千等万等,终于还是等来了阿里最新开源的音频基座大模型FunAudioLLM,真不愧是AI届的活菩萨啊,不过,我心心念念的达摩院寻光AI视频创作平台到底什么时候开放啊!!
停止发疯,进入正题。。。
引言
【语音】作为人工智能的【启蒙钥匙】,不仅率先踏出实验室大门,步入寻常百姓家,也成为了人类与AI初次触电的【桥接技术】。初期,智能语音技术的研究重心落在了语音识别领域,致力于使机器具备理解人类语言的能力。
回顾历史,AT&T贝尔实验室推出的Audrey系统,作为电子计算机领域的先驱,成功辨识了10个英文数字,开启了这一征程。1988年,李开复博士突破性地构建了首个运用隐马尔可夫模型的大词汇量语音识别系统Sphinx。1997年,Dragon NaturallySpeaking的问世,标志着全球首个供消费者使用的连续语音输入系统的商业化。而至2009年,微软Windows 7操作系统内置的语音功能,进一步普及了该技术。
转折点发生在2011年,iPhone 4S携Siri登场,智能语音技术由此迈入**【互动】**新纪元。同年,谷歌内部启动了Google语音搜索的测试,预告着这一功能即将登上Google的舞台。
从单纯识别到实现互动,这一跨越为人机交互的繁盛奠定了坚实基础。时至今日,语音交互技术已渗透至智能家居、智能驾驶乃至机器人领域,在AI技术迭代的推动下愈发流畅,应用生态呈现多样化。技术层面,各大云服务提供商通过API形式对外开放其AI语音服务,极大促进了开发者基于此的创新应用开发。
近年来,随着大规模预训练模型的兴起,直接在模型层面上的开放与定制化调整日益受到瞩目。开发者能够通过模型训练与微调,深度优化模型性能,进而提升其在特定应用场景下的部署效能,为语音技术的广泛应用开辟了新的路径。
GPT-SoVITS作为一个标志性的语音合成框架,已经为行业树立了高质量语音生成的标准。它通过深度学习模型,尤其是基于WaveNet和Transformer架构的创新,实现了语音自然度和真实感的显著提升,为用户带来了接近真人的听觉体验,在上线后便获得极高热度,仅需提供 5 秒语音样本,便可收获相似度达到 80%~95% 的克隆语音。
随着技术的不断迭代与需求的日益多元化,ChatTTS作为后起之秀,在继承SoVITS等前辈优点的同时,进一步聚焦于对话场景的优化与个性化表达,能实现更加流畅、连贯及富含情感色彩的语音输出,甚至包括语气词、笑声。
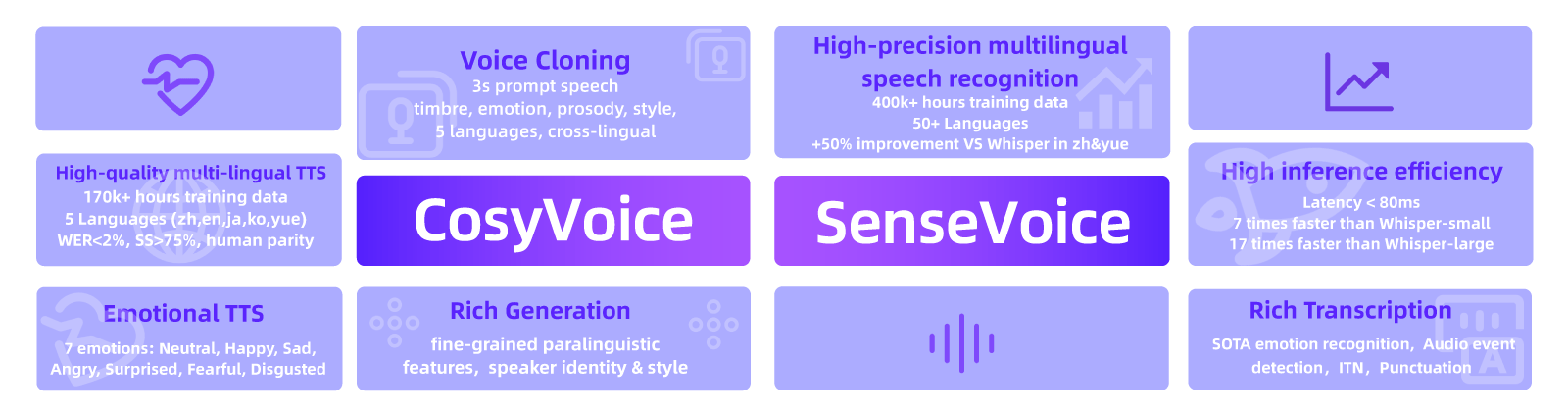
而在本月,阿里通义实验室也发布了最新的研究成果音频基座大模型FunAudioLLM,其中包括两大模型SenseVoice和CosyVoice,这一发布标志着阿里在语音技术领域取得了重大进展,并且是对现有技术如GPT-SoVITS和ChatTTS的重要补充和提升。
FunAudioLLM简介
本部分内容均为周周翻译并总结自论文,有兴趣的朋友可以直接阅读原文,地址如下:https://arxiv.org/pdf/2407.04051

如上文所述,FunAudioLLM主要包括两大模型SenseVoice和CosyVoice。其中:
SenseVoice:精准多语言识别与情感辨识。
-
多语言识别:采用超过** 30 万小时的数据训练,支持超过 50 种语言,在中文和粤语上的识别准确度提升超过 50%**。
-
情感辨识:具备出色的情感识别能力,在测试数据上达到或超过当前最佳情感识别模型的效果。
-
声音事件检测:能够识别多种情绪和交互事件,如音乐、掌声、笑声、哭声等。
-
模型架构:包括自动语音识别(ASR)、语言识别(LID)、情感识别(SER)以及音频事件检测(AED),能够适应不同应用场景。
CosyVoice:模拟音色与提升情感表现力
-
多语言合成:采用了总共超** 15 万小时**的数据训练,支持中英日粤韩 5 种语言的合成,合成效果显著优于传统语音合成模型。
-
极速音色模拟:仅需要** 3 至 10 秒的原始音频,即可生成模拟音色,包含韵律和情感等细节,甚至能够实现跨语言**的语音生成。
-
细粒度控制:支持通过富文本或自然语言形式,对生成语音的情感和韵律进行细粒度控制,大大提升了生成语音在情感表现力上的细腻程度。
-
模型架构:包含回归变换器,用于生成输入文本的语音标记;基于 ODE 的扩散模型(流匹配),用于从生成的语音标记重建梅尔频谱;以及基于 HiFTNet 的声码器,用于合成波形。
在有了基本了解之后,下面分别对其架构进行简要说明。
SenseVoice
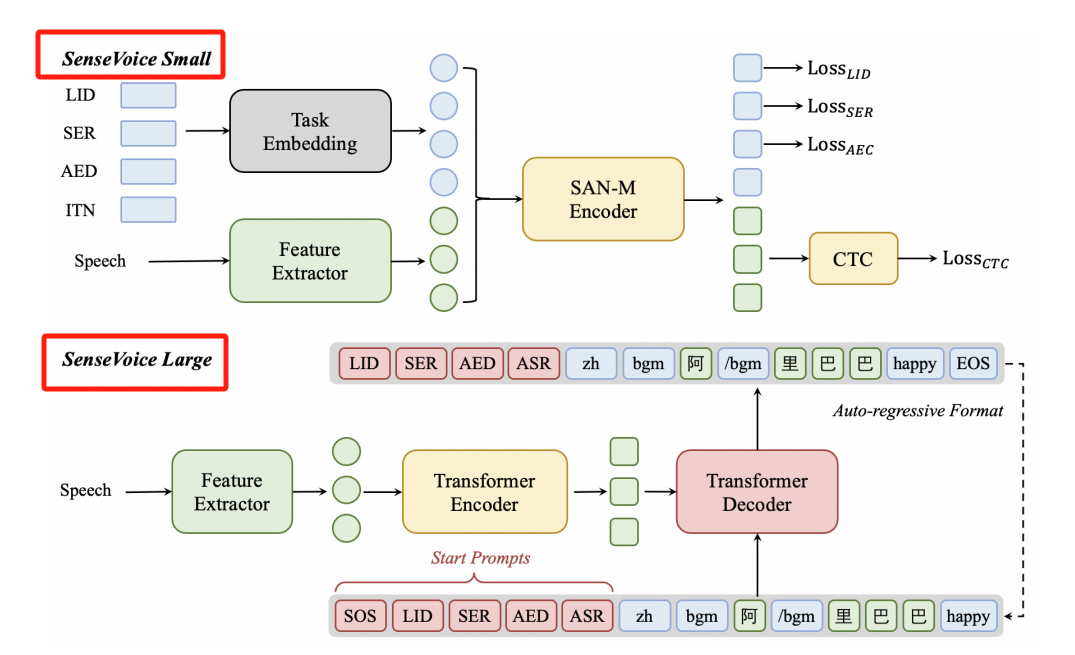
SenseVoice 是一个语音基础模型,具有多种语音理解功能,包括 ASR、LID、SER 和 AED。为了适应不同的需求,提出了两种不同规模和架构的模型SenseVoice-Small和SenseVoice-Large。
SenseVoice-Small :一个仅编码器模型,经过优化以实现快速的语音理解。它提供了高速处理能力,同时支持5种语言。
SenseVoice-Large:一个编码器-解码器模型,旨在实现更精确的跨语言范围的语音理解。它在准确性方面表现出色,并支持广泛的语言能力。
CosyVoice
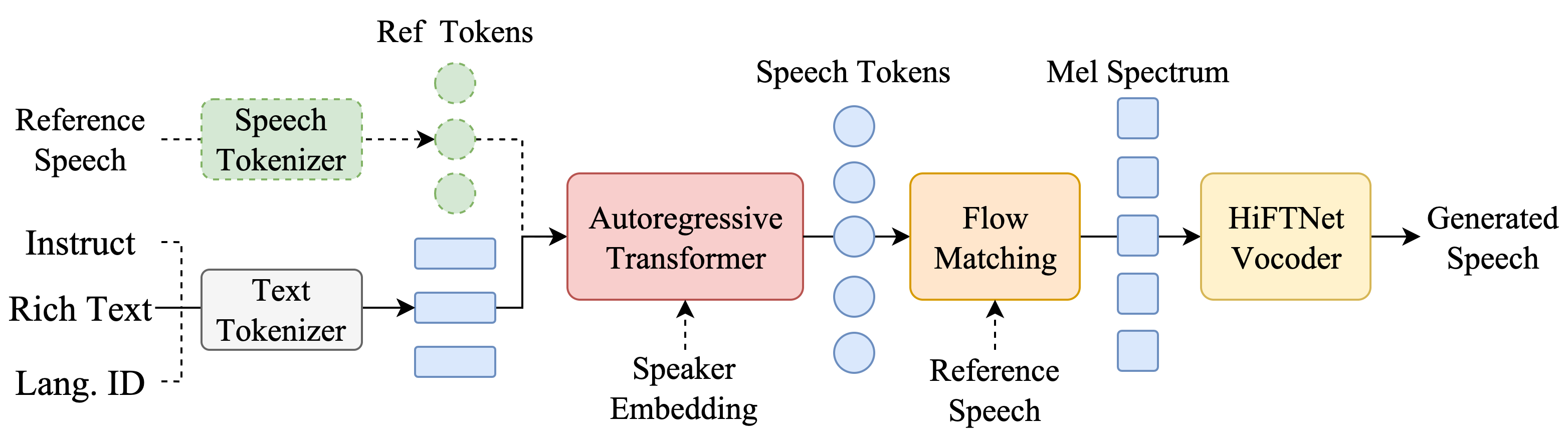
CosyVoice 由一个自回归变换器(用于为输入文本生成相应的语音标记)、一个基于 ODE 的扩散模型、流匹配(用于从生成的语音标记重建梅尔频谱)和一个基于 HiFTNet 的声码器(用于合成波形)组成。虚线模块在特定模型用途中是可选的,例如跨语言、SFT 推理等。
关于上述两块内容,在论文中也有基于底层原理的说明,但由于篇幅和专业性的限制,这里我们还是将重点放在模型的体验上,不过多赘述其底层原理了。

FunAudioLLM应用场景
语音到语音翻译(语音转译)
通过整合 SenseVoice、大型语言模型(LLMs)和 CosyVoice,我们可以轻松地执行语音到语音的翻译(S2ST)
示例地址:https://funaudiollm.github.io/

比如说一个中国男子用中文询问 “今天去哪儿吃饭?”,他的语音会被 SenseVoice 解析成文字。接着,这些文字被传送到大型语言模型进行翻译,将其转化为英文 “Where are you going to eat today?”。最后,CosyVoice 将翻译后的英文文字重新生成为美国女性的声音,完成了从中文语音到英文语音的完整翻译过程。
在上述地址中,我们也可以在线试听一些案例,包括中文转化为英、日、粤语、韩语等:
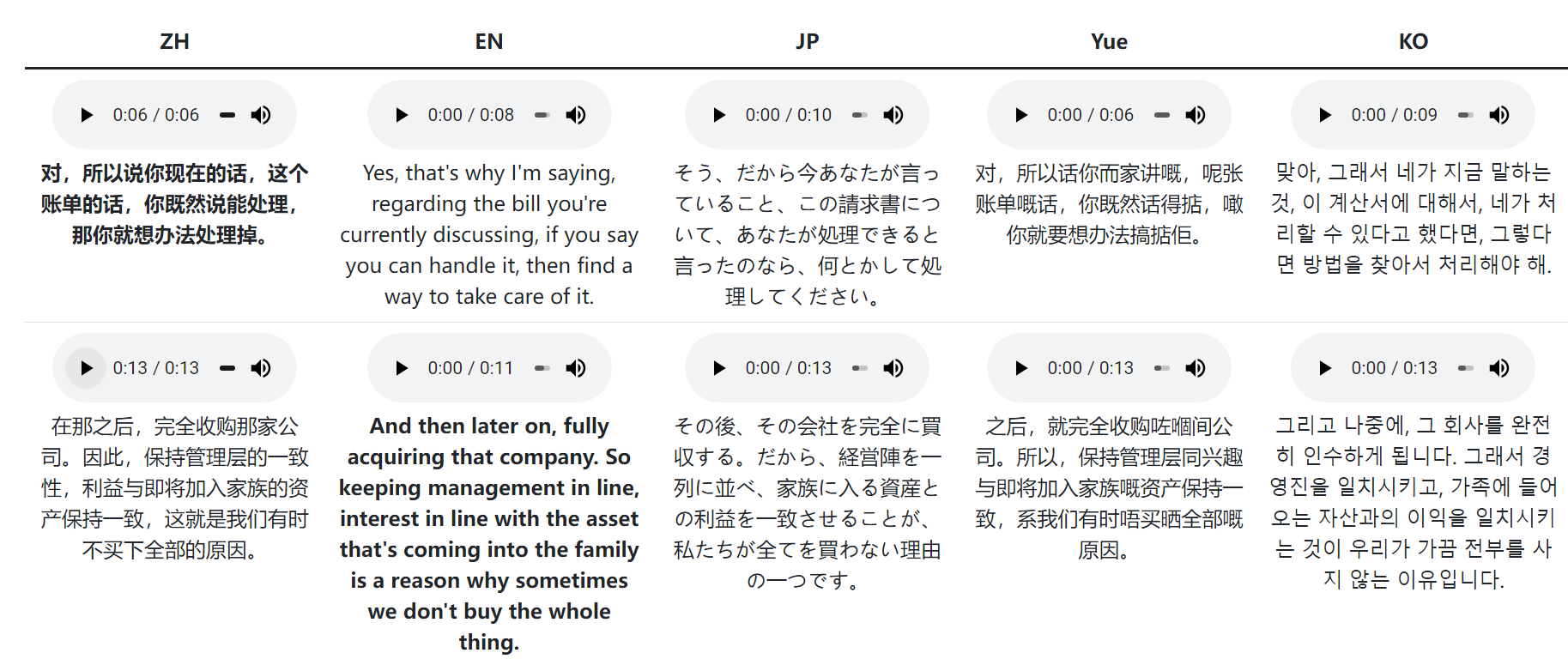
通过前后对比不难发现,FunAudioLLM生成的语音不仅在音色上保持了较高的一致性,而且在语气与表达习惯上也尽可能地做到了相近(至少在短句的情况下听起来是这样的)。
这意味着即使是跨语言转换,生成的语音也能很好地保留原说话人的特色,从而让用户感觉更加自然和真实。这种高水平的一致性和自然度对于语音转换技术来说是一个重要的里程碑,尤其是在需要高质量语音转换的应用场景中,如在线翻译等。
情感语音对话
通过整合 SenseVoice、LLMs(Large Language Models)和 CosyVoice,我们可以开发一款情感语音聊天应用。在下面的例子中,用户和助手的内容都是由 CosyVoice 合成的。
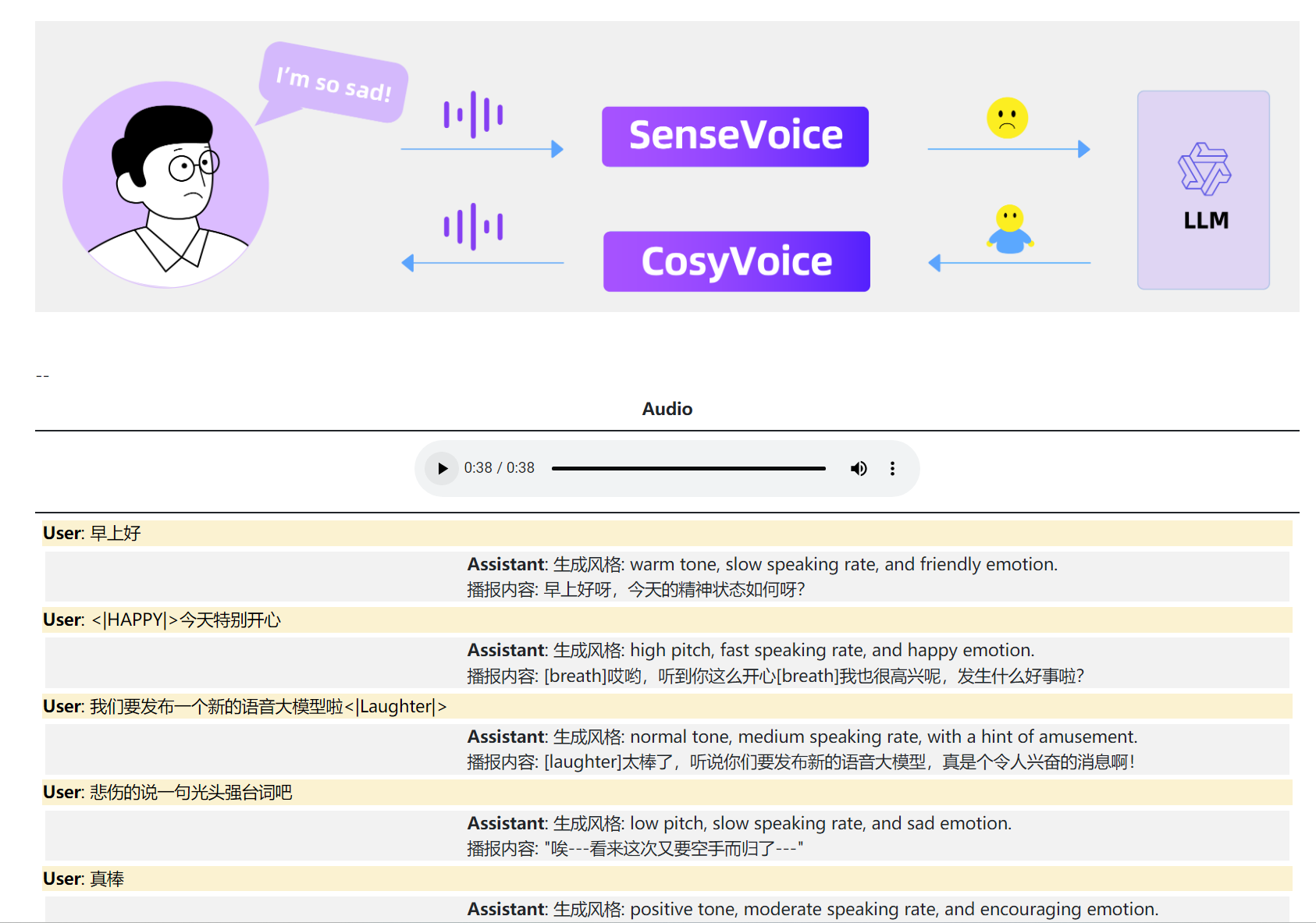
从这个案例中可以看出,FunAudioLLM生成的语音在情感表达上极其自然和真实。它不仅能够通过富文本(<|HAPPY|>、**<|Laughter|>**等)和文本语义来控制并反映所要传达的情感色彩,还能根据上下文的变化调整语调和节奏,使得合成的语音听起来更加贴近真人发声,极大地提升了用户体验和交互的真实性。
因此,以此为基础开发情感语音对话APP极具潜力,这样的应用能够在客户服务、娱乐互动甚至是心理健康支持等领域发挥重要作用。
互动播客
通过将 SenseVoice、基于 LLM 的实时知识多代理系统和 CosyVoice 整合,FunAudioLLM 可以创造一个互动式播客电台。
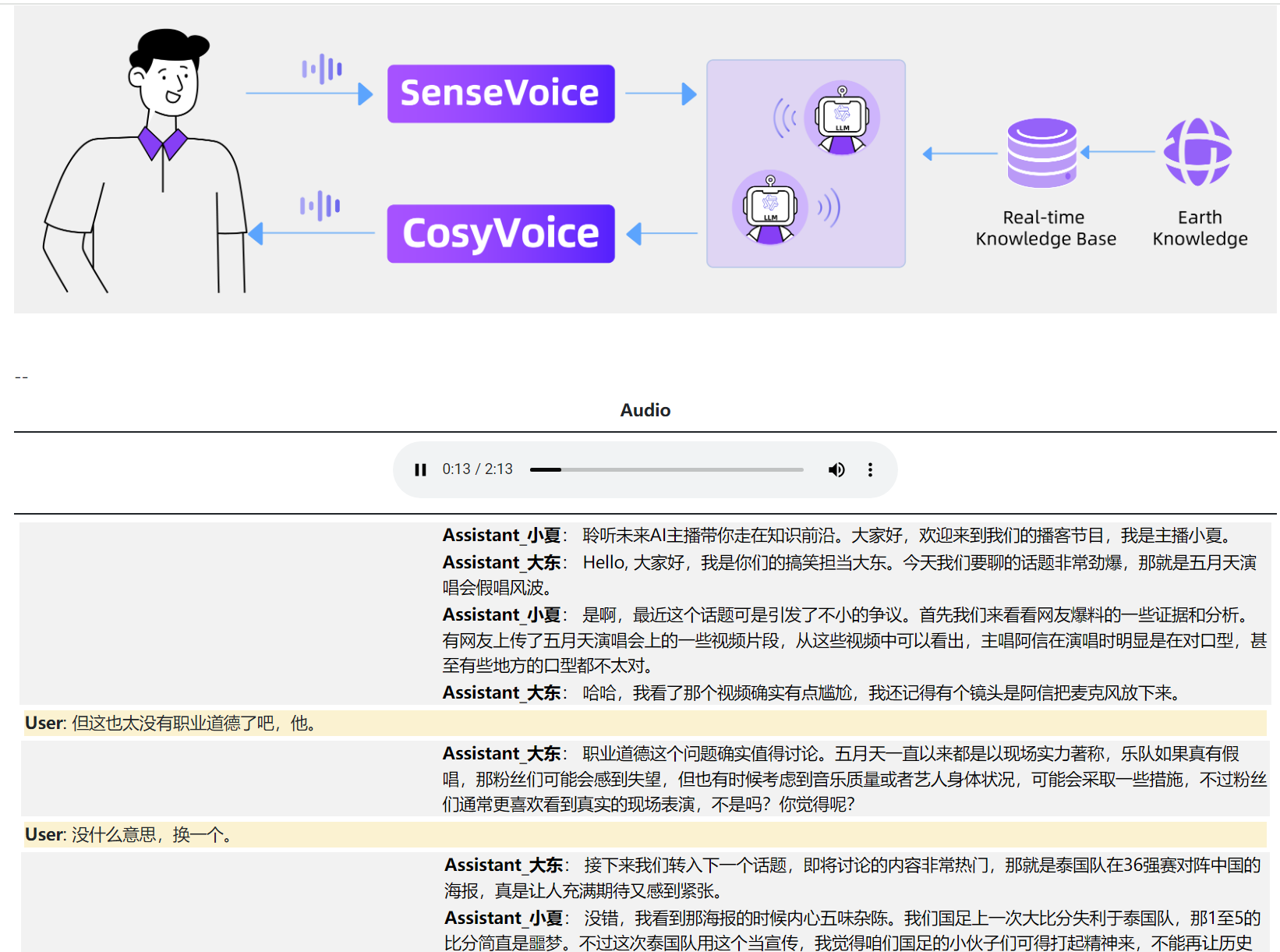
在这样的播客中,SenseVoice利用其高精度多语言语音识别功能,实时捕捉AI播客和用户的对话,甚至能够辨识环境音效和情感。
LLM多代理系统则能够处理SenseVoice提供的语音数据,实时更新知识库,确保话题和信息的及时性和准确性。
在交互中,用户可以随时打断AI播客的对话,引导主题方向等,CosyVoice将用于生成AI播客的语音,具备多种语言、音色和情感的控制能力,为听众带来丰富多彩的听觉体验。
有声读物
借助于LLM出色的分析能力,可对书籍内容进行结构化并识别其中的情感,再与CosyVoice的语音生成技术结合,能够实现具有更高表现力的有声读物。
这样的有声读物不再是单一无变化的朗读,而是一场充满情感与生动表达的听觉盛宴,让每个故事和角色都栩栩如生。

这一段我试听了一下,只能说,配音师真的快失业了。CosyVoice 不仅能够准确地模仿不同的声音特征,还能根据内容的情感需求调整语气和语调,几乎达到了与专业配音员媲美的水平。
体验FunAudioLLM
目前,我们可以通过魔搭创空间体验进行在线体验,体验地址如下:
CosyVoice多语言音频生成大模型
SenseVoice多语言音频理解大模型
体验CosyVoice
预置语音生成
进入CosyVoice后,我们先随机生成一个音频试一下,保持默认配置即可,点击生成音频。
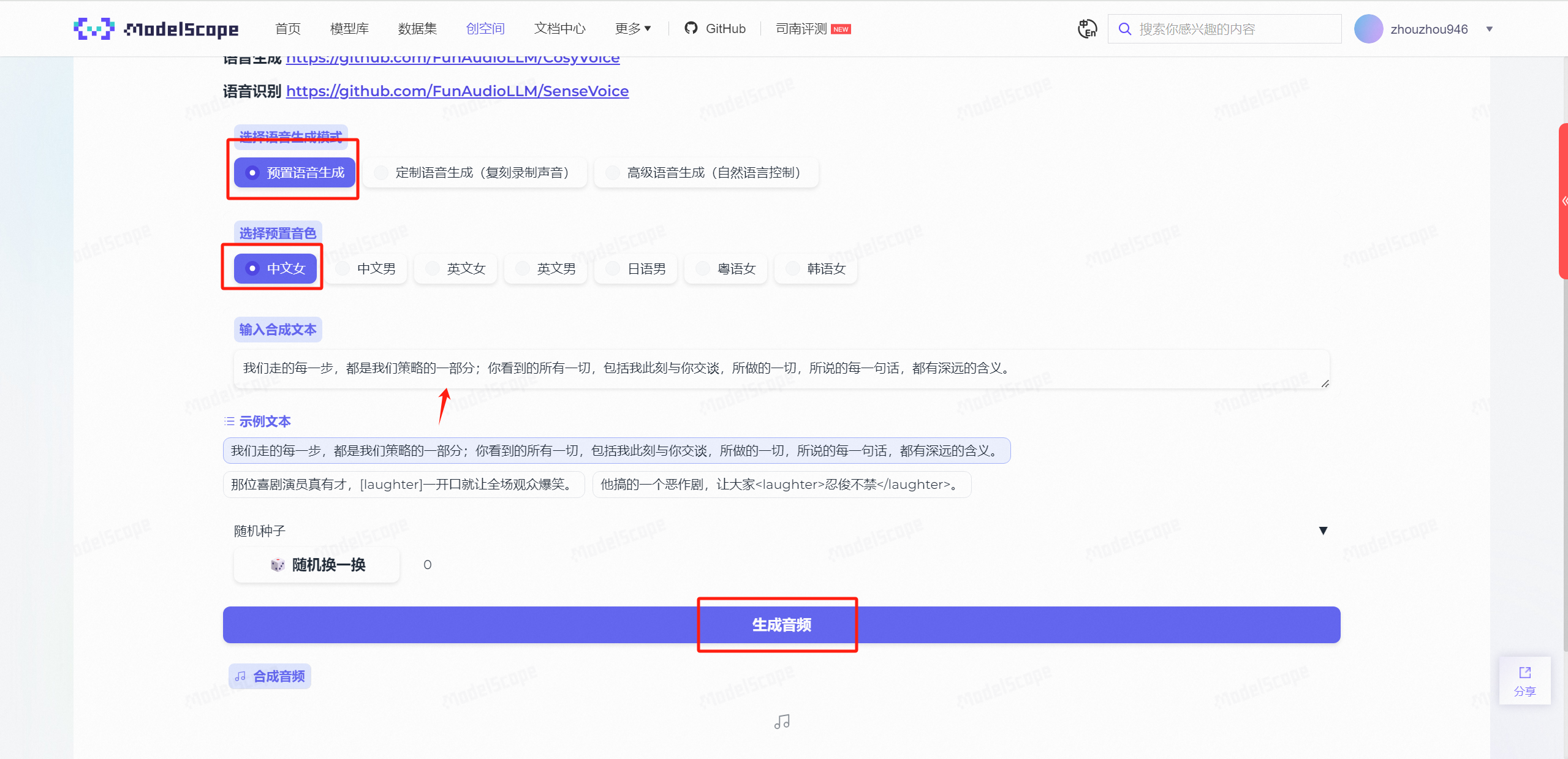
效果确实还是不错的!优点在于生成速度快(相比于ChatTTS),且语音仿真度高。
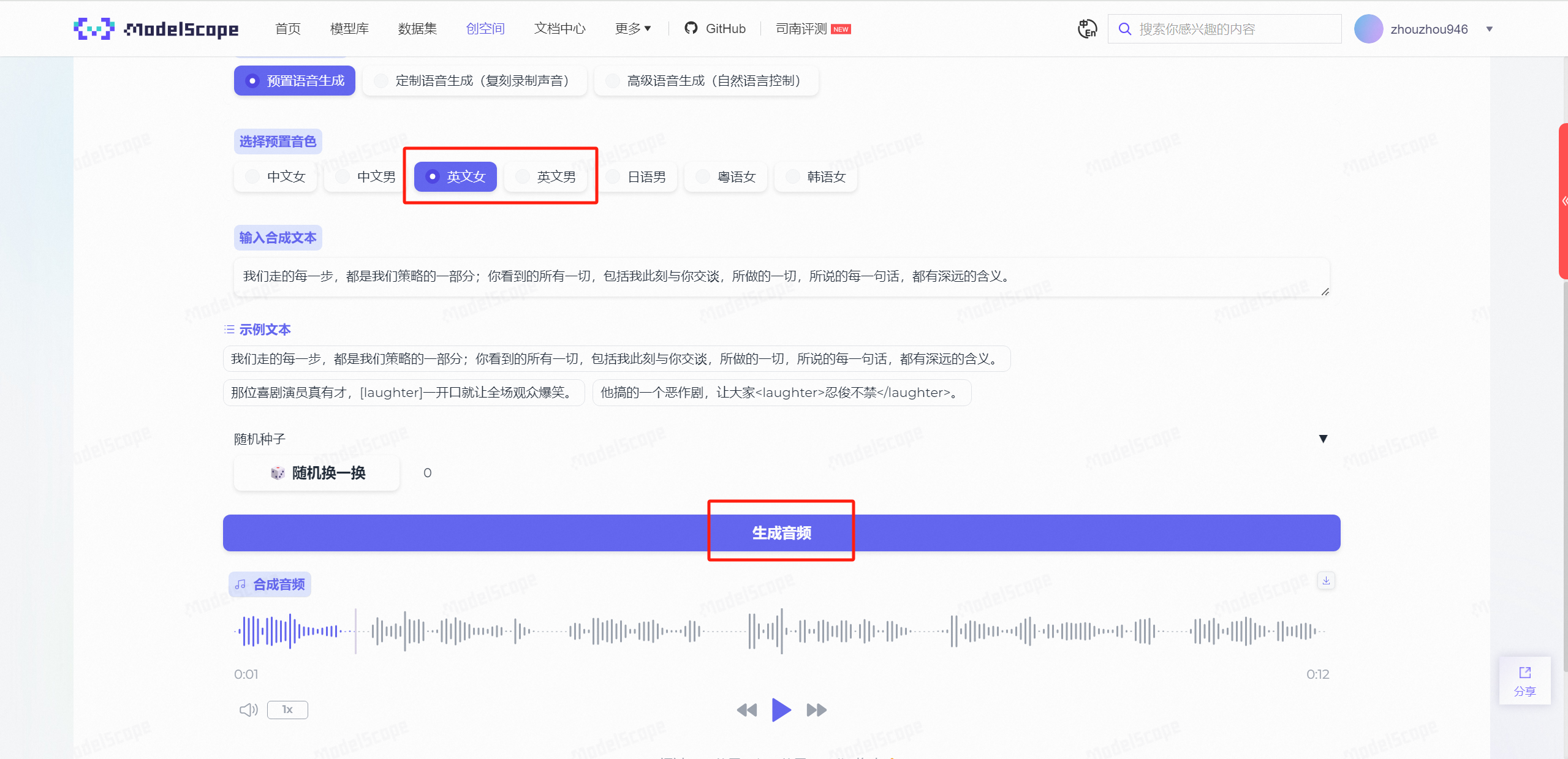
我们再尝试一下其他几个,在【英文女\男】的选择下,生成出来的音频是带有浓重外国口音的中文音频,在【日语男】【韩语女】下面同样也是如此。
同样,我们也测试一下富文本的情绪识别,选择示例文本:
那位喜剧演员真有才,[laughter]一开口就让全场观众爆笑。
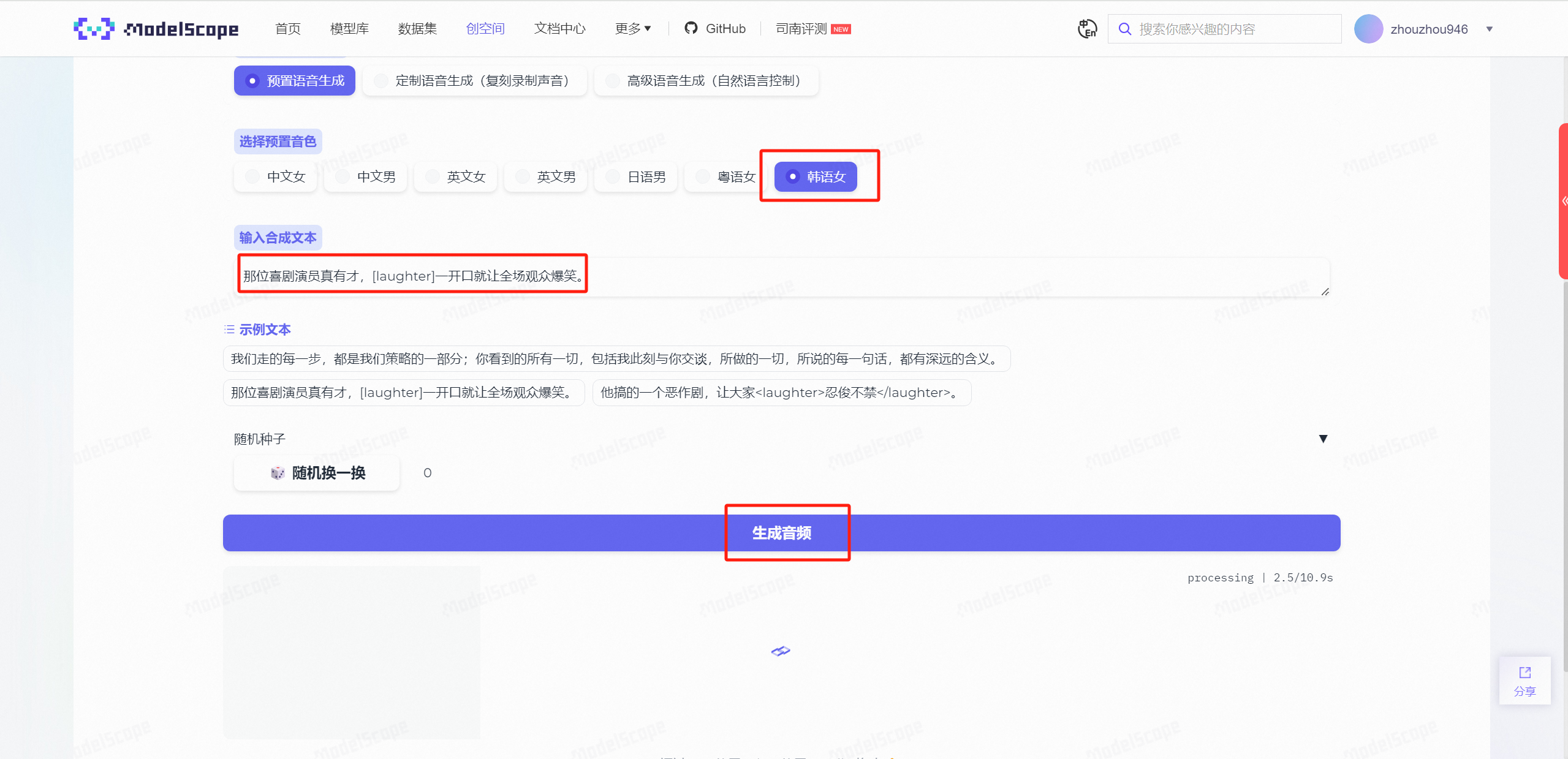
可以明显地感受出来,笑声发出的前后语音、语气衔接是非常流畅的,这种自然的过渡让整个对话听起来更加真实和连贯,几乎难以分辨是由AI合成还是真人发声。
随后,我更换了随机种子再次测试,此时生成的笑声又与之前的笑声完全不同了,但是不变的还是真实感!
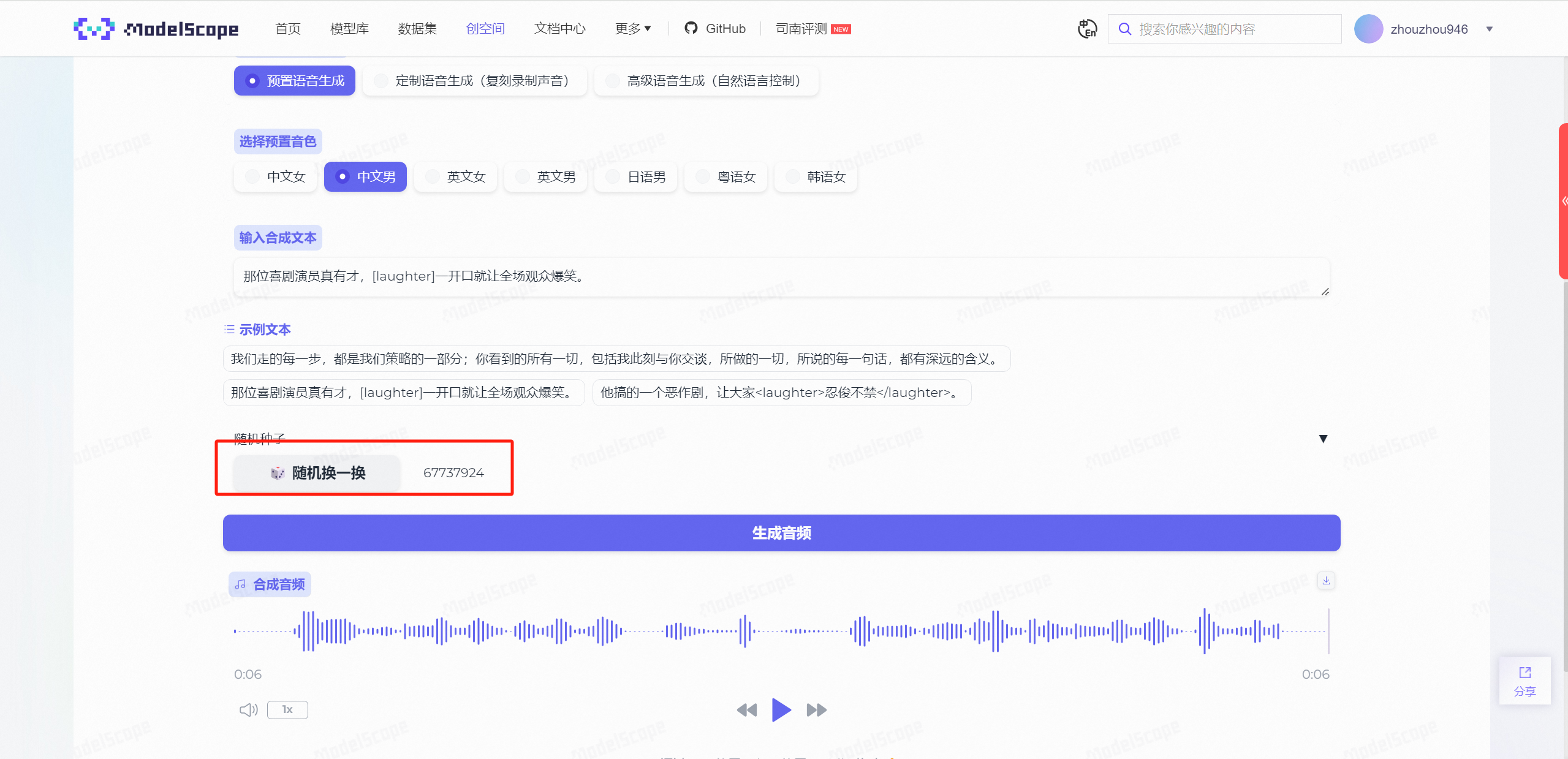
但是,如果仅仅做到这个程度,那么似乎跟ChatTTS也没有什么区别,所以下面,要开始着重介绍CosyVoice的两个特色功能:定制语音生成和高级语音生成。
定制语音生成
在我今年4月份撰写ChatTTS的测评文章时,当时是还没有集成语音克隆这个功能的,所以主要的音色克隆还是依靠GPT-SoVITS。
但是,现在的CosyVoice已经默认集成了音色克隆及特征音频生成能力了。
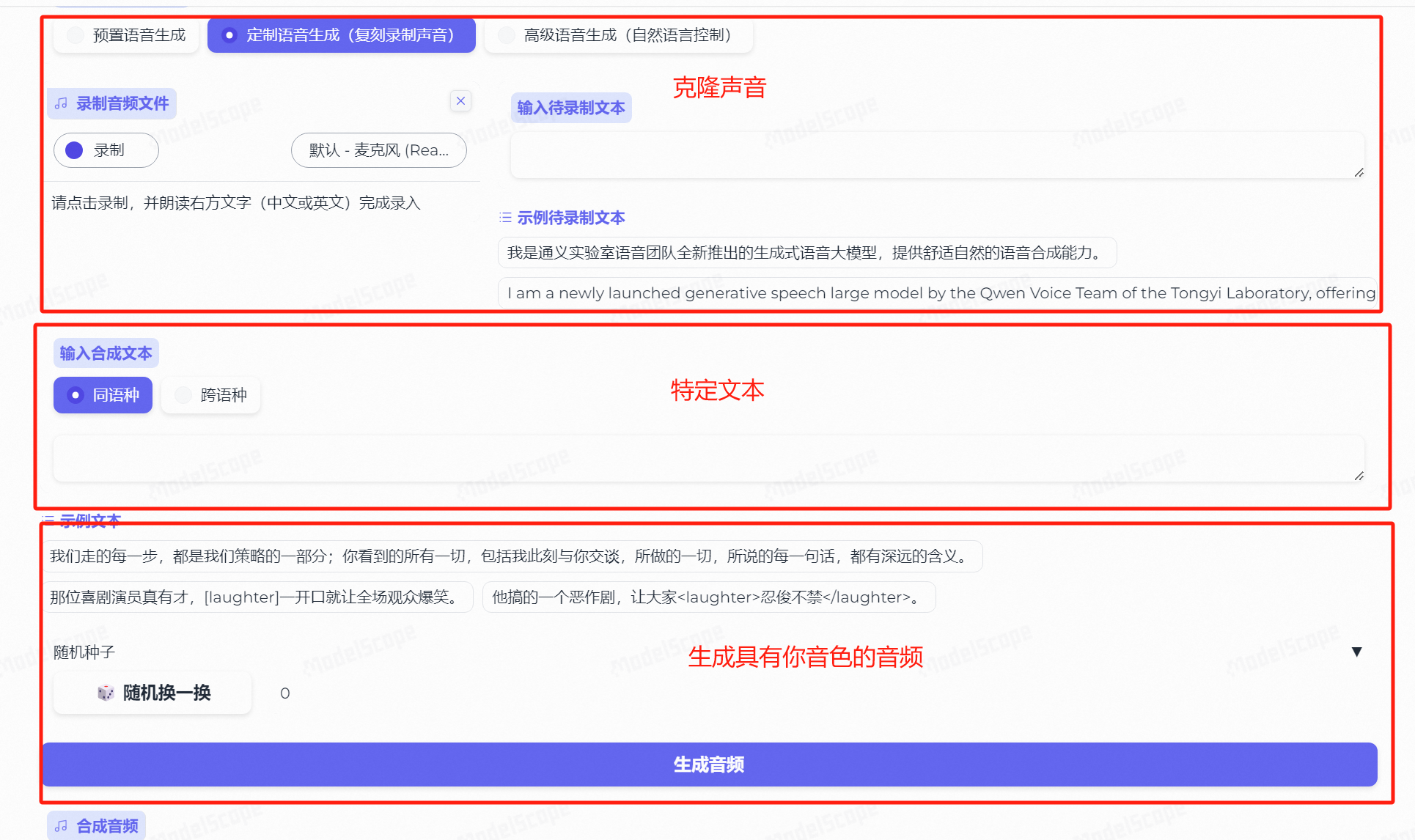
我们先点击示例待录制文本,让其选入输入待录制文本中,然后点击录制按钮:
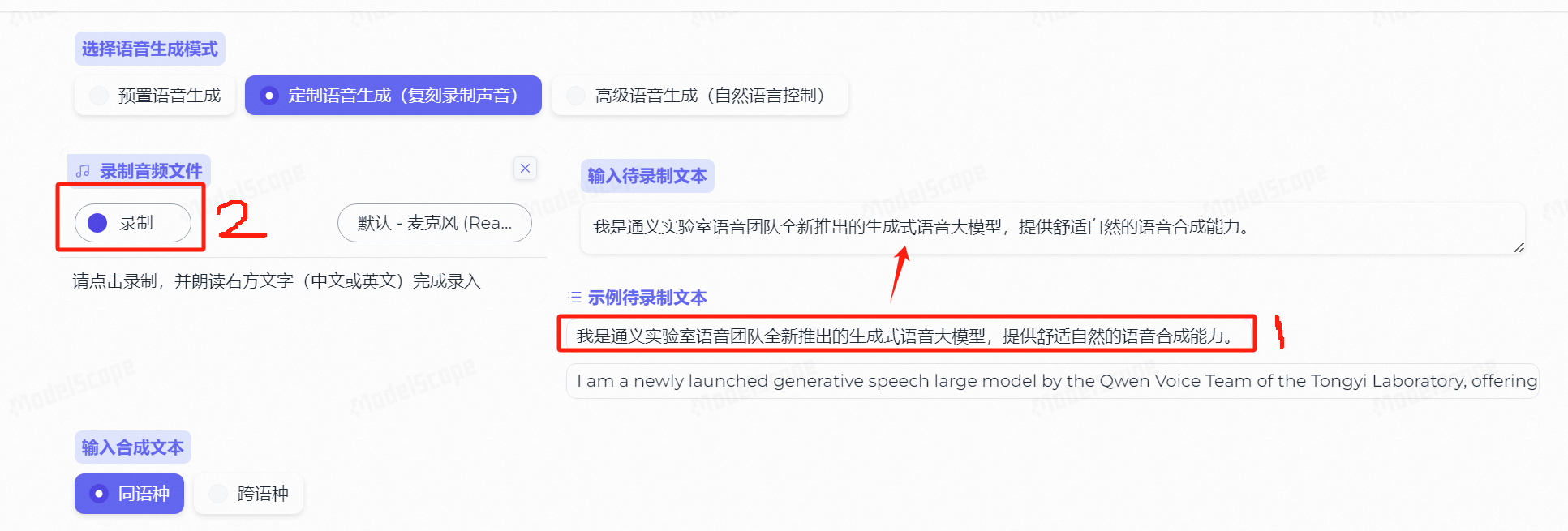
录音完毕后,点击停止按钮,此时会得到一段原声:
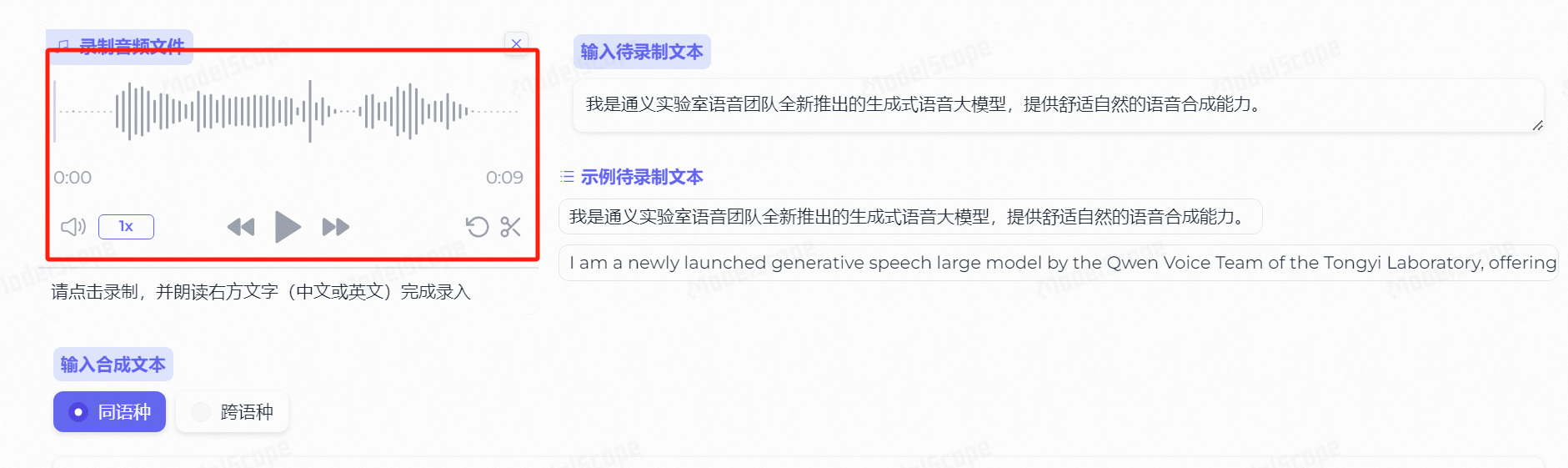
点击选择合成文本,然后直接点击生成音频:
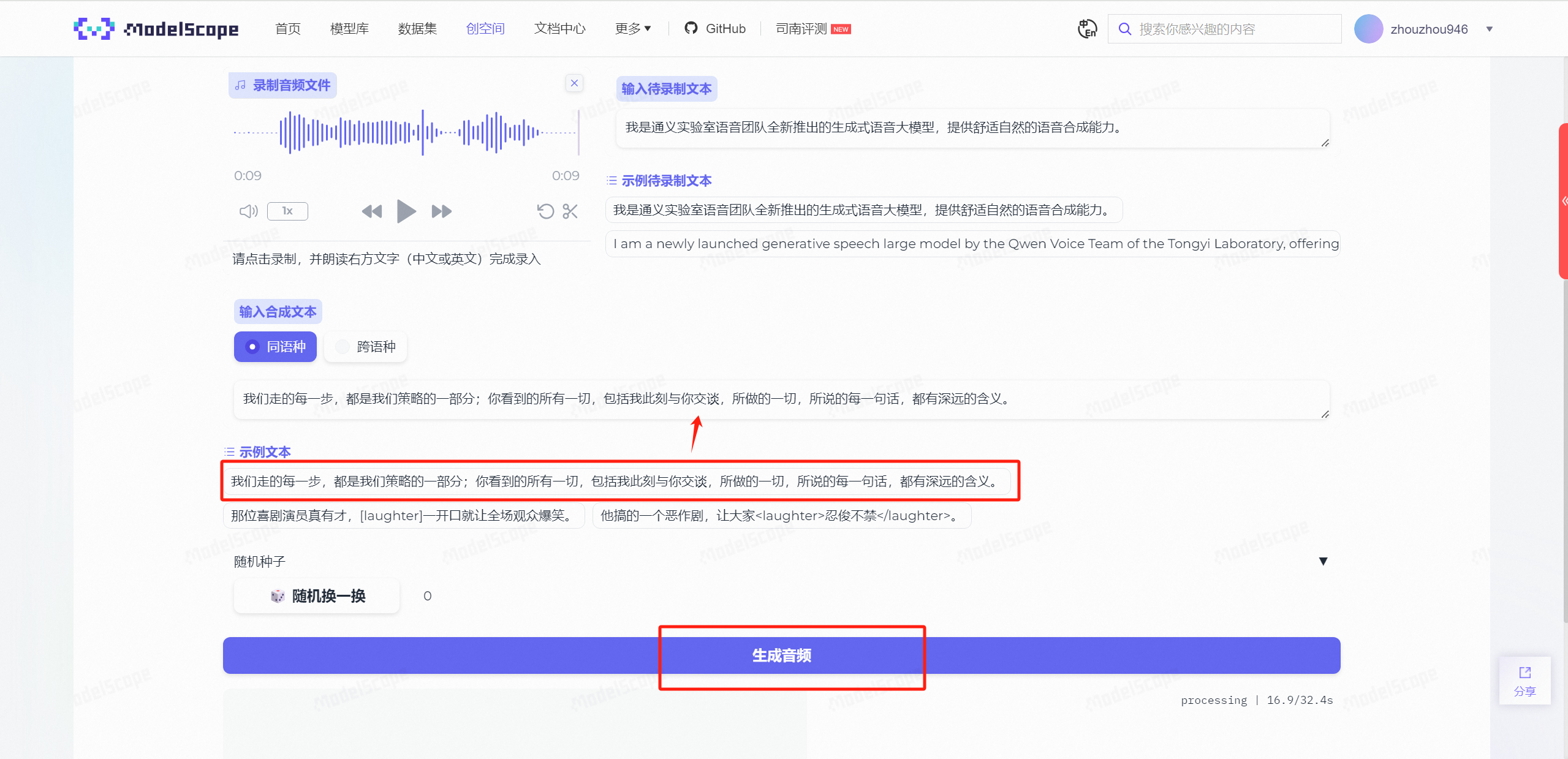
大约10s左右,会得到一段带有你音色特征的全新音频:
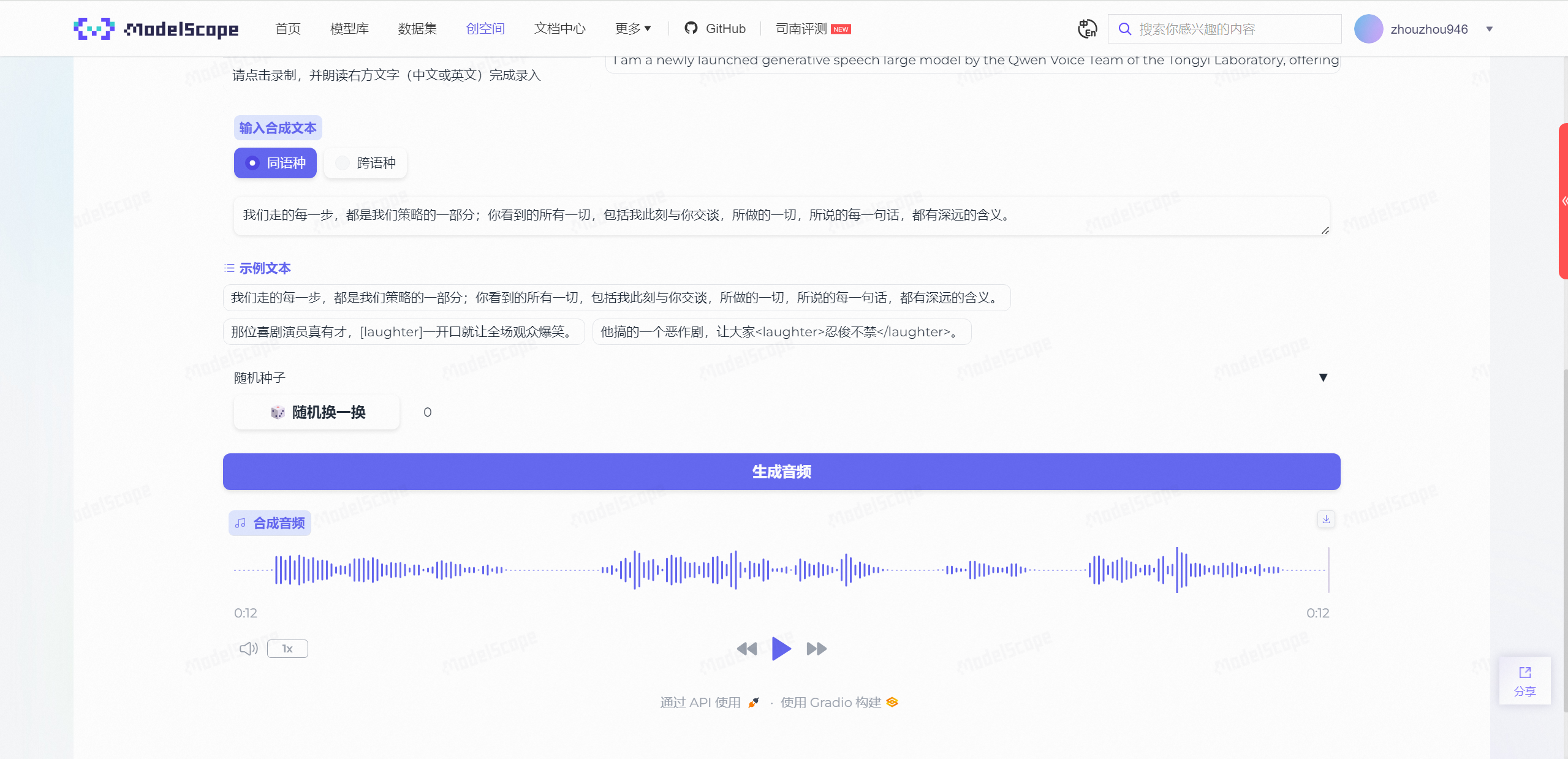
听了一下,效果确实还是很不错的,随后我又尝试采用富文本控制情绪来生成音频:

这个笑声甚至都真的有点像我自己了,并且,在第一次学习之后,后续的平均生成速度也保持在了2~3s左右,非常快!
除了同语种外,我们也可以尝试跨语种,比如我此时选择生成的文本为英语:
Every step we take is part of our strategy; everything you see, including my conversation with you right now, every action I make, and every word I say, has profound meaning.
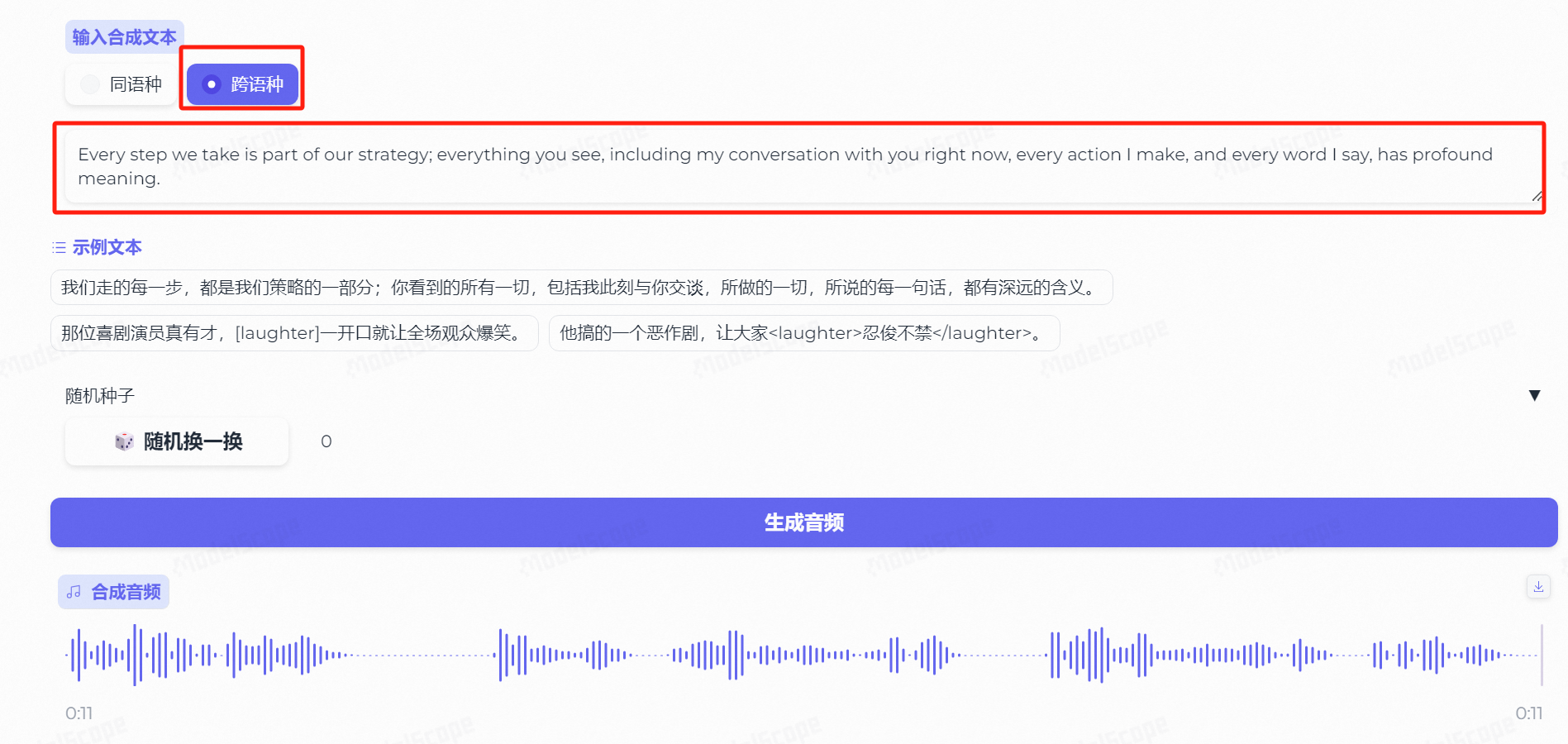
两个字,无敌!
高级语音生成
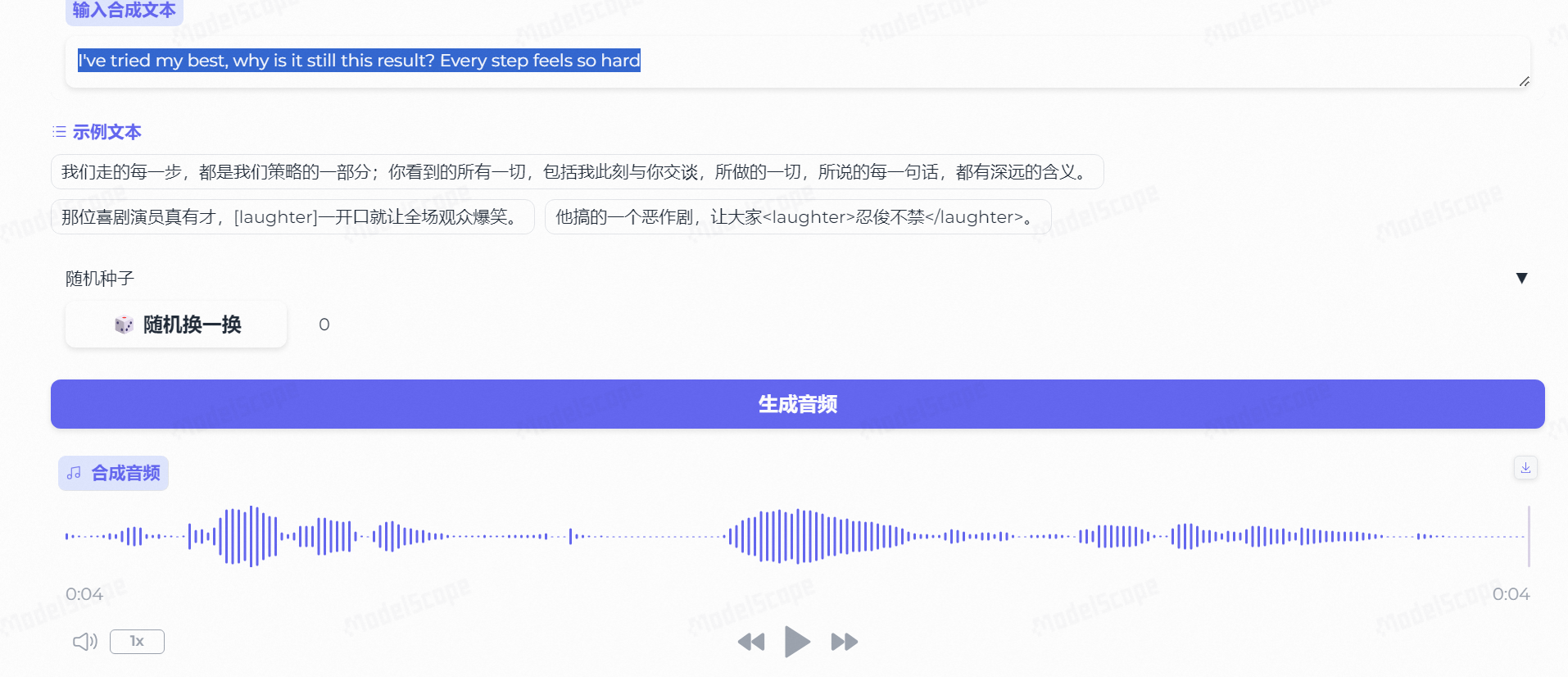
这是CosyVoice最具有特色的能力了,能依靠自然语言或prompt来控制AI生成音频中的情绪。
比如说我们选择默认的:
A female speaker with normal pitch, slow speaking rate, and sad emotion.
一位女性说话者,音高正常,语速缓慢,并带有悲伤的情绪。
合成文本为:
我尽力了,为什么还是这样的结果
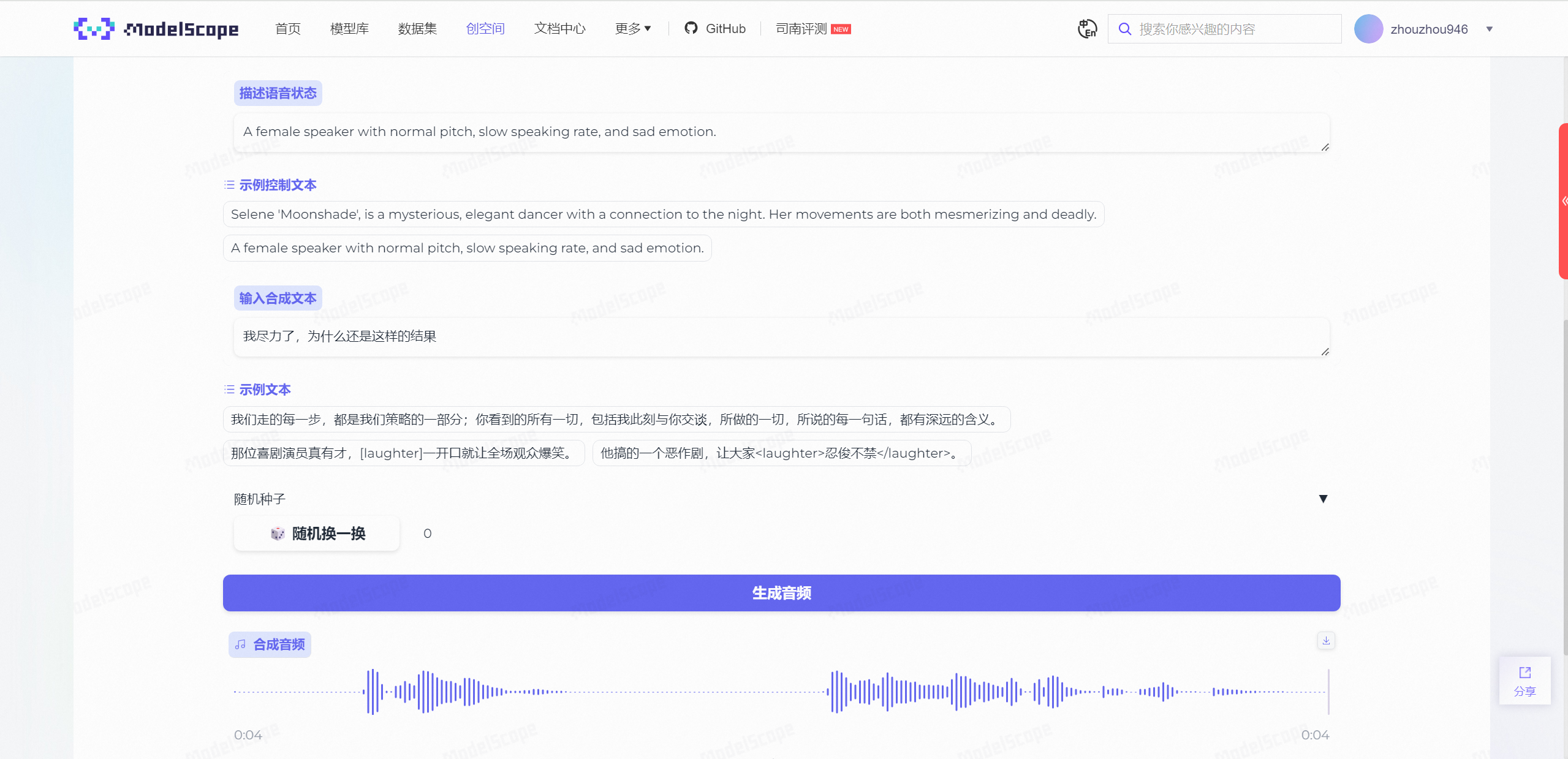
悲伤的情绪确实渲染的极其到位,每一个字都仿佛带着沉重的叹息一般,这个情感表达真的没话说。。。
后面又尝试了一下英文版,同样也是能很好的表达情绪:
I’ve tried my best, why is it still this result? Every step feels so hard
对比ChatTTS
首先,已经能够明确的是,ChatTTS的基础版本功能丰富度是不如CosyVoice的,所以接下来我仅对基础能力进行测评比较。
短文本生成音频
在面对短句文本生成音频时,两者的表现都非常的优异,自是不必多言。
长文本生成音频
目前,ChatTTS在线版仅支持生成小于30s的音频,即使部署本地高级版也无法在保持一致性及高品质的情况下生成超过2分钟的视频,对于CosyVoice,能够直接生成2分40秒的视频,这一轮,CosyVoice赢麻了!
语气控制
目前。ChatTTS中仅可控制【笑声】和【停顿】。
[laugh] 代表笑声
[uv_break] 代表停顿
并且可通过 params_refine_text 中的 prompt 参数可以控制笑声和停顿的强度:
笑声:laugh_(0-2),可选值:laugh_0、laugh_1、laugh_2(笑声愈加强烈)
停顿:break_(0-7),可选值:break_0 至 break_7(停顿逐渐明显)
chat.infer([text], params_refine_text={“prompt”: ‘[oral_2][laugh_0][break_6]’})
chat.infer([text], params_refine_text={“prompt”: ‘[oral_2][laugh_2][break_4]’})
不过实际测试发现,[break_0] 到 [break_7] 以及 [laugh_0] 到 [laugh_2] 的区别不明显。
而CosyVoice中,有多种语气控制关键词,如下:

毫无疑问,这波CosyVoice又赢麻了。
小结
通过对CosyVoice三个功能的体验,我觉得这里也可以得出如下一个基本结论:目前就功能丰富度来看,CosyVoice已经优于ChaTTS了;在情绪表达和音色控制上,CosyVoice生成的音频是更符合中国人说话习惯的,比如其理解的笑声或者忍俊不禁才是符合我个人认知中的开心的状态,换句话说,我之前使用ChatTTS时,确实也能控制它来生成笑声,但是这个笑声并不是我认知中或者我理想中的那个正常人类的笑声,显然,CosyVoice仍然略胜一筹;从教程和介绍的完整性上来看,我说实话,真的找不到比阿里这边更负责的撰写人了,从基础原理到应用场景再到用法示例,归纳的一清二楚,在使用ChatTTS时,我知道可以通过富文本控制语气,但是不知道哪些关键词才能够被触发,而在CosyVoice中,我们可以显而易见的查阅使用方式。

真不是尬吹,CosyVoice确实好用,免费、便捷、高效,谁用谁知道!
体验SenseVoice
SenseVoice主要是用于情感识别、声音事件检测、语音识别等功能的音频理解模型。
在线体验界面如下:
点击麦克风按钮,选择录制,录入一段原声:
这里我是直接朗读了一段上面的英文模版:
Upload an audio file or input through a microphone, then select the task and language.
即使在不提前设置语言选择的情况下,也能够成功识别出原文:

为了加大难度,我又放置了一段日语原声,但是考虑到日语有借鉴过中文,部分单词发音相近,所以我决定做两次测试,即:第一次设置为默认状态让其识别,如果效果不佳,再设置为日语让其再识别。
但是很奇怪的是,采用在线录制的日语音频识别一直报错。
随后,我还是决定采用官方在右边给出的案例来进行测试,点击日语的MP3文件:
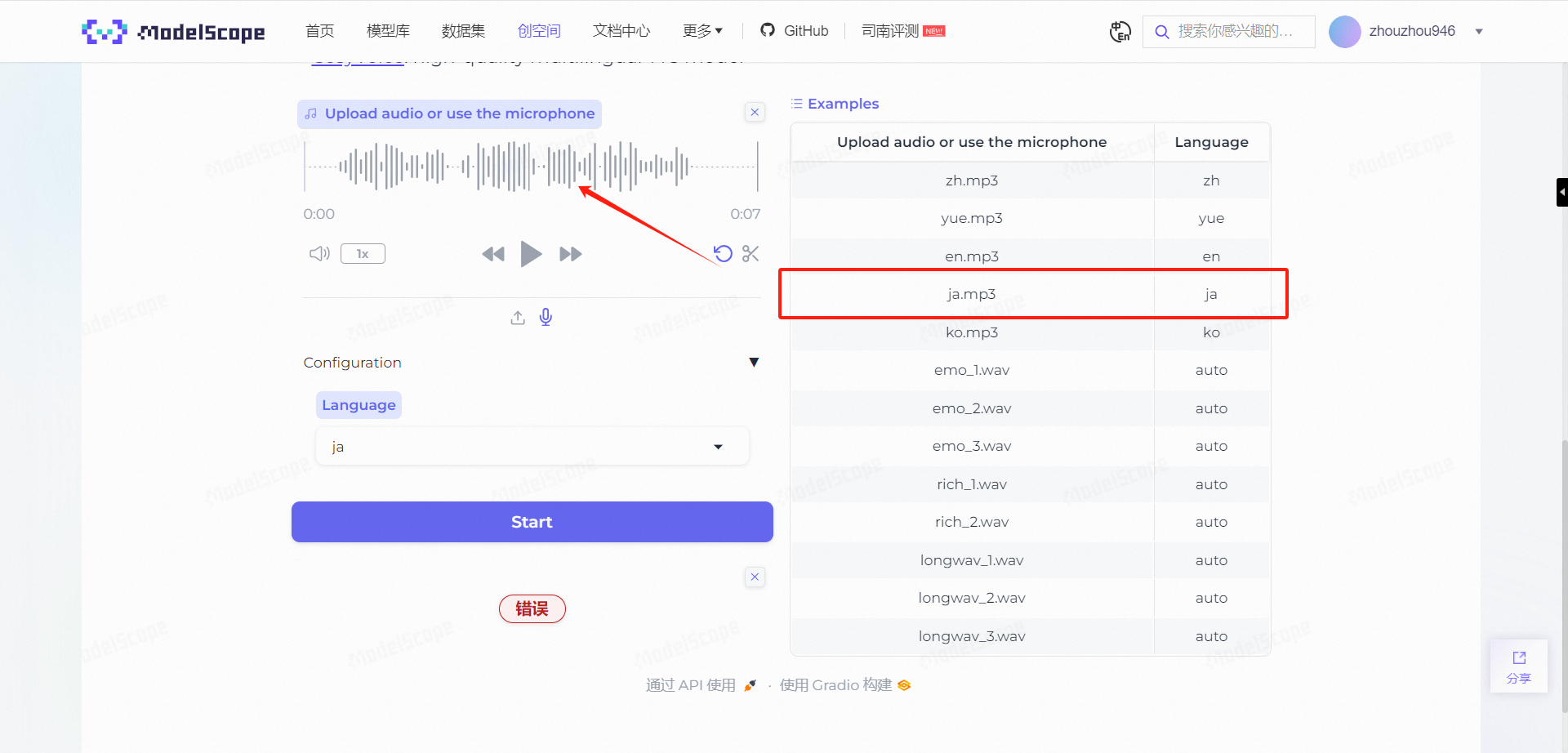
点击Start,可以正常识别到对应文字,现在想来,可能是刚才录制的日语音频带有杂音。
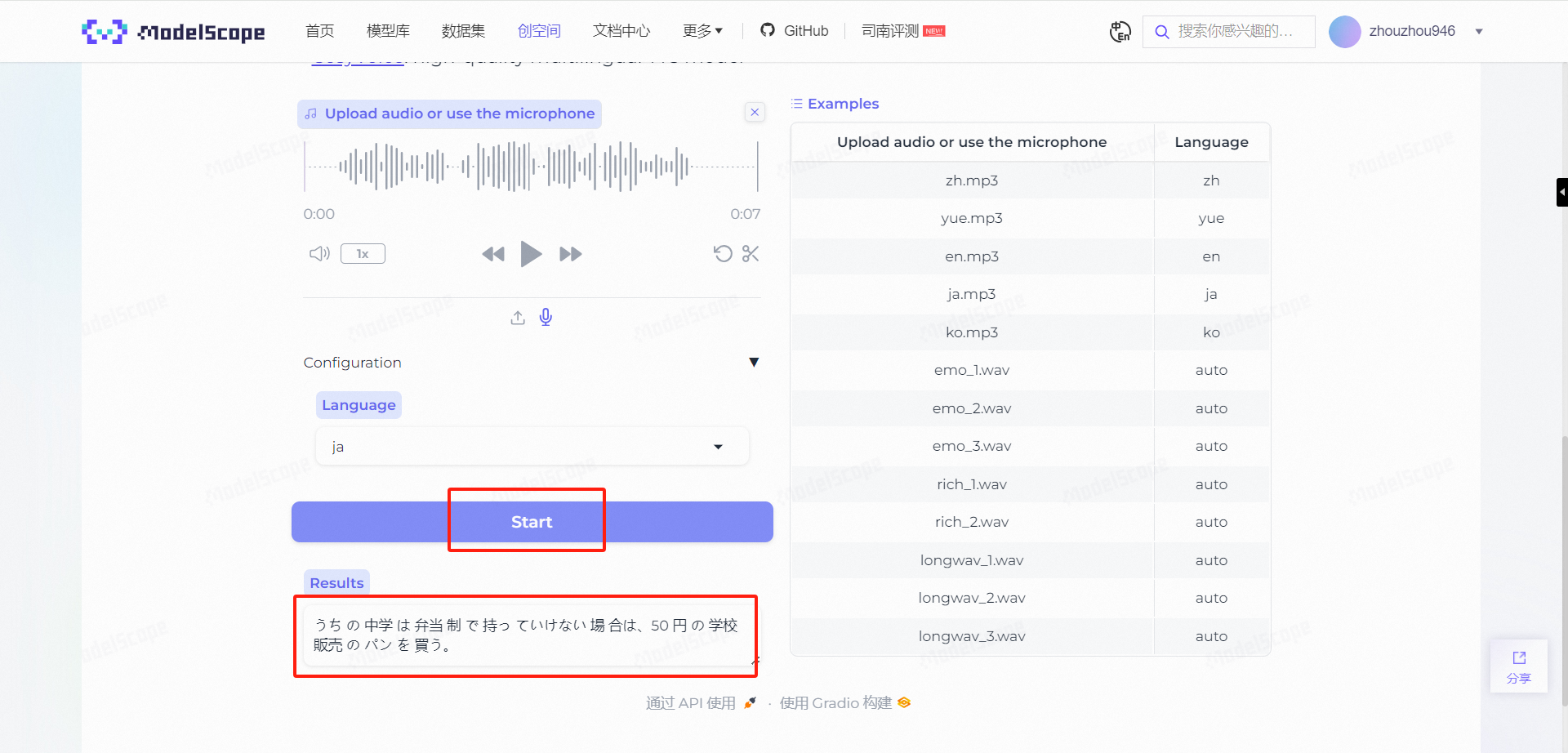
做到这一步,基本功能算是测试完毕了,那么接下来就是体验SenseVoice的高级能力:情感识别。
情感识别
我们选择情感识别中的几个示例录音,在生成之后会发现带上了一个Emotion。
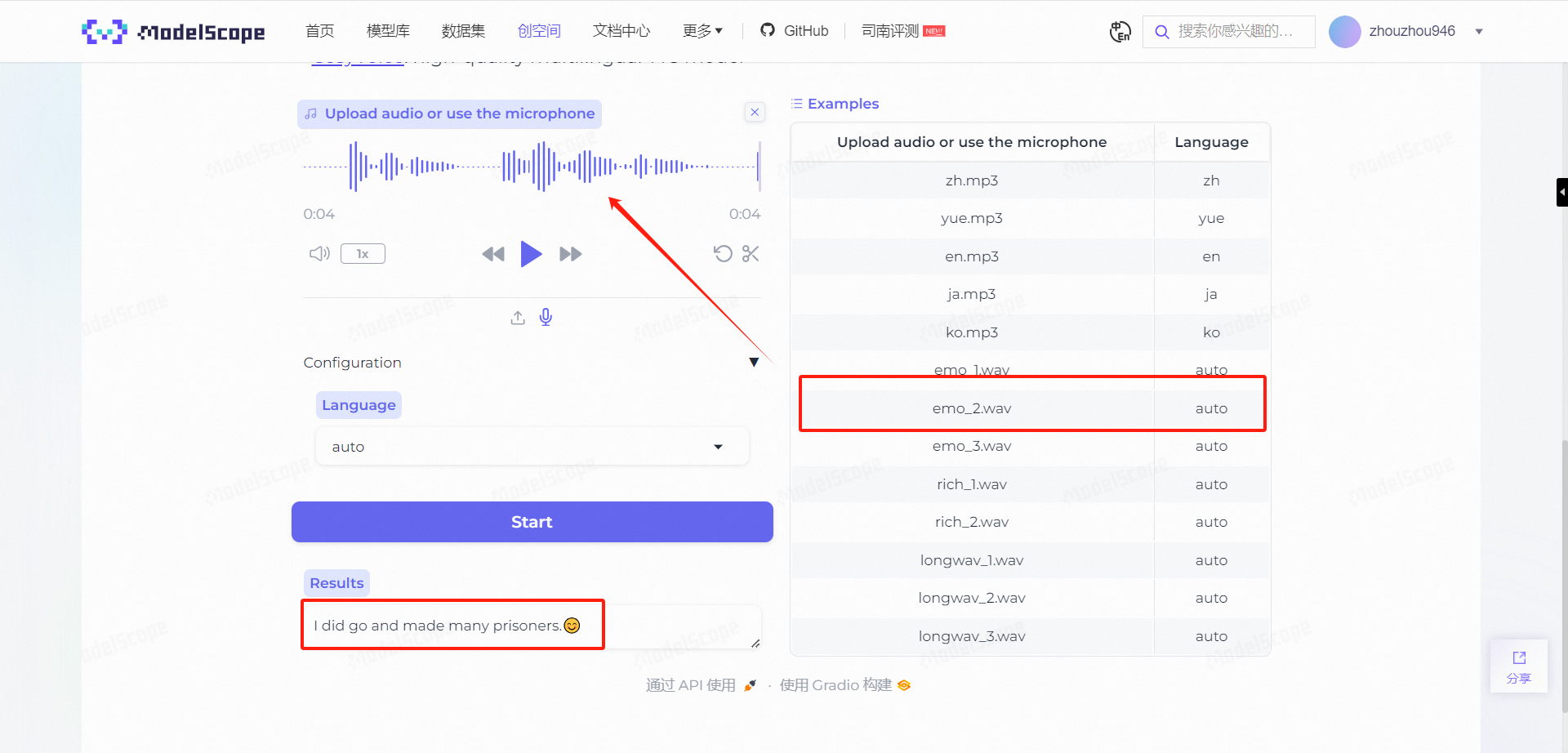
而SenseVoice的厉害之处在于,它识别情感并不仅仅依靠音频文字本身,而是依靠人在说话时的声音特征,比如音调的变化、语速的快慢以及停顿的长短等非言语信号。


即便是识别到同一句话,也能够分辨出人物说话时的真实情感。
除此,它能识别到情绪种类也非常多样:
并不仅限于开心、伤心、生气等。
长音频识别
SenseVoice的另一个特点就是在长音频、多语言、复杂情感的情况下,仍然能很好的识别和理解音频内容:
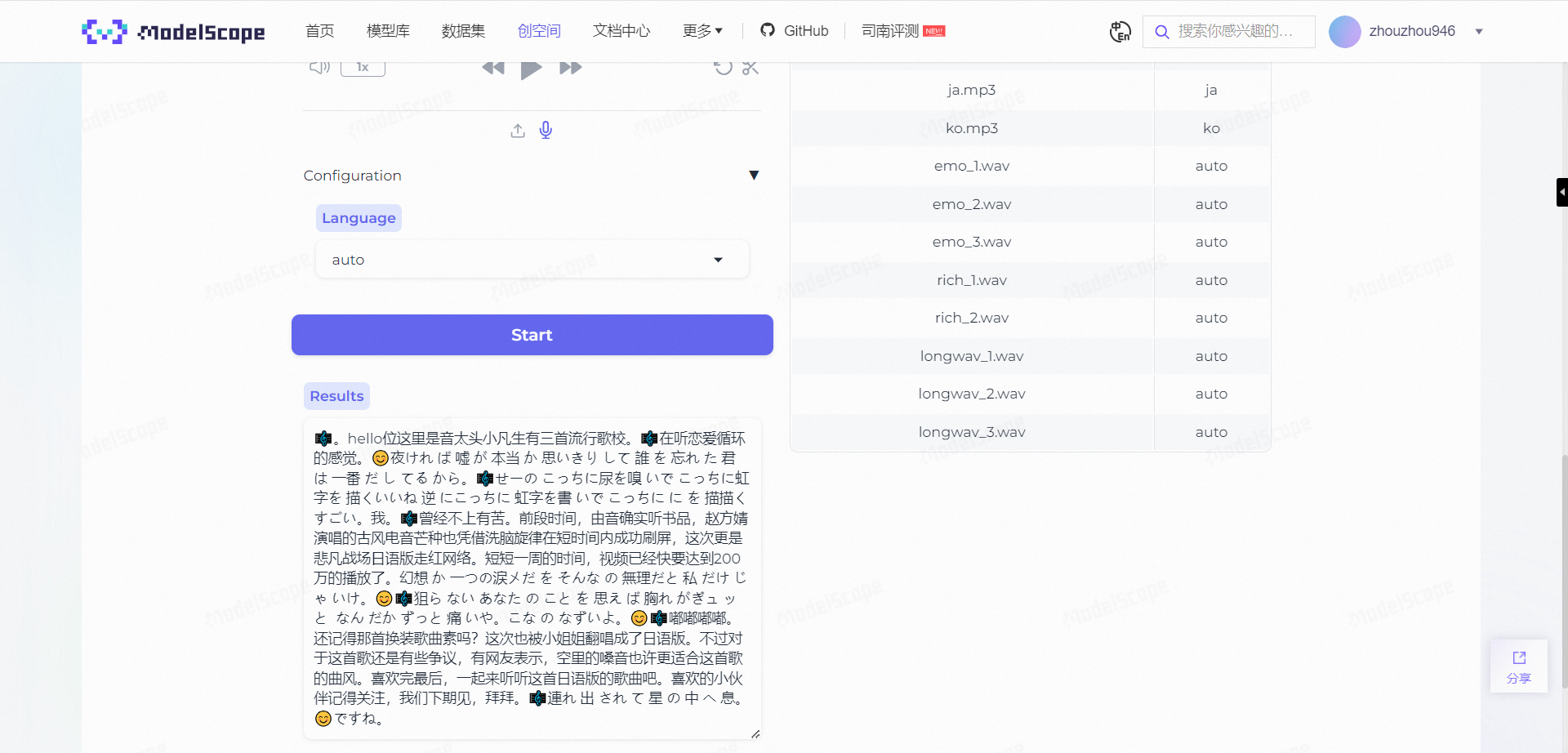
这一段是广播的原声,开头播放的是一首音乐,所以这里给出了音乐的logo。

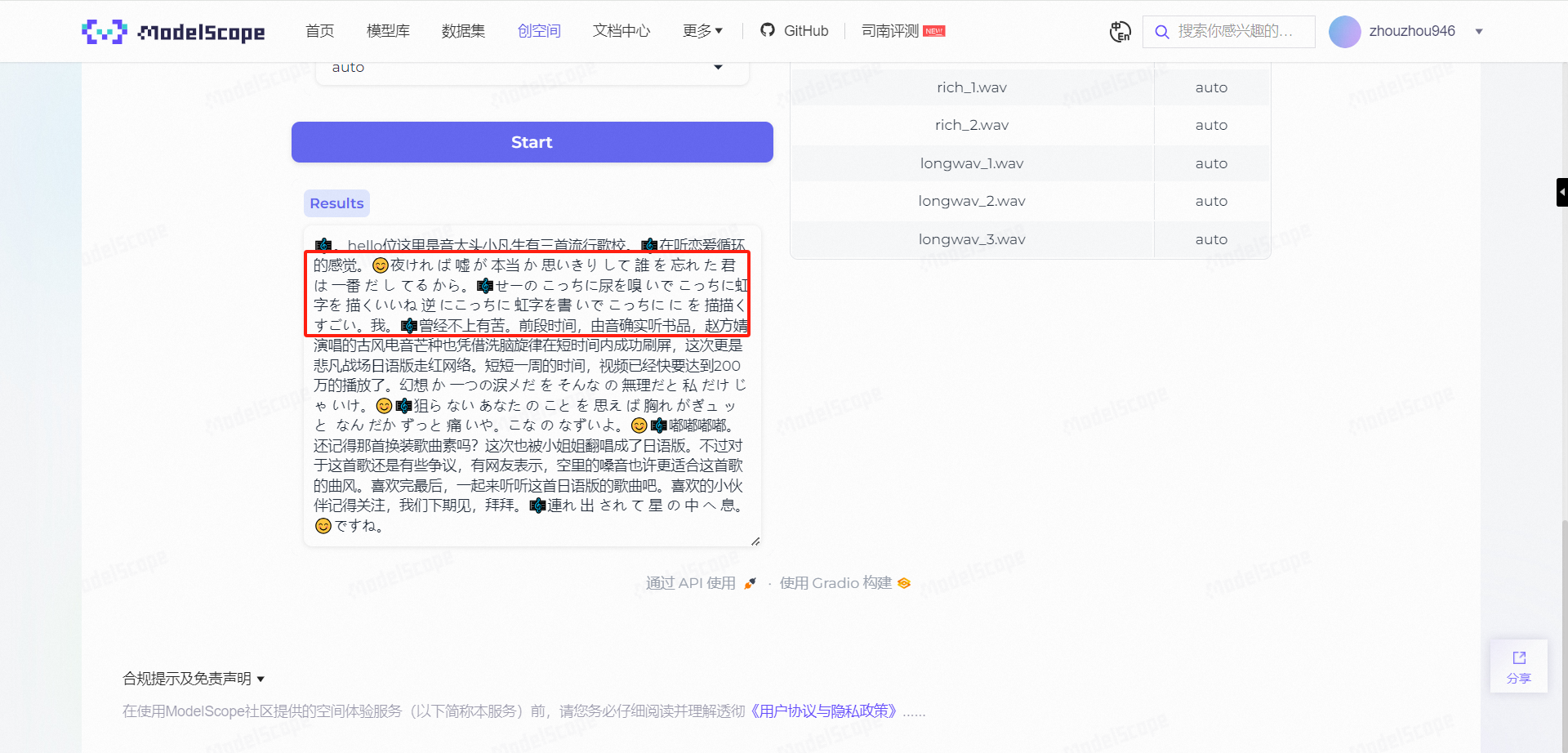
而在后面播放日语版歌曲时,不但识别到了音乐,甚至也将日语歌词识别了出来:
小结
通过对CosyVoice的体验,我们可以得出以下基本结论:作为一款开放在线使用的语音情感识别模型,它确实具有强大的语音识别能力,不仅能准确识别不同语言的内容,还能通过分析说话人的声音特征来判断真实情感,且情感类型丰富多样。此外,SenseVoice在处理包含音乐、多种语言和复杂情感的长音频时,依然能够很好地识别和理解其中的内容。
本地化部署FunAudioLLM
既然是开源的模型,那么肯定可以部署在本地的,这里,我们就尝试来将FunAudioLLM部署至本地环境。
本地部署CosyVoice
源码安装
下面以winodws操作系统为例进行部署操作。
首先克隆项目:
git clone https://github.com/v3ucn/CosyVoice_For_Windows
进入项目中,执行如下命令:
cd CosyVoice_For_Windows
生成内置模块:
git submodule update --init --recursive
随后安装如下依赖:
conda create -n cosyvoice python=3.11
conda activate cosyvoice
pip install -r requirements.txt -i https://mirrors.aliyun.com/pypi/simple/ --trusted-host=mirrors.aliyun.com
官方推荐的Python版本是3.8,实际上3.11也是可以跑起来的,并且理论上3.11的性能更好。
随后下载deepspeed的windows版本安装包来进行安装:
https://github.com/S95Sedan/Deepspeed-Windows/releases/tag/v14.0%2Bpy311
最后,安装gpu版本的torch:
pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu121
这里cuda的版本选择12,也可以安装11的。
随后下载模型:
# git模型下载,请确保已安装git lfs
mkdir -p pretrained_models
git clone https://www.modelscope.cn/iic/CosyVoice-300M.git pretrained_models/CosyVoice-300M
git clone https://www.modelscope.cn/iic/CosyVoice-300M-SFT.git pretrained_models/CosyVoice-300M-SFT
git clone https://www.modelscope.cn/iic/CosyVoice-300M-Instruct.git pretrained_models/CosyVoice-300M-Instruct
git clone https://www.modelscope.cn/speech_tts/speech_kantts_ttsfrd.git pretrained_models/speech_kantts_ttsfrd
由于使用国内的魔搭仓库,所以速度非常快,最后添加环境变量:
set PYTHONPATH=third_party/AcademiCodec;third_party/Matcha-TTS
基础用法如下:
from cosyvoice.cli.cosyvoice import CosyVoice
from cosyvoice.utils.file_utils import load_wav
import torchaudio
cosyvoice = CosyVoice('speech_tts/CosyVoice-300M-SFT')
# sft usage
print(cosyvoice.list_avaliable_spks())
output = cosyvoice.inference_sft('你好,我是通义生成式语音大模型,请问有什么可以帮您的吗?', '中文女')
torchaudio.save('sft.wav', output['tts_speech'], 22050)
cosyvoice = CosyVoice('speech_tts/CosyVoice-300M')
# zero_shot usage
prompt_speech_16k = load_wav('zero_shot_prompt.wav', 16000)
output = cosyvoice.inference_zero_shot('收到好友从远方寄来的生日礼物,那份意外的惊喜与深深的祝福让我心中充满了甜蜜的快乐,笑容如花儿般绽放。', '希望你以后能够做的比我还好呦。', prompt_speech_16k)
torchaudio.save('zero_shot.wav', output['tts_speech'], 22050)
# cross_lingual usage
prompt_speech_16k = load_wav('cross_lingual_prompt.wav', 16000)
output = cosyvoice.inference_cross_lingual('<|en|>And then later on, fully acquiring that company. So keeping management in line, interest in line with the asset that\'s coming into the family is a reason why sometimes we don\'t buy the whole thing.', prompt_speech_16k)
torchaudio.save('cross_lingual.wav', output['tts_speech'], 22050)
cosyvoice = CosyVoice('speech_tts/CosyVoice-300M-Instruct')
# instruct usage
output = cosyvoice.inference_instruct('在面对挑战时,他展现了非凡的<strong>勇气</strong>与<strong>智慧</strong>。', '中文男', 'Theo \'Crimson\', is a fiery, passionate rebel leader. Fights with fervor for justice, but struggles with impulsiveness.')
torchaudio.save('instruct.wav', output['tts_speech'], 22050)
也可以使用webui,更加直观和方便:
python3 webui.py --port 9886 --model_dir ./pretrained_models/CosyVoice-300M
访问 http://localhost:9886 ,可以看到界面如下:
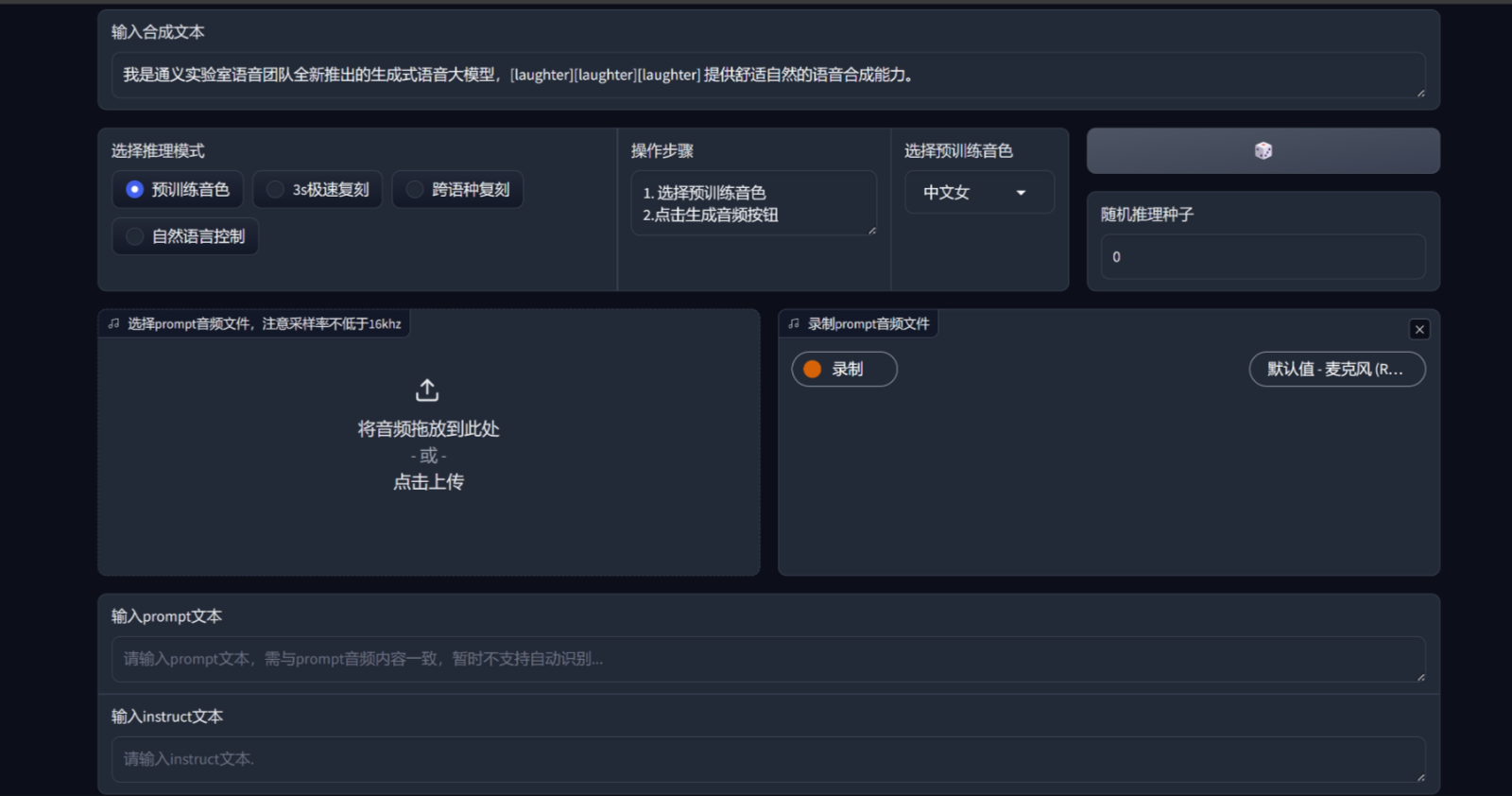
不过,由于官方的torch的backend使用的是sox,这里改成了soundfile,可能会存在bug。
所以我更推荐下面的一键包。
一键整合包
CosyVoice整合包0711(Windows) : https://pan.quark.cn/s/4177b0716e35
本地部署SenseVoice
源码安装
创建虚拟环境:
conda create -n sensevoice python=3.11 -y
conda activate sensevoice
克隆代码
git clone https://github.com/FunAudioLLM/SenseVoice.git
cd SenseVoice
安装依赖模块
vi python>=3.8
--- delete
python>=3.8
---
pip install -r requirements.txt
pip install gradio
python webui.py
使用浏览器打开 http://localhost:7860 :
一键整合包
链接: https://pan.baidu.com/s/1Spq6NA1Iuik19XsZ070d5w?pwd=8zfh 提取码: 8zfh 复制这段内容后打开百度网盘手机App,操作更方便哦
写在结尾的话
通过上文的整个测试和安装部署过程,我们确实可以感受到阿里团队的用心,这两款音频大模型确实都极具特色。
SenseVoice不仅在语音识别方面表现出色,还具备独特的情感识别功能,能够通过分析说话人的声音特征来准确捕捉其情绪状态,即使在处理长音频或多语言场景下也能保持高度准确性。这种全面的能力使得SenseVoice成为了音频理解领域内一个强有力的技术解决方案,适用于各种应用场景,从客户服务到情感分析等多个方面都能发挥重要作用。
CosyVoice不仅在功能丰富度方面表现优异,而且特别符合中国用户的使用习惯,这得益于其针对中文环境进行了优化设计。无论是从用户体验的角度还是技术实现层面来看,CosyVoice都展现了其在语音交互领域的先进性和实用性,尤其是在满足国内用户需求方面有着明显的优势。
展望未来,随着技术的不断进步和发展,期望这两款音频大模型在更多领域得到广泛应用,并持续提升其性能和服务质量。例如,进一步增强多语言支持能力、提高在嘈杂环境下的语音识别准确率、拓展更多个性化定制选项等,都将为用户提供更加智能、便捷的服务体验。同时,随着人工智能技术的发展,这些音频大模型有望在教育、医疗、智能家居等行业发挥更大的作用,为人们的生活带来更多便利。