💛前情提要💛
本文是传知代码平台中的相关前沿知识与技术的分享~
接下来我们即将进入一个全新的空间,对技术有一个全新的视角~
本文所涉及所有资源均在传知代码平台可获取
以下的内容一定会让你对AI 赋能时代有一个颠覆性的认识哦!!!
以下内容干货满满,跟上步伐吧~
📌导航小助手📌
- 💡本章重点
- 🍞一. 热门研究领域:情感计算的横向发展
- 🍞二. 研究背景
- 🍞三.模型结构和代码
- 🍞四.数据集介绍
- 🍞五.性能展示
- 🍞六.模型总结
- 🫓总结
💡本章重点
- MSA+抑郁症模型总结(三)
🍞一. 热门研究领域:情感计算的横向发展
随着社交网络的不断发展,近年来出现了多模态数据的热潮。越来越多的用户采用媒体形式的组合(例如文本加图像、文本加歌曲、文本加视频等)。来表达他们的态度和情绪。多模态情感分析(MSA)是从多模态信息中提取情感元素进行情感预测的一个热门研究课题。传统的文本情感分析依赖于词、短语以及它们之间的语义关系,不足以识别复杂的情感信息。随着面部表情和语调的加入,多模态信息(视觉、听觉和转录文本)提供了更生动的描述,并传达了更准确和丰富的情感信息。
此外,随着近些年来生活压力的增加,抑郁症已成为现代工作环境中最常见的现象。早期发现抑郁症对避免健康恶化和防止自杀倾向很重要。无创监测应激水平在筛查阶段是有效的。许多基于视觉提示、音频馈送和文本消息的方法已用于抑郁倾向监测。

概述
这篇文章,我开始介绍第三篇情感计算经典论文模型,他是ACMMM 2020的一篇多模态情感计算的论文 “MISA: Modality-Invariant and -Specific Representations for Multimodal Sentiment Analysis”,其中提出的模型是MISA;
论文地址
MISA: Modality-Invariant and -Specific Representations for Multimodal Sentiment Analysis
🍞二. 研究背景
多模态情感分析和抑郁症检测是一个活跃的研究领域,它利用多模态信号对用户生成的视频进行情感理解和抑郁症程度判断。解决这一问题的主要方法是发展先进的模态融合技术。
然而,信号的异质性造成了分布模式的差距,构成了重大挑战。在本文中,我们的目标是学习有效的模态表示,以帮助融合的过程。
主要贡献
-
提出MISA,一个简单而灵活的多模态学习框架,强调多模态表示学习作为多模态融合的前体。
-
MISA学习modality-invariant和modality-specific表示,以提供多模态数据的全面和分解视图,从而帮助融合预测情感状态;
-
MSA任务的实验证明了MISA的强大功能,其中学习的表示帮助简单的融合策略超越复杂的最先进的模型。
🍞三.模型结构和代码
1. 总体框架
如下图所示,MISA的功能可以分为两个主要阶段:模态表征学习和模态融合。

2. 模态表征学习

模态不变和特定的表征。现在将每个话语向量 um 投射到两个不同的表示。第一个是 modality-invariant组件,它学习一个具有分布相似性约束的公共子空间共享表示。该约束有助于最小化异质性间隙–这是多模融合的理想特性。第二个是特定于模态的组件,它捕获了该模态的独特特征。
通过这篇论文,我们论证了模态不变和模态特定表示的存在为有效融合提供了一个整体的视角。学习这些表示法是该工作的首要目标。
以下为部分代码展示:
if not self.config.use_cmd_sim:
# discriminator
reversed_shared_code_t = ReverseLayerF.apply(self.utt_shared_t, self.config.reverse_grad_weight)
reversed_shared_code_v = ReverseLayerF.apply(self.utt_shared_v, self.config.reverse_grad_weight)
reversed_shared_code_a = ReverseLayerF.apply(self.utt_shared_a, self.config.reverse_grad_weight)
self.domain_label_t = self.discriminator(reversed_shared_code_t)
self.domain_label_v = self.discriminator(reversed_shared_code_v)
self.domain_label_a = self.discriminator(reversed_shared_code_a)
else:
self.domain_label_t = None
self.domain_label_v = None
self.domain_label_a = None
self.shared_or_private_p_t = self.sp_discriminator(self.utt_private_t)
self.shared_or_private_p_v = self.sp_discriminator(self.utt_private_v)
self.shared_or_private_p_a = self.sp_discriminator(self.utt_private_a)
self.shared_or_private_s = self.sp_discriminator( (self.utt_shared_t + self.utt_shared_v + self.utt_shared_a)/3.0 )
# For reconstruction
self.reconstruct()
3. 模态融合
在将模态投影到它们各自的表示中之后,我们将它们融合到一个联合向量中,用于下游预测。我们设计了一个简单的融合机制,首先执行自注意-基于Transformer,然后是所有六个变换的模态向量的级联。
融合进程。首先,我们堆叠六个模态表示矩阵。然后,我们在这些表示上执行多头自注意,以使每个向量都知道其他跨模态(和跨子空间)表示。这样做允许每个表征从同伴表征中诱导潜在的信息,这些信息对总体情感取向是协同的。这种跨模态匹配在最近的跨模态学习方法中已经非常突出。
# Projecting to same sized space
self.utt_t_orig = utterance_t = self.project_t(utterance_t)
self.utt_v_orig = utterance_v = self.project_v(utterance_v)
self.utt_a_orig = utterance_a = self.project_a(utterance_a)
self.utt_private_t = self.private_t(utterance_t)
self.utt_private_v = self.private_v(utterance_v)
self.utt_private_a = self.private_a(utterance_a)
self.utt_shared_t = self.shared(utterance_t)
self.utt_shared_v = self.shared(utterance_v)
self.utt_shared_a = self.shared(utterance_a)
🍞四.数据集介绍
-
CMU-MOSI: CMU-MOSI数据集是MSA研究中流行的基准数据集。该数据集是YouTube独白的集合,演讲者在其中表达他们对电影等主题的看法。MOSI共有93个视频,跨越89个远距离扬声器,包含2198个主观话语视频片段。这些话语被手动注释为[-3,3]之间的连续意见评分,其中-3/+3表示强烈的消极/积极情绪。
-
CMU-MOSEI: CMU-MOSEI数据集是对MOSI的改进,具有更多的话语数量,样本,扬声器和主题的更大多样性。该数据集包含23453个带注释的视频片段(话语),来自5000个视频,1000个不同的扬声器和250个不同的主题
-
AVEC2019: AVEC2019 DDS数据集是从患者临床访谈的视听记录中获得的。访谈由虚拟代理进行,以排除人为干扰。与上述两个数据集不同的是,AVEC2019中的每种模态都提供了几种不同的特征。例如,声学模态包括MFCC、eGeMaps以及由VGG和DenseNet提取的深度特征。在之前的研究中,发现MFCC和AU姿势分别是声学和视觉模态中两个最具鉴别力的特征。因此,为了简单和高效的目的,我们只使用MFCC和AU姿势特征来检测抑郁症。数据集用区间[0,24]内的PHQ-8评分进行注释,PHQ-8评分越大,抑郁倾向越严重。该基准数据集中有163个训练样本、56个验证样本和56个测试样本。
-
SIMS/SIMSV2: CH-SIMS数据集[35]是一个中文多模态情感分析数据集,为每种模态提供了详细的标注。该数据集包括2281个精选视频片段,这些片段来自各种电影、电视剧和综艺节目,每个样本都被赋予了情感分数,范围从-1(极度负面)到1(极度正面)
-
UR_FUNNY: 对于MHD,我们考虑最近提出的UR_FUNNY数据集。与情绪类似,幽默的产生和感知也是通过多通道进行的。因此,这个数据集提供了多模态的话语,作为从TED演讲中采样的笑点。它还为每个目标话语提供相关的上下文,并确保说话者和主题的多样性。每个目标话语被标记为幽默/非幽默实例的二元标签。
🍞五.性能展示
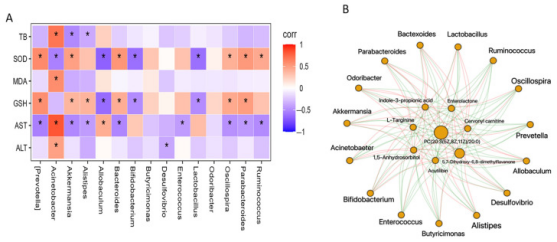
-
在情感计算任务中,可以看到Self_MM模型性能超越其他模型,证明了其有效性:


-
抑郁症检测任务中,Self_MM在我们的数据集AVEC2019中依旧亮眼:

-
SIMS数据集

🍞六.模型总结
1. 适用场景
-
社交媒体情感分析: MISA模型适用于分析社交媒体平台上用户的多模态数据,包括文本、图像和音频,从而深入理解用户的情感倾向、态度和情绪变化。例如,可以用于监测社交媒体上的舆情、分析用户对特定事件或产品的反应等。
-
情感驱动的内容推荐: 在内容推荐系统中,MISA模型可以根据用户的多模态数据,如观看历史、社交互动、文字评论等,推荐符合用户情感和兴趣的个性化内容,提升用户体验和内容吸引力。
-
智能健康监测: MISA模型在智能健康监测领域具有潜力,可以通过分析用户的语音情绪、面部表情和文字记录来监测心理健康状态,包括抑郁倾向和情绪波动,为个体提供早期干预和支持。
-
教育和人机交互: 在教育领域,MISA模型可以用于情感教育和个性化学习支持。通过分析学生的情感表达和反馈,提供定制化的学习体验和情感指导,增强教育效果和学习动机。
2. 项目特点
-
多模态融合: MISA模型能够有效整合文本、图像和音频等多种数据源,充分利用不同模态之间的关联性和信息丰富度,提升情感分析的全面性和准确性。
-
情感感知和表达建模: 通过先进的深度学习技术,MISA模型能够深入学习和模拟情感感知与表达过程,实现对复杂情感信息的准确捕捉和高效表示。
-
自适应学习和个性化: MISA模型具备自适应学习能力,可以根据具体任务和用户需求调整情感建模策略,实现个性化的情感分析和反馈。
-
跨领域应用能力: 由于其多模态分析的通用性和灵活性,MISA模型不仅适用于社交媒体分析和智能健康监测,还能应用于广告推荐、产品评价和人机交互等多个领域。
综上所述,MISA模型在多模态情感分析和智能应用领域展现出广泛的适用性和高效的技术特点,为实际应用场景提供了强大的分析和决策支持能力
🫓总结
综上,我们基本了解了“一项全新的技术啦” 🍭 ~~
恭喜你的内功又双叒叕得到了提高!!!
感谢你们的阅读😆
后续还会继续更新💓,欢迎持续关注📌哟~
💫如果有错误❌,欢迎指正呀💫
✨如果觉得收获满满,可以点点赞👍支持一下哟~✨
【传知科技 – 了解更多新知识】