文章目录
- 写在前面
- Task 0 - Read the Source Code
- 算子(executor)如何获取数据,BusTub如何描述算子?
- ButTub如何存储表的数据,描述表的结构?
- Task 1 - Access Method Executors
- SeqScan
- Insert
- Update
- Delete
- IndexScan
- Optimizing SeqScan to IndexScan
- Task 2 - Aggregation & Join Executors
- Aggregation
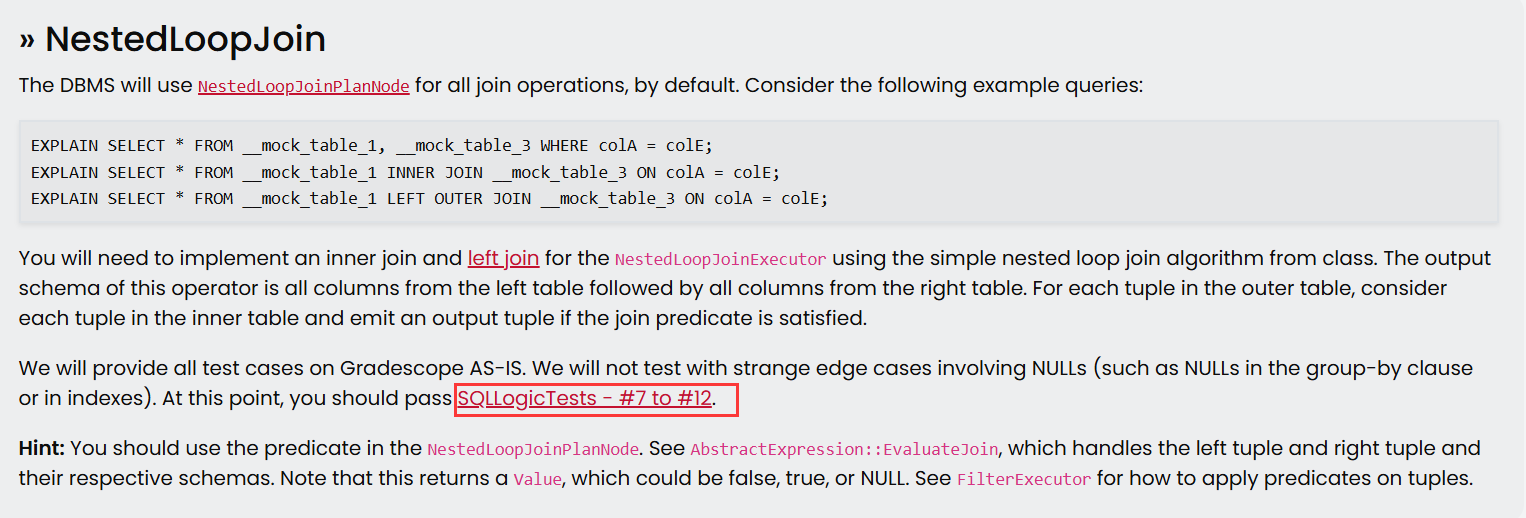
- NestedLoopJoin
- Task 3 - HashJoin Executor and Optimization
- HashJoin
- Optimizing NestedLoopJoin to HashJoin
- Task 4: Sort + Limit Executors + Window Functions + Top-N Optimization
- Sort
- Limit
- Top-N Optimization Rule
- Window Functions
- 写在最后
写在前面
在Project 3中,我们将实现数据库的查询执行部分。它包括了:
- 不同算子的具体执行逻辑
- 编写优化规则,转换查询计划,以提高其执行效率
相比于Projcet 2,本次项目侧重于源码阅读,我们需要看懂BusTub的查询执行逻辑,弄清楚每个组件之间的关系,否则我们将无从下手。
此外,ButTub提供了Live Shell,我们可以在网页上运行SQL,或是用来debug。由于不同学期实现的BusTub在细节上略有不同,我们需要修改url中的学期字段,以访问相应的Live Shell:
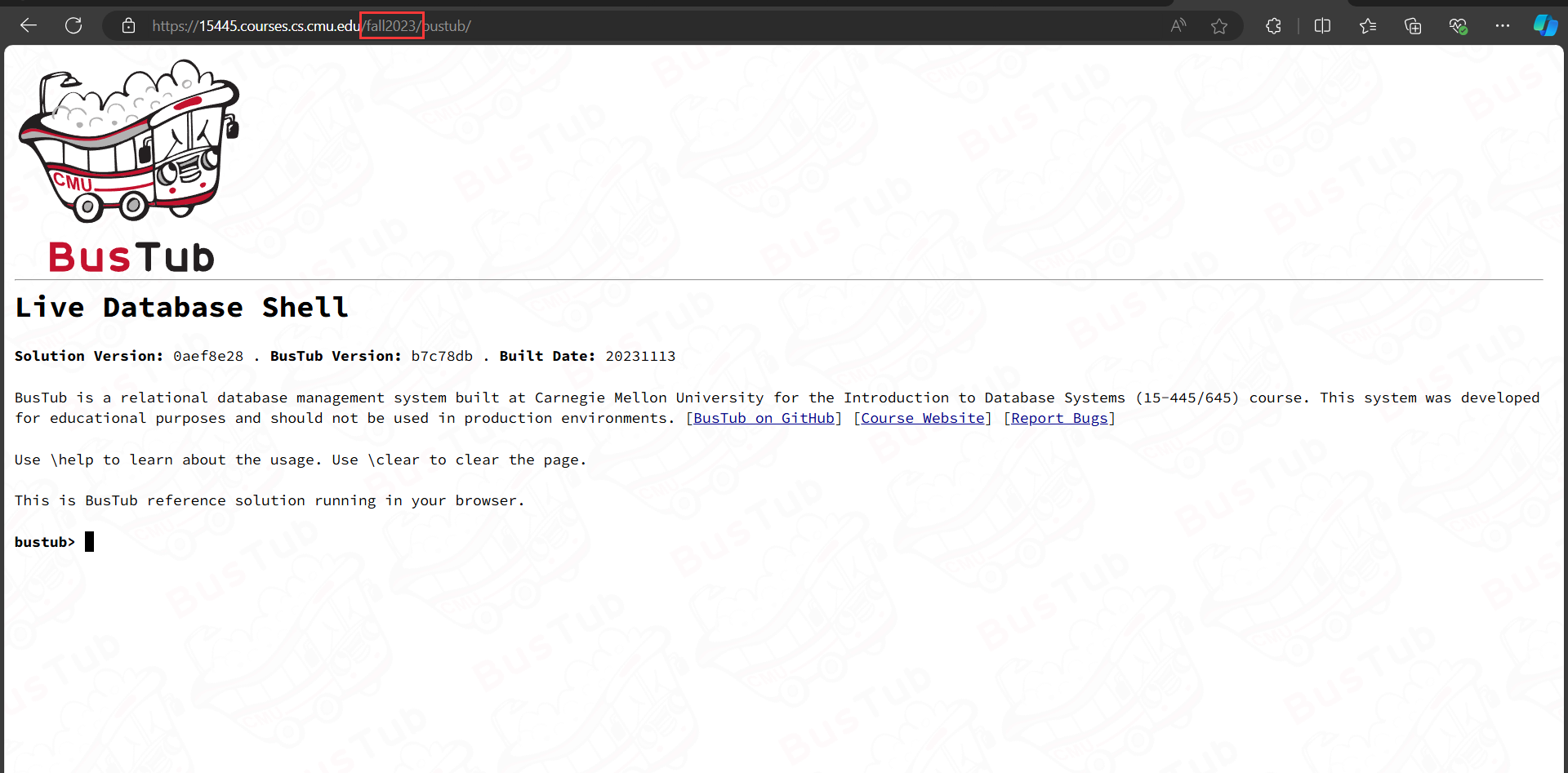
最后Project 3没有隐藏用例,官方将所有测试用例提供给了我们,它们在test/sql/目录下。每当你完成一个Task,文档都会提示你相应的测试用例,你需要通过测试再完成后续Task:
而测试用例的运行方法在文档的最后Testing部分:

make -j$(nproc) sqllogictest
./bin/bustub-sqllogictest ../test/sql/p3.00-primer.slt --verbose
Task 0 - Read the Source Code
首先,我们需要了解一条SQL将如何被数据库执行?官方给出的执行流程图如下:
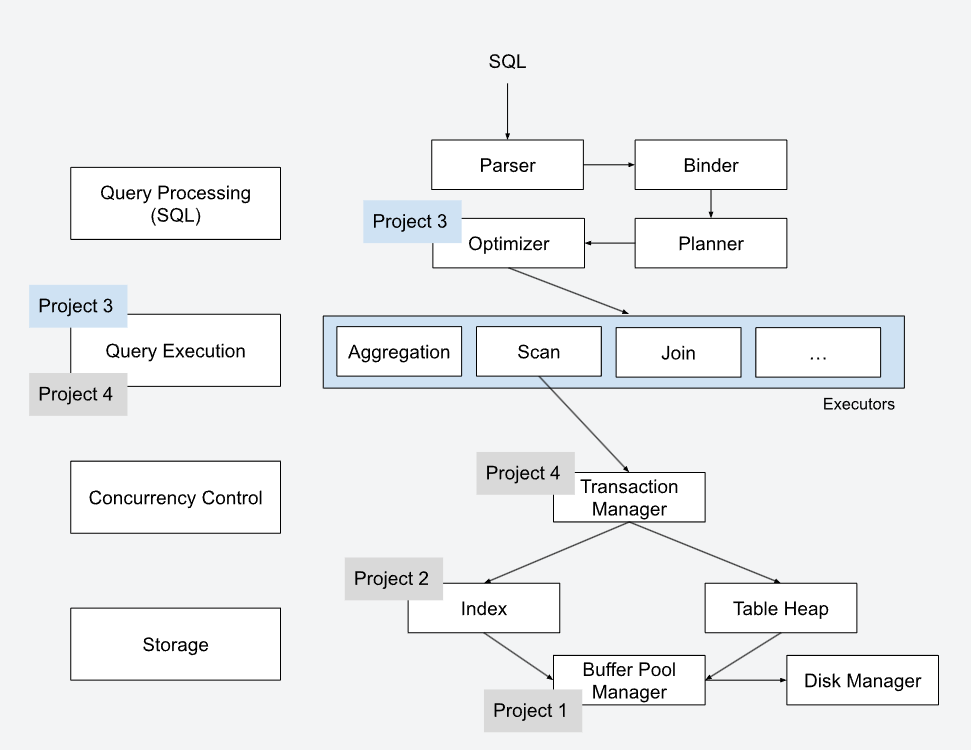
SQL语句的执行将经历五个模块:Parser, Binder, Planner, Optimizer以及Executors
lecture提到了每个模块的具体行为:
- Parser:将SQL文本转换成抽象语法树(如果你学过了编译原理,就能很好的理解)
- Binder:将抽象语法树中的符号(表名、列名、索引名等)转换程DBMS认识的符号(ID、标识符)。转换的同时会进行检查,判断用户的SQL是否合法
- Planner(Tree Rewrite):将抽象语法树转换成树状执行计划,作为优化器优化的起点
- Optimizer(数据库中最难实现的模块):对执行计划进行优化,生成更高效的执行计划
- Executors:依照执行计划,对数据进行查询与处理
BusTub已经实现了前三个模块以及后两个模块的框架,我们只需要阅读Optimizer和Executors模块即可。你需要弄懂的类包括但不限于:
- TableInfo, TableHeap, TablePage, Tuple, Schema, Column, Value, RID, TupleMeta
- AbstractExecutor, AbstractPlanNode, AbstractExpression, ExecutorContext, Catalog
你需要带着问题阅读源码,想一想SQL的运行过程涉及哪些逻辑概念?我给你提供了以下两个问题,当然,我也会做出相应的解答:
- 算子(executor)如何获取数据,BusTub如何描述算子?
- BusTub如何存储表的数据,描述表的结构?
在阅读源码之前,你可能会感到无从下手,官方为我们提供三个实现好的Executor,分别是:
- Projectioin
- Filter
- Values
所有的算子实现在src/execution/目录下,而相应定义在src/include/executor/execution目录下(按着Ctrl再左击类名,会跳转到类的定义,一般编辑器都有这个功能),不妨读一读以上三个算子的实现吧。
以下是我对问题的解答,你应该一边对照着代码,一边往下阅读。不然会一头雾水的: )
算子(executor)如何获取数据,BusTub如何描述算子?
首先你需要知道SQL的处理模型,它一般是树形结构,BusTub使用了火山模型:
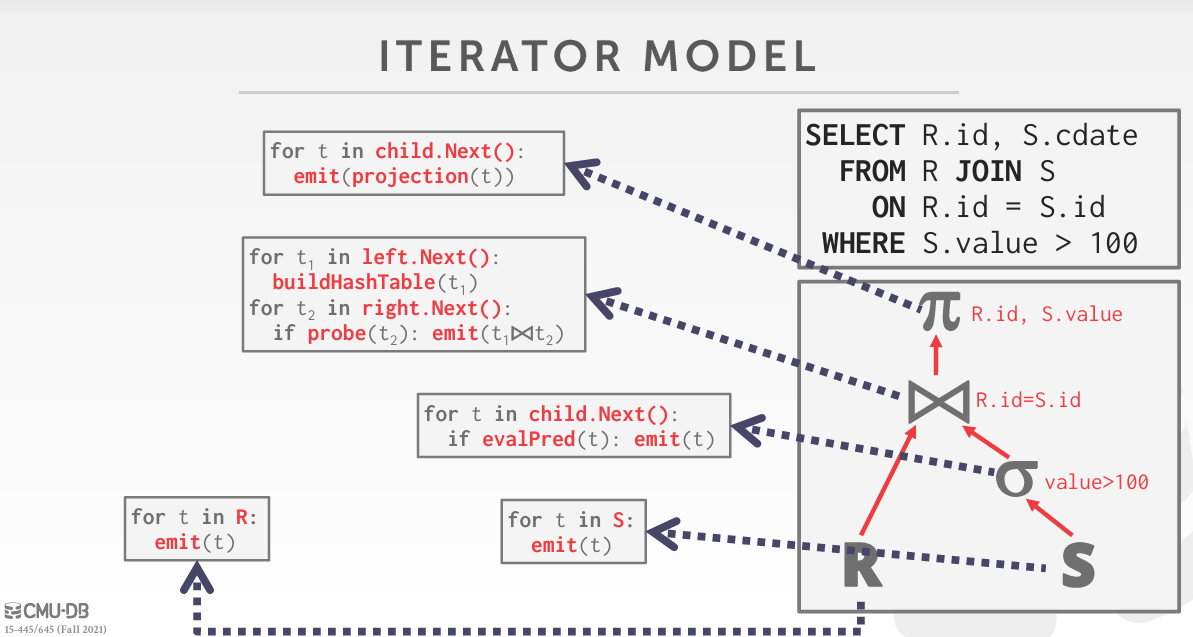
Optimizer将优化逻辑执行计划。上图右下角就是一个逻辑执行计划,它描述了SQL语句要做的事(抽象的),如scan, join, project.
Optimizer还会生成逻辑执行计划对应的物理执行计划。上图中,每个逻辑算子对应一段具体代码,它描述了SQL语句具体要做的事(具体的),比如决定逻辑算子scan应该seq scan还是index scan,join应该hash join还是nested loop loin.
总之,每个逻辑算子都对应着合适的物理算子,如无特别说明,后文所说的算子(executor)指的都是物理算子。
我们发现:逻辑执行计划是一颗树,物理执行计划也是一颗树。在BusTub中,逻辑执行计划树的每个节点为PlanNode,而物理执行计划树的每个节点为Executor。当然Executor存储了相应PlanNode以获取执行过程中需要的信息。
回到火山模型:
- 每个Executor必须具有
Next()方法供上层调用,执行Next()时Executor将返回一条数据或者NULL以表示是否运行完成 - 上层节点不断调用子节点的Next()拽出自身需要的数据
了解了火山模型后,看看Executor的具体代码实现。每个Executor都含有一个成员:PlanNode,以SeqScanExecutor为例,其含有SeqScanPlanNode成员。正如我刚才所说,PlanNode存储了Executor运行时所需的信息,如:table_name_, Expression.
Expression先放在一边,聪明的你应该发现了,Executor还有一个继承自抽象类的成员:ExecutorContext。ExecutorContext保存比PlanNode更多的信息,在Project 3我们只需要关注其Catalog成员。Catalog也有很多成员,这些成员类型我们都认识,无需继续纠结它们。看看Catalog的成员函数,我们发现其管理了所有表和索引。以SeqScanExecutor为例,我们需要用SeqScanPlanNode中的table_name_向Catalog索要表数据,以获取需要扫描的表。
综上,Executor需要访问PlanNode与Catalog,以获取运行时的必要数据。
再捡起Expression,为什么PlanNode要存储它呢?以ProjectionExecutor为例,其Next()方法调用了Expression的Evalute(),这其实是在执行表达式。我们发现BusTub中有以下类型的Expression:

比如这个SQL语句:select col1 from table1,ProjectionExecutor的Expression具体是一个列值表达式,Evaluate()将获取talbe1中的一行数据的col1列。
再以SeqScanExecutor为例,运行SQL语句:select col1 from table1 where col2 = 3时。SeqScanExecutor的Expression就是一个比较表达式,Evaluate()将比较table1中的一行数据的col2列是否等于3。
总之Evaluate()将执行Expression,并返回执行结果。有些Executor可能需要保存执行结果,如Projection的列值。有些Executor可能需要根据执行结果,做下一步判断,如SeqScan的where子句。
综上,我们理清了第一个问题:executor如何获取数据,BusTub如何描述executor?
做个小结:BusTub以AbstractExecutor为抽象类,对于不同executor实现了不同了Executor类。Executor需要通过Catalog和PlanNode获取执行时需要的数据,而Executor通常具有Expression,用于进一步处理获取的数据。
ButTub如何存储表的数据,描述表的结构?
聪明的你在看Catalog时应该发现了,Executor可以通过Catalog的GetTalbe()获取表数据。GetTable()将返回TableInfo,这是一张表的元信息。描述了这张表的结构Schema,名字,表id,以及最重要的TableHeap。
如果你看过Disk Manager那节lecture,你就会知道DBMS的磁盘管理模块的不同管理方式,它们分别是:
- Heap File Organization
- Sequential File Organization
- Hashing File Organization
BusTub使用Heap File的方式管理磁盘,而Heap File又有两种具体实现:
- Linked List
- Page Directory
BusTub采用了类似Linked List的方式管理磁盘。你可以看到TableHeap记录了first_page_id_与last_page_id_,它们分别是无序文件页集合的头和尾。再看TableHeap的InsertTuple()方法,如果你完成了Project 2,那么你将看到两行熟悉的代码:
auto page_guard = bpm_->FetchPageWrite(last_page_id_);
auto page = page_guard.AsMut<TablePage>();
是的,表数据的存储经过了Project 2实现的Buffer Pool。通过Buffer Pool获取page资源后,将其视为TablePage以存储表数据。再看TablePage的成员,其next_page_id_指向了下一张page,你可以将其理解为链表的next指针。所以我刚才说:BusTub采用了类似Linked List的方式管理磁盘。
如果看过lecture,那你一定知道:TablePage存储了tuple以及tuple的元信息(header),如下图所示:
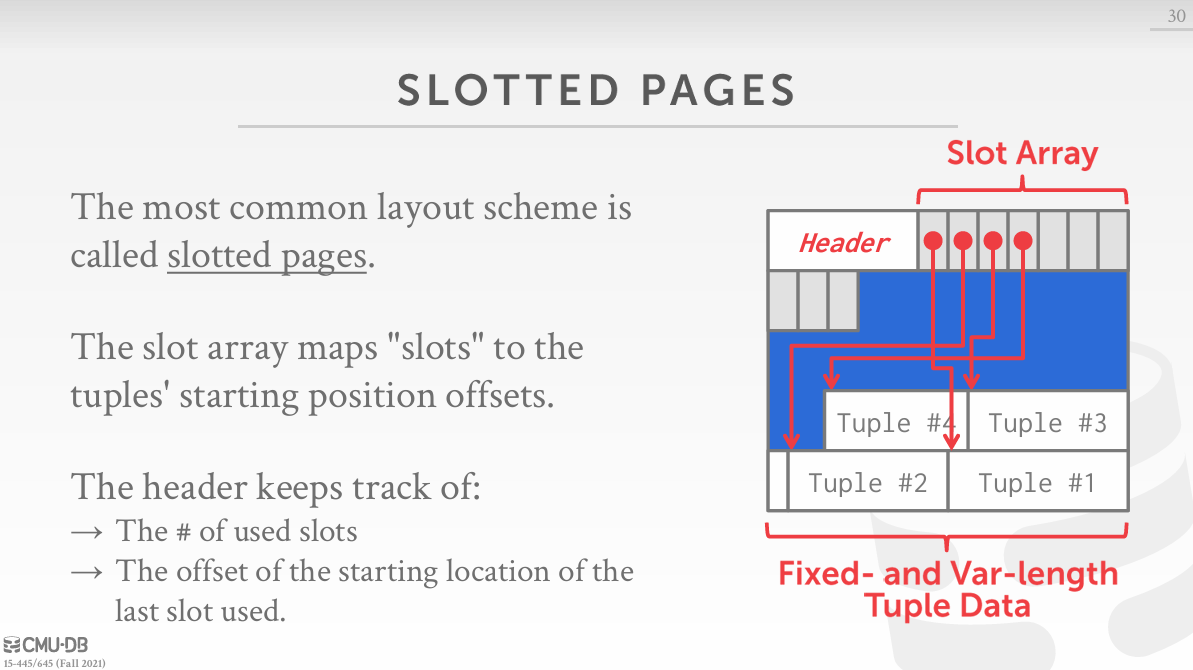
官方甚至还贴心地注释了header和tuple的结构布局:
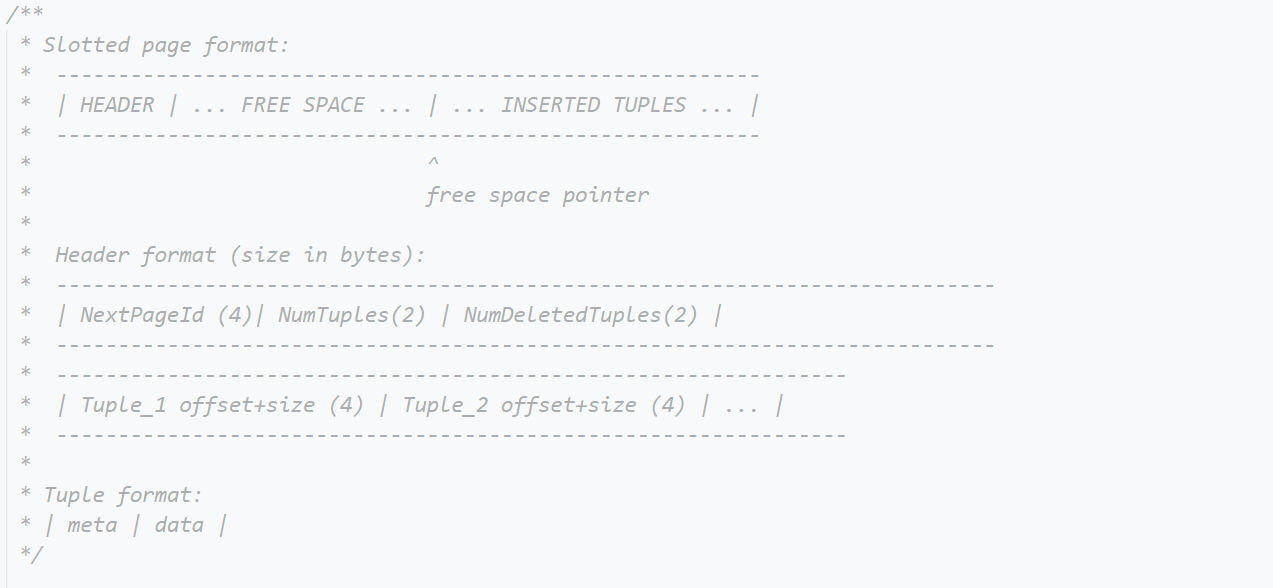
在完成Project 3后,可以看看TablePage的InsertTuple()和GetTuple(),里面涉及到很多的指针加减运算,是一些很细节的内存操作。
至此,我们理清了这样一条访问逻辑:Catalog->TableInfo->TableHeap->TablePage. 在实际的开发过程中,我们只会访问到TableHeap,经常使用的方法有:InsertTuple(), GetTuple(), GetTupleMeta(), UpdateTupleMeta()。各位读者对这些方法有个印象就行。
聪明的你应该注意到了,BusTub用Tuple描述我们常说的一行记录。其含有RID成员,这是一个64位整数,前32位为page id,后32位为slot id. 用于唯一地标识Tuple. 顺便一提,BusTub中的索引为非聚簇索引,因为其存储的是RID, 不是完整的tuple.
而Tuple由多个列值组成,可以看到Tuple有个GetValue()方法,能够获取指定列上的值。其返回值为Value,也就是说BusTub用Value描述Tuple存储的列值。Value的成员TypeId描述了列值的类型,通过Value的成员函数可以知道,Value的底层是Type,这是一个抽象类,BusTub对不同数据类型进行了封装:
我们回到TableInfo中,那里还有一个因为TableHeap而被我们跳过的类:Schema. 可以看到Schema存储了std::vector<Column>, 而Column则是用来描述列属性的类:列名,长度,类型…
所以可以认为Schema描述了表的结构,换句话说:表中所有列的属性,它包括了所有列的总长度,是否存在变长属性… 你不应该纠结于length如何计算,具有可变Column的Tuple如何在TablePage中存储… 这些问题,你应该快速地扫一眼,理清结构之间的关系即可
总之,我们理清了第二个问题:BusTub如何存储表的数据,描述表的结构?
做个小结:我们需要通过Catalog->TableInfo->TableHeap访问表的数据,实际的数据将存储在TablePage中。而BusTub用Schema描述表的结构,Schema由多个Column的组成。每张表存储了多个Tuple,Tuple的列值则被描述为Value
Task 1 - Access Method Executors
我们可以为具体算子添加一些额外成员,以支持算子的执行。每个具体算子都包含了Init()和Next()方法。我们需要在Init()中调用子执行器的Init()方法(如果存在子执行器的话),或是初始化一些成员。在Next()够Tuple并返回true,直到没有Tuple,此时返回false。
需要注意的是:Next()的两个参数Tuple和RID都是输出型参数,有些算子需要从子执行器获取Tuple,比如Sort, HashJoin. 有些算子需要从TableHeap中获取Tuple,它们通常是执行树的叶子,比如SeqScan, IndexScan.
SeqScan
关于Executor返回的Tuple和RID: 我们需要返回TableHeap中的Tuple与其RID.
该算子需要从TableHeap中获取Tuple,如何访问表的数据?我们刚刚已经梳理了。访问到一张表后,如何遍历表?不妨看看TableHeap是否为我们提供了遍历的方法吧。
Init: 用于SeqScan没有子执行器,将该函数放空即可。
Next: TableHeap为我们提供了MakeIterator(), IsEnd()与operator++(), 使用迭代器遍历。TableHeap即可。不过你不能输出(1)被删除的tuple, (2)不符合filter的tuple。
值得注意的是:(1)BusTub删除了TableIterator的拷贝方法,我们只能为SeqScanExecutor添加TableIterator成员,在构造函数的初始化列表对其进行初始化。(2)由于谓词下推导致了filter提前,这个filter是一个比较表达式,Expression的返回类型为Value,你需要通过Value的GetAs()方法将Value转换成bool值。
Insert
关于Executor返回的Tuple和RID: InsertExecutor作为pipeline breaker. 官方要求返回的Tuple只有一个Value,且类型为int. 我们要insert所有tuple, 统计成功insert的数量,构造Tuple后再返回。而返回的RID是无效的,在调用子执行器的Next()前,我们需要清楚其返回的Tuple和RID是否有效。
以上过程将涉及的问题有(1)如何用int类型构造Value?Value(TypeId type, int32_t i);(2)如何构造Tuple?Tuple(std::vector<Value> values, const Schema *schema).
Init: 初始化子执行器。
Next: 调用TableHeap的InsertTuple(),以及通过Catalog的GetTableIndexes()获取所有索引,并通过IndexInfo的InsertEntry()维护索引。
维护索引时,你会用到Tuple的KeyFromTuple()方法,其中的参数可以通过TableInfo, IndexInfo, Index得到。但是你需要考虑清楚:KeyFromTuple()的第一个参数是谁的Schema?InsertExecutor有Schema,要insert的表也有Schema. 而最后构造Tuple时,应该使用哪个Schema?
最后一个要考虑的问题:InsertExecutor作为pipeline break, 将所有tuple insert后,应该返回true还是false?
Update
关于Executor返回的Tuple和RID: 和InsertExecutor相同,UpdateExecutor也是pipeline breaker。我们需要用update成功的tuple数量构造Tuple,而RID则是无效输出。
阅读代码的过程中,你应该注意到了:TableHeap的GetTuple()方法返回的是TupleMeta和Tuple。TupleMeta中有一个is_delete_标志位,用于表示该Tuple是否被删除。我们将需要update的tuple先删除,再插入更新后的数据,同时维护索引。为什么不直接调用TableHeap的UpdateTupleInPlace()?官方说:这是一个将在PJ 4使用的函数,我们不应该在PJ 3中使用。
Init: 初始化子执行器。
Next:
- 通过子执行器的Next()获取需要修改的RID
- 调用TableHeap的GetTuple()获取old tuple, 调用TableInfo的UpdateTupleMeta()修改其TupleMeta的is_delete_标志位,通过Catalog的
GetTableIndexes()获取所有索引,并通过IndexInfo的EraseEntry()维护索引。 - 调用TableHeap的
InsertTuple(),通过Catalog的GetTableIndexes()获取所有索引,并通过IndexInfo的InsertEntry()维护索引。
你可能会遇到的问题:如何获取更新后的tuple?调用PlanNode的Expression的Evaluate()方法即可。而PlanNode有多个Expression, 你可以做个测试,看看一个有几个Expression, 这个值是否和tuple的列数量相同?再看看Evaluae()的返回值类型,聪明的你应该知道要怎么做了: )。
你需要注意:有些函数需要传入Schema参数,你应该考虑清楚要传入哪个Schema参数?是子执行器的Schema, 还是old tuple的Schema?
Delete
关于Executor返回的Tuple和RID: DeleteExecutor依然是一个pipeline breaker. 我们需要用update成功的tuple数量构造Tuple,而RID则是无效输出。
Init: 初始化子执行器。
Nest: 逻辑和update的Next()前半部分完全一样,懒得写了: )
你需要注意:有些函数需要传入Schema参数,你应该考虑清楚要传入哪个Schema参数?是子执行器的Schema, 还是old tuple的Schema?
IndexScan
关于Executor返回的Tuple和RID: 该算子需要通过索引进行点查询,返回查询到的Tuple与其RID.
Init: 通过PlanNode的index oid与Catalog的GetIndex获取IndexInfo, 对其中的Index视为具体的索引类型,以进行查找,并保存查找结果。官方提供了类型转换的参考代码:

Next: 根据Init的查找结果(符合条件的RID),与TableHeap的GetTuple获取具体tuple. 但是要注意不能返回被删除的tuple, 所以要瞅一眼tuple的meta.
你可能会遇到的问题:调用索引的ScanKey()方法时,需要以key值为Value, 构造一个Tuple, 作为ScanKey()的参数。要怎么获取key值呢?通过PlanNode执行Expression的Evaluate即可。
Optimizing SeqScan to IndexScan
优化规则:PlanNode具有Expression,其类型为比较表达式。且Expression的一个子表达式类型为列值表达式,另一个子表达式的类型为常量表达式,且列值表达式所表示的列上具有索引。此时SeqScan可以被转换成IndexScan。似乎Expression自描述的功能,其TypeId成员用来表示返回值类型,而不是表达式类型,那么我们要怎么判断表达式类型呢?
获取的表达式类型为AbstractExpressRef, 是一个智能指针,其get()方法可以获取原生指针。我们可以利用C++的dynamic_cast将指针的类型转换成子类的指针类型,这是dynamic_cast的一个很重要的使用:多态类型之间的安全转换。
比如一个父类类型的指针,它能指向子类A,也能指向子类B。假设该指针指向了子类A,那么我们可以将其dynamic_cast成子类A类型的指针,但是不能将其dynamic_cast成子类B类型的指针,这将导致转换失败返回nullptr值。
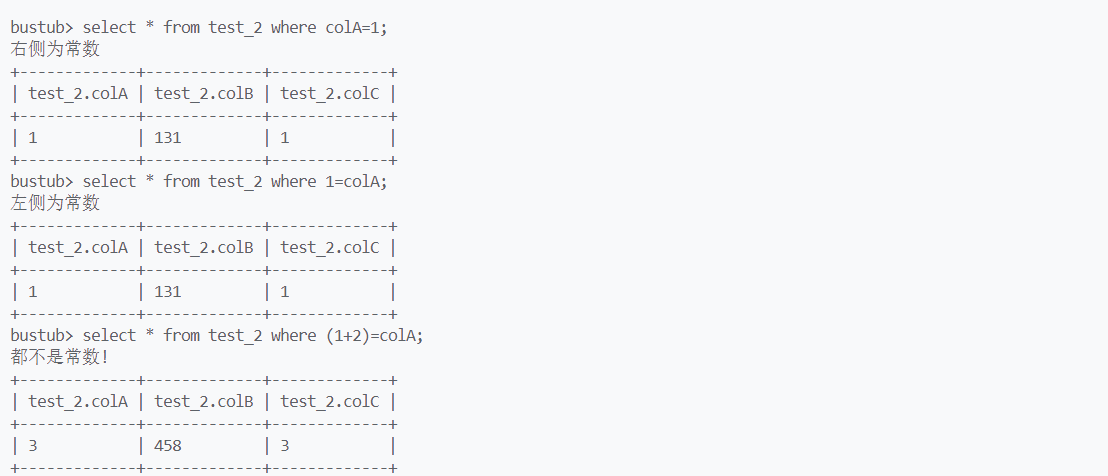
根据这个性质,我们可以通过dynamic_cast的返回值,判断转换是否成功,同时也能判断该指针指向的数据类型。测试代码如下:

结果如下:
那么我们要怎么判断列值表达式的列,是否具有索引呢? ColumnValueExpression具有col_idx_成员,其表示ColumnValueExpression的列为table的第col_idx列(从0开始)。而Index的GetKeyAttrs()方法可以获取一个数组,该数组表示索引列的下标。我们只需要判断GetKeyAttrs()数组中是否有元素和col_idx相等即可。
注意:在优化前,我们需要调用OptimizeMergeFilterScan()进行谓词下推。
最后,你的实现需要通过测试用例p3.01 ~ p3.06。
Task 2 - Aggregation & Join Executors
Aggregation
我们常用hash解决aggregation问题,一般情况下,aggregation都有group by子句。这意味着我们需要将tuple分组,如何通过hash分组tuple呢?假设现在需要根据colA列分组,显而易见的是:colA列值相同的tuple将会分在一组。相同的列值经过hash得到的hash值一定也是相同的,所以我们只需要以group-by的列为key,对group-by的列值做hash,就能将tuple分组。
说完group-by后,再来看aggregation。我们为什么要具有相同group-by列值的tuple分到一起呢?为了统计某些信息,如:成绩的最高分(max),身高的平均值(avg)。对具有相同group-by列值的tuple的某些列做aggregate, aggregate的类型有:

因此,我们不需要将具有相同group-by列值的tuple分到一组,只需要将tuple的某些列分到一组,接着做aggregate即可。在代码实现中,BusTub则是边对tuple分组,边对列值做aggregate. 因此,官方要求我们完成hash table的CombineAggregateValues函数
回到代码实现中,我们需要用SimpleAggregationHashTable完成hash分组任务,PlanNode提供了GetGroupBys与GetAggregates方法,它们会返回一些表达式,用于获取group-by或是aggregate列值。而Executor提供了MakeAggregateKey和MakeAggregateValue方法,它们分别会调用GetGroupBys与GetAggregates方法,将group-by与aggregate的列值保存在AggregateKey与AggregateValue中,这两个结构都是对std::vector<Value>的封装。为什么不是对Value的封装呢?可能存在多个group-by与aggregate对象嘛,比如 SELECT max(colA), min(colB) FROM test_2 group by colA, colB,只有colA与colB都相同的tuple才会分到一组,并且对colA和colB两列做aggregate.
由于我们需要用AggregateKey作为std::unordered_map的key,那么AggregateKey必须支持一个hash函数,用于将复杂类型转换成一个hash值(整数),因此官方特化了hash模板:

同时,重载了AggregateKey的==,用于hash冲突时,进行key值的比较:
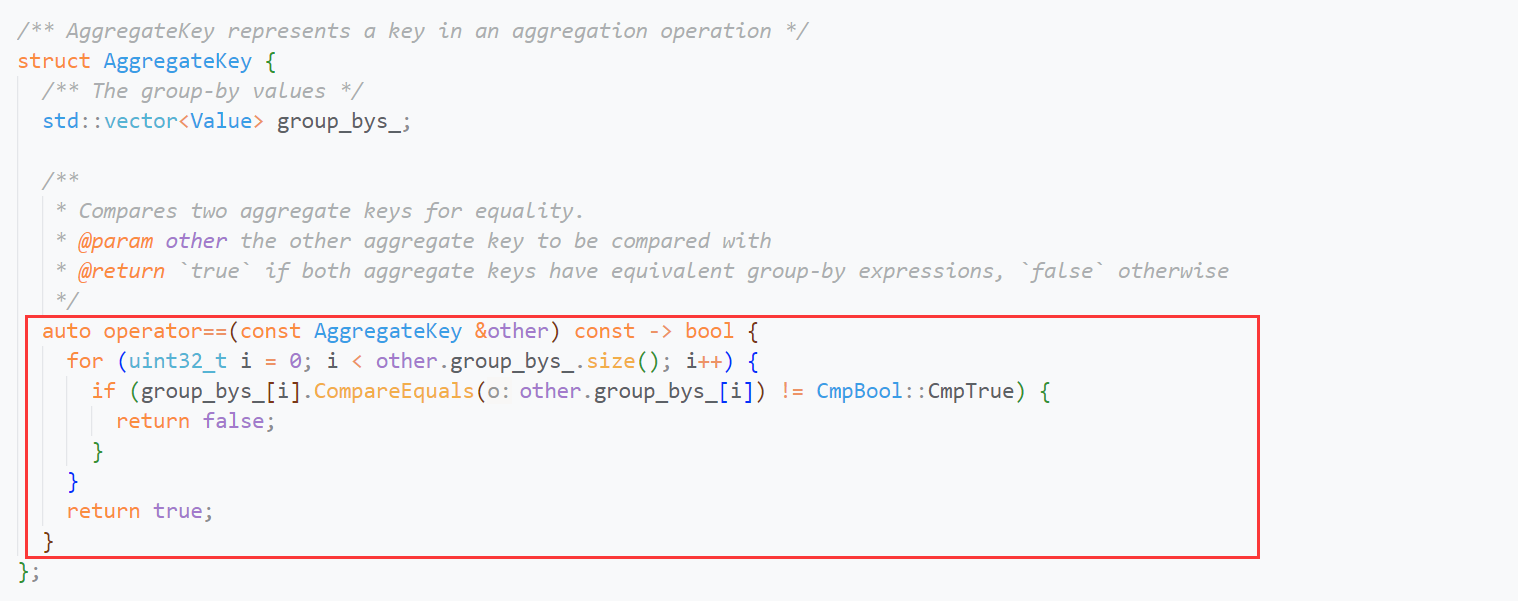
如果你完成了PJ 2,就能很快理解为什么要这么做。
关于Executor返回的Tuple和RID: AggregationExecutor作为pipeline breaker. 我们需要遍历SimpleAggregationHashTable以构造Tuple,而RID则是无效输出。
关于CombineAggregateValues: aggregate列的数量和AggregateValue的Value数量相同。你需要遍历AggregateValue的所有Value,根据aggregate的类型对result进行运算,可能是求和,也可能是取最小值… 但是你需要判断result或者input为null的情况:input为null时无需参数运算,result为null时,需要用input覆盖。
Init:
- 调用子执行器的Next获取Tuple
- 通过MakeAggregateKey和MakeAggregateValue获取tuple的k-v
- 调用SimpleAggregationHashTable的InsertCombine
Next: 遍历SimpleAggregationHashTable, 构造聚合结果即可。
你需要注意的是:Executor输出的Tuple的Schema. 根据文档,它应该是所有group-by列+所有aggregate列。所以构造Tuple时,你需要先保存key的所有Value再保存value的所有Value.
以及:如果SimpleAggregationHashTable为空,且group-by为空,需要输出一个默认值(GenerateInitialAggregateValue())。而如果SimpleAggregationHashTable为空,且group-by不为空,则直接返回false. 这是一个很奇怪的点。
NestedLoopJoin
外层循环遍历左表,内存循环遍历右表。所以我们需要不断调用right_executor_的Next(), 当然你需要先调用Init(), 在测试程序中,官方添加了Init()的强制检查,如果你没有调用Init(), 就算结果正确也无法通过测试。
因此,你需要回头看看SeqScan的实现,是否支持多次调用?由于Iterator不可复制,我只能在构造函数的初始化列表获取Iterator. 将第一遍SeqScan的结果缓存在result中,当然你也可以在NestedLoopJoin中缓存右表的SeqScan结果。
关于Executor返回的Tuple和RID: NestedLoopJoinExecutor作为pipeline breaker. 我们需要在Init()中完成表的连接并保存结果,在Next()中遍历连表结果以构造Tuple,而RID则是无效输出。
关于怎么判断两条tuple是否满足Join条件:执行PlanNode的Expression的EvaluateJoin()方法,其返回值为包装了bool的Value变量,通过GetAs()即可读取。最后根据返回值来判断是否能Join, 实际上这个EvaluteionJoin()只是提取出两个tuple的Join列(Value),并比较它们是否相等。
关于怎么将两条tuple连接成一条:看看Tuple的构造函数,第一个参数是std::vector<Value>的那个,拆Value再拼起来: )
官方只需要我们实现Inner Join和Left Join,关于Left Join: 你需要记录左tuple是否和右tuple Join过,如果没有Join过,你需要将左tuple与一条所有Value为null的tuple Join.
最后,你的实现需要通过测试用例p3.07 ~ p3.12。
Task 3 - HashJoin Executor and Optimization
HashJoin
你需要仿照SimpleAggregationHashTable实现一个自己的hash table,用来存储左表的hash结果。接着获取右表的tuple, 以其Join列为key, 查询已经构建好的hash table. 将相同key值的tuple连接在一起。
或者,你可以在已经实现的SimpleAggregationHashTable上添加接口,如InsertForJoin(),这样就不用写一个大部分代码重复的结构了。但是SimpleAggregationHashTable这个名字似乎要改改,因为它不仅用来aggregate还用来hash Join.
总之,HashJoinExecutor依然是一个pipeline breaker, 我们需要在Init中建立hash table, 并进行Join, 保存Join结果。在Next中返回Join结果。
如果你还是不懂要怎么提取tuple的Join列列值的话,去看看PlanNode吧。可能存在多个Join条件,所以用了std::vector存储Expression. 但是left_key_expressions_和right_key_expressions_的size总是相同的。
你可能会有疑问:如果存在两个Join Col,这两个Join Col在两表中的相对顺序不同,那么left_key_expressions_和right_key_expressions_所表示的列是否会以正确顺序保存?在Live Shell验证下就知道了:
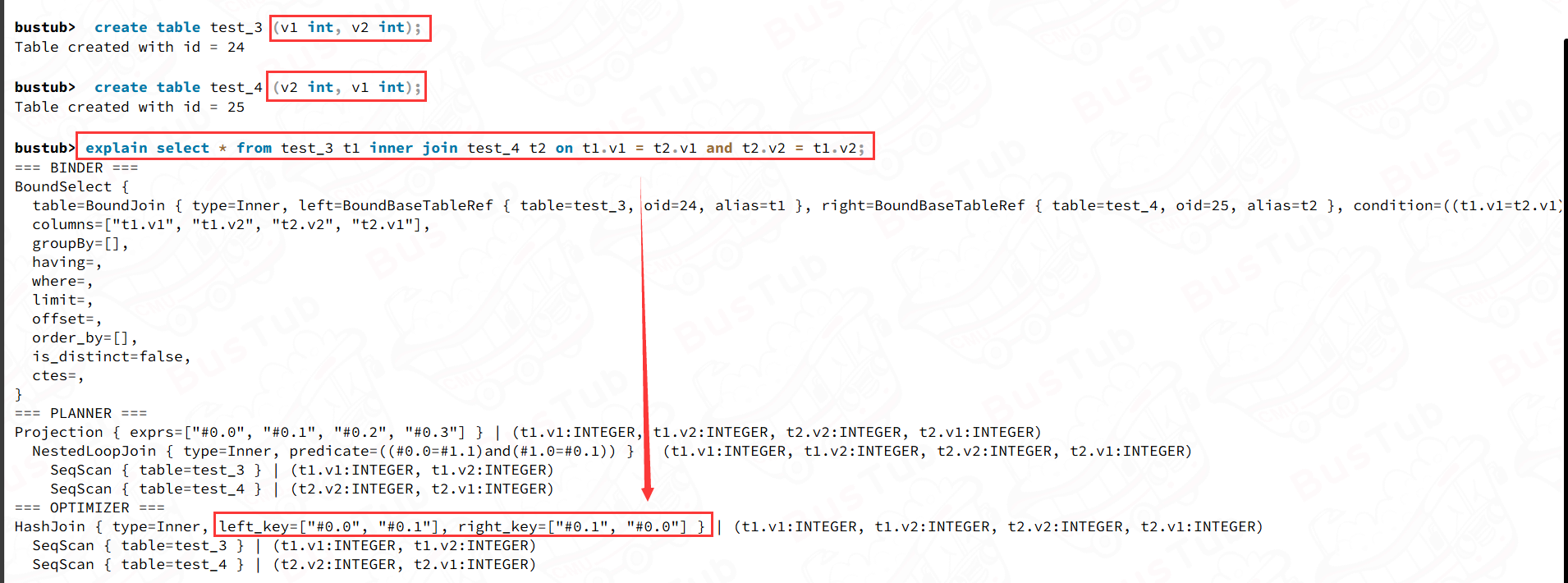
关于左连接:如果我们对左表建hash, 再用右表查询。此时想要知道左表的哪条tuple没有被Join过,会比较麻烦。所以你可以对右表建hash.
Optimizing NestedLoopJoin to HashJoin
当NLJ的Join条件都是等值表达式时,我们可以将其优化成HJ. 比如:

但是多个等值表达式需要用逻辑符号连接,只有这些符号都是AND时,才能进行优化。
你应该察觉到了:由于表达式是树形结构,需要递归遍历节点,判断表达式类型啊。所以你需要实现一个递归函数,遍历表达式树的每个表达式,同时你还需要维护left_key_expressions与right_key_expressions, 而等值比较表达式的左右子表达式类型一定为列值表达式。不过你不能断定左子表达式表示的列值一定是左表的列值,因此你需要根据列值表达式的tuple_idx_为0(左表的列值)还是1(右表的列值),进一步判断。
注意:在优化前,我们需要调用OptimizeMergeFilterNLJ()进行谓词下推。
Task 4: Sort + Limit Executors + Window Functions + Top-N Optimization
Sort
我们不需要实现外部排序,将表加载到内存中,用常规的排序算法即可。而排序也不应该修改原表,所以我们不需要把结果写回磁盘。
- 将表的所有tuple加载到
std::vector<Tuple> - 重载Tuple的比较器,调用
std::sort即可
如何重载Tuple的比较器?定义一个类,如TupleCompare,实现方法operator(),该方法需要比较两个Tuple,满足<=时返回true,否则返回false即可。调用std::sort()时,将该类的匿名对象作为参数传入即可。不过比较器还考虑order by的类型,以上比较方法为升序,这是默认的比较方法。如果order by desc,我们需要在满足>=时返回true,否则返回false.
如果你不知道怎么获取列值,可以看看PlanNode的order_bys_参数,调用Expression的Evaluate()即可。通过order_bys_也能获取order-by的类型。
Limit
记录调用子执行器的次数cnt,当cnt达到limit或者子执行器返回false时,返回false.
Top-N Optimization Rule
为什么要将order-by+limit优化成Top-N呢?考虑时空复杂度:Top-N的时间复杂度为 O ( N l o g K ) O(NlogK) O(NlogK), 空间复杂度为 O ( K ) O(K) O(K). 而order-by的时间复杂度为 O ( N l o g N ) O(NlogN) O(NlogN), 空间复杂度为 O ( N ) O(N) O(N). 无论在时间还是空间上,Top-N都是更好的选择。
关于优化规则:当前执行计划为Limit且子执行计划为Sort时,优化。
关于Top-N Executor的实现:我们需要利用std::priority_queue, 这是标准库为我们提供的堆,默认情况下是一个大堆,比较器在<=时返回true. 而我们需要实现Tuple的比较方法,这个在实现Sort时已经完成了。
我们需要考虑的是:order-by为降序时,需要输出前k个最大突破了,此时应该建大堆还是小堆?我们需要建小堆,可能有些反直觉。在遍历table时,我们将tuple push进小堆,如果堆满了,我们需要比较当前tuple和堆顶tuple的大小关系:
- 堆顶tuple是k个tuple中最小的,如果当前tuple比堆顶tuple还小,它一定不是前k个最大tuple
- 如果当前tuple比堆顶tuple大,它可能是前k个最大tuple,将堆顶tuple删除,push当前tuple进堆
根据以上规则,遍历完table, 我们就能维护出k个最大tuple, 不过堆顶的tuple是k个tuple中最小中,我们需要将所有tuple pop到vector中,并反转tuple(也可以在Next函数中倒着遍历vector).
总之,order-by为asc时,我们需要建大堆,使比较器在满足<=时返回true. order-by为desc时,我们需要建小堆,使比较器在满足>=时返回true. 这个规则和之前实现TupleCompare一致,所以直接拿来就行。和std:;sort不同,我们需要以模板参数的形式传入TupleCompare,如果你实现的TupleCompare需要显式调用构造函数,可以去cppreference.com查下关于priority_queue的构造函数。
至此,你的实现需要通过测试用例p3.16 ~ p3.19。
Window Functions
最后是一个有些难度的Executor: 窗口函数,和aggregate类似,将对分组中的tuple进行aggregate. 与之不同的是:窗口函数输出的tuple数量和原表相同,在不改变原schema的基础上,添加一个聚合列。就想给房子开窗一样,在原有的基础上进行添加。如果你之前不了解窗口函数,去问问gpt吧。
因此,如果查询含有窗口函数,那么PlanNode的列将用占位符替代,因为这是原表中不存在的列。如下所示:

也就是说,注释符的数量等于窗口函数的数量。
窗口函数有三个参数:order-by, parition-by(group-by), frame. 每个参数都是可选的,因此在不同的排列下,我们能组合出非常多种执行情况。在具体实现中,非常容易写成一堆条件的嵌套,使代码难以维护,所以官方不要求我们实现frame参数(其实我已经看不懂我的代码了~)。
再看PlanNode,其封装了WindowFunction,用来描述窗口函数:

- function_: over之前的表达式,如官方注释中的:sum(0,3) over. function_用来获取某列的值
- type_: 窗口类型,如:Rank, Sum, Avg. 聚合类型是窗口类型的子集
- partition_by_: 一些表达式,用于获取分组的列值。因为分组的列可能有多个,所以用了
std::vector - order_by_: 一些表达式+排序类型,用于获取排序的列值。因为排序的列可能有多个,所以用了
std::vector
显然,我们需要对原tuple执行以上表达式的Evaluate().
值得注意的是:查询语句中可能有多个窗口函数,如果这些窗口函数的order-by不同,我们需要不停地对中间结果进行排序。而官方向我们保证,如果存在多个order-by,那么它们一定是相同的,所以我们最多只需进行一次排序。
再看PlanNode的成员:std::unordered_map<uint32_t, WindowFunction> window_functions_,为什么key为uint32_t? 这表示了窗口函数在output schema中位于的列下标。
那么,我们要怎么获取非窗口函数列的列值?PlanNode还有一个成员:std::vector<AbstractExpressionRef> columns_,你可以测试一下它的大小和schema的列数量是否相同。显然这是当前schema的所有列值的表达式,如果是窗口函数列,表达式和WindowFunciton.function_相同。如果是非窗口函数列呢?它应该是原tuple的列值表达式,不妨测试一下:
我在Init函数中打印了当前查询语句的第4个列值表达式的列下标,代码如下:
auto col = dynamic_cast<const ColumnValueExpression*>(this->plan_->columns_[3].get());
std::cout << col->GetColIdx() << '\n';
测试结果如下:

如果为3,则说明它表示当前tuple的第4列。但结果为0,说明它表示原tuple的第1列。因为columns_[0]为窗口函数列,列下标也为0,表示当前tuple的第1列。
显然,我们需要通过PlanNode的columns_与原tuple获取非窗口函数列的列值。
知道了执行过程中必须的数据从何而来,我们再来看看要怎么处理这些数据?先不考虑Rank类型的窗口函数。与之前实现的AggregateExecutor类似,我们需要以parition-by对象为key, aggregate对象为value. 由于可能存在多个parition-by对象,我们可以用AggregateKey对多个Value进行封装。而窗口函数的aggregate只有一个aggregate对象,所以只有一个Value, 但是还是推荐你将其封装为AggregateValue. 你需要通过WindowFunction.partition_by_获取parition-by对象,通过WindowFunction.function_获取aggregate对象。之后就是将k-v插入到hash table中,你可以利用之前修改过的SimpleAggregationHashTable,也可以自己写一个类似的hash table.
以及:当order-by存在且parition-by存在时,aggregate应该从分组的第一个数据aggregate到当前数据。当order-by不存在,aggregate应该从分组的第一个数据aggregate到分组最后一条数据,如果aggregate不存在,可以将整张表视为一组。
所以你需要根据order-by是否存在,进行不同的aggregate. order-by存在时,你需要保存每一次的aggregate结果。不存在时,你只需要保存最后一次aggregate结果,像AggregationExecutor的InsertCombine一样。
而如果aggregate类型为Rank,你需要注意当前order key等于前一个order key时,Rank值应该与前者相同。但是不影响后续Rank, 比如可能存在这样一个Rank序列:1, 2, 2, 4, 但不可能存在这样的Rank序列:1, 2, 2, 3. 因为相同Rank不应该影响后续的Rank.
写在最后
Project 3给我的感受就是:无从下手,就算阅读了源码。写着写着就在考虑Executor需要从哪拿数据,特别是Expression的Evalute(), 文档甚至没有提到它,但是每个Executor基本都会用到它。我需要猜测其具体表示哪个表达式,它会返回Value表示什么…
最后,如果你对文章的某些描述感到疑惑,或是发现了文章的错误,欢迎在评论区提出: )



















