文章目录
- 前言
- HashSet底层原理
- 1.哈希表
- 2.哈希值
- 3.底层原理
- 4.回答三个问题
前言
关于Set和HashSet的API使用可参见 集合基础入门(Collection,ArrayList,HashSet,HashMap)
HashSet底层原理
1.哈希表
HashSet集合底层采取哈希表存储数据
哈希表是一种对于增删改查数据性能都较好的结构
哈希表组成
JDK8之前:数组+链表(可以看作元素为链表的数组)
JDK8开始:数组+链表+红黑树
2.哈希值
根据hashcode方法算出来的int类型的整数
该方法定义在Object类中,所有对象都可以调用,默认使用地址值进行计算。一般情况下,会重写hashcode方法,利用对象内部的属性值计算哈希值
对象的哈希值特点
- 如果没有重写hashCode方法,不同对象计算出的哈希值是不同的
- 如果已经重写hashcode方法,不同的对象只要属性值相同,计算出的哈希值就是一样的
- 在小部分情况下,不同的属性值或者不同的地址值计算出来的哈希值也有可能一样。(哈希碰撞)
e.g.
新建一个Student Bean类,没有重写hashcode方法
再创建Student对象
Student std1 = new Student("zs",22);
Student std2 = new Student("lisi",23);
Student std3 = new Student("zs",22);
System.out.println(std1.hashCode()); // 434091818
System.out.println(std2.hashCode()); // 398887205
System.out.println(std3.hashCode()); // 2114889273,此时std1和std3虽然属性值相同,但没有重写HashCode方法,所以哈希值不同
重写HashCode方法后
在Student Bean类方法中重写
@Override
public boolean equals(Object o) {
if (this == o) return true;
if (o == null || getClass() != o.getClass()) return false;
Student student = (Student) o;
return age == student.age && Objects.equals(name, student.name);
}
@Override
public int hashCode() {
return Objects.hash(name, age);
}
再创建对象
Student std1 = new Student("zs",22);
Student std2 = new Student("lisi",23);
Student std3 = new Student("zs",22);
System.out.println(std1.hashCode()); // 121790
System.out.println(std2.hashCode()); // 102983077
System.out.println(std3.hashCode()); // 121790,此时std1和std3属性相同,而且重写了HashCode方法,所以哈希值相同
String s1 = "重地";
String s2 = "通话";
String s3 ="hello";
System.out.println(s1.hashCode()); // 1179395
System.out.println(s2.hashCode()); // 1179395,哈希碰撞:不同的地址值可能也会哈希值相同
System.out.println(s3.hashCode()); // 99162322
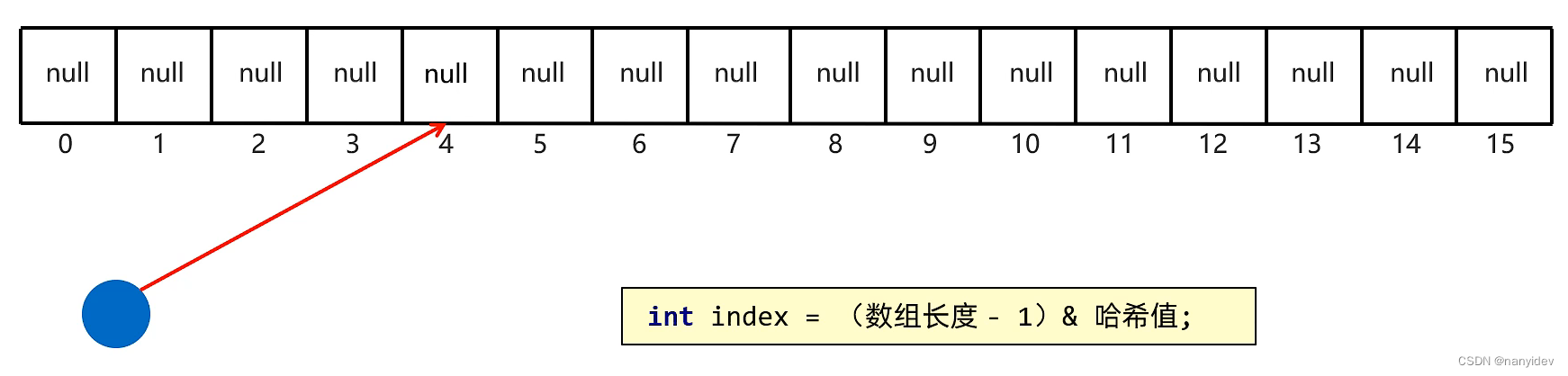
3.底层原理
(1)创建一个默认长度16,默认加载因子为0.75的数组,数组名table
(2)根据元素的哈希值跟数组的长度计算出应存入的位置
// 计算公式
int index = (数组长度-1) & 哈希值
(3)判断当前位置是否为null,如果是null直接存入
(4)如果位置不为null,表示有元素,则调用equals方法比较属性值
(5)一样:不存; 不一样:存入数组,形成链表
JDK8以前:新元素存入数组,老元素挂在新元素下面
JDK8以后:新元素直接挂在老元素下面
其中加载因子是用于扩容:当HashSet的元素到达16 *0.75=12时,就扩容到原先的两倍(32)
另外:
JDK8以后,当链表长度超过8,而且数组长度大于等于64时,自动转换为红黑树

如果集合中存储的是自定义对象,必须重写hashCode和equals方法(String,Integer等数据类型jdk已经重写好hashCode方法)
4.回答三个问题
Q1:HashSet为什么存和取的顺序不一样(无序性)?
在遍历时会按照数组的索引进行遍历,如果当前索引有链表,则继续遍历当前链表
Q2:HashSet为什么没有索引?
哈希表的底层既有数组又有链表,无法统一索引
Q3:HashSet是利用什么机制保证数据去重的?
利用hashcode和equals方法
参考链接:
https://www.bilibili.com/video/BV17F411T7Aop=197&vd_source=38cb30e60861b967d6cdfa51ce1c31fa