总结:本文为和鲸python 可视化探索训练营资料整理而来,加入了自己的理解(by GPT4o)
注意跟练题目3中提到的多种数据替换方式,非常值得学习!!
原作者:作者:大话数据分析,知乎、公众号【大话数据分析】主理人,5年数据分析经验,前蚂蚁金服数据运营,现京东经营分析师。
原活动链接
目录
- 第四节 电商数据可视化案例
- 一、用户画像
- 1.数据处理
- 1.1数据信息查看
- 1.2数据类型转换
- 1.3计算客户年龄
- 1.4客户年龄分组
- ⏳跟练题目1
- 2.数据可视化
- 2.1性别差异
- ⏳跟练题目2
- 2.2婚姻状况
- 2.3文化程度
- 代码解释
- 2.4年龄段差异
- 3.用户画像仪表盘
- 二、销售数据分析
- 1.数据处理
- 1.1数据信息查看
- 1.2数值替换处理
- ⏳跟练题目3 *
- 1.3数据分列处理
- 2.数据可视化
- 2.1单量趋势
- ⏳跟练题目4
- 2.2销量分析
- 2.3利润分析
- 2.4成本分析
- 2.5销售额分析
- 2.6品类分析
- 3.销售分析仪表盘
- 三、闯关题
- STEP1: 按照要求计算下方题目结果
第四节 电商数据可视化案例
本节你将学习两个经典的电商数据分析案例:用户画像分析和销售数据分析。通过本节的实操学习,你将掌握使用Pandas数据处理、Matplotlib数据可视化两方面知识,并制作交互式仪表盘来整合分析结果,对于用户分析和策略制定具有非常高的实用价值,而且,还有助于你更好地理解和掌握销售数据分析的全流程,对于在未来职场中参与销售策略制定、市场预测等工作提供有力支持。
核心知识点
1.案例分析:用户画像
- Pandas数据处理
- Matplotlib可视化
- 用户画像仪表盘
2.案例分析:销售数据分析
- Pandas数据处理
- Matplotlib可视化
- 销售分析仪表盘
一、用户画像
什么是用户画像?
用户画像是指根据用户的属性、行为、需求等信息而抽象出的一个标签化的用户模型。它是对用户信息进行标签化的过程,以方便计算机处理。用户画像的作用主要表现在以下几个方面:
- 精准营销:通过用户画像,企业可以了解目标用户的需求和偏好,从而制定更精准的营销策略,提高营销效果。
- 个性化推荐:基于用户画像,可以为用户提供个性化的产品和服务推荐,提升用户满意度和忠诚度。
- 产品优化:通过分析用户画像,企业可以了解用户的需求和痛点,针对性地优化产品功能和设计,提高产品的用户体验。
- 市场分析:用户画像可以帮助企业了解市场的整体趋势和用户需求变化,从而指导企业的市场决策。
因此,用户画像在电商、互联网、金融等各个领域都得到了广泛的应用。对于电商平台而言,建立准确的用户画像有助于更好地理解用户需求,提升用户体验,实现精准营销和个性化服务。
描述电商用户画像维度
- 基础信息维度:包括用户的年龄、性别、地域、职业等基础信息,这些信息有助于了解用户的基本特征和背景。
- 购买行为维度:包括用户的购买频率、购买时间、购买商品种类等,这些信息可以揭示用户的购买习惯和购买力。
1.数据处理
首先,导入数据,数据包含基础信息维度,比如出生日期、性别、婚姻状况、文化程度等,以及购买行为维度,比如购买时间、购买频率、购买金额等。
import pandas as pd
import numpy as np
# 设置随机数种子
np.random.seed(42)
data = pd.read_csv(r'./data/EM4_用户下单数据.csv',
engine='python',
encoding='gbk')
data.head()
| 用户ID | 用户出生日期 | 性别 | 婚姻状况 | 文化程度 | 下单时间 | 订单ID | 交易金额 | |
|---|---|---|---|---|---|---|---|---|
| 0 | 6414111 | 1991/8/24 | 男 | 已婚 | 本科 | 2020/1/1 17:41 | 1000595826 | 402.765811 |
| 1 | 6516117 | 1983/7/21 | 女 | 已婚 | 博士 | 2021/10/15 22:47 | 1000610643 | 545.273062 |
| 2 | 6714112 | 1986/6/21 | 女 | 已婚 | 博士 | 2020/11/22 09:45 | 1001934364 | 256.716973 |
| 3 | 5311117 | 1978/5/25 | 女 | 未婚 | 大专 | 2021/3/26 11:53 | 1007749907 | 275.547080 |
| 4 | 4316113 | 1979/8/1 | 男 | 未婚 | 大专 | 2021/7/10 18:59 | 1007770144 | 1023.500156 |
1.1数据信息查看
查看数据分基本维度,如果有缺失值数据,可对缺失值数据做填充。
#查看是否有缺失值
data.info()
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 5000 entries, 0 to 4999
Data columns (total 8 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 用户ID 5000 non-null int64
1 用户出生日期 5000 non-null object
2 性别 5000 non-null object
3 婚姻状况 5000 non-null object
4 文化程度 5000 non-null object
5 下单时间 5000 non-null object
6 订单ID 5000 non-null int64
7 交易金额 5000 non-null float64
dtypes: float64(1), int64(2), object(5)
memory usage: 312.6+ KB
1.2数据类型转换
为了确保数据处理的准确性,对数据类型进行适当的检查和转换是非常重要的,如果两个不同类型的数据进行运算,可能会产生错误或不可预知的结果。比如,在算术运算中,如果一个是整数类型,另一个是字符串类型,那么这可能导致错误,因为这两种类型的数据无法进行数学运算。
#查看数据类型
data.dtypes
用户ID int64
用户出生日期 object
性别 object
婚姻状况 object
文化程度 object
下单时间 object
订单ID int64
交易金额 float64
dtype: object
将字符型数据转化为日期型数据,用于计算用户年龄以及下单的时间间隔。
# 将用户出生日期处理为为日期数据类型
data['用户出生日期'] = pd.to_datetime(data['用户出生日期'],format='%Y/%m/%d')
# 将交易日期处理为日期数据类型
data['下单时间'] = pd.to_datetime(data['下单时间'],infer_datetime_format=True).dt.date
C:\Users\Cheng\AppData\Local\Temp\ipykernel_23656\3633062673.py:5: UserWarning: The argument 'infer_datetime_format' is deprecated and will be removed in a future version. A strict version of it is now the default, see https://pandas.pydata.org/pdeps/0004-consistent-to-datetime-parsing.html. You can safely remove this argument.
data['下单时间'] = pd.to_datetime(data['下单时间'],infer_datetime_format=True).dt.date
#将用户ID和订单ID转化为字符型数据
data['用户ID']=data['用户ID'].astype('str')
data['订单ID']=data['订单ID'].astype('str')
1.3计算客户年龄
按照间隔天数近似计算用户的年龄。
# 假设2023-11-11是计算当天,求当天距离用户出生日期的间隔天数
data['间隔天数'] = pd.to_datetime('2023-11-11') - data['用户出生日期']
# 从时间距离中获取天数
data['间隔天数'] = data['间隔天数'].dt.days
data['年龄']=(data['间隔天数']/365).round(0)
data.head()
| 用户ID | 用户出生日期 | 性别 | 婚姻状况 | 文化程度 | 下单时间 | 订单ID | 交易金额 | 间隔天数 | 年龄 | |
|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 6414111 | 1991-08-24 | 男 | 已婚 | 本科 | 2020-01-01 | 1000595826 | 402.765811 | 11767 | 32.0 |
| 1 | 6516117 | 1983-07-21 | 女 | 已婚 | 博士 | 2021-10-15 | 1000610643 | 545.273062 | 14723 | 40.0 |
| 2 | 6714112 | 1986-06-21 | 女 | 已婚 | 博士 | 2020-11-22 | 1001934364 | 256.716973 | 13657 | 37.0 |
| 3 | 5311117 | 1978-05-25 | 女 | 未婚 | 大专 | 2021-03-26 | 1007749907 | 275.547080 | 16606 | 45.0 |
| 4 | 4316113 | 1979-08-01 | 男 | 未婚 | 大专 | 2021-07-10 | 1007770144 | 1023.500156 | 16173 | 44.0 |
这里求年龄的极差(最大值减去最小值),我们近似可以分为10个年龄段组别。
#年龄求分位数
print('年龄最小值: {}'.format(data['年龄'].min()))
print('年龄平均值: {}'.format(data['年龄'].mean()))
print('年龄最大值: {}'.format(data['年龄'].max()))
年龄最小值: 23.0
年龄平均值: 39.6336
年龄最大值: 56.0
1.4客户年龄分组
使用pd.qcut函数,将用户的年龄自动分组,按照相同的组距分为不同的年龄段,设置将年龄段分为10组。
#自动分组
age_qcut=pd.qcut(data['年龄'],10)
data['年龄分组']=age_qcut
data.head()
| 用户ID | 用户出生日期 | 性别 | 婚姻状况 | 文化程度 | 下单时间 | 订单ID | 交易金额 | 间隔天数 | 年龄 | 年龄分组 | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 6414111 | 1991-08-24 | 男 | 已婚 | 本科 | 2020-01-01 | 1000595826 | 402.765811 | 11767 | 32.0 | (30.0, 34.0] |
| 1 | 6516117 | 1983-07-21 | 女 | 已婚 | 博士 | 2021-10-15 | 1000610643 | 545.273062 | 14723 | 40.0 | (37.0, 40.0] |
| 2 | 6714112 | 1986-06-21 | 女 | 已婚 | 博士 | 2020-11-22 | 1001934364 | 256.716973 | 13657 | 37.0 | (34.0, 37.0] |
| 3 | 5311117 | 1978-05-25 | 女 | 未婚 | 大专 | 2021-03-26 | 1007749907 | 275.547080 | 16606 | 45.0 | (43.0, 46.0] |
| 4 | 4316113 | 1979-08-01 | 男 | 未婚 | 大专 | 2021-07-10 | 1007770144 | 1023.500156 | 16173 | 44.0 | (43.0, 46.0] |
⏳跟练题目1
✍跟练1:以上我们使用pd.qcut()设置参数自动将年龄数据分组,在实际应用场景中,我们也会使用loc()的形式来手动分组,原理也比较简单,就是使用loc筛选特定条件的数据,然后赋值,从而达到手动分组的目的,请你尝试使用loc方法来手动分组。
💡 提示:在使用这种赋值方法分组时,需要提前copy()拷贝一个数据,确保原始数据不要被更改,同时,要预先初始化一个新的列,用于存放新的赋值数据,你可以直接运行下面的程序,或者自己更改,从而达到手动分组的目的。
#创建数据拷贝,这样可以确保原始数据不会被更改
data1 = data.copy()
#初始化一个新的列'loc分组',并为其分配一个空字符串
data1['loc分组']=''
#使用loc方法为不同年龄段的数据分配不同的标签
data1.loc[(data1['年龄'] >= 20) & (data1['年龄'] < 30), 'loc分组'] = '20~30岁'
data1.loc[(data1['年龄'] >= 30) & (data1['年龄'] < 40), 'loc分组'] = '30~40岁'
data1.loc[(data1['年龄'] >= 40) & (data1['年龄'] < 50), 'loc分组'] = '40~50岁'
data1.loc[(data1['年龄'] >= 50) & (data1['年龄'] < 60), 'loc分组'] = '50~60岁'
data1
| 用户ID | 用户出生日期 | 性别 | 婚姻状况 | 文化程度 | 下单时间 | 订单ID | 交易金额 | 间隔天数 | 年龄 | 年龄分组 | loc分组 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 6414111 | 1991-08-24 | 男 | 已婚 | 本科 | 2020-01-01 | 1000595826 | 402.765811 | 11767 | 32.0 | (30.0, 34.0] | 30~40岁 |
| 1 | 6516117 | 1983-07-21 | 女 | 已婚 | 博士 | 2021-10-15 | 1000610643 | 545.273062 | 14723 | 40.0 | (37.0, 40.0] | 40~50岁 |
| 2 | 6714112 | 1986-06-21 | 女 | 已婚 | 博士 | 2020-11-22 | 1001934364 | 256.716973 | 13657 | 37.0 | (34.0, 37.0] | 30~40岁 |
| 3 | 5311117 | 1978-05-25 | 女 | 未婚 | 大专 | 2021-03-26 | 1007749907 | 275.547080 | 16606 | 45.0 | (43.0, 46.0] | 40~50岁 |
| 4 | 4316113 | 1979-08-01 | 男 | 未婚 | 大专 | 2021-07-10 | 1007770144 | 1023.500156 | 16173 | 44.0 | (43.0, 46.0] | 40~50岁 |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 4995 | 6518114 | 1984-02-28 | 女 | 已婚 | 博士 | 2023-05-22 | 8991789286 | 703.983370 | 14501 | 40.0 | (37.0, 40.0] | 40~50岁 |
| 4996 | 3615116 | 1977-05-11 | 女 | 未婚 | 中专 | 2023-01-19 | 8993443974 | 468.703603 | 16985 | 47.0 | (46.0, 49.0] | 40~50岁 |
| 4997 | 4212112 | 1987-09-06 | 女 | 已婚 | 中专 | 2022-06-13 | 8993812802 | 530.658640 | 13215 | 36.0 | (34.0, 37.0] | 30~40岁 |
| 4998 | 4812120 | 1970-04-29 | 女 | 已婚 | 本科 | 2021-11-04 | 8993866163 | 605.657681 | 19554 | 54.0 | (52.0, 56.0] | 50~60岁 |
| 4999 | 5112117 | 1993-09-24 | 男 | 未婚 | 大专 | 2020-12-18 | 8997660647 | 254.759645 | 11005 | 30.0 | (27.0, 30.0] | 30~40岁 |
5000 rows × 12 columns
2.数据可视化
2.1性别差异
深入了解用户画像中的性别分析是至关重要的。在当今日益多元化的市场中,不同性别的消费者往往展现出截然不同的消费习惯和需求。通过精细的性别分析,企业能够更好地洞察目标用户的喜好、购买习惯以及消费心理,从而制定出更为精准有效的营销策略。
随着社会的进步和观念的转变,性别在消费中的角色也在发生变化。比如,现今越来越多的女性在职场取得成功,她们的购买力与消费决策影响力也随之增强。因此,针对不同性别的用户制定专属的市场策略,如产品设计、宣传方式、促销策略等,将有助于企业捕捉市场机遇,提升竞争力。
性别分析作为用户画像中的重要组成部分,对于经管专业的学生来说,掌握其精髓并运用到实际工作中,无疑将为企业在激烈的市场竞争中获得更多的优势。这样的细分分析能够为企业提供更丰富的市场细分策略,帮助企业确定最有潜力的目标市场。
#不使用科学计数法,格式化为小数点后保留一位
pd.set_option('display.float_format', lambda x: '%.1f' % x)
df_pay_sex=data.groupby('性别')['交易金额'].sum().reset_index()
df_pay_sex
| 性别 | 交易金额 | |
|---|---|---|
| 0 | 女 | 1507590.6 |
| 1 | 男 | 1361555.0 |
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt #导入matplotlib包
import matplotlib.style as psl
import warnings
#魔法命令,用于在笔记本内联显示matplotlib图表
%matplotlib inline
warnings.filterwarnings("ignore") # 忽略警告信息
plt.rcParams['font.sans-serif'] = ['SimHei'] # 用来正常显示中文标签
plt.rcParams['axes.unicode_minus'] = False # 用来正常显示负号
plt.rcParams['figure.dpi'] = 100 # 分辨率
psl.use('ggplot')
plt.figure(figsize = (9, 6)) #设置图表画布大小
#导入数据
x=df_pay_sex['交易金额'].tolist()
labels = df_pay_sex['性别'].tolist()
#饼图
plt.pie(x,#导入数据
autopct='%.1f%%',#数据标签
labels=labels,
startangle=90, #初始角度
pctdistance=0.87, # 设置百分比标签与圆心的距离
explode=[0.01,0], # 突出显示数据
textprops = {'fontsize':12, 'color':'k'}, # 设置文本标签的属性值
counterclock = False, # 是否逆时针
)
plt.title("不同性别交易金额占比")
plt.show()

⏳跟练题目2
✍跟练2:上面我们对不同性别客户的交易金额占比做分析,但实际上,我们对于不同性别客户的订单数占比也应该做分析,根据客单价=客户交易金额/客户订单数,研究订单数占比可侧面分析不同性别客户的客单价分布情况,请做一个不同性别客户的订单数占比圆环图,直观地展示不同性别客户的订单数占比。
💡 提示:对不同性别的订单数 [‘订单ID’] 做分组统计可使用groupby函数,plt.pie()函数调节wedgeprops参数可做圆环图,做出来的图表应类似如下的图表。
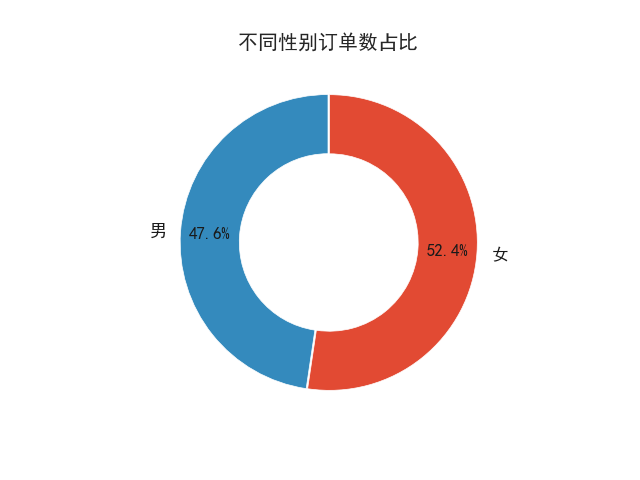
2.2婚姻状况
深入了解和分析用户的婚姻状况是用户画像中的重要一环。婚姻状况往往能够揭示出用户的生活阶段、家庭结构、经济状况以及消费习惯等多方面的信息,这些信息对于企业精准定位目标用户和制定营销策略具有不可估量的价值。
首先,婚姻状况能够反映出用户的生活阶段。已婚用户往往更加成熟稳定,他们可能更关注家庭、子女教育、房产等方面的产品和服务。而未婚用户可能更加关注个人成长、娱乐、旅行等方面的消费。针对不同婚姻状况的用户,企业可以制定相应的产品和服务策略,以满足他们不同的需求。
其次,婚姻状况还可以透露出用户的经济状况。一般来说,已婚用户可能拥有更为稳定的家庭经济来源,他们的消费能力相对较强。而未婚用户可能更注重个性化、时尚化的产品,对于价格敏感度较高。因此,在定价和推广策略上,企业可以针对不同婚姻状况的用户进行合理的区分。
最后,婚姻状况分析还有助于企业了解用户的消费习惯和决策方式。已婚用户可能在购买决策上更加注重家庭成员的意见和感受,而未婚用户可能更加自主和独立。因此,在营销手段上,企业可以针对不同婚姻状况的用户采取不同的宣传和推广方式,以提高营销效果。
婚姻状况分析对于经管专业的学习者来说是一项重要的任务。通过深入了解和分析用户的婚姻状况,企业能够更准确地把握用户需求和市场趋势,从而制定出更加精准有效的营销策略,提升市场竞争力。
#不使用科学计数法,格式化为小数点后保留一位
pd.set_option('display.float_format', lambda x: '%.1f' % x)
df_pay_mary=data.groupby('婚姻状况')['交易金额'].sum().reset_index()
df_pay_mary
| 婚姻状况 | 交易金额 | |
|---|---|---|
| 0 | 已婚 | 1345481.9 |
| 1 | 未婚 | 1523663.7 |
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt #导入matplotlib包
import matplotlib.style as psl
import warnings
#魔法命令,用于在笔记本内联显示matplotlib图表
%matplotlib inline
warnings.filterwarnings("ignore") # 忽略警告信息
plt.rcParams['font.sans-serif'] = ['SimHei'] # 用来正常显示中文标签
plt.rcParams['axes.unicode_minus'] = False # 用来正常显示负号
plt.rcParams['figure.dpi'] = 100 # 分辨率
psl.use('ggplot')
plt.figure(figsize = (9, 6)) #设置图表画布大小
x=df_pay_mary['婚姻状况'].tolist()
y1=df_pay_mary['交易金额'].tolist()
#绘制圆环图
plt.pie(y1,#用于绘制饼图的数据,表示每个扇形的面积
labels=x,#各个扇形的标签,默认值为 None。
radius=1.0,#设置饼图的半径,默认为 1
startangle=90, #初始角度
explode=[0.01,0], # 突出显示数据
wedgeprops= dict(edgecolor = "w",width = 0.4),#指定扇形的属性,比如边框线颜色、边框线宽度等
autopct='%.1f%%',#设置饼图内各个扇形百分比显示格式,%0.1f%% 一位小数百分比
pctdistance=0.8#指定 autopct 的位置刻度
)
#设置标题
plt.title("不同婚姻状况交易金额占比", loc = "center")
#图像展示
plt.show()

2.3文化程度
对用户进行文化程度分析是深入了解目标市场的重要一环。文化程度不仅反映了个体的教育背景和知识水平,还能在一定程度上揭示其消费观念、价值取向以及信息接收能力等方面的特征。因此,合理有效地进行文化程度分析有助于企业更准确地把握用户需求,进而实现精准营销。
在进行文化程度分析时,经管专业的学生首先需要关注目标用户群体的受教育程度,如中专、大专、本科、研究生及以上的分布情况。不同受教育程度的用户往往具有不同的信息接收能力和消费观念。例如,受过高等教育的用户可能更倾向于理性消费,注重产品的品质和性价比,而受教育程度相对较低的用户可能更容易受到广告和促销活动的影响。
此外,文化程度分析还应关注用户的专业领域和职业背景。不同专业和职业的用户往往具有不同的兴趣和需求。例如,从事技术行业的用户可能更关注产品的创新性和科技含量,而从事艺术行业的用户可能更注重产品的设计感和审美价值。
基于文化程度分析的结果,经管专业的学生可以为企业提供有针对性的市场策略建议。例如,针对受教育程度较高的用户群体,可以加大在产品品质、售后服务和品牌建设等方面的投入;针对具有特定专业和职业背景的用户,可以推出符合他们兴趣和需求的专业化产品或服务。
data['文化程度'].tolist()[:10]
['本科', '博士', '博士', '大专', '大专', '本科', '中专', '博士', '中专', '中专']
这里使用plt.text()函数来添加数据标签。我们指定了每个标签的x坐标(通过p.get_x() + p.get_width() / 2计算得到)和y坐标(通过p.get_height()得到),ha='center’和va='bottom’参数用于水平居中对齐和垂直底部对齐标签。
palette='Greens_d’是Seaborn中一种预设的调色板,属于Sequential调色板中的一种,用于表示从低到高的单一序列。Greens_d调色板包含不同深浅的绿色,颜色从浅到深表示数值从小到大的变化。除此之外,还有其他预设的调色板可供选择,Blues、Oranges、BuGn_r、RdYlGn、BrBG、PiYG、PRGn、RdBu、YlGnBu、Cmap。
import seaborn as sns
import matplotlib.pyplot as plt
psl.use('ggplot')
plt.figure(figsize = (9, 6)) #设置图表画布大小
#导入原始数据
data=data
ax = sns.countplot(x='文化程度',data=data,palette='Blues')#计数图
plt.title("不同文化程度人数计数", loc="center")#设置标题
#添加数据标签
# 显示数据标签
for p in ax.patches:
plt.text(p.get_x() + p.get_width() / 2, p.get_height(), f'{str(p.get_height())}人',
ha='center', va='bottom')
plt.ylabel("人数")
plt.show()

在这段代码中,我们使用 seaborn 绘制了一个计数图(countplot),并在图上添加了数据标签。这段代码的关键部分是如何在每个柱子(柱形图)上添加显示数据值的标签。以下是对这段代码中标签添加过程的详细解释:
代码解释
-
导入库并设置环境:
import seaborn as sns import matplotlib.pyplot as plt # 确保图表内联显示并以SVG格式显示 %matplotlib inline %config InlineBackend.figure_format = 'svg'seaborn用于数据可视化,matplotlib.pyplot用于图形展示和图形设置。%matplotlib inline用于在 Jupyter Notebook 中显示图形。%config InlineBackend.figure_format = 'svg'设置图形以 SVG 格式显示,以确保图形的清晰度。
-
设置图形样式和大小:
psl.use('ggplot') plt.figure(figsize=(9, 6)) # 设置图表画布大小- 使用
ggplot样式,使图形更加美观。 plt.figure(figsize=(9, 6))设置图形的宽度和高度。
- 使用
-
绘制计数图:
ax = sns.countplot(x='文化程度', data=data, palette='Blues') # 计数图 plt.title("不同文化程度人数计数", loc="center") # 设置标题sns.countplot绘制一个柱状图,x 轴为文化程度,计数每个类别的数量。palette='Blues'设置柱子的颜色。plt.title设置图表的标题。
-
添加数据标签:
for p in ax.patches: plt.text(p.get_x() + p.get_width() / 2, p.get_height(), f'{str(p.get_height())}人', ha='center', va='bottom')ax.patches返回图形中所有的矩形对象(柱子)。for p in ax.patches循环遍历每个柱子。plt.text在每个柱子上方添加文本标签。p.get_x() + p.get_width() / 2计算柱子中心的 x 坐标。p.get_height()获取柱子的高度,即计数值。f'{str(p.get_height())}人'创建标签文本,表示人数。ha='center'将文本水平居中于柱子。va='bottom'将文本放置在柱子顶端。
-
设置 y 轴标签并显示图表:
plt.ylabel("人数") plt.show()plt.ylabel设置 y 轴的标签。plt.show()显示图形。
2.4年龄段差异
对目标市场进行细致的年龄段分析是市场研究中不可或缺的一环。年龄段分析能够帮助企业深入了解各个年龄层消费者的特点、需求以及消费习惯,为企业制定有针对性的市场策略提供重要依据。
在进行年龄段分析时,需要关注不同年龄段消费者的核心特征和差异。例如,年轻消费者(如90后、00后)通常更加注重个性化和时尚感,对新媒体和科技产品更加熟悉和依赖;而中老年消费者可能更加看重产品的实用性、品质和口碑,对传统媒体和线下购物有更深的情感认同。
此外,不同年龄段的消费者在消费能力和消费观念上也存在显著差异。年轻消费者往往拥有较强的消费潜力和较高的购买力,更容易接受信贷消费和分期付款等新型消费方式;而中老年消费者可能更注重储蓄和投资,对价格和消费成本更加敏感。
针对这些差异,经管专业的学生可以为企业提供有针对性的市场策略建议。例如,针对年轻消费者,可以加大在社交媒体、短视频等新媒体平台的营销投入,推出个性化、时尚化的产品设计和包装;针对中老年消费者,可以加强品牌口碑建设,提供优质的售后服务和客户关怀,同时注重产品的实用性和性价比。
年龄段分析对于经管专业的学生来说是一项基础且关键的市场分析工作。通过深入了解各个年龄段的消费者特点和需求,企业能够制定更加精准有效的市场策略,提升品牌竞争力和市场份额。
df_age=data.groupby(['年龄分组'])['交易金额'].sum().reset_index()
df_age
| 年龄分组 | 交易金额 | |
|---|---|---|
| 0 | (22.999, 27.0] | 292805.2 |
| 1 | (27.0, 30.0] | 297144.4 |
| 2 | (30.0, 34.0] | 350413.1 |
| 3 | (34.0, 37.0] | 281342.1 |
| 4 | (37.0, 40.0] | 321637.7 |
| 5 | (40.0, 43.0] | 294724.5 |
| 6 | (43.0, 46.0] | 273285.6 |
| 7 | (46.0, 49.0] | 255085.8 |
| 8 | (49.0, 52.0] | 268330.2 |
| 9 | (52.0, 56.0] | 234377.0 |
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt #导入matplotlib包
import matplotlib.style as psl
psl.use('ggplot')
plt.figure(figsize = (9, 6)) #设置图表画布大小
x=df_age['年龄分组'].astype('str').tolist()
y=df_age['交易金额'].tolist()
#绘制柱状图
plt.bar(x,y,width=0.5,align="center",label="金额")
plt.title("不同年龄段交易情况", loc="center")#设置标题
#添加数据标签
for a,b in zip(x, y):
plt.text(a,b,f'{b/10000:.1f}万',ha = "center", va = "bottom", fontsize = 10)
plt.xlabel("年龄分段",labelpad=5)#设置x和y轴的名称
plt.ylabel("交易金额")
plt.xticks(rotation=15,fontsize=9,color='k')#设置X坐标轴刻度
plt.yticks([])#设置不显示Y坐标轴刻度
plt.legend(fontsize=9,)#显示图例
plt.show()

3.用户画像仪表盘
用户画像仪表盘用于整合和展示用户画像相关的数据和分析结果。可将复杂的用户数据以直观、易懂的方式展现出来,帮助团队深入了解用户特点、跟踪用户行为、发现用户需求并做出数据驱动的决策。通过不断优化产品和服务以满足用户的需求,企业可以提高竞争力并实现可持续发展。通过仪表盘,团队不仅可以直观地看到关于用户的基本信息、行为特征、兴趣偏好等关键指标,从而快速了解用户群体的整体情况。而且,可以根据不同的维度(如年龄、性别、地域等)展示用户的分布情况,帮助团队识别不同的用户细分群体及其特点。更重要的是,基于仪表盘提供的用户画像数据,团队可以更明智地制定营销策略、产品改进方案等,提高用户满意度和忠诚度。
import pandas as pd
import numpy as np
import seaborn as sns
import matplotlib.pyplot as plt #导入matplotlib包
import matplotlib.style as psl
psl.use('ggplot')
plt.figure(figsize = (12, 8)) #设置图表画布大小
#饼图
plt.subplot(2,2,1)
#导入数据
x=df_pay_sex['交易金额'].tolist()
labels = df_pay_sex['性别'].tolist()
plt.pie(x,#导入数据
autopct='%.1f%%',#数据标签
labels=labels,
startangle=90, #初始角度
pctdistance=0.8, # 设置百分比标签与圆心的距离
explode=[0.01,0], # 突出显示数据
textprops = {'fontsize':9, 'color':'k'}, # 设置文本标签的属性值
counterclock = False, # 是否逆时针
)
plt.title("不同性别交易金额占比",fontsize=12,color='k')
#圆环图
plt.subplot(2,2,2)
x=df_pay_mary['婚姻状况'].tolist()
y1=df_pay_mary['交易金额'].tolist()
#绘制圆环图
plt.pie(y1,#用于绘制饼图的数据,表示每个扇形的面积
labels=x,#各个扇形的标签,默认值为 None。
radius=1.0,#设置饼图的半径,默认为 1
startangle=90, #初始角度
explode=[0.01,0], # 突出显示数据
wedgeprops= dict(edgecolor = "w",width = 0.4),#指定扇形的属性,比如边框线颜色、边框线宽度等
autopct='%.1f%%',#设置饼图内各个扇形百分比显示格式,%0.1f%% 一位小数百分比
textprops = {'fontsize':9, 'color':'k'}, # 设置文本标签的属性值
pctdistance=0.8#指定 autopct 的位置刻度
)
#设置标题
plt.title("不同婚姻状况交易金额占比",loc = "center",fontsize=12,color='k')
#计数图
plt.subplot(2,2,3)
#导入原始数据
data=data
ax = sns.countplot(x='文化程度',data=data,palette='Blues')#计数图
plt.title("不同文化程度人数计数", loc="center",fontsize=12,color='k')#设置标题
#添加数据标签
# 显示数据标签
for p in ax.patches:
plt.text(p.get_x() + p.get_width() / 2, p.get_height(), f'{str(p.get_height())}人',
ha='center', va='bottom')
plt.ylabel("人数",fontsize =9,color='k')
#柱形图
plt.subplot(2,2,4)
x=df_age['年龄分组'].astype('str').tolist()
y=df_age['交易金额'].tolist()
plt.bar(x,y,width=0.5,align="center",label="金额",color='#348abd')
plt.title("不同年龄段交易情况", loc="center",fontsize=12,color='k')#设置标题
#添加数据标签
for a,b in zip(x, y):
plt.text(a,b,f'{b/10000:.1f}万',ha="center",va ="bottom",fontsize =9)
plt.xlabel("年龄分段",labelpad=5,fontsize =9,color='k')#设置x和y轴的名称
plt.ylabel("交易金额",fontsize =9,color='k')
plt.xticks(rotation=25,fontsize=6,color='k')#设置X坐标轴刻度
plt.yticks([])#设置不显示Y坐标轴刻度
plt.suptitle("用户画像仪表盘",fontsize=16,color='k')
plt.show()
#plt.savefig('my_figure1.png')

二、销售数据分析
什么是电商销售数据分析?
电商销售数据分析是电商运营中的核心环节,尤其对于经管专业的学习者来说,掌握这一技能至关重要。电商销售数据分析不仅仅是对数据的简单统计和呈现,更是一种深度的、基于数据的商业洞察。对于经管专业的学习者来说,掌握电商销售数据分析的技能,不仅有助于深入理解电商平台的运营机制,更能为未来从事电商相关工作打下坚实的基础。
具体来说,电商销售数据分析是一个系统性的过程,它开始于收集电商平台上的各种销售数据。这些数据包括但不限于商品浏览量、加购量、订单数量、订单金额、用户行为等。这些原始数据,经过整理、筛选和清洗,将被转化为有意义的信息。接下来的分析环节,则是要通过各种统计和分析方法,对这些数据进行进一步的挖掘。
通过对比不同时间段内的销售数据,可发现销售的季节性趋势;通过分析用户的购买路径和频次,可洞察用户的购买行为和习惯;通过研究不同商品的销售表现,可发掘市场的潜在机会。电商销售数据分析的目标是为电商平台的运营决策提供支持。基于分析结果,电商平台可以调整商品策略,优化购物流程,提升用户体验,或者针对性地开展营销活动。而这些决策的调整和优化,都有助于电商平台提升销售业绩,增强市场竞争力。
1.数据处理
对收集到的数据进行清洗,去除重复、无效、异常的数据,确保数据的准确性和完整性。
import pandas as pd
df_sale=pd.read_excel(r'./data/EM4_电商销售数据.xlsx',#指定文件路径
dtype={'订单号':str},#指定列的数据类型
parse_dates=['日期']#解析为日期列
)
df_sale.head()
| 日期 | 订单号 | 区域 | 客户性别 | 客户年龄 | 商品品类 | 进货价格 | 实际售价 | 销售数 | 销售额 | 利润 | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 2023-11-01 | 10021404488 | 华东-上海市-上海 | 女 | 22 | 床品件套 | ¥4150 | 7090 | 11 | 77990 | 32340 |
| 1 | 2023-11-01 | 10021344597 | 华北-山西省-忻州 | 女 | 59 | 厨房电器 | ¥14000 | 17220 | 6 | 103320 | 19320 |
| 2 | 2023-11-01 | 10021531018 | 东北-辽宁省-辽阳 | 女 | 24 | 床品件套 | ¥7100 | 5680 | 3 | 17040 | -4260 |
| 3 | 2023-11-01 | 10021583928 | 东北-吉林省-松原 | 女 | 33 | 床品件套 | ¥11000 | 16170 | 2 | 32340 | 10340 |
| 4 | 2023-11-01 | 10021353159 | 西南-四川省-乐山 | 女 | 34 | 床品件套 | ¥8350 | 11180 | 10 | 111800 | 28300 |
1.1数据信息查看
info()显示 DataFrame 的简要摘要,包括索引类型、列名、非空值计数和数据类型,从而对整体数据的内容做一个概览,可以快速了解数据的特征和质量。
df_sale.info()
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 7284 entries, 0 to 7283
Data columns (total 11 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 日期 7284 non-null datetime64[ns]
1 订单号 7284 non-null object
2 区域 7284 non-null object
3 客户性别 7284 non-null object
4 客户年龄 7284 non-null int64
5 商品品类 7284 non-null object
6 进货价格 7284 non-null object
7 实际售价 7284 non-null int64
8 销售数 7284 non-null int64
9 销售额 7284 non-null int64
10 利润 7284 non-null int64
dtypes: datetime64[ns](1), int64(5), object(5)
memory usage: 626.1+ KB
1.2数值替换处理
数值替换能够处理数据中的异常值、错误值或者不符合分析需求的数值,使数据更符合预期和分析的要求,这里将人民币符号 ‘¥’ 进行替换,然后将进货价格数据类型转化为浮点型,这样就可以做数值运算。
df_sale['进货价格']=df_sale['进货价格'].str.replace('¥','').astype('float')
df_sale.head()
| 日期 | 订单号 | 区域 | 客户性别 | 客户年龄 | 商品品类 | 进货价格 | 实际售价 | 销售数 | 销售额 | 利润 | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 2023-11-01 | 10021404488 | 华东-上海市-上海 | 女 | 22 | 床品件套 | 4150.0 | 7090 | 11 | 77990 | 32340 |
| 1 | 2023-11-01 | 10021344597 | 华北-山西省-忻州 | 女 | 59 | 厨房电器 | 14000.0 | 17220 | 6 | 103320 | 19320 |
| 2 | 2023-11-01 | 10021531018 | 东北-辽宁省-辽阳 | 女 | 24 | 床品件套 | 7100.0 | 5680 | 3 | 17040 | -4260 |
| 3 | 2023-11-01 | 10021583928 | 东北-吉林省-松原 | 女 | 33 | 床品件套 | 11000.0 | 16170 | 2 | 32340 | 10340 |
| 4 | 2023-11-01 | 10021353159 | 西南-四川省-乐山 | 女 | 34 | 床品件套 | 8350.0 | 11180 | 10 | 111800 | 28300 |
再次查看数据信息,基本的数据类型已经转化,可以进一步做数据处理。
df_sale.info()
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 7284 entries, 0 to 7283
Data columns (total 11 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 日期 7284 non-null datetime64[ns]
1 订单号 7284 non-null object
2 区域 7284 non-null object
3 客户性别 7284 non-null object
4 客户年龄 7284 non-null int64
5 商品品类 7284 non-null object
6 进货价格 7284 non-null float64
7 实际售价 7284 non-null int64
8 销售数 7284 non-null int64
9 销售额 7284 non-null int64
10 利润 7284 non-null int64
dtypes: datetime64[ns](1), float64(1), int64(5), object(4)
memory usage: 626.1+ KB
⏳跟练题目3 *
✍跟练3:上面使用str.replace()将特殊字符进行了替换,实际上,我们有多种方式对于特定数据字段做替换,比如使用replace()函数、使用map()函数、使用loc[]进行条件替换、使用where()函数进行条件替换、使用mask()函数进行条件替换,以上替换方法可实现数据的差异化替换,可根据数据需求进行处理。
💡 提示:请使用下面的销售数据集,借助上面多种数据替换方法来实现,以满足具体的数据处理需求。
- 将销售额中的¥替换为’',将销售额2133替换为10000。
df['str_rep替换'] = df['销售额'].str.replace('¥','').astype('int')
df['int_rep替换'] = df['str_rep替换'].replace(2133, 10000)
- map函数根据映射关系替换值,映射关系为{‘北京’:‘上海’,‘广州’:‘杭州’,‘上海’:‘上海’, ‘杭州’: ‘杭州’}。
df['map替换'] = df['城市'].map({'北京':'上海','广州':'杭州','上海':'上海', '杭州': '杭州'})
- 使用loc[]来进行条件替换,这里对销售数进行条件替换,从而达到销售数分组目的。
df = df.copy() # 不会保护原始数据不变,是为了避免潜在的链式赋值问题:特别是在使用 .loc、.iloc 或直接赋值时
df['loc替换']=''
df.loc[(df['销售数']>=100) & (df['销售数']<200),'loc替换']='100~200单'
df.loc[(df['销售数']>=200) & (df['销售数']<300),'loc替换']='200~300单'
df.loc[(df['销售数']>=300),'loc替换']='300单以上'
- 使用mask()函数来进行条件替换,对于满足条件的数据进行替换。
df['mask替换']=df['年龄'].mask(df['年龄']<18,'小于18岁')
- mask()函数的逆运算,使用where()函数进行条件替换。
df['where替换']=df['年龄'].where(df['年龄']>18,'小于18岁')
#如下是一个销售数据集
import pandas as pd
df = pd.DataFrame({'订单ID':['JD00','JD01','JD02','JD03','JD04','JD05'],
'城市':['北京', '上海', '广州', '上海', '杭州', '北京'],
'年龄':[13,30,14,32,34,12],
'性别':['男','女','男','女','男','男'],
'销售数':[320,100,200,300,200,300],
'销售额':['¥3200','¥1356','¥2133','¥3986','¥2980','¥3452']},
columns =['订单ID','城市','年龄','性别','销售数','销售额'])
df
| 订单ID | 城市 | 年龄 | 性别 | 销售数 | 销售额 | |
|---|---|---|---|---|---|---|
| 0 | JD00 | 北京 | 13 | 男 | 320 | ¥3200 |
| 1 | JD01 | 上海 | 30 | 女 | 100 | ¥1356 |
| 2 | JD02 | 广州 | 14 | 男 | 200 | ¥2133 |
| 3 | JD03 | 上海 | 32 | 女 | 300 | ¥3986 |
| 4 | JD04 | 杭州 | 34 | 男 | 200 | ¥2980 |
| 5 | JD05 | 北京 | 12 | 男 | 300 | ¥3452 |
df['str_rep替换'] = df['销售额'].str.replace('¥','').astype('int')
df['int_rep替换'] = df['str_rep替换'].replace(2133, 10000)
df['map替换'] = df['城市'].map({'北京':'上海','广州':'杭州','上海':'上海','杭州':'杭州'})
df = df.copy()
df['loc替换'] = ''
df.loc[(df['销售数']>=100) & (df['销售数']<200),'loc替换']='100~200单'
df.loc[(df['销售数']>=200) & (df['销售数']<300),'loc替换']='200~300单'
df.loc[df['销售数']>=300,'loc替换']='300单以上'
df['mask替换']=df['年龄'].mask(df['年龄']<18,'小于18岁')
df['where替换']=df['年龄'].where(df['年龄']>18,'小于18岁')
df.head()
| 订单ID | 城市 | 年龄 | 性别 | 销售数 | 销售额 | str_rep替换 | int_rep替换 | map替换 | loc替换 | mask替换 | where替换 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | JD00 | 北京 | 13 | 男 | 320 | ¥3200 | 3200 | 3200 | 上海 | 300单以上 | 小于18岁 | 小于18岁 |
| 1 | JD01 | 上海 | 30 | 女 | 100 | ¥1356 | 1356 | 1356 | 上海 | 100~200单 | 30 | 30 |
| 2 | JD02 | 广州 | 14 | 男 | 200 | ¥2133 | 2133 | 10000 | 杭州 | 200~300单 | 小于18岁 | 小于18岁 |
| 3 | JD03 | 上海 | 32 | 女 | 300 | ¥3986 | 3986 | 3986 | 上海 | 300单以上 | 32 | 32 |
| 4 | JD04 | 杭州 | 34 | 男 | 200 | ¥2980 | 2980 | 2980 | 杭州 | 200~300单 | 34 | 34 |
1.3数据分列处理
区域部分是按照短’-‘进行连接的,可以使用str.split()方法按照短杠’-'进行分列,从而得到更容易操作的数据。
df_split=df_sale['区域'].str.split(pat='-',expand=True)#数据拆分
df_sale['区域']=df_split.iloc[:,0]
df_sale['省份']=df_split.iloc[:,1]
df_sale['城市']=df_split.iloc[:,2]
df_sale.head()
| 日期 | 订单号 | 区域 | 客户性别 | 客户年龄 | 商品品类 | 进货价格 | 实际售价 | 销售数 | 销售额 | 利润 | 省份 | 城市 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 2023-11-01 | 10021404488 | 华东 | 女 | 22 | 床品件套 | 4150.0 | 7090 | 11 | 77990 | 32340 | 上海市 | 上海 |
| 1 | 2023-11-01 | 10021344597 | 华北 | 女 | 59 | 厨房电器 | 14000.0 | 17220 | 6 | 103320 | 19320 | 山西省 | 忻州 |
| 2 | 2023-11-01 | 10021531018 | 东北 | 女 | 24 | 床品件套 | 7100.0 | 5680 | 3 | 17040 | -4260 | 辽宁省 | 辽阳 |
| 3 | 2023-11-01 | 10021583928 | 东北 | 女 | 33 | 床品件套 | 11000.0 | 16170 | 2 | 32340 | 10340 | 吉林省 | 松原 |
| 4 | 2023-11-01 | 10021353159 | 西南 | 女 | 34 | 床品件套 | 8350.0 | 11180 | 10 | 111800 | 28300 | 四川省 | 乐山 |
2.数据可视化
电商销售数据分析的可视化不仅能直观地展现数据,还能帮助发现隐藏的信息和规律,为电商平台的运营策略提供关键支持。同时,它也促进了团队内部的沟通和协作,助力企业在竞争激烈的市场环境中做出迅速而准确的应对,电商销售数据可视化对电商企业具有极高的参考价值。
通过可视化方式,能够直观地展示大量销售数据,如销售额、订单量等。这样的展示方式更易于理解和解读,使得用户可以快速掌握数据的核心含义。并且,能够揭示数据中隐藏的关联和趋势。如,通过散点图可以观察产品的价格与销量之间的关系;通过热力图可以展现不同时间和地区的销售热度。
2.1单量趋势
电商销售数据分析中的一个重要内容是单量趋势分析。对于经管专业的学习者来说,掌握单量趋势分析技能对于深入理解电商业务具有重要意义。单量趋势分析是指通过收集、整理并分析电商平台的订单数据,来研究订单量的变化趋势和规律。这种分析能够帮助我们了解消费者的购买行为和市场需求,从而为电商平台的运营和决策提供支持。
在进行单量趋势分析时,可观察订单量在不同时间尺度上的变化情况。通过对比历史数据,可以发现季节性、周期性或趋势性的变化,进而预测未来一段时间内的订单量走势。同时,还可以结合其他相关数据进行分析,如销售额、转化率、客单价等指标,来揭示订单量与这些因素之间的关系。
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt #导入matplotlib包
import matplotlib.style as psl
psl.use('ggplot')
plt.figure(figsize = (9, 6)) #设置图表画布大小
df_sale_line=df_sale.groupby('日期')['销售数'].sum().reset_index()
x=df_sale_line['日期'].astype('str').tolist()
y=df_sale_line['销售数'].tolist()
plt.plot(x,y,color="red",linestyle= "--",linewidth=1,marker="o",markersize=5)
plt.xlabel("日期",labelpad = 10) #设置X轴距离,labelpad控制标题到图表的距离
plt.ylabel("电商销售数",labelpad = 10) #设置Y轴距离,labelpad控制标题到图表的距离
plt.title('双十一销售量数据趋势', loc = "center")
plt.xticks(x, ['{}日'.format(i+1) for i in range(30)],rotation=45,fontsize=9,color='k')#设置X坐标轴刻度
plt.yticks(fontsize=9,color='k')#设置Y坐标轴刻度
plt.grid(visible = True,linestyle='dashed')#设置网格线为虚线,axis='y'可只对Y轴打开网格线
for a,b in zip(x, y):
plt.text(a,b,b, ha = "center", va = "bottom", fontsize = 9)
plt.show()

⏳跟练题目4
✍跟练4:根据每年双十一的销售惯例,11月9日到15日这是一个销售单量的高峰期,对于这个高峰期的单量可以做单独研究,筛选这期间的销售数据并做柱形图,研究其波动趋势,发现销售规律。
💡 提示:筛选特定范围内的数据使用between(),plt.bar()做图,要求包含基本的图表元素,使得图表表现形式更加丰富一些,做出来的图表应类似如下图表。
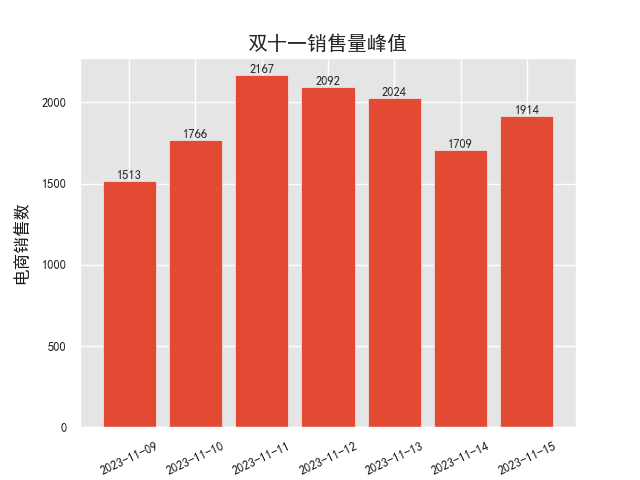
df_sale.info()
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 7284 entries, 0 to 7283
Data columns (total 13 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 日期 7284 non-null datetime64[ns]
1 订单号 7284 non-null object
2 区域 7284 non-null object
3 客户性别 7284 non-null object
4 客户年龄 7284 non-null int64
5 商品品类 7284 non-null object
6 进货价格 7284 non-null float64
7 实际售价 7284 non-null int64
8 销售数 7284 non-null int64
9 销售额 7284 non-null int64
10 利润 7284 non-null int64
11 省份 7284 non-null object
12 城市 7284 non-null object
dtypes: datetime64[ns](1), float64(1), int64(5), object(6)
memory usage: 739.9+ KB
# 将'日期'列转换为日期时间格式
# df['日期'] = pd.to_datetime(df['日期'])
# 筛选出2023年11月9号到11月15号之间的订单数据
start_date = '2023-11-09'
end_date = '2023-11-15'
filtered_df = df_sale[df_sale['日期'].between(start_date, end_date)]
filtered_df
| 日期 | 订单号 | 区域 | 客户性别 | 客户年龄 | 商品品类 | 进货价格 | 实际售价 | 销售数 | 销售额 | 利润 | 省份 | 城市 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1965 | 2023-11-09 | 10021498757 | 东北 | 男 | 48 | 床品件套 | 14550.0 | 11150 | 1 | 11150 | 4000 | 辽宁省 | 营口 |
| 1966 | 2023-11-09 | 10021387249 | 东北 | 男 | 34 | 汽车配件 | 7400.0 | 12780 | 12 | 153360 | 40560 | 辽宁省 | 营口 |
| 1967 | 2023-11-09 | 10021497509 | 东北 | 男 | 35 | 家装饰品 | 8450.0 | 23170 | 3 | 69510 | 28860 | 黑龙江 | 伊春 |
| 1968 | 2023-11-09 | 10021265610 | 东北 | 男 | 58 | 床品件套 | 6750.0 | 5650 | 7 | 39550 | -5950 | 黑龙江 | 伊春 |
| 1969 | 2023-11-09 | 10021266600 | 东北 | 男 | 58 | 汽车配件 | 11900.0 | 15070 | 2 | 30140 | 8140 | 黑龙江 | 伊春 |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 5612 | 2023-11-12 | 10021436168 | 华东 | 女 | 32 | 床品件套 | 19100.0 | 18530 | 12 | 222360 | 2160 | 浙江省 | 台州 |
| 5613 | 2023-11-12 | 10021409281 | 华北 | 女 | 62 | 汽车配件 | 11850.0 | 11690 | 6 | 70140 | 28140 | 北京市 | 北京市 |
| 5614 | 2023-11-12 | 10021686373 | 华北 | 女 | 43 | 汽车配件 | 18200.0 | 10320 | 8 | 82560 | 21360 | 天津市 | 天津 |
| 5615 | 2023-11-12 | 10021372939 | 华北 | 女 | 34 | 浴室用品 | 8050.0 | 7970 | 2 | 15940 | -4260 | 北京市 | 北京市 |
| 5616 | 2023-11-12 | 10021680544 | 西北 | 女 | 48 | 床品件套 | 11350.0 | 18030 | 10 | 180300 | 68300 | 甘肃省 | 平凉 |
2006 rows × 13 columns
data = filtered_df.groupby('日期')[['销售数']].sum().reset_index()
data
| 日期 | 销售数 | |
|---|---|---|
| 0 | 2023-11-09 | 1513 |
| 1 | 2023-11-10 | 1766 |
| 2 | 2023-11-11 | 2167 |
| 3 | 2023-11-12 | 2092 |
| 4 | 2023-11-13 | 2024 |
| 5 | 2023-11-14 | 1709 |
| 6 | 2023-11-15 | 1914 |
data.columns
Index(['日期', '销售数'], dtype='object')
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt #导入matplotlib包
import matplotlib.style as psl
psl.use('ggplot')
plt.figure(figsize = (9, 6)) #设置图表画布大小
x=data['日期'].astype('str').tolist()
y=data['销售数'].tolist()
#绘制柱状图
plt.bar(x,y,width=0.5,align="center",label="金额")
plt.title("双11销售量峰值", loc="center")#设置标题
#添加数据标签
for a,b in zip(x, y):
plt.text(a,b,f'{b}',ha = "center", va = "bottom", fontsize = 10)
plt.ylabel("电商销售数")
plt.xticks(rotation=15,fontsize=9,color='k')#设置X坐标轴刻度
plt.show()

2.2销量分析
电商销售数据分析中的一个核心部分是销售分析。对于经管专业的学习者来说,深入理解和掌握销售分析的方法和技巧,对于评估电商业务绩效、指导运营策略以及推动业务增长具有至关重要的作用。销售分析涉及到对电商平台上的销售额、销售量等关键指标进行细致而系统的研究。
在进行销售分析时,经管专业的学生可以采用多种分析方法和工具,如对比分析,以全面评估销售业绩。通过对比分析,可以评估不同产品的销售差异和变化。电商销售数据分析中的销售分析是经管专业学习者不可或缺的核心技能。通过掌握销售分析的方法和技巧,深入剖析销售数据,经管专业的学生能够为电商企业提供有价值的决策支持,助力企业在竞争激烈的市场环境中实现业务的持续繁荣和发展。
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt #导入matplotlib包
import matplotlib.style as psl
psl.use('ggplot')
plt.figure(figsize = (9, 6)) #设置图表画布大小
df_sale_barh=df_sale.groupby('商品品类')['销售数'].sum().reset_index().sort_values(by='销售数')
x=df_sale_barh['商品品类'].tolist()
y=df_sale_barh['销售数'].tolist()
#绘制柱状图
plt.barh(x, width = y, height = 0.5, align = "center", label = "销售数")
#设置标题
plt.title("不同商品品类销售数", loc="center")
plt.xticks(fontsize=9,color='k')#设置X坐标轴刻度
plt.yticks(fontsize=9,color='k')#设置Y坐标轴刻度
#添加数据标签
for a,b in zip(x, y):
plt.text(b,a,b,ha = "left", va = "center", fontsize = 10)
plt.xlabel("销售数",labelpad=10,fontsize=9,color='k')#设置X轴距离,labelpad控制标题到图表的距离
plt.ylabel("商品品类",labelpad=10,fontsize=9,color='k')#设置x和y轴的名称
plt.show()

2.3利润分析
电商销售数据分析中的利润分析是经管专业学习者必须掌握的关键内容之一。对于电商企业而言,利润是衡量经营绩效和财务健康状况的重要指标。因此,经管专业的学生需要深入了解和应用于电商环境中的利润分析方法。利润分析涉及到对电商平台的收入、成本、费用等方面进行综合考量。通过对利润数据的细致分析,可以揭示出电商平台的盈利能力、成本控制效果以及经营效率等方面的情况。
在进行利润分析时,经管专业的学生需要结合电商平台的特点和运营模式,对利润数据进行多维度的剖析。可以分析不同区域的利润,找出高利润和低利润的区域,并进一步研究其原因,从而为各区域定制不同的策略来调整利润情况。通过深入研究和理解利润数据,学生能够为电商企业提供有关盈利能力评估和经营决策的建议。这将有助于企业在激烈的市场竞争中保持稳健的财务状况,实现可持续发展和长期盈利。
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt #导入matplotlib包
import matplotlib.style as psl
import seaborn as sns
psl.use('ggplot')
plt.figure(figsize = (9, 6)) #设置图表画布大小
plt.title('电商销售利润箱线图')
x=df_sale['利润']#指定绘制箱线图的数据
sns.boxplot(x=df_sale['区域'],y=df_sale['利润'],data=df_sale)
plt.xticks(fontsize=9,color='k')#设置X坐标轴刻度
plt.yticks(fontsize=9,color='k')#设置Y坐标轴刻度
plt.xlabel("区域",labelpad=10,fontsize=10,color='k')#设置X轴距离,labelpad控制标题到图表的距离
plt.ylabel("利润",labelpad=10,fontsize=10,color='k')#设置x和y轴的名称
Text(0, 0.5, '利润')

2.4成本分析
电商销售数据分析中也涉及到成本分析,这对于经管专业的学习者来说,是理解电商业务运营全貌的重要一环。在电商运营中,成本是一个不可忽视的因素。对于电商平台来说,成本涉及到商品进货价格与实际售价的关系。成本分析的核心在于对电商平台的各项成本进行详细的核算和分析。
通过成本分析,经管专业的学生可以深入了解电商平台的成本结构。在实际操作中,经管专业的学生应充分利用电商平台提供的数据工具和报表,提取和分析相关成本数据。通过成本分析,才能够更全面地评估电商平台的运营状况,为优化成本结构、提高经营效率、增强竞争力提供有力支持,推动企业的可持续发展。
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt #导入matplotlib包
import matplotlib.style as psl
psl.use('ggplot')
plt.figure(figsize = (9, 6)) #设置图表画布大小
df_sale_stack=df_sale.groupby('日期')[['进货价格','实际售价']].sum().reset_index()
x=df_sale_stack['日期'].astype('str').tolist()
y1=df_sale_stack['进货价格'].tolist()
y2=df_sale_stack['实际售价'].tolist()
#绘制面积图
plt.stackplot(x, y1, y2, labels = ["进货价格","实际售价"] )
#设置标题
plt.title("双十一进货价格与实际售价对比面积图",loc ="center")
#设置x和y轴的名称
plt.xlabel("日期")
plt.ylabel("价格")
#设置X坐标轴刻度
plt.xticks(x, ['{}日'.format(i+1) for i in range(30)],rotation=45,fontsize=9,color='k')#设置X坐标轴刻度
plt.yticks(fontsize=9,color='k')#设置Y坐标轴刻度
#设置图例
plt.legend(loc = "upper right",frameon=False,fontsize=9)
plt.xlabel("日期",labelpad=10,fontsize=10,color='k')#设置X轴距离,labelpad控制标题到图表的距离
plt.ylabel("价格",labelpad=10,fontsize=10,color='k')#设置x和y轴的名称
#图像展示
plt.show()

2.5销售额分析
电商销售数据分析中的销售额分析是经管专业学习者的核心关注点之一。对于电商平台来说,销售额是衡量业绩和成长性的关键指标,因此,对销售额进行深入分析具有至关重要的意义。对于经管专业的学生而言,掌握销售额分析的方法与技巧,能够帮助他们更好地了解电商平台的销售表现。
通过销售额的趋势分析,经管专业的学生可以观察销售额与销售数的关系,为电商平台制定销售计划和策略提供依据。通过销售额分析,经管专业的学习者能够更准确地把握电商平台的销售情况和市场动态,为企业的市场定位、目标设定和策略制定提供重要依据。这将有助于他们在电商领域中展现出色的分析和决策能力,推动业务的增长和成功。
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt #导入matplotlib包
import matplotlib.style as psl
psl.use('ggplot')
plt.figure(figsize = (9, 6)) #设置图表画布大小
#导入数据
df_sale_scatter=df_sale.groupby('日期')[['销售数','销售额']].sum().reset_index()
#设置数据系列
x=df_sale_scatter['销售数']
y=df_sale_scatter['销售额']
#绘制气泡图
plt.scatter(x,y,marker="o",c=y*100,s =y/30000)
#设置标题
plt.title("双11销售数与销量额关系图",loc="center")
#添加数据标签
for a,b in zip(x,y):
plt.text(a,b,f'{b/10000:.1f}万',ha="center",va="center",fontsize=8,color="white")
#设置x和y轴名称
plt.xlabel("销售数/个")
plt.ylabel("销售额/万")
#图像展示
plt.show()

2.6品类分析
电商销售数据分析中的品类分析是一个重要且富有价值的分析维度。在电商平台上,商品品类繁多,每个品类的销售表现和市场需求都各不相同。因此,通过品类分析,经管专业的学生能够深入了解各个品类的销售情况,为电商平台的商品管理、市场策略和资源配置提供重要决策依据。
通过对比分析,比较不同品类之间的销售表现,找出优势品类和潜力品类。电商销售数据分析中的品类分析为经管专业的学习者提供了深入了解商品销售情况和市场需求的途径。掌握品类分析的方法和技巧,将有助于他们在电商领域展现出色的分析能力,为企业的发展贡献智慧和决策支持。
df_sale['日']=df_sale['日期'].dt.strftime('%d日')
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt #导入matplotlib包
import matplotlib.style as psl
import seaborn as sns
psl.use('ggplot')
plt.figure(figsize = (9, 6)) #设置图表画布大小
plt.title('电商品类销售数热力图')
# 绘制热力图
grouped_df = df_sale.pivot_table(index='商品品类', columns='日', values='销售数', aggfunc='sum')
sns.heatmap(data=grouped_df, cmap='coolwarm') #常见的颜色映射有"viridis"、"coolwarm"、"RdBu"等
#设置X坐标轴刻度
plt.xticks(rotation=45,fontsize=9,color='k')#设置X坐标轴刻度
plt.yticks(fontsize=9,color='k')#设置Y坐标轴刻度
plt.xlabel("日期",labelpad=10,fontsize=10,color='k')#设置X轴距离,labelpad控制标题到图表的距离
plt.ylabel("商品品类",labelpad=10,fontsize=10,color='k')#设置x和y轴的名称
plt.show()

3.销售分析仪表盘
销售仪表盘是一个交互式的工具,用于展示销售数据的关键指标和趋势,可以将复杂的销售数据以直观、易懂的方式展现出来,帮助销售团队更好地了解销售情况、跟踪目标、诊断问题并做出数据驱动的决策。通过仪表盘,销售团队可以直观地看到销售额、订单量、客户数量等关键指标,从而快速了解销售情况,并且,仪表盘展示了销售数据的变化趋势,帮助团队发现销售增长或下降的原因,并及时采取措施,除此之外,仪表盘提供的数据可视化有助于团队更深入地了解销售情况,从而基于数据做出更明智的决策。
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt #导入matplotlib包
import matplotlib.style as psl
import seaborn as sns
psl.use('ggplot')
plt.figure(figsize = (12, 8)) #设置图表画布大小
#折线图
plt.subplot(3,2,1)
df_sale_line=df_sale.groupby('日期')['销售数'].sum().reset_index()
x=df_sale_line['日期'].astype('str').tolist()
y=df_sale_line['销售数'].tolist()
plt.plot(x,y,color="red",linestyle= "--",linewidth=1,marker="o",markersize=5)
plt.xlabel("日期",labelpad=10,fontsize=9,color='k') #设置X轴距离,labelpad控制标题到图表的距离
plt.ylabel("电商销售数",labelpad=10,fontsize=9,color='k') #设置Y轴距离,labelpad控制标题到图表的距离
plt.title('双十一销售量数据趋势',loc = "center",fontsize=12,color='k')
plt.xticks(x, ['{}日'.format(i+1) for i in range(30)],rotation=45,fontsize=9,color='k')#设置X坐标轴刻度
plt.yticks(fontsize=9,color='k')#设置Y坐标轴刻度
plt.grid(visible = True,linestyle='dashed')#设置网格线为虚线,axis='y'可只对Y轴打开网格线
for a,b in zip(x, y):
plt.text(a,b,b,ha="center",va = "bottom",fontsize=9,color='k')
#条形图
plt.subplot(3,2,2)
df_sale_barh=df_sale.groupby('商品品类')['销售数'].sum().reset_index().sort_values(by='销售数')
x=df_sale_barh['商品品类'].tolist()
y=df_sale_barh['销售数'].tolist()
#绘制柱状图
plt.barh(x, width = y, height = 0.5, align = "center", label = "销售数")
#设置标题
plt.title("不同商品品类销售数",loc="center",fontsize=12,color='k')
plt.xticks(fontsize=9,color='k')#设置X坐标轴刻度
plt.yticks(fontsize=9,color='k')#设置Y坐标轴刻度
#添加数据标签
for a,b in zip(x, y):
plt.text(b,a,b,ha="left",va="center",fontsize=9,color='k')
plt.xlabel("销售数",labelpad=8,fontsize=9,color='k')#设置X轴距离,labelpad控制标题到图表的距离
plt.ylabel("商品品类",labelpad=8,fontsize=9,color='k')#设置x和y轴的名称
#箱线图
plt.subplot(3,2,3)
x=df_sale['利润']#指定绘制箱线图的数据
sns.boxplot(x=df_sale['区域'],y=df_sale['利润'],data=df_sale)
plt.xticks(fontsize=9,color='k')#设置X坐标轴刻度
plt.yticks(fontsize=9,color='k')#设置Y坐标轴刻度
plt.title("不同区域利润情况", loc="center",fontsize=12,color='k')#设置标题
plt.xlabel("区域",labelpad=8,fontsize=9,color='k')#设置X轴距离,labelpad控制标题到图表的距离
plt.ylabel("利润",labelpad=8,fontsize=9,color='k')#设置x和y轴的名称
#面积图
plt.subplot(3,2,4)
df_sale_stack=df_sale.groupby('日期')[['进货价格','实际售价']].sum().reset_index()
x=df_sale_stack['日期'].astype('str').tolist()
y1=df_sale_stack['进货价格'].tolist()
y2=df_sale_stack['实际售价'].tolist()
#绘制面积图
plt.stackplot(x, y1, y2, labels = ["进货价格","实际售价"] )
#设置标题
plt.title("双十一进货价格与实际售价对比面积图",loc ="center",fontsize=12,color='k')
#设置x和y轴的名称
plt.xlabel("日期")
plt.ylabel("价格")
#设置X坐标轴刻度
plt.xticks(x, ['{}日'.format(i+1) for i in range(30)],rotation=45,fontsize=9,color='k')#设置X坐标轴刻度
plt.yticks(fontsize=9,color='k')#设置Y坐标轴刻度
#设置图例
plt.legend(loc = "upper right",frameon=False,fontsize=9)
plt.xlabel("日期",labelpad=8,fontsize=9,color='k')#设置X轴距离,labelpad控制标题到图表的距离
plt.ylabel("价格",labelpad=8,fontsize=9,color='k')#设置x和y轴的名称
#气泡图
plt.subplot(3,2,5)
#导入数据
df_sale_scatter=df_sale.groupby('日期')[['销售数','销售额']].sum().reset_index()
#设置数据系列
x=df_sale_scatter['销售数']
y=df_sale_scatter['销售额']
#绘制气泡图
plt.scatter(x,y,marker="o",c=y*100,s =y/80000)
#设置标题
plt.title("双11销售数与销量额关系图",loc="center",fontsize=12,color='k')
#添加数据标签
for a,b in zip(x,y):
plt.text(a,b,f'{b/10000:.1f}万',ha="center",va="center",fontsize=8,color="white")
#设置x和y轴名称
plt.xlabel("销售数/个",labelpad=8,fontsize=9,color='k')
plt.ylabel("销售额/万",labelpad=8,fontsize=9,color='k')
# 热力图
plt.subplot(3,2,6)
grouped_df = df_sale.pivot_table(index='商品品类', columns='日', values='销售数', aggfunc='sum')
sns.heatmap(data=grouped_df, cmap='coolwarm') #常见的颜色映射有"viridis"、"coolwarm"、"RdBu"等
#设置X坐标轴刻度
plt.xticks(rotation=45,fontsize=9,color='k')#设置X坐标轴刻度
plt.yticks(fontsize=9,color='k')#设置Y坐标轴刻度
plt.title("各品类商品热力图", loc="center",fontsize=12,color='k')#设置标题
plt.xlabel("日期",labelpad=8,fontsize=9,color='k')#设置X轴距离,labelpad控制标题到图表的距离
plt.ylabel("商品品类",labelpad=8,fontsize=9,color='k')#设置x和y轴的名称
plt.suptitle("销售仪表盘",fontsize=16,color='k')
plt.subplots_adjust(wspace=0.25,hspace=0.7) #wspace:子图之间的宽度间隔,hspace:子图之间的高度间隔。
plt.show()
#plt.savefig('my_figure2.jpg')

三、闯关题
STEP1: 按照要求计算下方题目结果
⛳️闯关题目:区域利润差异与异常值分析
假如你是一家大型公司的数据分析师,公司最近在多个区域开展了业务。为了评估各区域的盈利状况,你决定使用matplotlib制作箱线图来分析各区域的利润数据,并进一步研究利润差异最大的区域。同时,你也需要筛选出异常数据,并分析这部分数据的异常特征,是哪些订单数据影响了整理的利润数据。
💡题目提示:
- 使用matplotlib为各区域的利润数据制作箱线图。
- 根据箱线图,判断哪个区域的利润差异最大。
- 筛选出利润数据中的异常值。
- 分析异常值的特征,找出利润异常的那几个订单数据。
📚IQR判断异常值指标解释
当使用IQR(四分位距)来判断异常值时,主要涉及以下几个指标:
- 第一四分位数 (Q1):也叫做下四分位数,表示数据集中25%的数据小于或等于该值,75%的数据大于或等于该值。
- 第三四分位数 (Q3):也叫做上四分位数,表示数据集中75%的数据小于或等于该值,25%的数据大于或等于该值。
- 四分位距 (IQR):是第三四分位数与第一四分位数的差值,即IQR = Q3 - Q1。IQR是衡量数据分布散度的一个统计量,用于描述中间50%数据的离散程度。
在判断异常值时,通常使用以下公式,小于下界或大于上界的值被视为异常值。
- 下界 = Q1 - 1.5 * IQR
- 上界 = Q3 + 1.5 * IQR
#导入电商销售数据
import pandas as pd
df_sale=pd.read_excel(r'./data/EM4_电商销售数据.xlsx',#指定文件路径
dtype={'订单号':str},#指定列的数据类型
parse_dates=['日期']#解析为日期列
)
df_sale.head()
| 日期 | 订单号 | 区域 | 客户性别 | 客户年龄 | 商品品类 | 进货价格 | 实际售价 | 销售数 | 销售额 | 利润 | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 2023-11-01 | 10021404488 | 华东-上海市-上海 | 女 | 22 | 床品件套 | ¥4150 | 7090 | 11 | 77990 | 32340 |
| 1 | 2023-11-01 | 10021344597 | 华北-山西省-忻州 | 女 | 59 | 厨房电器 | ¥14000 | 17220 | 6 | 103320 | 19320 |
| 2 | 2023-11-01 | 10021531018 | 东北-辽宁省-辽阳 | 女 | 24 | 床品件套 | ¥7100 | 5680 | 3 | 17040 | -4260 |
| 3 | 2023-11-01 | 10021583928 | 东北-吉林省-松原 | 女 | 33 | 床品件套 | ¥11000 | 16170 | 2 | 32340 | 10340 |
| 4 | 2023-11-01 | 10021353159 | 西南-四川省-乐山 | 女 | 34 | 床品件套 | ¥8350 | 11180 | 10 | 111800 | 28300 |
# 下面这里写入你的代码
df_sale['大区'] = [x[0] for x in df_sale['区域'].str.split('-')]
df_sale['省份'] = [x[1] for x in df_sale['区域'].str.split('-')]
df_sale['市州'] = [x[2] for x in df_sale['区域'].str.split('-')]
df_sale.head()
| 日期 | 订单号 | 区域 | 客户性别 | 客户年龄 | 商品品类 | 进货价格 | 实际售价 | 销售数 | 销售额 | 利润 | 大区 | 省份 | 市州 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 2023-11-01 | 10021404488 | 华东-上海市-上海 | 女 | 22 | 床品件套 | ¥4150 | 7090 | 11 | 77990 | 32340 | 华东 | 上海市 | 上海 |
| 1 | 2023-11-01 | 10021344597 | 华北-山西省-忻州 | 女 | 59 | 厨房电器 | ¥14000 | 17220 | 6 | 103320 | 19320 | 华北 | 山西省 | 忻州 |
| 2 | 2023-11-01 | 10021531018 | 东北-辽宁省-辽阳 | 女 | 24 | 床品件套 | ¥7100 | 5680 | 3 | 17040 | -4260 | 东北 | 辽宁省 | 辽阳 |
| 3 | 2023-11-01 | 10021583928 | 东北-吉林省-松原 | 女 | 33 | 床品件套 | ¥11000 | 16170 | 2 | 32340 | 10340 | 东北 | 吉林省 | 松原 |
| 4 | 2023-11-01 | 10021353159 | 西南-四川省-乐山 | 女 | 34 | 床品件套 | ¥8350 | 11180 | 10 | 111800 | 28300 | 西南 | 四川省 | 乐山 |
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt #导入matplotlib包
import matplotlib.style as psl
import seaborn as sns
psl.use('ggplot')
plt.figure(figsize = (9, 6)) #设置图表画布大小
plt.title('电商销售利润箱线图')
x=df_sale['利润']#指定绘制箱线图的数据
sns.boxplot(x=df_sale['大区'],y=df_sale['利润'],data=df_sale)
plt.xticks(fontsize=9,color='k')#设置X坐标轴刻度
plt.yticks(fontsize=9,color='k')#设置Y坐标轴刻度
plt.xlabel("大区",labelpad=10,fontsize=10,color='k')#设置X轴距离,labelpad控制标题到图表的距离
plt.ylabel("利润",labelpad=10,fontsize=10,color='k')#设置x和y轴的名称
plt.show()#展示图像

q1:各区域的利润数据分组统计后,根据各区域的箱线图判断哪个区域的利润差异最大?选择正确的选项,并把选项赋值给a1。
- A:华东
- B:华北
- C:东北
- D:西南
- E:华南
- F:西北
#各区域的利润数据分组统计后,判断哪个区域的利润差异最大
a1='C' #在=后填入哪个区域的利润差异最大。可选项:A:'华东'、B:'华北'、C:'东北'、D:'西南'、E:'华南'、F:'西北'
a1
'C'
q2:计算IQR值,判断东北区域中导致销售利润异常差异最严重的那两个订单号,选择正确的选项,并把选项赋值给a2,此题为多选题,订单号选项为A:10021632781、B:10021440305、C:10021440304。
- AB
- AC
- BC
import pandas as pd
import matplotlib.pyplot as plt
import matplotlib.style as psl
psl.use('ggplot')
plt.title('东北区域电商销售利润箱线图')
#筛选区域为东北的数据
df_select=df_sale[df_sale['大区']=='东北']
x=df_select['利润']#指定绘制箱线图的数据
plt.boxplot(x,#指定绘制箱线图的数据
whis=1.5, #指定1.5倍的四分位数差
widths=0.1, #指定箱线图中箱子的宽度为0.3
showmeans=True, #显示均值
#patch_artist=True, #填充箱子的颜色
#boxprops={'facecolor':'RoyalBlue'}, #指定箱子的填充色为宝蓝色
flierprops={'markerfacecolor':'red','markeredgecolor':'red','markersize':3}, #指定异常值的填充色、边框色和大小
meanprops={'marker':'h','markerfacecolor':'black','markersize':8}, #指定中位数的标记符号(虚线)和颜色
medianprops={'linestyle':'--','color':'orange'}, #指定均值点的标记符号(六边形)、填充色和大小
labels=['利润']
)
plt.xticks(fontsize=9,color='k')#设置X坐标轴刻度
plt.yticks(fontsize=9,color='k')#设置Y坐标轴刻度
plt.xlabel("大区",labelpad=10,fontsize=10,color='k')#设置X轴距离,labelpad控制标题到图表的距离
plt.ylabel("利润",labelpad=10,fontsize=10,color='k')#设置x和y轴的名称
Text(0, 0.5, '利润')

# 计算IQR的值,定义异常值的上下界,根据上下界判断异常值点。
import pandas as pd
# 计算第一四分位数 (Q1)
Q1 = df_select['利润'].quantile(0.25)
# 计算第三四分位数 (Q3)
Q3 = df_select['利润'].quantile(0.75)
# 计算四分位距 (IQR)
IQR = Q3 - Q1
# 定义异常值的上下界
lower_bound = Q1 - 1.5 * IQR
upper_bound = Q3 + 1.5 * IQR
# 筛选出异常值
outliers =df_select[(df_select['利润'] < lower_bound) | (df_select['利润']> upper_bound)]
import seaborn as sns
import matplotlib.pyplot as plt
import matplotlib.style as psl
psl.use('ggplot')
sns.barplot(x="订单号",y="利润",data=outliers)
plt.xlabel("订单号",labelpad = 20) #设置X轴距离,labelpad控制标题到图表的距离
plt.ylabel("电商销售利润",labelpad = 20) #设置Y轴距离,labelpad控制标题到图表的距离
plt.title('东北区域电商销售利润异常值分析', loc = "center")
plt.xticks([])#设置X坐标轴刻度
plt.show()

#使用布尔索引分别筛选出这两个异常值点的订单号。
outliers[(outliers['利润']>800000)|(outliers['利润']<-200000)][['订单号']]
| 订单号 | |
|---|---|
| 1170 | 10021632781 |
| 6772 | 10021440305 |
#计算IQR值,判断哪几个订单号导致利润数据异常?
a2='AB'#在=后填入多选项,如AB、AC、BC
a2
'AB'