七、详解ByteBuf缓冲区
为了确保引用计数不会混乱,在Netty的业务处理器开发过程中,应该坚持一个原则:retain和release方法应该结对使用。简单地说,在一个方法中,调用了retain,就应该调用一次release。
public void handlMethodA(ByteBufbyteBuf) {
byteBuf.retain();
try {
handlMethodB(byteBuf);
} finally {
byteBuf.release();
}
}
如果retain和release这两个方法,一次都不调用呢?则在缓冲区使用完成后,调用一次release,就是释放一次。例如在Netty流水线上,中间所有的Handler业务处理器处理完ByteBuf之后直接传递给下一个,由最后一个Handler负责调用release来释放缓冲区的内存空间。
当引用计数已经为0, Netty会进行ByteBuf的回收。分为两种情况:(1)Pooled池化的ByteBuf内存,回收方法是:放入可以重新分配的ByteBuf池子,等待下一次分配。(2)Unpooled未池化的ByteBuf缓冲区,回收分为两种情况:如果是堆(Heap)结构缓冲,会被JVM的垃圾回收机制回收;如果是Direct类型,调用本地方法释放外部内存(unsafe.freeMemory)。
7. ByteBuf的Allocator分配器
Netty通过ByteBufAllocator分配器来创建缓冲区和分配内存空间。Netty提供了ByteBufAllocator的两种实现:PoolByteBufAllocator和UnpooledByteBufAllocator。
PoolByteBufAllocator(池化ByteBuf分配器)将ByteBuf实例放入池中,提高了性能,将内存碎片减少到最小;这个池化分配器采用了jemalloc高效内存分配的策略,该策略被好几种现代操作系统所采用。
UnpooledByteBufAllocator是普通的未池化ByteBuf分配器,它没有把ByteBuf放入池中,每次被调用时,返回一个新的ByteBuf实例;通过Java的垃圾回收机制回收。
为了验证两者的性能,大家可以做一下对比试验:
(1)使用UnpooledByteBufAllocator的方式分配ByteBuf缓冲区,开启10000个长连接,每秒所有的连接发一条消息,再看看服务器的内存使用量的情况。
实验的参考结果:在短时间内,可以看到占到10GB多的内存空间,但随着系统的运行,内存空间不断增长,直到整个系统内存被占满而导致内存溢出,最终系统宕机。
(2)把UnpooledByteBufAllocator换成PooledByteBufAllocator,再进行试验,看看服务器的内存使用量的情况。
实验的参考结果:内存使用量基本能维持在一个连接占用1MB左右的内存空间,内存使用量保持在10GB左右,经过长时间的运行测试,我们会发现内存使用量都能维持在这个数量附近,系统不会因为内存被耗尽而崩溃。
在Netty中,默认的分配器为ByteBufAllocator.DEFAULT,可以通过Java系统参数(System Property)的选项io.netty.allocator.type进行配置,配置时使用字符串值:“unpooled”, “pooled”。
不同的Netty版本,对于分配器的默认使用策略是不一样的。在Netty 4.0版本中,默认的分配器为UnpooledByteBufAllocator。而在Netty 4.1版本中,默认的分配器为PooledByteBufAllocator。现在PooledByteBufAllocator已经广泛使用了一段时间,并且有了增强的缓冲区泄漏追踪机制。因此,可以在Netty程序中设置启动器Bootstrap的时候,将PooledByteBufAllocator设置为默认的分配器。
ServerBootstrap b = new ServerBootstrap()
//....
//4 设置通道的参数
b.option(ChannelOption.SO_KEEPALIVE, true);
b.option(ChannelOption.ALLOCATOR, PooledByteBufAllocator.DEFAULT);
b.childOption(ChannelOption.ALLOCATOR, PooledByteBufAllocator.DEFAULT);
//....
内存管理的策略可以灵活调整,这是使用Netty所带来的又一个好处。只需一行简单的配置,就能获得到池化缓冲区带来的好处。在底层,Netty为我们干了所有“脏活、累活”!这主要是因为Netty用到了Java的Jemalloc内存管理库。
使用分配器分配ByteBuf的方法有多种。下面列出主要的几种:
package com.crazymakercircle.netty.bytebuf;
//...
public class AllocatorTest {
@Test
public void showAlloc() {
ByteBuf buffer = null;
//方法一:分配器默认分配初始容量为9,最大容量100的缓冲区
buffer = ByteBufAllocator.DEFAULT.buffer(9, 100);
//方法二:分配器默认分配初始容量为256,最大容量Integer.MAX_VALUE的缓冲区
buffer = ByteBufAllocator.DEFAULT.buffer();
//方法三:非池化分配器,分配基于Java的堆(Heap)结构内存缓冲区
buffer = UnpooledByteBufAllocator.DEFAULT.heapBuffer();
//方法四:池化分配器,分配基于操作系统管理的直接内存缓冲区
buffer = PooledByteBufAllocator.DEFAULT.directBuffer();
//…..其他方法
}
}
如果没有特别的要求,使用第一种或者第二种分配方法分配缓冲区即可。
8. ByteBuf缓冲区的类型
根据内存的管理方不同,分为堆缓存区和直接缓存区,也就是Heap ByteBuf和Direct ByteBuf。另外,为了方便缓冲区进行组合,提供了一种组合缓存区。
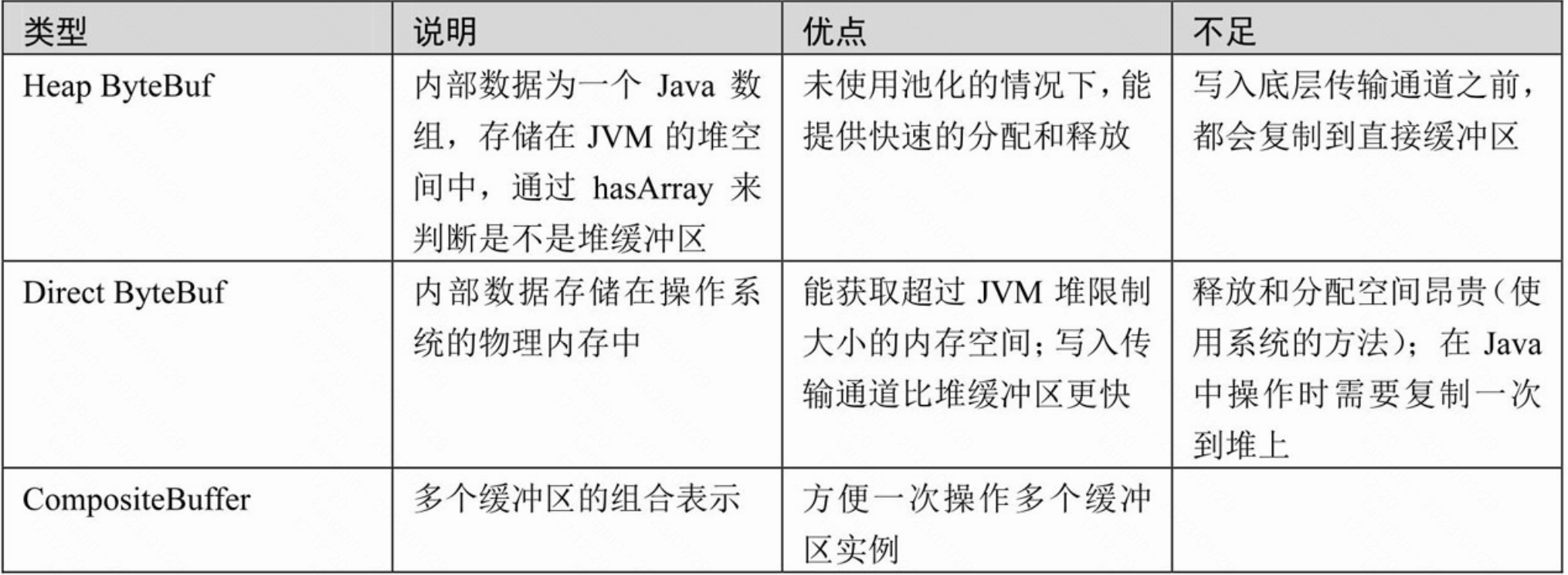
上面三种缓冲区的类型,无论哪一种,都可以通过池化(Pooled)、非池化(Unpooled)两种分配器来创建和分配内存空间。
下面对Direct Memory(直接内存)进行一下特别的介绍:
- Direct Memory不属于Java堆内存,所分配的内存其实是调用操作系统malloc()函数来获得的;由Netty的本地内存堆Native堆进行管理。
- Direct Memory容量可通过-XX:MaxDirectMemorySize来指定,如果不指定,则默认与Java堆的最大值(-Xmx指定)一样。注意:并不是强制要求,有的JVM默认Direct Memory与-Xmx无直接关系。
- Direct Memory的使用避免了Java堆和Native堆之间来回复制数据。在某些应用场景中提高了性能。
- 在需要频繁创建缓冲区的场合,由于创建和销毁Direct Buffer(直接缓冲区)的代价比较高昂,因此不宜使用Direct Buffer。也就是说,Direct Buffer尽量在池化分配器中分配和回收。如果能将Direct Buffer进行复用,在读写频繁的情况下,就可以大幅度改善性能。
- 对Direct Buffer的读写比Heap Buffer快,但是它的创建和销毁比普通Heap Buffer慢。
- 在Java的垃圾回收机制回收Java堆时,Netty框架也会释放不再使用的Direct Buffer缓冲区,因为它的内存为堆外内存,所以清理的工作不会为Java虚拟机(JVM)带来压力。注意一下垃圾回收的应用场景:(1)垃圾回收仅在Java堆被填满,以至于无法为新的堆分配请求提供服务时发生;(2)在Java应用程序中调用System.gc()函数来释放内存。
Heap ByteBuf和Direct ByteBuf两类缓冲区的使用。它们有以下几点不同:
· 创建的方法不同:Heap ByteBuf通过调用分配器的buffer()方法来创建;而Direct ByteBuf的创建,是通过调用分配器的directBuffer()方法。
· Heap ByteBuf缓冲区可以直接通过array()方法读取内部数组;而Direct ByteBuf缓冲区不能读取内部数组。
· 可以调用hasArray()方法来判断是否为Heap ByteBuf类型的缓冲区;如果hasArray()返回值为true,则表示是Heap堆缓冲,否则就不是。
· Direct ByteBuf要读取缓冲数据进行业务处理,相对比较麻烦,需要通过getBytes/readBytes等方法先将数据复制到Java的堆内存,然后进行其他的计算。


![[论文分享] How could Neural Networks understand Programs?](https://img-blog.csdnimg.cn/90029c3b25094c3d9bed51403e10dbd1.png)











![[leetcode 215] 数组中的第K个最大元素](https://img-blog.csdnimg.cn/cf0ed000f7f64ded8ac31e469680fbc3.png)

