ChatGPT 从 2023 年一月份爆火,到了六月份热度下降,大量的 Chat 应用昙花一现,很多人又开始讨论——大模型到底能解决什么问题?过去太多的焦点给到了 ChatGPT,让大家以为 AI = ChatGPT,而忽略了背后的 LLM。Chat 只是 LLM 应用的交互形式之一,甚至都不是最重要的交互形式。要让 LLM 解决实际问题,光靠 Chat 肯定是不行的,现在行业冷了,是个静下心来思考的好机会,这篇文章用来总结这大半年来我们用 LLM 构建复杂应用解决实际问题的思考和实践。
我对于微软 Semantic Kernel 团队的一个总结特别印象深刻:人类觉得有困难的工作,对于 LLM 同样困难。但这句话只说了一半,另外一半是:LLM 有一个人类没有的优点,不厌其烦,任劳任怨。如果你长期使用 ChatGPT,你一定会意识到它能做的事情,你通过学习,Google,问同事等手段也能做,只是你嫌烦。我们可以把 LLM 看成类似于人脑,一个可以理解意图的工具,一个可以代替脑力劳动的工具,只是这个工具可控性比较差,这也是复杂 LLM 应用要解决的核心问题。
下图是 A16Z 访谈了很多 LLM 应用团队总结的架构。复杂的 LLM 应用典型的就是原理很简单,工程很复杂的案例。我这里并不是要讲工程实践的细节,也不是教程,而是想聊聊复杂 LLM 应用的挑战和解法。
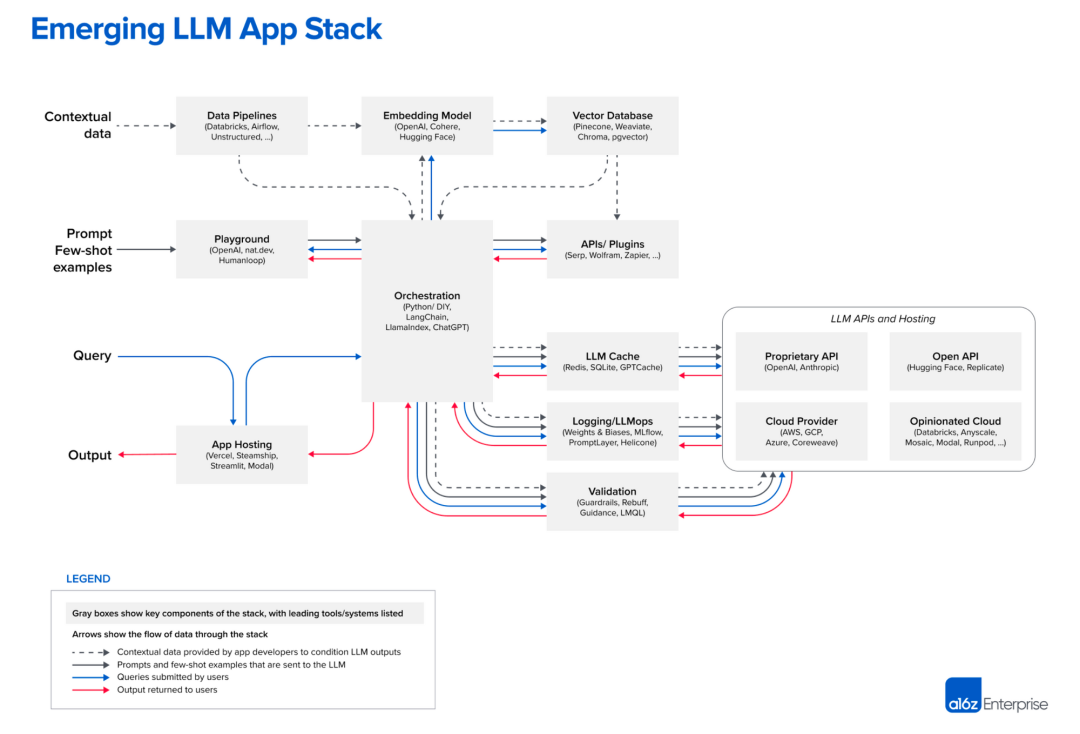
https://a16z.com/2023/06/20/emerging-architectures-for-llm-applications/
- 复杂 LLM 应用 -
ChatGPT 火爆的时候,一时间出现了无数“包皮” GPT 应用:OpenAI API + Prompt + 聊天框,但尝鲜过后基本没有留存下来的应用。特别是 ChatGPT 全面开放了 Code Interpretor 以后,简单的私有数据上下文的 Chat 应用也没有了存在的必要。
那什么样的应用不会被 ChatGPT 这样的 Killer APP 取代,具有长期价值呢?我认为这类应用必须得具有两个核心特点:隐式上下文,结构化输出。
1. 隐式上下文
类 ChatGPT 应用所有的信息都在聊天框里面,应用的开发者只需要根据 LLM 的上下文长度判断聊天框中的哪些信息需要给到 LLM 就行了,剩下的都是 LLM 的能力。但实际工作或者生活场景中,有很多信息是非文字信息,例如当前的时间,温度,天气,屏幕大小等等。举个例子:王总跟秘书说“帮我订个包厢,晚上请 xxx 吃饭”。这里包含了大量的隐含信息,例如王总的喜好,xxx 的重要程度,地理位置,当前的天气等等。ChatGPT 的 plugin 现在也可以订餐,但大概率解决不了王总的问题。这也是为啥在兴奋过后,ChatGPT 流量下降,因为很多实际问题解决不了。
那如何解决实际问题呢?我们用广大程序员熟悉的 Github Copilot 举例(我认为 Copilot 是第一个大规模商用的复杂 LLM 应用)。

要实现图中的补全效果,LLM 必须考虑这个函数的注释,函数声明,这些是显性的。但同时 LLM 还得考虑跟这个文件相关的其他文件,当前光标位置等等隐含信息。当光标位置不在当前方法内部的时候,就不应该触发补全。如果光标后面还有其他代码,那还应该考虑补全出来的代码能否跟后续代码接上。因为上下文长度有限,所以相关文件信息要优先考虑临近的 tab。我们来看一下 Github Copilot 实际怎么做的:

https://github.com/mengjian-github/copilot-analysis
可以看到为了提高预测的精准度,Copilot 给 LLM 提供了大量的“场外”信息。这些信息的来源非常多样化,可能是一些项目配置,也可能是行业常识,也可能是用户当前的环境信息。如果我们想做一个医疗或者工业制造领域的 Copilot,也会遇到类似的情况,除了明确的指令以外,Copilot 还需要收集整理大量的隐含信息给到 LLM。
隐式上下文的存在注定了复杂 LLM 应用的界面不可能只是聊天框,需要在现有工具和流程中增加埋点才可能获取这些信息。如何埋点,获取哪些信息需要大量的行业 Know How,这就导致 Copilot 无法复用,无论是信息的组织还是 Prompt 的模版都必须针对特定领域定制开发。这也是为什么我不看好通用 Agent(例如 AutoGPT) 这个方向,下文会详细讨论。
2.结构化输出
隐式上下文解决了 LLM 的输入问题,但复杂的 LLM 应用还要解决 LLM 输出的问题。如果是 Chat 应用,处理 LLM 返回信息的是人,解析能力很高,对于输出格式要求不高,例如:
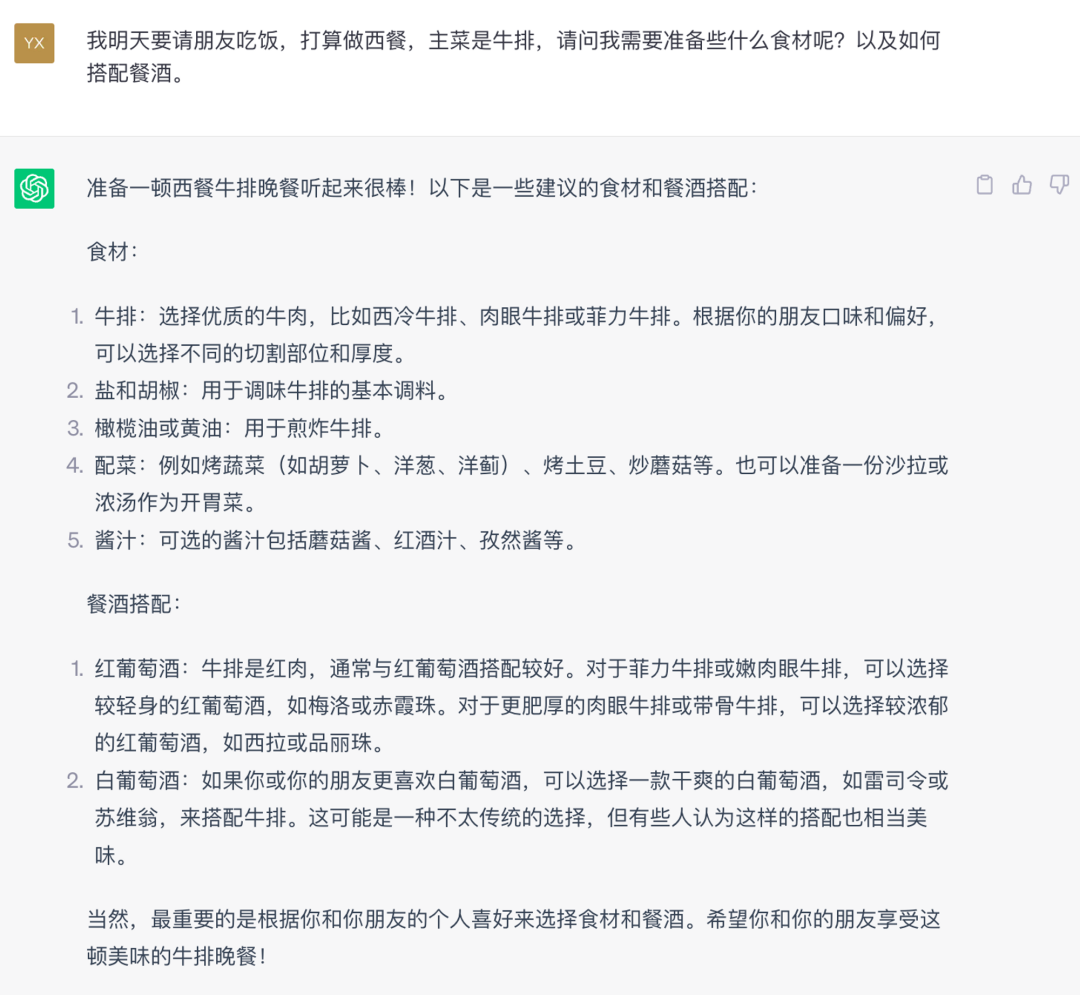
以上对话中,ChatGPT 的回答作为人类可以很容易的理解,并且可以按照它说的步骤去做。但假如我们需要构建一个自动化的买菜机器人,上述 ChatGPT 的输出却无法作为机器人的输入,因为机器人无法通过这段文字精确的知道买什么,买多少,也就无法完成后续的流程。我在《为什么大模型 LLM 不会取代软件?》这篇文章中详细讲述了 LLM 跟传统软件的配合关系,但这里有个前提就是 LLM 得输出结构化内容,这样传统软件才能接的上。例如上述 GitHub Copilot 的例子,LLM 输出的内容需要被 Copilot 解析以后精准的获得当前光标处的代码内容,才能在编辑器展示。如何精准的控制 LLM 的输出格式是个困难的工作,后续会详细讨论。
- LLM 三大问题 -
刚开始接触 LLM 的时候,有一种强烈的感觉就是这东西很强大,但是很不稳定,它输出什么内容基本靠命,就是玄学。这大半年跟 LLM 打交道,我总结了用 LLM 做复杂应用的三大挑战:Unpredictable Output(答非所问),Hallucination(胡说八道),Context Winows(视而不见)。

下面的三个截图,分别是这三个问题的实际案例:

原文 prompt 很长,这里截取了一部分
如图所示是答非所问,Unpredictable Output,我问的是一个写代码问题,它跟我说养宠物的十个好处。
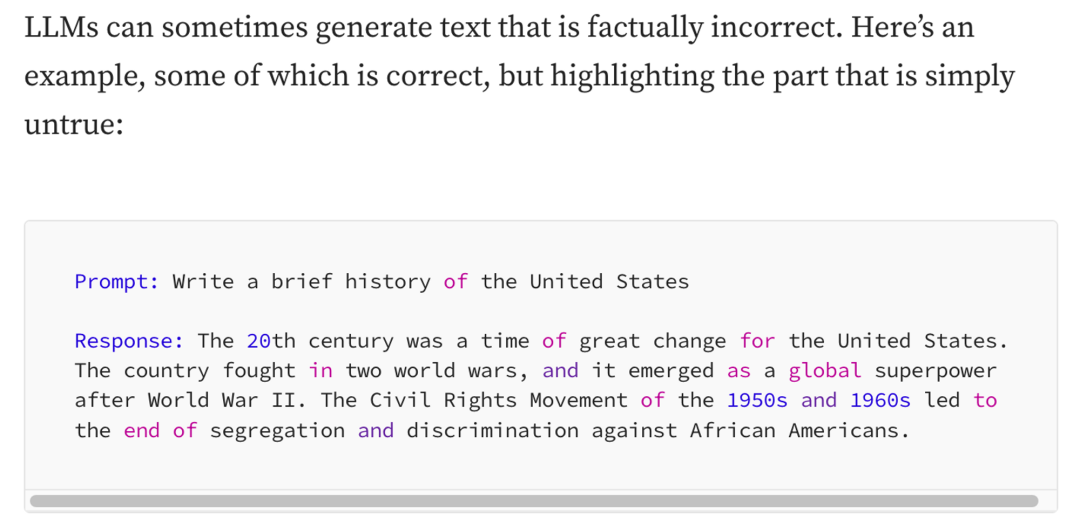 https://towardsdatascience.com/llm-hallucinations-ec831dcd7786
https://towardsdatascience.com/llm-hallucinations-ec831dcd7786
如图所示是 Hallucination,胡说八道。它的回答主题是对的,但是内容只有部分是真的,另外一部分是编造的,例如美国参加了两次世界大战。

如果你输入的信息过多,就会遇到上下文太长这个错误,即 Context Winows 视而不见。
这三个问题对于复杂的 LLM 应用都是致命的。Context 长度问题极大的限制了隐式上下文的内容,而答非所问和胡说八道的问题影响了结构化输出。但这三个问题基本上不影响聊天应用,我就不展开了。
- Prompt Engineering 咒语工程-
针对上述问题有大量的论文探讨,很多研究正在进行,大模型本身也在进化,比如 GPT-4 胡说八道的问题就减少了很多。但目前应用层在工程上解决上述问题的办法是“Prompt Engineering”,也就是提示工程,但我更乐意把它称为“咒语工程”,因为如果 LLM 是玄学,那控制玄学的就是咒语😊。
LLM 的应用理论上有两种方式,一种是 Fine Tuning,另外一种是 Prompt Engineering。就目前实际的行业发展而言,Fine Tuning 还未形成共识,并且成本巨高,实际目前的大量应用都是基于 Prompt Engineering 做的——当前世界上应用最广泛的模型 GPT-3.5/GPT-4 并不提供 Fine Tuning 的选项。我们最近(2023年7月)测了可以公开获得的国内外的各种模型,结论是只有GPT-3.5 和 GPT-4有能力支撑复杂应用,其他模型最多勉强达到 GPT-3 的水平(主要是遵循指令和多层推理能力不够,不要看各种评测报告,自己试试就知道了)。这里多说一句,我不看好在开源模型上 Fine Tuning 的努力,同样是传授武艺,你肯定要找个令狐冲教啊,而不是令狐冲的师兄们。
既然 Prompt Engineering 是目前的行业共识,自然会有大量相关工具出现,例如当红炸子鸡 Langchain,Pinecone 等等。一时间出现了太多概念,太多工具,太多教程,反而会让开发者舍本逐末。事实上搞咒语工程你唯一需要彻底理解的只有一个 OpenAI 的 API:
source:https://platform.openai.com/docs/api-reference/chat/create
曾经 OpenAI 针对不同的场景是有不同的模型和不同的 API 的,但是最近的更新 OpenAI 正在收敛这里的复杂度,几乎所有的模型都推荐用 GPT-4 替代,所有的调用方式(包括 completion,summarization,edit 等等)都统一到 chat 这一个接口。
这个 API 有两个核心概念:无状态,一切都是 Message。所谓“无状态”,就是 GPT 根本不会去记你跟他讲过什么,你的每一次请求对于 GPT 来讲都是全新的。ChatGPT 所表现出来的记忆,是因为每次请求都把过去的对话记录带上了。“一切都是 Message”的意思就是,你向 GPT 传递信息的唯一途径就是这个接口中描述的 messages,并且这个 messages 长度有限,8000 个 token 左右,差不多两万个字符。所有咒语工程所做的努力都在解决如何在这个有限的 token 长度内更有效的传递信息,所谓米上雕花。
做一个 LLM 应用的基本原理极其简单,这也是为什么我们看到那么多 Chat 应用满天飞,但是要做好一个 LLM 应用却极其复杂,这个米上雕花的工作考验工程能力。这个方面,我认为最值得参考的是微软的一篇论文,来自 Office Copilot 团队**《Natural Language Commanding via Program Synthesis》**,基本上把这篇论文理解了,你已经站在了咒语工程的前沿。实际上这个领域大家是在同一起跑线的,我看到这篇论文的时候心情无比激动,因为我发现 Office Copilot 的实践跟我们出奇的一致,至少说明我们跟世界上最牛逼的团队在这个方面差距不大。这篇论文提到的工程实践有一个核心点就是 ODSL,是 Office 团队为这个场景定制的一套 DSL,这也是控制大模型输出的主要手段,就是结构化,事实证明“大模型喜欢结构化”。
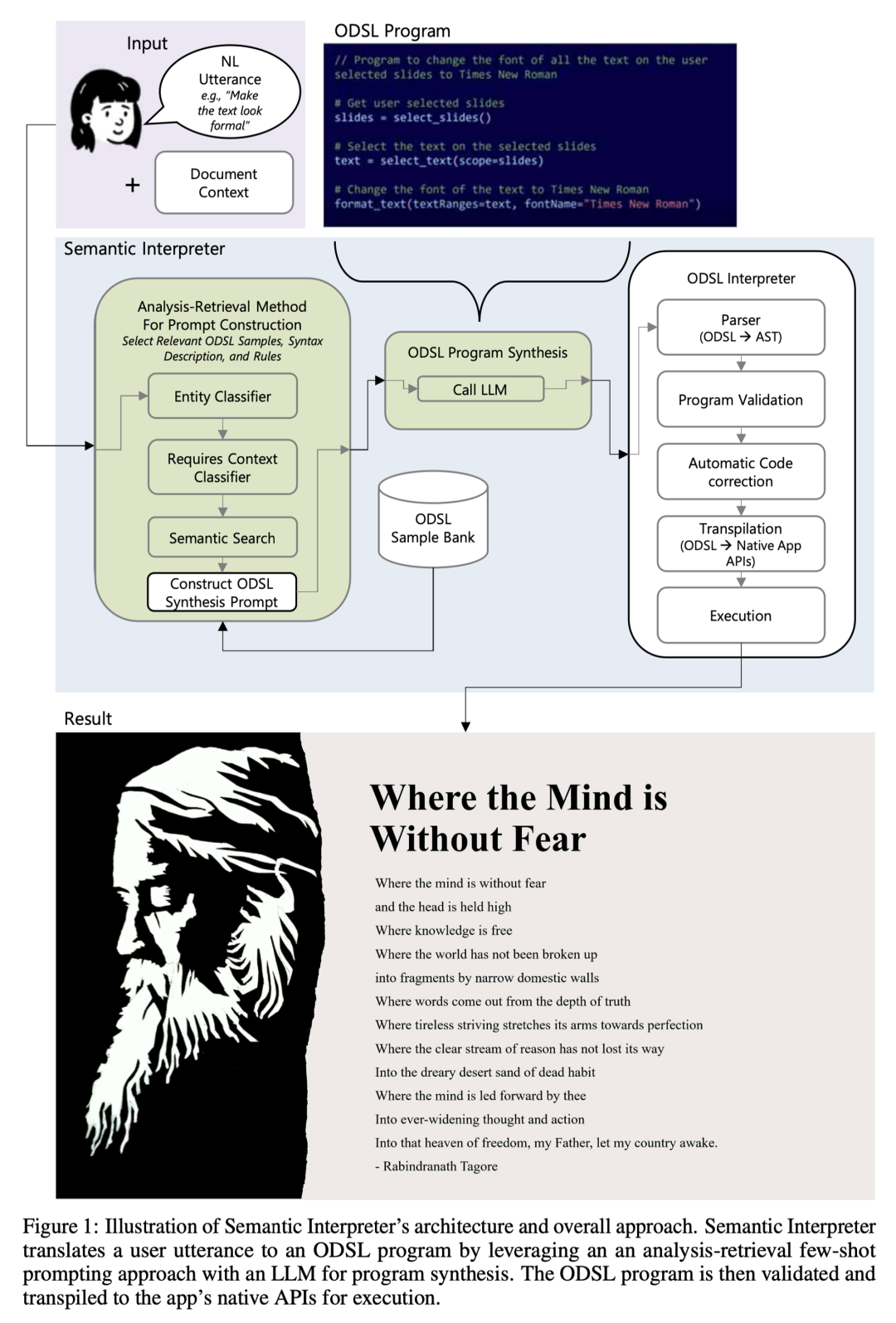
截取自上述论文,这一页解释了 Office Copilot 修改 PPT 的背后原理
这个工程实践基本上覆盖了 LLM 三大问题的解法(最简单的描述):
-
通过精雕细琢的 prompt 和 DSL 解决答非所问的问题。
-
通过程序化验证解决胡说八道的问题。
-
通过向量数据库解决上下文长度的问题。
目前咒语工程并没有统一的解法,也还没有形成类似于 Java Spring 框架这样事实上的标准,还在野蛮发展阶段,每个应用都有自己的一套(包括文章开头 A16Z 总结的那套,大家看看就行了)。我不确定这个领域最后会不会有这么一个事实上的标准,Langchain 好像在做这方面的努力,但就目前看并不成功。Langchain 在几个月前大家觉得很牛逼,但最近有很多声音质疑它的价值。就这短短的几个月时间大家的认知飞速发展,在面临实际问题的时候,你会发现 Langchain 提供的那些工具只能解决边缘小问题,只是让你少写了几行代码。类似的还有微软的 Semantic Kernel 和 Guidance。让我们静观其变。
最后聊一聊 Agent,这是我认为被过度神话的概念。大量的炫酷 Demo 让人觉得 AGI 要来了,有一种 2018 年自动驾驶暴热,说 2020 年 L5 就会普及,然而现在已经 2023 年了,L4 还不知道在哪里。Agent 也是 LLM 应用的一种,无论如何包装 LLM 应用,最终都是上文提到那个 API,都是去构造 messages。几个月前 AutoGPT 的出现,把这个概念推向了高潮。AutoGPT 在 Github 有 14 万 star,但几个月过去了你看到它解决啥问题了吗?我觉得 Agent 的理念是好的,AutoGPT 提出的实践逻辑也是好的,但是缺乏落地可行性,究其原因是 LLM 本身能力不够,米上雕花不可能造出来啥都能干的 Agent,你不能指望在功能机时代去做抖音这样的应用。但单一功能的 Agent 我认为是有机会的,类似于封闭路段的自动驾驶。AutoGPT 更像是一个实验项目,探索咒语工程的边界。或者换个角度讲,你觉得 Github Copilot 是不是一种 Agent?
就我目前的认知而言,咒语工程是值得投入的,除非大模型的能力急剧提升,并且 Fine Tuning 的成本急剧下降。就看你信不信了。
- BabelGPT -
为了使得这篇文章的内容具有可信度,为了证明我不是胡说八道,这里放一个我们的产品 Demo。我们正在开发一个新产品,期望能极大的降低开发应用的门槛。这个 Demo 是我们新产品中部分 AI 功能的演示:BabelGPT 根据用户对于应用需求的自然语言描述,全自动生成完整的软件结构以及代码,并且展示运行结果。这里演示的需求是“每隔六小时监控比特币价格,如果低于40000美元,就给我发邮件。同时我需要一个网页查看比特币价格走势图。”
BabelGPT 是基于咒语工程做的,整个过程的 workflow 是预先定义好的(准确率远高于让 GPT 去做 planning),但是流程中每个环节通过上下文切换和不同的 prompt 来让 GPT 完成不同的任务。除了视频中的场景,我们也支持单独生成/修改部分结构的代码,针对选中的代码进行重写等等。这里的细节就不展开了,下次专门写一篇文章介绍。
视频中演示的那个应用,生成一次大概需要 10 次 OpenAI GPT-4 调用,每次平均 4000 Tokens,也就是说,生成这个应用需要大约 1.5 美元,你觉得是贵还是便宜?