开源的目的之一吧:)