C++入门基础(上篇)
hello everybody!经历了C语言和初阶数据结构的头脑风暴,相信大家对于编程的学习更加开心,所以说接下来我们将迎来C++的学习与探索,话不多说让我们开始吧
namespace的价值
在C/C++中,变量、函数和后⾯要学到的类都是⼤量存在的,这些变量、函数和类的名称将都存在于全 局作⽤域中,可能会导致很多冲突。使⽤命名空间的⽬的是对标识符的名称进⾏本地化,以避免命名 冲突或名字污染,namespace关键字的出现就是针对这种问题的。
c语⾔项⽬类似下⾯程序这样的命名冲突是普遍存在的问题,C++引⼊namespace就是为了更好的解决 这样的问题
#include <stdio.h>
#include <stdlib.h>
int rand = 10;
int main()
{
// 编译报错:error C2365: “rand”: 重定义;以前的定义是“函数”
printf("%d\n", rand);
return 0;
}
namespace的定义
• 定义命名空间,需要使⽤到namespace关键字,后⾯跟命名空间的名字,然后接⼀对{}即可,{}中 即为命名空间的成员。命名空间中可以定义变量/函数/类型等。
• namespace本质是定义出⼀个域,这个域跟全局域各⾃独⽴,不同的域可以定义同名变量,所以下 ⾯的rand不在冲突了。
• C++中域有函数局部域,全局域,命名空间域,类域;域影响的是编译时语法查找⼀个变量/函数/ 类型出处(声明或定义)的逻辑,所有有了域隔离,名字冲突就解决了。局部域和全局域除了会影响 编译查找逻辑,还会影响变量的⽣命周期,命名空间域和类域不影响变量⽣命周期。
#define _CRT_SECURE_NO_WARNINGS 1
#include <stdio.h>
#include <stdlib.h>
// 1. 正常的命名空间定义
namespace Tzuyu
{
// 命名空间中可以定义变量/函数/类型
int rand = 10;
}
//2. 命名空间可以嵌套
namespace Red
{
namespace Velvet
{
int rand = 1;
int Add(int left, int right)
{
return left + right;
}
}
namespace Irene
{
int rand = 2;
int Add(int left, int right)
{
return (left + right) * 10;
}
}
}
int main()
{
// 这⾥默认是访问的是全局的rand函数指针
//printf("%d\n", rand);
// 这⾥指定Tzuyu命名空间中的rand
printf("%d\n",Tzuyu::rand);
printf("%d\n", Red::Velvet::Add(1,2));
printf("%d\n", Red::Irene::Add(1,2));
return 0;
}
// 多⽂件中可以定义同名namespace,他们会默认合并到⼀起,就像同⼀个namespace⼀样
// Stack.h
#pragma once
#include<stdio.h>
#include<stdlib.h>
#include<stdbool.h>
#include<assert.h>
namespace bit
{
typedef int STDataType;
typedef struct Stack
{
STDataType* a;
int top;
int capacity;
}ST;
void STInit(ST* ps, int n);
void STDestroy(ST* ps);
void STPush(ST* ps, STDataType x);
void STPop(ST* ps);
STDataType STTop(ST* ps);
int STSize(ST* ps);
bool STEmpty(ST* ps);
}
// Stack.cpp
#include"Stack.h"
namespace bit
{
void STInit(ST* ps, int n)
{
assert(ps);
ps->a = (STDataType*)malloc(n * sizeof(STDataType));
ps->top = 0;
ps->capacity = n;
}
// 栈顶
void STPush(ST* ps, STDataType x)
{
assert(ps);
// 满了, 扩容
if (ps->top == ps->capacity)
{
printf("扩容\n");
int newcapacity = ps->capacity == 0 ? 4 : ps->capacity* 2;
STDataType* tmp = (STDataType*)realloc(ps->a,
newcapacity * sizeof(STDataType));
if (tmp == NULL)
{
perror("realloc fail");
return;
}
ps->a = tmp;
ps->capacity = newcapacity;
}
ps->a[ps->top] = x;
ps->top++;
}
//...
}
// Queue.h
#pragma once
#include<stdlib.h>
#include<stdbool.h>
#include<assert.h>
namespace bit
{
typedef int QDataType;
typedef struct QueueNode
{
int val;
struct QueueNode* next;
}QNode;
typedef struct Queue
{
QNode* phead;
QNode* ptail;
int size;
}Queue;
void QueueInit(Queue* pq);
void QueueDestroy(Queue* pq);
// ⼊队列
void QueuePush(Queue* pq, QDataType x);
// 出队列
void QueuePop(Queue* pq);
QDataType QueueFront(Queue* pq);
QDataType QueueBack(Queue* pq);
bool QueueEmpty(Queue* pq);
int QueueSize(Queue* pq);
}
// Queue.cpp
#include"Queue.h"
namespace bit
{
void QueueInit(Queue* pq)
{
assert(pq);
pq->phead = NULL;
pq->ptail = NULL;
pq->size = 0;
}
// ...
}
// test.cpp
#include"Queue.h"
#include"Stack.h"
// 全局定义了⼀份单独的Stack
typedef struct Stack
{
int a[10];
int top;
}ST;
void STInit(ST* ps){}
void STPush(ST* ps, int x){}
int main()
{
// 调⽤ST st1;
STInit(&st1);
STPush(&st1, 1);
STPush(&st1, 2);
printf("%d\n", sizeof(st1));
// 调⽤bit namespace的
bit::ST st2;
printf("%d\n", sizeof(st2));
bit::STInit(&st2);
bit::STPush(&st2, 1);
bit::STPush(&st2, 2);
return 0;
}
• namespace只能定义在全局,当然他还可以嵌套定义。
• 项⽬⼯程中多⽂件中定义的同名namespace会认为是⼀个namespace,不会冲突。
• C++标准库都放在⼀个叫std(standard)的命名空间中。
命名空间使⽤
编译查找⼀个变量的声明/定义时,默认只会在局部或者全局查找,不会到命名空间⾥⾯去查找。所以 下⾯程序会编译报错。所以我们要使⽤命名空间中定义的变量/函数,有三种⽅式:
• 指定命名空间访问,项⽬中推荐这种⽅式。
• 展开命名空间中全部成员,项⽬不推荐,冲突⻛险很⼤,⽇常⼩练习程序为了⽅便推荐使⽤。
namespace hhh
{
int a = 0;
int b = 1;
}
int main()
{
// 编译报错:error C2065: “a”: 未声明的标识符
printf("%d\n", a);
return 0;
}
// 指定命名空间访问
int main()
{
printf("%d\n", hhh::a);
return 0;
}
// using将命名空间中某个成员展开
using hhh::b;
int main()
{
printf("%d\n", hhh::a);
printf("%d\n", b);
return 0;
}
// 展开命名空间中全部成员
using namespce hhh;
int main()
{
printf("%d\n", a);
printf("%d\n", b);
return 0;
}
C++输⼊&输出
• 是 Input Output Stream 的缩写,是标准的输⼊、输出流库,定义了标准的输⼊、输 出对象。
• std::cin 是 istream 类的对象,它主要⾯向窄字符(narrow characters (of type char))的标准输 ⼊流。
• std::cout 是 ostream 类的对象,它主要⾯向窄字符的标准输出流。
• std::endl 是⼀个函数,流插⼊输出时,相当于插⼊⼀个换⾏字符加刷新缓冲区。
• <<是流插⼊运算符,>>是流提取运算符。(C语⾔还⽤这两个运算符做位运算左移/右移)
• 使⽤C++输⼊输出更⽅便,不需要像printf/scanf输⼊输出时那样,需要⼿动指定格式,C++的输⼊ 输出可以⾃动识别变量类型(本质是通过函数重载实现的),其实最重要的是 C++的流能更好的⽀持⾃定义类型对象的输⼊输出。
• cout/cin/endl等都属于C++标准库,C++标准库都放在⼀个叫std(standard)的命名空间中,所以要 通过命名空间的使⽤⽅式去⽤他们。
• ⼀般⽇常练习中我们可以using namespace std,实际项⽬开发中不建议using namespace std。
• 这⾥我们没有包含<stdio.h>,也可以使⽤printf和scanf,在包含间接包含了。vs系列 编译器是这样的,其他编译器可能会报错。
#define _CRT_SECURE_NO_WARNINGS 1
#include <iostream>
using namespace std;
int main()
{
int a = 0;
double b = 0.1;
char c = 'x';
cout << a << " " << b << " " << c << endl;
std::cout << a << " " << b << " " << c << std::endl;
scanf("%d%lf", &a, &b);
printf("%d %lf\n", a, b);
// 可以⾃动识别变量的类型
cin >> a;
cin >> b >> c;
cout << a << endl;
cout << b << " " << c << endl;
return 0;
}
#include<iostream>
using namespace std;
int main()
{
// 在io需求⽐较⾼的地⽅,如部分⼤量输⼊的竞赛题中,加上以下3⾏代码
// 可以提⾼C++IO效率
ios_base::sync_with_stdio(false);
cin.tie(nullptr);
cout.tie(nullptr);
return 0;
}
缺省参数
• 缺省参数是声明或定义函数时为函数的参数指定⼀个缺省值。在调⽤该函数时,如果没有指定实参 则采⽤该形参的缺省值,否则使⽤指定的实参,缺省参数分为全缺省和半缺省参数。(有些地⽅把 缺省参数也叫默认参数)
• 全缺省就是全部形参给缺省值,半缺省就是部分形参给缺省值。C++规定半缺省参数必须从右往左 依次连续缺省,不能间隔跳跃给缺省值。
• 带缺省参数的函数调⽤,C++规定必须从左到右依次给实参,不能跳跃给实参。
• 函数声明和定义分离时,缺省参数不能在函数声明和定义中同时出现,规定必须函数声明给缺省 值。
#include <iostream>
#include <assert.h>
using namespace std;
void Func(int a = 0)
{
cout << a << endl;
}
int main()
{
Func(); // 没有传参时,使⽤参数的默认值
Func(10); // 传参时,使⽤指定的实参
return 0;
}
#include <iostream>
using namespace std;
// 全缺省
void Func1(int a = 10, int b = 20, int c = 30)
{
cout << "a = " << a << endl;
cout << "b = " << b << endl;
cout << "c = " << c << endl << endl;
}
// 半缺省
void Func2(int a, int b = 10, int c = 20)
{
cout << "a = " << a << endl;
cout << "b = " << b << endl;
cout << "c = " << c << endl << endl;
}
int main()
{
Func1();
Func1(1);
Func1(1,2);
Func1(1,2,3);
Func2(100);
Func2(100, 200);
Func2(100, 200, 300);
return 0;
}
优化栈的实现:
// Stack.h
#include <iostream>
#include <assert.h>
using namespace std;
typedef int STDataType;
typedef struct Stack
{
STDataType* a;
int top;
int capacity;
}ST;
void STInit(ST* ps, int n = 4);
// Stack.cpp
#include"Stack.h"
// 缺省参数不能声明和定义同时给
void STInit(ST* ps, int n)
{
assert(ps && n > 0);
ps->a = (STDataType*)malloc(n * sizeof(STDataType));
ps->top = 0;
ps->capacity = n;
}
// test.cpp
#include"Stack.h"
int main()
{
ST s1;
STInit(&s1);
// 确定知道要插⼊1000个数据,初始化时⼀把开好,避免扩容
ST s2;
STInit(&s2, 1000);
return 0;
}
函数重载
C++⽀持在同⼀作⽤域中出现同名函数,但是要求这些同名函数的形参不同,可以是参数个数不同或者 类型不同。这样C++函数调⽤就表现出了多态⾏为,使⽤更灵活。C语⾔是不⽀持同⼀作⽤域中出现同 名函数的。
#include<iostream>
using namespace std;
// 1、参数类型不同
int Add(int left, int right)
{
cout << "int Add(int left, int right)" << endl;
return left + right;
}
double Add(double left, double right)
{
cout << "double Add(double left, double right)" << endl;
return left + right;
}
// 2、参数个数不同
void f()
{
cout << "f()" << endl;
}
void f(int a)
{
cout << "f(int a)" << endl;
}
// 3、参数类型顺序不同
void f(int a, char b)
{
cout << "f(int a,char b)" << endl;
}
void f(char b, int a)
{
cout << "f(char b, int a)" << endl;
}
// 返回值不同不能作为重载条件,因为调⽤时也⽆法区分
//void fxx()
//{}
//
//int fxx()
//{
// return 0;
//}
// 下⾯两个函数构成重载
// f()但是调⽤时,会报错,存在歧义,编译器不知道调⽤谁
void f1()
{
cout << "f()" << endl;
}
void f1(int a = 10)
{
cout << "f(int a)" << endl;
}
int main()
{
Add(10, 20);
Add(10.1, 20.2);
f();
f(10);
f(10, 'a');
f('a', 10);
return 0;
}
引⽤
引⽤的概念和定义
引⽤不是新定义⼀个变量,⽽是给已存在变量取了⼀个别名,编译器不会为引⽤变量开辟内存空间, 它和它引⽤的变量共⽤同⼀块内存空间。⽐如:水浒传中李逵,宋江叫"铁⽜",江湖上⼈称"⿊旋 ⻛";林冲,外号豹⼦头;
类型& 引⽤别名 = 引⽤对象;
C++中为了避免引⼊太多的运算符,会复⽤C语⾔的⼀些符号,⽐如前⾯的<< 和 >>,这⾥引⽤也和取 地址使⽤了同⼀个符号&,⼤家注意使⽤⽅法⻆度区分就可以。(吐槽⼀下,这个问题其实挺坑的,个 ⼈觉得⽤更多符号反⽽更好,不容易混淆)

#include<iostream>
using namespace std;
int main()
{
int a = 0;
// 引⽤:b和c是a的别名
int& b = a;
int& c = a;
// 也可以给别名b取别名,d相当于还是a的别名
int& d = b;
++d;
// 这⾥取地址我们看到是⼀样的
cout << &a << endl;
cout << &b << endl;
cout << &c << endl;
cout << &d << endl;
return 0;
}
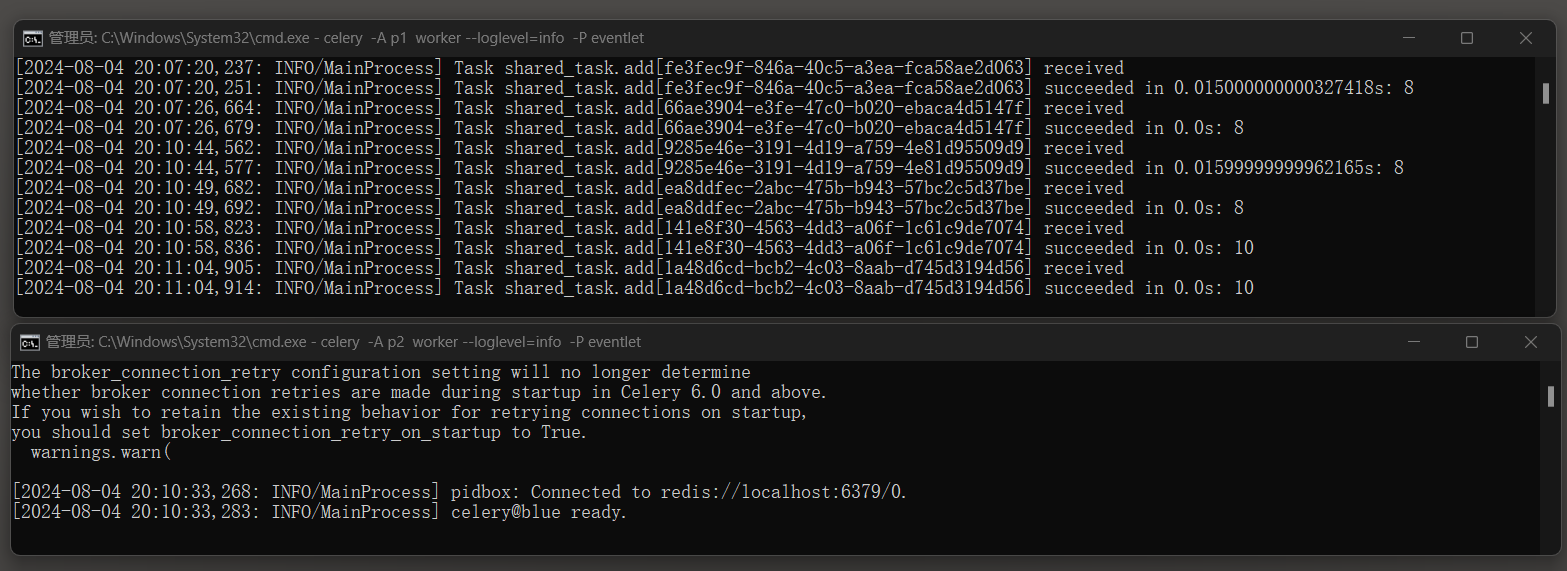
运行结果如下:

引⽤的特性
• 引⽤在定义时必须初始化
• ⼀个变量可以有多个引⽤
• 引⽤⼀旦引⽤⼀个实体,再不能引⽤其他实体
引⽤的使⽤
• 引⽤在实践中主要是于引⽤传参和引⽤做返回值中减少拷⻉提⾼效率和改变引⽤对象时同时改变被 引⽤对象。
• 引⽤传参跟指针传参功能是类似的,引⽤传参相对更⽅便⼀些。
• 引⽤和指针在实践中相辅相成,功能有重叠性,但是各有特点,互相不可替代。C++的引⽤跟其他 语⾔的引⽤(如Java)是有很⼤的区别的,除了⽤法,最⼤的点,C++引⽤定义后不能改变指向, Java的引⽤可以改变指向。
• ⼀些主要⽤C代码实现版本数据结构教材中,使⽤C++引⽤替代指针传参,⽬的是简化程序,避开 复杂的指针,但是很多同学没学过引⽤,导致⼀头雾⽔。
void Swap(int& rx, int& ry)
{
int tmp = rx;
rx = ry;
ry = tmp;
}
int main()
{
int x = 0, y = 1;
cout << x <<" " << y << endl;
Swap(x, y);
cout << x << " " << y << endl;
return 0;
}
#include<iostream>
using namespace std;
typedef int STDataType;
typedef struct Stack
{
STDataType* a;
int top;
int capacity;
}ST;
void STInit(ST& rs, int n = 4)
{
rs.a = (STDataType*)malloc(n * sizeof(STDataType));
rs.top = 0;
rs.capacity = n;
}
// 栈顶
void STPush(ST& rs, STDataType x)
{
assert(ps);
// 满了, 扩容
if (rs.top == rs.capacity)
{
printf("扩容\n");
int newcapacity = rs.capacity == 0 ? 4 : rs.capacity * 2;
STDataType* tmp = (STDataType*)realloc(rs.a, newcapacity *
sizeof(STDataType));
if (tmp == NULL)
{
perror("realloc fail");
return;
}
rs.a = tmp;
rs.capacity = newcapacity;
}
rs.a[rs.top] = x;
rs.top++;
}
// int STTop(ST& rs)
int& STTop(ST& rs)
{
assert(rs.top > 0);
return rs.a[rs.top];
}
int main()
{
// 调⽤全局的
ST st1;
STInit(st1);
STPush(st1, 1);
STPush(st1, 2);
cout << STTop(st1) << endl;
STTop(st1) += 10;
cout << STTop(st1) << endl;
return 0;
}
#include<iostream>
using namespace std;
typedef struct SeqList
{
int a[10];
int size;
}SLT;
// ⼀些主要⽤C代码实现版本数据结构教材中,使⽤C++引⽤替代指针传参,⽬的是简化程序,避开复
杂的指针,但是很多同学没学过引⽤,导致⼀头雾⽔。
void SeqPushBack(SLT& sl, int x)
{}
typedef struct ListNode
{
int val;
struct ListNode* next;
}LTNode, *PNode;
// 指针变量也可以取别名,这⾥LTNode*& phead就是给指针变量取别名
// 这样就不需要⽤⼆级指针了,相对⽽⾔简化了程序
//void ListPushBack(LTNode** phead, int x)
//void ListPushBack(LTNode*& phead, int x)
void ListPushBack(PNode& phead, int x)
{
PNode newnode = (PNode)malloc(sizeof(LTNode));
newnode->val = x;
newnode->next = NULL;
if (phead == NULL)
{
phead = newnode;
}
else
{
//...
}
}
int main()
{
PNode plist = NULL;
ListPushBack(plist, 1);
return 0;
}

可以大大优化代码,之前写一些数据结构的时候可能会面临着传址调用,形参改变实参的问题,这个用引用可以很好的提高效率
一些小小补充:
看下列代码:
typedef struct ListNode
{
int val;
struct ListNode* next;
}LTNode, *PNode;
//typedef struct ListNode* PNode; 只是为了节省将*PNode写到了上面
void ListPushBack(PNode& phead, int x)
{
PNode newnode = (PNode)malloc(sizeof(LTNode));
newnode->val = x;
newnode->next = NULL;
if (phead == NULL)
{
phead = newnode;
}
else
{
//...
}
}
int main()
{
PNode plist = NULL;
ListPushBack(plist, 1);
return 0;
}
= newnode;
}
else
{
//…
}
}
int main()
{
PNode plist = NULL;
ListPushBack(plist, 1);
return 0;
}
[外链图片转存中...(img-IuRw8uIX-1722785653889)]
可以大大优化代码,之前写一些数据结构的时候可能会面临着传址调用,形参改变实参的问题,这个用引用可以很好的提高效率
一些小小补充:
看下列代码:
```C++
typedef struct ListNode
{
int val;
struct ListNode* next;
}LTNode, *PNode;
//typedef struct ListNode* PNode; 只是为了节省将*PNode写到了上面
void ListPushBack(PNode& phead, int x)
{
PNode newnode = (PNode)malloc(sizeof(LTNode));
newnode->val = x;
newnode->next = NULL;
if (phead == NULL)
{
phead = newnode;
}
else
{
//...
}
}
int main()
{
PNode plist = NULL;
ListPushBack(plist, 1);
return 0;
}
我们在之前学习数据结构譬如链表的创建和销毁要用到二级指针,我们学习了引用的知识以后可以不用二级指针了