文章目录
- 1.高可用基本原理
- 1.NameNode 高可用性
- 主备 NameNode
- JournalNode
- 2.Zookeeper 协调
- 3.Quorum Journal Manager (QJM)
- 4.Failover 控制器
- 5.元数据共享
- 6.检查点机制
- 7.切换过程
- 2.Hadoop高可用配置
- 1.环境背景
- 2.hdfs-site.xml
- 基本配置
- 高可用配置
- 3.core-site.xml
- 基本配置
- 代理用户配置
- HTTP 静态用户配置
- I/O 配置
- 垃圾回收配置
- ZooKeeper 配置
- 3.分发配置文件
- 4.启动集群
- 1.关闭集群
- 2.zookeeper的启动
- 3.启动HDFS服务
- 5.测试高可用
- 1.检查节点状态
- 2.kill掉active节点
- 参考资料
1.高可用基本原理
1.NameNode 高可用性
在 Hadoop 生态系统中,NameNode 是文件系统的中心管理器,负责管理 HDFS 的元数据。为了避免单点故障(Single Point of Failure,SPOF),Hadoop 引入了 NameNode 的高可用性架构。主要组件包括:
主备 NameNode
- Active NameNode:当前负责处理客户端请求并管理 HDFS 元数据。
- Standby NameNode:处于热备状态,与 Active NameNode 保持同步,但不处理客户端请求。当 Active NameNode 故障时,Standby NameNode 会接管。
JournalNode
- 作用:JournalNode 充当共享存储的角色,记录 NameNode 的编辑日志(edits log)。
- 机制:当 Active NameNode 接收到客户端请求时,它会将操作记录到 JournalNode 集群中。Standby NameNode 也会从 JournalNode 中读取这些编辑日志,以保持元数据的同步。
2.Zookeeper 协调
Zookeeper 在 Hadoop HA 架构中用于管理 NameNode 的选主(leader election)和状态协调。它帮助确定当前哪个 NameNode 是 Active 的,并在故障发生时进行切换。
3.Quorum Journal Manager (QJM)
QJM 是管理 JournalNode 的组件,确保在集群中至少一半以上的 JournalNode 写入成功后,操作才被认为是持久化成功的。
4.Failover 控制器
Hadoop HA 中的 Failover 控制器(比如 ZKFailoverController)用于自动化主备 NameNode 的切换。它监控 Active NameNode 的健康状态,当检测到故障时,会自动切换到 Standby NameNode。
5.元数据共享
- 共享编辑日志:通过 JournalNode,所有 NameNode 共享同一个编辑日志,以保持一致性。
- 共享的状态(Namespace):Active 和 Standby NameNode 共享相同的命名空间,Standby NameNode 通过读取 JournalNode 的日志来不断更新其命名空间,以保持与 Active NameNode 的一致性。
6.检查点机制
Standby NameNode 会定期从 JournalNode 读取编辑日志,并将它们应用到自己的内存中。与此同时,它还会创建新的检查点(checkpoint),以减少系统重启时的恢复时间。
7.切换过程
- 故障检测:如果 Active NameNode 出现故障,Zookeeper 和 Failover 控制器会检测到并启动切换过程。
- 切换到 Standby NameNode:Standby NameNode 被激活并接管所有客户端请求。
- 恢复过程:故障的 Active NameNode 恢复后,会被设置为新的 Standby NameNode,等待下次切换。
这种 HA 架构确保了即使一个 NameNode 发生故障,另一个 NameNode 也能迅速接管,保证 HDFS 的高可用性和数据可靠性。
2.Hadoop高可用配置
1.环境背景
当前高可用在以下三台节点组成的hadoop3.3.4集群中进行配置,当前已经完成了集群安装,hdfs的验证,并且zookeeper组件已经安装完成。
| hostname | ip |
|---|---|
| ubuntu1 | 172.16.167.131 |
| ubuntu2 | 172.16.167.132 |
| ubuntu3 | 172.16.167.133 |
2.hdfs-site.xml
这是我当前配置 Hadoop HA(高可用)集群的hdfs-site.xml配置文件。
<configuration>
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>ubuntu2:9868</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/home/hadoop/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/home/hadoop/dfs/data</value>
</property>
<property>
<name>dfs.namenode.rpc-address</name>
<value>ubuntu1:8020</value>
</property>
<property>
<name>dfs.namenode.rpc-address</name>
<value>ubuntu2:8020</value>
</property>
<!-- 高可用配置开始 -->
<property>
<name>dfs.nameservices</name>
<value>mycluster</value>
</property>
<property>
<name>dfs.ha.namenodes.mycluster</name>
<value>nn1,nn2</value>
</property>
<property>
<name>dfs.namenode.rpc-address.mycluster.nn1</name>
<value>ubuntu1:8020</value>
</property>
<property>
<name>dfs.namenode.rpc-address.mycluster.nn2</name>
<value>ubuntu2:8020</value>
</property>
<property>
<name>dfs.namenode.http-address.mycluster.nn1</name>
<value>ubuntu1:50070</value>
</property>
<property>
<name>dfs.namenode.http-address.mycluster.nn2</name>
<value>ubuntu2:50070</value>
</property>
<property>
<name>dfs.journalnode.edits.dir</name>
<value>/usr/local/hadoop/data/journalnode</value>
</property>
<property>
<name>dfs.namenode.shared.edits.dir</name>
<value>qjournal://ubuntu1:8485;ubuntu2:8485;ubuntu3:8485/mycluster</value>
</property>
<property>
<name>dfs.client.failover.proxy.provider.mycluster</name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
</property>
<property>
<name>dfs.ha.fencing.methods</name>
<value>sshfence</value>
</property>
<property>
<name>dfs.ha.fencing.ssh.private-key-files</name>
<value>/root/.ssh/id_rsa</value>
</property>
<property>
<name>dfs.ha.automatic-failover.enabled</name>
<value>true</value>
</property>
<!-- 高可用配置结束 -->
</configuration>
基本配置
- dfs.replication:设置 HDFS 中文件的默认副本数。这里设置为 2,意味着每个文件会存储两个副本。
- dfs.namenode.secondary.http-address:配置 Secondary NameNode 的 HTTP 地址(在 HA 配置中通常不需要)。
- dfs.namenode.name.dir:NameNode 存储元数据的本地路径。
- dfs.datanode.data.dir:DataNode 存储数据块的本地路径。
- dfs.namenode.rpc-address:NameNode 的 RPC 地址。在 HA 配置中应通过服务名和节点标识来定义。
高可用配置
- dfs.nameservices:定义 HDFS 集群的逻辑名称,这里为
mycluster。 - dfs.ha.namenodes.mycluster:定义
mycluster集群中包含的 NameNode,这里为nn1和nn2。 - dfs.namenode.rpc-address.mycluster.nn1:
nn1的 RPC 地址,提供 HDFS 服务。 - dfs.namenode.rpc-address.mycluster.nn2:
nn2的 RPC 地址。 - dfs.namenode.http-address.mycluster.nn1:
nn1的 HTTP Web 界面地址。 - dfs.namenode.http-address.mycluster.nn2:
nn2的 HTTP Web 界面地址。 - dfs.journalnode.edits.dir:JournalNode 存储编辑日志的本地路径。
- dfs.namenode.shared.edits.dir:共享编辑日志的路径,这里使用的是 QJM(Quorum Journal Manager)方式,路径格式为
qjournal://{host1:port};{host2:port};{host3:port}/clustername。 - dfs.client.failover.proxy.provider.mycluster:设置客户端的 failover 代理提供者类,这里使用
ConfiguredFailoverProxyProvider,用于在 NameNode 之间自动切换。 - dfs.ha.fencing.methods:配置切断失效的 Active NameNode 的方法。这里使用
sshfence,即通过 SSH 命令来隔离失效的 NameNode。 - dfs.ha.fencing.ssh.private-key-files:指定用于 SSH 连接的私钥文件路径。
- dfs.ha.automatic-failover.enabled:启用自动故障转移。
3.core-site.xml
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://mycluster</value>
</property>
<!--2.指定hadoop 数据的存储目录默认为/tmp/hadoop-${user.name} -->
<property>
<name>hadoop.tmp.dir</name>
<value>/home/hadoop/tmp</value>
</property>
<!--hive.hosts 允许 root 代理用户访问 Hadoop 文件系统设置 -->
<property>
<name>hadoop.proxyuser.root.hosts</name>
<value>*</value>
</property>
<!--hive.groups 允许 Hive 代理用户访问 Hadoop 文件系统设置 -->
<property>
<name>hadoop.proxyuser.root.groups</name>
<value>*</value>
</property>
<!-- 配置 HDFS 网页登录使用的静态用户为 root -->
<property>
<name>hadoop.http.staticuser.user</name>
<value>root</value>
</property>
<!--配置缓存区的大小,实际可根据服务器的性能动态做调整-->
<property>
<name>io.file.buffer.size</name>
<value>4096</value>
</property>
<!--开启hdfs垃圾回收机制,可以将删除数据从其中回收,单位为分钟-->
<property>
<name>fs.trash.interval</name>
<value>10080</value>
</property>
<!--zookeeper-->
<property>
<name>ha.zookeeper.quorum</name>
<value>ubuntu1:2181,ubuntu2:2181,ubuntu3:2181</value>
</property>
</configuration>
core-site.xml 基于高可用的配置,主要用于配置 Hadoop 的核心设置,这里重点是zookeeper的配置项要加上。以下是每个配置项的解释:
基本配置
- fs.defaultFS:
- 设定 HDFS 的默认文件系统。这里指定为
hdfs://mycluster,表示使用高可用集群mycluster的 HDFS 作为默认文件系统。
- 设定 HDFS 的默认文件系统。这里指定为
- hadoop.tmp.dir:
- 指定 Hadoop 临时数据的存储目录。默认情况下,这些数据会存储在
/tmp/hadoop-${user.name}目录中,这里指定为/home/hadoop/tmp。
- 指定 Hadoop 临时数据的存储目录。默认情况下,这些数据会存储在
代理用户配置
- hadoop.proxyuser.root.hosts:
- 允许
root用户代理其他用户访问 Hadoop 文件系统的主机。*表示允许所有主机。
- 允许
- hadoop.proxyuser.root.groups:
- 允许
root用户代理其他用户访问 Hadoop 文件系统的用户组。*表示允许所有用户组。
- 允许
HTTP 静态用户配置
- hadoop.http.staticuser.user:
- 配置 HDFS 网页界面的静态用户为
root。这意味着访问 HDFS Web UI 时将默认使用root用户身份。
- 配置 HDFS 网页界面的静态用户为
I/O 配置
- io.file.buffer.size:
- 配置文件系统 I/O 操作的缓存区大小。这里设置为 4096 字节,可根据服务器性能进行调整。
垃圾回收配置
- fs.trash.interval:
- 开启 HDFS 垃圾回收机制的时间间隔,单位为分钟。这里设置为 10080 分钟(即 7 天)。在该时间段内删除的数据可以从回收站中恢复。
ZooKeeper 配置
- ha.zookeeper.quorum:
- 指定用于 Hadoop HA 配置的 ZooKeeper 集群的主机和端口。这里指定的三个 ZooKeeper 实例分别运行在
ubuntu1、ubuntu2和ubuntu3上,端口号为 2181。
- 指定用于 Hadoop HA 配置的 ZooKeeper 集群的主机和端口。这里指定的三个 ZooKeeper 实例分别运行在
3.分发配置文件
修改完hdfs-site.xml和core-site.xml一定要向集群中所有节点分发。
4.启动集群
由于更改了配置文件,所以要关闭集群再重启才能使高可用生效。
1.关闭集群
将hadoop集群所有组件停止服务。
stop-all.sh
2.zookeeper的启动
要保证zookeeper进程在后台运行,QuorumPeerMain需要在三台节点都运行。
在三台节点执行:
zkServer.sh start
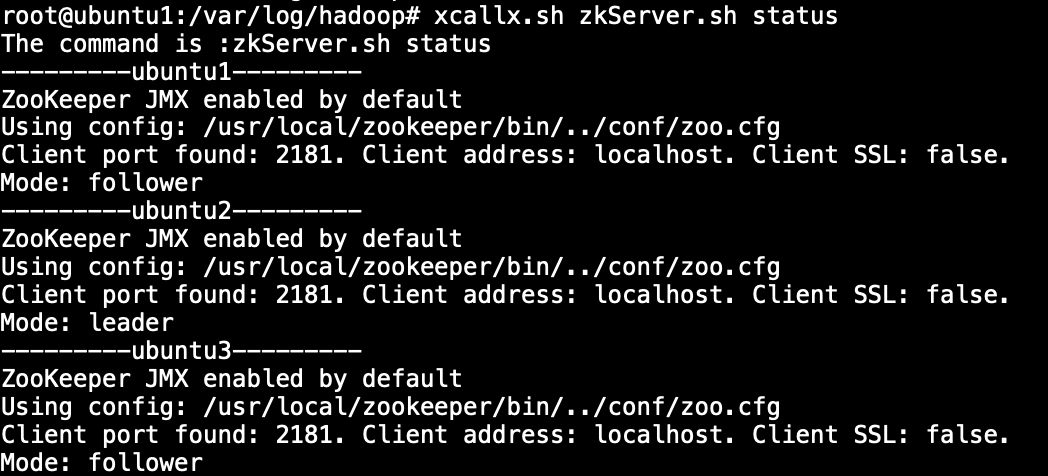
查看zookeeper状态:
zkServer.sh status
成功显示leader和follower
3.启动HDFS服务
- 启动
journalnode
在三台节点上都要启动:
hdfs --daemon start journalnode
如果因为启动失败而重新配置,需要将目录中的数据删除,再次启动:
rm -rf /usr/local/hadoop/data/journalnode/mycluster/*
- HDFS
NameNode的格式化,如果是第一次配置启动hadoop则需要格式化
hdfs namenode -format
- 在ubuntu1共享日志文件初初始化
hdfs namenode -initializeSharedEdits
- 启动hdfs
start-dfs.sh
# 或者使用群起命令
start-all.sh
如果启动时没有datanode进程,则应删除hdfs数据文件,避免clusterID冲突:
rm -rf /home/hadoop/dfs/data/*
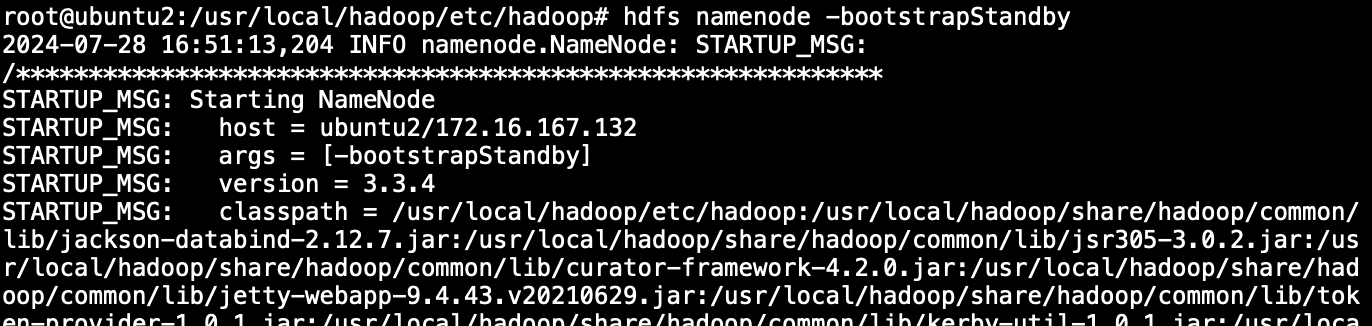
- 在ubuntu2同步镜像数据
hdfs namenode -bootstrapStandby
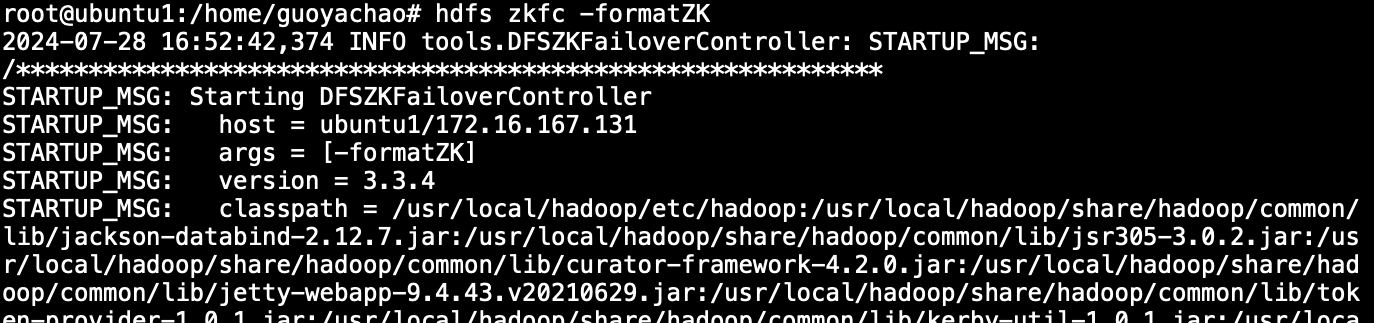
- zookeeper FailerController格式化
在主节点ubuntu1执行:
hdfs zkfc -formatZK
- 全部组建启动成功:
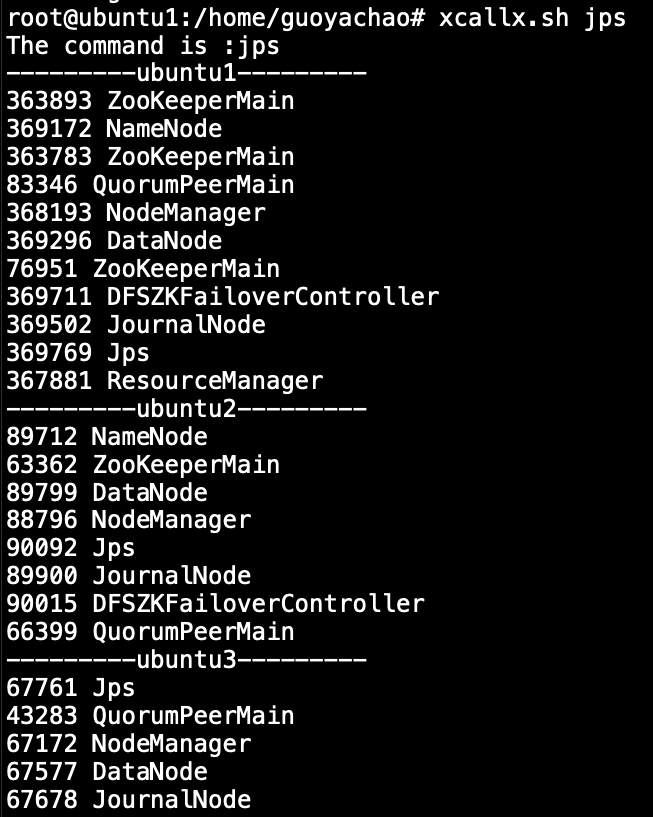 有多个
有多个ZooKeeperMain是因为我开启了一个zookeeper客户端连接,所以会有多个进程在后台。
5.测试高可用
1.检查节点状态
通过以下命令可以看到,ubuntu1为standby,ubuntu2为active。
root@ubuntu1:/home/guoyachao# hdfs haadmin -getServiceState nn1
2024-07-28 17:13:09,214 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
standby
root@ubuntu1:/home/guoyachao# hdfs haadmin -getServiceState nn2
2024-07-28 17:13:11,292 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
active
2.kill掉active节点
注意查看jps进程,我将ubuntu2的namenode进程kill掉,造成节点故障的现象。
root@ubuntu2:/usr/local/hadoop/etc/hadoop# jps
89712 NameNode
63362 ZooKeeperMain
89799 DataNode
90152 Jps
88796 NodeManager
89900 JournalNode
90015 DFSZKFailoverController
66399 QuorumPeerMain
root@ubuntu2:/usr/local/hadoop/etc/hadoop# jps|grep NameNode|awk '{print $1}'|xargs kill -9
root@ubuntu2:/usr/local/hadoop/etc/hadoop# jps
63362 ZooKeeperMain
90180 Jps
89799 DataNode
88796 NodeManager
89900 JournalNode
90015 DFSZKFailoverController
66399 QuorumPeerMain
此时查看节点状态,无法连接到Ubuntu2的namenode
root@ubuntu2:/usr/local/hadoop/etc/hadoop# hdfs haadmin -getServiceState nn1
2024-07-28 17:16:20,249 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
standby
root@ubuntu2:/usr/local/hadoop/etc/hadoop# hdfs haadmin -getServiceState nn2
2024-07-28 17:16:25,256 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
2024-07-28 17:16:26,292 INFO ipc.Client: Retrying connect to server: ubuntu2/172.16.167.132:8020. Already tried 0 time(s); retry policy is RetryUpToMaximumCountWithFixedSleep(maxRetries=1, sleepTime=1000 MILLISECONDS)
Operation failed: Call From ubuntu2/172.16.167.132 to ubuntu2:8020 failed on connection exception: java.net.ConnectException: Connection refused; For more details see: http://wiki.apache.org/hadoop/ConnectionRefused
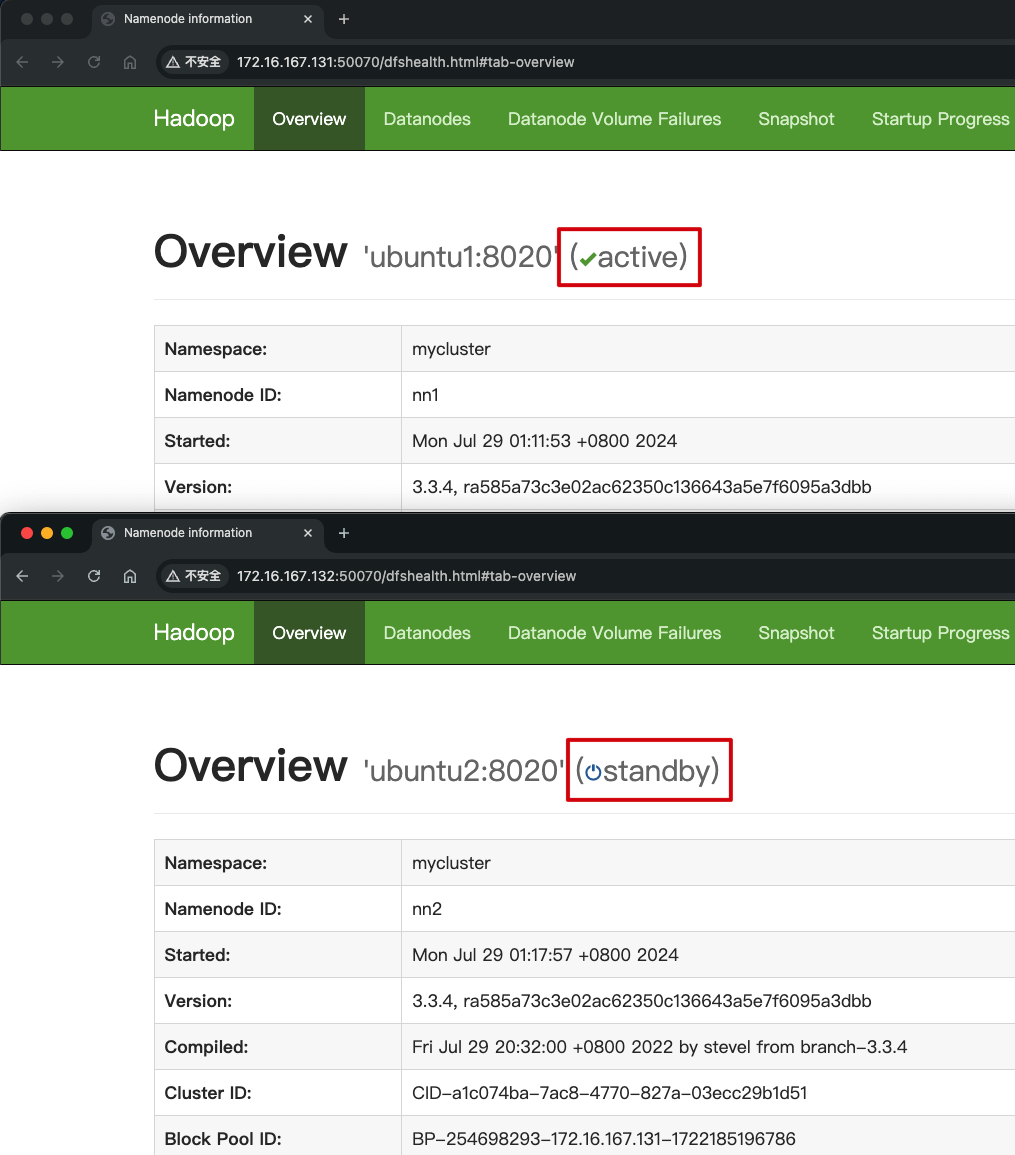
再次启动ubuntu2的namenode,并查看高可用状态,此时ubuntu1已经完成了状态切换。回显表示ubuntu2已经切换为了standby。
root@ubuntu2:/usr/local/hadoop/etc/hadoop# hdfs --daemon start namenode
root@ubuntu2:/usr/local/hadoop/etc/hadoop# hdfs haadmin -getServiceState nn2
2024-07-28 17:19:14,086 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
standby
也可以在web界面查看,ubuntu1自动完成了active的切换:
参考资料
- 【尚硅谷HA教程(大数据ha快速入门)】 https://www.bilibili.com/video/BV1zb411P7KY/?share_source=copy_web&vd_source=bde27502bfa0838cc98c5cf2835884aa
- 【CSDN HDFS高可用】:http://t.csdnimg.cn/9TkdQ
- 【Hadoop官方文档】https://hadoop.apache.org/docs/r3.3.4/hadoop-project-dist/hadoop-hdfs/HDFSHighAvailabilityWithQJM.html
- 【Hadoop 3.3.4 HA(高可用)原理与实现(QJM)】https://www.cnblogs.com/liugp/p/16607424.html